depth_multiple: 0.33 # model depth multiple ����ģ�͵����(BottleneckCSP����)
width_multiple: 0.50 # layer channel multiple ����Convͨ��channel����(����������)
# depth_multiple��ʾBottleneckCSPģ�����������,������BottleneckCSPģ���Bottleneck���ϸò����õ����ո�����
# width_multiple��ʾ����ͨ������������,���ǽ����������backbone��head�����й�Convͨ��������,ȫ�����Ը�ϵ����
# ͨ�������������Ϳ���ʵ�ֲ�ͬ���Ӷȵ�ģ����ơ�
anchors:
- [10,13, 16,30, 33,23] # P3/8,���СĿ��,10,13��һ��ߴ�,�ܹ�������СĿ��,FPN�����������²���8�����anchor��С
- [30,61, 62,45, 59,119] # P4/16,�����Ŀ��,������,�²���4�����anchor��С
- [116,90, 156,198, 373,326] # P5/32,����Ŀ��,������,�²���2�����anchor��С
��anchor�ߴ���Ϊ����ͼ��640��640�ֱ���Ԥ���,ʵ���˼�������С����ͼ(feature map)�ϼ���Ŀ��,Ҳ�����ڴ�����ͼ�ϼ��СĿ�ꡣ���ֳߴ������ͼ,ÿ������ͼ�ϵĸ����������ߴ��anchor��
yolov5-5
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
yolov5-6
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
from:����������һ��,-1������һ��,1������1��,3������3��
number:��depth_multiple���ȷ����������,����number����Ҫ����1
module:��width_multiple���ȷ������Ŀ���,��Ҫ�Ǹı�����˵�����
args:ģ�����,channel,kernel_size,stride,padding,bias��
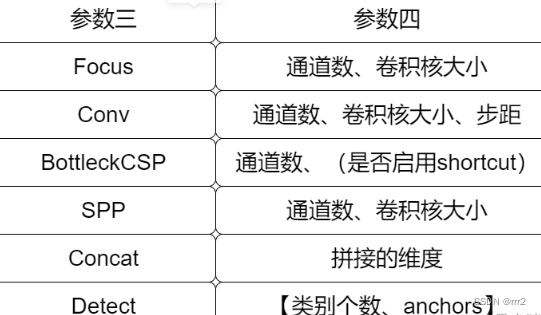
������������Ϊ Focus ʱ,������ͼ������Ƭ����,[64,3]�õ�[3,32,3],������channel=3(RGB),���Ϊ64*0.5(width_multiple)=32,3Ϊ�����˳ߴ硣 ���ĸ�������,��һ��ֵΪ��ģ������Ҫ�õ���ͨ����,�ڶ���ֵΪ�����˴�С;
������������Ϊ Conv ʱ,���ĸ�������,��һ��ֵΪ��ģ������Ҫ�õ���ͨ����,�ڶ���ֵΪ�����˴�С,����������Ϊ�����С,���ĸ���padding;nn.conv(kenel_size=1,stride=1,groups=1,bias=False) + Bn + Leaky_ReLu��
eg [-1, 1, Conv, [128, 3, 2]]:����������һ��,ģ������Ϊ1��,��ģ��ΪConv,������������128*0.5(width_multiple)=32��������,�����˳ߴ�Ϊ3,stride=2,��
������������Ϊ BottleneckCSP(C3) ʱ,���ĸ�������,��һ��ֵ�Ǹ�ģ���õ���ͨ����;������ڵڶ�������,�ڶ�������:�Ƿ����� shortcut ����. C3���CSPNet����ṹ,��3���������X���в�ģ��Concat���,����False,��û�вв�ģ��,��ô��ɽṹΪnn.conv+Bn+Leaky_ReLu.
������������Ϊ SPPʱ,���ĸ��������� SPP ����Ҫ�õ��ľ����˴�С��
������������Ϊ nn.Upsampleʱ,���� torch ��ʵ�ֵ��ϲ���������
������������Ϊ Concatʱ,���ĸ��������� concat ��ƴ�ӵ�ά�ȡ�
������������Ϊ Detectʱ,���ĸ�������,��һ��ֵΪ������,�ڶ���ֵΪ������ anchors ��ֵ��
YOLOV5-6 �����YOLOV5-5���������½ṹ:
- ��Focus()ģ��,��һ��Conv(k=6,s=2,p=2)����
- ʹ��SPPF() �滻 SPP() ���Լ��ٲ���
- ���� P3 ���ɲ� C3() �� 9 �� 6 �ظ�������ٶ�
- �������� SPPF() �������ɵ�ĩβ
- �����һ�� C3() ���ɲ�����������shortcut
- ������mixup��copy-paste �ij���
YOLOv5�е�Head����Neck��Detect_head�����֡�Neck������PANet����,Detect�ṹ��YOLOv3�е�Headһ��������BottleNeckCSP����False,˵��û��ʹ�òв�ṹ,���Dz��õ�backbone�е�Conv��
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
��ʼ������
YOLOv5�ij����ļ���data/hyp.finetune.yaml(����VOC���ݼ�)����hyo.scrach.yaml(����COCO���ݼ�)�ļ�
lr0: 0.01 # ��ʼѧϰ�� (SGD=1E-2, Adam=1E-3)
lrf: 0.2 # ѭ��ѧϰ�� (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1 ѧϰ�ʶ���
weight_decay: 0.0005 # Ȩ��˥��ϵ��
warmup_epochs: 3.0 # Ԥ��ѧϰ (fractions ok)
warmup_momentum: 0.8 # Ԥ��ѧϰ����
warmup_bias_lr: 0.1 # Ԥ�ȳ�ʼѧϰ��
box: 0.05 # iou��ʧϵ��
cls: 0.5 # cls��ʧϵ��
cls_pw: 1.0 # cls BCELoss������Ȩ��
obj: 1.0 # ��������ϵ��(scale with pixels)
obj_pw: 1.0 # ��������BCELoss������Ȩ��
iou_t: 0.20 # IoUѵ��ʱ����ֵ
anchor_t: 4.0 # anchor�ij�����(��:�� = 4:1)
# anchors: 3 # ÿ��������anchors����(0 to ignore)
#����ϵ����������ǿϵ��,������ɫ�ռ��ͼƬ�ռ�
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
hsv_h: 0.015 # ɫ�� (fraction)
hsv_s: 0.7 # ���Ͷ� (fraction)
hsv_v: 0.4 # ���� (fraction)
degrees: 0.0 # ��ת�Ƕ� (+/- deg)
translate: 0.1 # ƽ��(+/- fraction)
scale: 0.5 # ͼ������ (+/- gain)
shear: 0.0 # ͼ����� (+/- deg)
perspective: 0.0 # ���� (+/- fraction), range 0-0.001
flipud: 0.0 # �������·�ת���� (probability)
fliplr: 0.5 # �������ҷ�ת���� (probability)
mosaic: 1.0 # ����Mosaic���� (probability)
mixup: 0.0 # ����ͼ��������(��,����ͼ���ص���һ��) (probability)
ѵ������������:yaml�ļ���ѡ��,��ѵ��ͼƬ�Ĵ�С,Ԥѵ��,batch,epoch�ȡ�
����ֱ����train.py��parser����,Ҳ������������ִ��ʱ��,��:$ python train.py --data coco.yaml --cfg yolov5s.yaml --weights ���� --batch-size 64
�Cdataָ��ѵ�������ļ� --cfg��������ṹ�������ļ� �Cweihts����Ԥѵ��ģ�͵�·��
ref
https://zhuanlan.zhihu.com/p/172121380