ЧАбд
дкзіЩюЖШбЇЯАдквНбЇгАЯёЩЯгІгУЕФЪБКђ,Ъ§ОнМЏЭљЭљЪЧ3DЕФ,ЖјЭјЩЯКмЖрЙЋПЊЕФtrickЛђепзЂвтСІЛњжЦЖМЪЧ2DЪЕЯжЕФ,вђДЫДјРДСЫвЛаЉРЇФбЁЃ
зіЗЈ
дкgithub(https://github.com/xmu-xiaoma666/External-Attention-pytorch)ЩЯПЩвдПДЕНКмЖрЯжгаМДВхМДгУЕФзЂвтСІФЃПщЁЃ
git cloneЕНБОЕиКѓ,ЙиМќОЭЪЧдѕУДдквбгаЕФДњТыПђМмЩЯВхШыетаЉзЂвтСІФЃПщЁЃ
**step0:**ЪЕР§ЛЏвЛИіФЃаЭ,РћгУtorch.randnКЏЪ§ФЃФтЪфШыЁЃЮветРяЪфШыЕФЪЧвЛИіbatchsizeЮЊ128,channelЮЊ1,xЮЊ24,yЮЊ24,zЮЊ20ЕФЭМЯёЁЃ
if __name__ == '__main__':
input=torch.randn(128,1, 24, 24, 20)
net=DiscriNet()
out=net(input)
print(out.shape)
**step1:**жЊЕРвЊВхЕФЮЛжУ,вЛАудкbackboneЕФКѓУцЁЃдкdef forward(self, x)ЗНЗЈжа,РћгУprint(x.size())жЊЕРЯргІЕФЪфШыГпДчЁЃ
def forward(self, x):
#print(x.size()) #torch.Size([128, 1, 20, 20, 16]) 128ЮЊbatchsize 1ЮЊchannel
x = self.net(x)
# print(x.size())
# print(x.size()) #torch.Size([128, 128, 2, 2, 2])
if self.is_fc:
x = x.view(-1, 128 * 2 * 2 * 2)
x = self.final(x)
else:
#print(self.final(x).size()) #torch.Size([128, 2, 1, 1, 1])
#print(self.final(x).squeeze(4).size()) #torch.Size([128, 2, 1, 1])
#print(self.final(x).squeeze(4).squeeze(3).squeeze(2).size())#torch.Size([128, 2])
x = self.final(x).squeeze(4).squeeze(3).squeeze(2)
#print(x.size()) #torch.Size([128, 2])
return x
**step2:**ИљОнвбОЗтзАКУЕФФЃПщ,НЋЫќЪЕР§ЛЏКѓВхШыЕНforwardЗНЗЈжаЁЃ
def forward(self, x):
from SelfAttention import ScaledDotProductAttention
#print(x.size())
x = self.net(x)
#print(x.size()) #torch.Size([128, 128, 4, 4, 4])
b = x.permute(0, 2, 3, 4, 1).reshape(128, -1, 128)
sa = ScaledDotProductAttention(d_model=128, d_k=128, d_v=128, h=8)
output = sa(b, b, b)
#print(output.size())
x = x.reshape(128, 4, 4, 4, 128).permute(0, 4, 1, 2, 3)
# print(x.size())
#print(x.equal(a))
x = x.contiguous().view(-1, 128 * 4 * 4 * 4)
#(x.size())
x = self.final(x)
return x
РћгУpermuteЁЂreshapeЁЂviewКЏЪ§,ОЭПЩвдзЊЛЛСЫЁЃЮветРягУЕФЪЧздзЂвтСІЛњжЦ,вђЮЊЦфБОЩэЪЧДгздШЛгябдСьгђзЊЛЛЖјРДЕФ,ЮоТлЪЧ2DЛЙЪЧ3DЫќЖМЛсзЊЛЛГЩ1DЕФtensorЁЃ
BUG1 RuntimeError: Expected all tensors to be on the same device, but found at least two devices
вЛАуЪЧtensorвЛИідкcpu,вЛИідкgpuЩЯБЈДэЁЃ
device = torch.device('cuda:0')
emsa = EMSA(d_model=128, d_k=128, d_v=128, h=8, H=8, W=8, ratio=2, apply_transform=True).to(device)
ШУФЃаЭдкgpuЩЯдЫааЁЃ
BUG2ДњТыПЩвддЫаа,ЕЋдЫааЕНзюКѓвЛИіepochБЈДэ
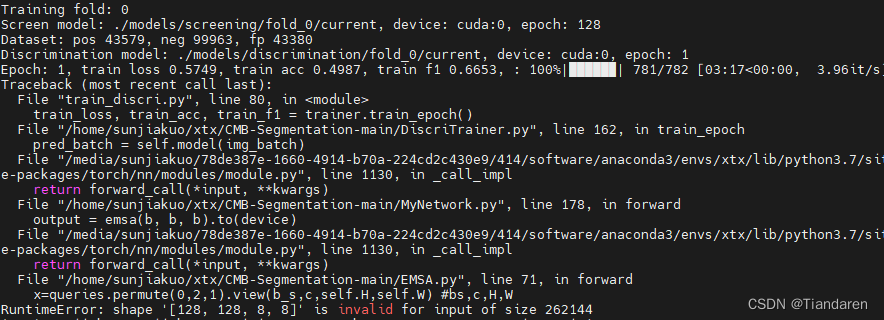
етЪЧгЩгкзюКѓвЛИіepochЕФbatchsizeВЛЕНжИЖЈЪ§СПЫљЕМжТЕФЁЃЮвbatchsizeЩшжУЮЊ128,зюКѓвЛИіepochВЛЕН128,вђДЫКѓУцЕФзЊЛЛОЭЛсБЈДэЁЃ
for img_batch, label_batch in dataloader:
if(len(img_batch)==self.batch_size):
МгвЛИіХаЖЯОЭКУЁЃ
ЛђепВЛвЊЙЬЖЈbatchsize
def forward(self, x):
from SelfAttention import ScaledDotProductAttention
#print(x.size())
x = self.net(x)
x_batchsize=x.size()[0]
device = torch.device('cuda:0')
b = x.permute(0, 2, 3, 4, 1).reshape(x_batchsize, -1, 128).to(device)
sa = ScaledDotProductAttention(d_model=128, d_k=128, d_v=128, h=8).to(device)
output = sa(b, b, b)
#print(output.size())
x = x.reshape(x_batchsize, 4, 4, 4, 128).permute(0, 4, 1, 2, 3)
# print(x.size())
#print(x.equal(a))
x = x.contiguous().view(-1, 128 * 4 * 4 * 4)
#(x.size())
x = self.final(x)
return x