��Ŀ�õ���paddlespeech2,ѧ�˼���paddlepaddle,��¼һ��:
����Ŀ¼
1 ��д����ʶ������
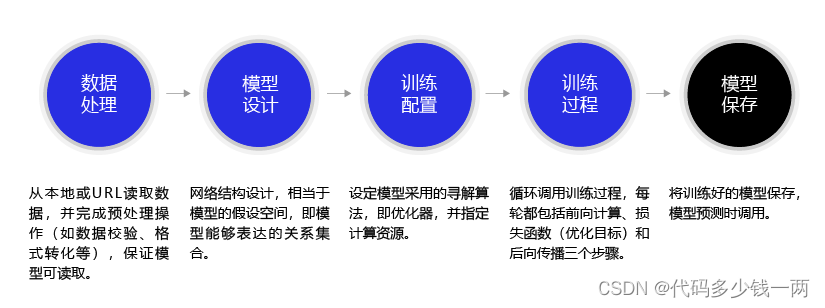
2 ����������д����ʶ��ģ��
����Ҫ���طɽ�ƽ̨�롰��д����ʶ��ģ����ص����
ͨ��paddle.vision.datasets.MNIST API�������ݶ�ȡ��
# �������ݶ�ȡ��,API�Զ���ȡMNIST����ѵ����
train_dataset = paddle.vision.datasets.MNIST(mode='train')
��¼���ɽ�����->�ĵ�->API�ĵ���,���Ի�ȡ�ɽ�API�ĵ���
ģ�����
ѵ������
ѵ������
ģ�Ͳ���
3����д����ʶ��֮���ݴ���
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-dQTIPeeR-1661928958262)(https://ai-studio-static-online.cdn.bcebos.com/257c74a23cef401c9db75fd2841bb93cdec28f756c6049b7b3e5ec1bf0ed058d)]
��������,һ���漰�����������:
- ���ݴ�������֮ǰ�Ĵ���,����ɽ�ƽ̨�����ݴ�����
- �������ݲ��������ݼ�
- ѵ����������������������
- ����������
- ��װ���ݶ�ȡ�봦������
ͬ�����ݶ�ȡ:���ݶ�ȡ��ģ��ѵ�����С���ģ����Ҫ����ʱ,���������ݶ�ȡ������õ�ǰ���ε����ݡ��ڶ�ȡ�����ڼ�,ģ��һֱ�ȴ����ݶ�ȡ�����Ž���ѵ��,���ݶ�ȡ�ٶ���Խ�����
�첽���ݶ�ȡ:���ݶ�ȡ��ģ��ѵ�����С���ȡ�������ݲ��ϵķ��뻺����,����ȴ�ģ��ѵ���Ϳ���������һ�����ݶ�ȡ����ģ��ѵ����һ�����κ�,���õȴ����ݶ�ȡ����,ֱ�Ӵӻ����������һ�������ݽ���ѵ��,�Ӷ��ӿ������ݶ�ȡ�ٶȡ�
�ɽ�ʵ���첽���ݶ�ȡ,��������:
- ����һ���̳�paddle.io.Dataset������ݶ�ȡ����
- ͨ��paddle.io.DataLoader�����첽���ݶ�ȡ�ĵ�������
4����д����ʶ������ṹ
��д����������28x28������ֵ,�����0-9�����ֱ�ǩ
���Իع�ģ������
��Ҫ����������:����Ķ��ȫ����������;��������硣
�Ƚ������ݴ���
�������ݼ���ȡ��
��������
��������ѵ����,��֤��,���Լ�
������
�������ݼ�ÿ�����ݵ����, ������Ŷ�ȡ����
��������������
4.1 �����ȫ����������
�����IJ�����:����㡢����������������
��д����ʶ�������,�������������:
�����ij߶�Ϊ28��28,�м������������Ϊ10��10�Ľṹ,�����ʹ�ó�����Sigmoid������
�뷿��Ԥ��ģ��һ��,ģ�͵�����ǻع�һ������,�����ijߴ����ó�1��
4.2 ����������
�����������ɶ��������ͳػ������,�����㸺����������ɨ�������ɸ������������ʾ,�ػ������Щ������ʾ���й���,������ؼ���������Ϣ��
5����д����ʶ����ʧ����
��ʧ������ģ���Ż���Ŀ��,�������ڶ�IJ���ȡֵ��,ʶ���������ȡֵ����ʧ�����ļ�����ѵ�����̵Ĵ�����,ÿһ��ģ��ѵ���Ĺ��̶���ͬ,����������:
- �ȸ������������������Ԥ�������
- �ٸ���Ԥ��ֵ����ʵֵ������ʧ��
- ��������ʧ�����ݶȲ����²�����
5.1 Softmax����
��ʵ�ı�ǩֵ����ת���һ��10ά�ȵ�one-hot����,�ڶ�Ӧ���ֵ�λ����Ϊ1,����λ��Ϊ0,�����ǩ��6������ת���[0,0,0,0,0,0,1,0,0,0]������Softmax�������Խ�ԭʼ���ת��ɶ�Ӧ��ǩ�ĸ���
��Ӧ��������,��Ҫ��ǰ�������,��ȫ������������������һ��Softmax����,outputs = F.softmax(outputs)��
5.2 ������
�������(�����ڻع�����)�����������(�����ڷ�������)
���������Ȼ˼��,������ֻ�����Ӧ�š���ȷ�⡱��ǩ���������Ȼ������
����,������ȷ��ǩ�������ǡ�2��,��֮��Ӧ��������������0.6,���������?log?0.6=0.51;����2����Ӧ�������0.1,�������Ϊ?log?0.1=2.30����ȷ���ǩ��Ӧ�����ԽС,���ص�ֵԽ��
�����صĴ���ʵ��:
��д����ʶ��������,���Ķ����д���,�Ϳ��Խ�������ģ�͵���ʧ�����滻�ɽ�����(Cross_entropy)��
- �ڶ�ȡ���ݲ���,����ǩ���������ó�int,��������һ����ǩ������ʵ��ֵ(�ɽ����Ĭ�Ͻ���ǩ������int64)��
- �����綨�岿��,�������ijɡ����ʮ����ǩ�ĸ��ʡ���ģʽ��
- ��ѵ�����̲���,����ʧ�����Ӿ������ɽ����ء�
6����д����ʶ���Ż��㷨
��һ����ȷ�˷����������ʧ����(�Ż�Ŀ��)����ظ����ʵ�ַ���,������Ҫ̽������д����ʶ��������,ʹ����ʧ�ﵽ��С�IJ���ȡֵ��ʵ�ַ�����[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-wXkqVeM9-1661928958264)(https://ai-studio-static-online.cdn.bcebos.com/af41e7b72180495c96e3ed4a370e9e030addebdfd16d42bc9035c53ca5883cd9)]
ǰ������
���Ż��㷨֮ǰ,��Ҫ�������ݴ��������������ṹ,��������һ�ڱ���һ��
����ѧϰ��
���ѧϰ������ģ����,ͨ��ʹ�ñ�������ݶ��½��㷨���²���,ѧϰ�ʴ����������·��ȵĴ�С,����������ѧϰ������ʱ,ģ�͵���Ч�������,�����ܴﵽ��Ч����á�
ѧϰ�ʵ������Ż��㷨
SGD��Momentum��AdaGrad��Adam
-
SGD: ����ݶ��½��㷨,ÿ��ѵ����������,����ƫ��µIJ���������������
-
Momentum: �����������������ĸ���,�ۻ��ٶ�,������,ʹ�������µķ�����ȶ���
-
AdaGrad: ���ݲ�ͬ�����������Ž��Զ��,��̬����ѧϰ�ʡ�ѧϰ�����½�,���ݸ������仯��С����ѧϰ�ʡ�
-
Adam: ���ڶ���������Ӧѧϰ�������Ż�˼·��������,��˿��Խ�����˼·�������,����ǵ�ǰ�㷺Ӧ�õ��㷨��
7����д����ʶ��֮��Դ����
��GPUѵ��
�ֲ�ʽѵ��
�ֲ�ʽѵ��������ʵ��ģʽ:
ģ�Ͳ���,��һ������ģ�Ͳ��Ϊ���,��ֺ��ģ�ͷֵ�����豸��(GPU)ѵ��,ÿ���豸��ѵ����������ͬ�ġ�������ģ�ͼܹ���������ģ�͵Ľṹ�����Զ����ij�����
���ݲ���,ÿ�ζ�ȡ�������,��ȡ�����������������豸(GPU)�ϵ�ģ��,ÿ���豸�ϵ�ģ������ȫ��ͬ��
ģ������ȫ��ͬ,�����������ݲ�ͬ,���ÿ���豸��ģ�ͼ�������ݶȲ�ͬ
�ݶ�ͬ��������֤ÿ���豸���ݶ�����ȫ��ͬ:PRCͨ�ŷ�ʽ��NCCL2ͨ�ŷ�ʽ
PRCͨ�ŷ�ʽͨ������CPU�ֲ�ʽѵ��,���������ڵ�:����������Parameter server��ѵ���ڵ�Trainer,parameter server�ռ�����ÿ���豸���ݶȸ�����Ϣ,�������һ��ȫ�ֵ��ݶȸ��¡�Trainer����ѵ��,ÿ��Trainer�ϵij�����ͬ,�����ݲ�ͬ����Parameter server�յ�����Trainer���ݶȸ�������ʱ,ͳһ����ģ�͵��ݶȡ�
�ɽ���GPU�ֲ�ʽѵ��ʹ�õ��ǻ���NCCL2��ͨ�ŷ�ʽ,���PRCͨ�ŷ�ʽ,ʹ��NCCL2(Collectiveͨ�ŷ�ʽ)���зֲ�ʽѵ��,����Ҫ����Parameter server����,ÿ��Trainer���̱���һ��������ģ�Ͳ���,������ݶȼ���֮��ͨ��Trainer֮����ͨ��,Reduce�ݶ����ݵ����нڵ�������豸,Ȼ��ÿ���ڵ��ڸ�����ɲ������¡�
���������
- ��ʼ�����л�����
- ʹ��paddle.DataParallel��װģ�͡�
������GPU��ѵ��,�����ַ�ʽ:
-
����launch����;
python train.py #������������,Ĭ��ʹ�õ�0�ſ��� python -m paddle.distributed.launch train.py #�����,Ĭ��ʹ�õ�ǰ�ɼ������п��� ython -m paddle.distributed.launch --gpus '0,1' --log_dir ./mylog train.py #���������,���õ�ǰʹ�õĵ�0�ź͵�1�ſ��� ���� export CUDA_VISIABLE_DEVICES='0,1' python -m paddle.distributed.launch train.py -
����spawn��ʽ������
# ����train�����ѵ��,Ĭ��ʹ�����пɼ���GPU���� if __name__ == '__main__': dist.spawn(train) # ����train����2������ѵ��,Ĭ��ʹ�õ�ǰ�ɼ���ǰ2�ſ��� if __name__ == '__main__': dist.spawn(train, nprocs=2) # ����train����2������ѵ��,Ĭ��ʹ�õ�4�ź͵�5�ſ��� if __name__ == '__main__': dist.spawn(train, nprocs=2, selelcted_gpus='4,5')
8����д����ʶ��֮ѵ���������Ż�
ѵ�������Ż�˼·��Ҫ����������ؼ�����:
8.1 �������ȷ��,�۲�ģ��ѵ��Ч����
��������ʧ����ֻ����Ϊ�Ż�Ŀ��,��ֱ��ȷ����ģ�͵�ѵ��Ч����ȷ�ʿ���ֱ�Ӻ���ѵ��Ч��,����������ɢ����,���ʺ���Ϊ��ʧ�����Ż������硣ͨ�������,��������ʧԽС��ģ��,�����ȷ��ҲԽ�ߡ����ڷ���ȷ��,���ǿ��Թ�ƽ�رȽ�������ʧ���������ӡ�
�����ڡ���д����ʶ��֮��ʧ�����½��о������ͽ����صıȽϡ�ʹ�÷ɽ��ṩ�ļ������ȷ��API,����ֱ�Ӽ���ȷ��:
class paddle.metric.Accuracy��API���������inputΪԤ��ķ�����predict,�������labelΪ������ʵ��label��
��ģ��ǰ��������forward�����м������ȷ��
8.2 ���ģ��ѵ������,ʶ��DZ��ѵ������
���ģ�͵���ʧ��������ָ������쳣,ͨ����Ҫ��ӡģ��ÿһ���������������λ����,�Լ�ÿ������IJ���,����ÿһ�����������ȡ�����ԭ��
ʹ��check_shape���������Ƿ��ӡ���ߴ硱,��֤����ṹ�Ƿ���ȷ��
ʹ��check_content���������Ƿ��ӡ������ֵ��,��֤���ݷֲ��Ƿ������
������ѵ���з����м��IJ����������Ϊ0,˵���ò��ֵ�����ṹ��ƴ�������,û�г�����á�
8.3 ����У������,��������ģ��Ч��
- У�鼯:���ڶ�ģ�ͳ�������ѡ��,��������ṹ�ĵ�����������Ȩ�ص�ѡ��ȡ�
8.4 ����������,����ģ�����
���������:��ѵ�����ϵ���ʧС,����֤������Լ��ϵ���ʧ�ϴ�֮,���ģ����ѵ�����Ͳ��Լ��Ͼ���ʧ�ϴ�,���ΪǷ��ϡ�
���¹����ԭ��:����ϱ�ʾģ��������,ѧϰ����ѵ�������е�һЩ���,����Щ��������ʵ�ķ�������,��Ҫ��ѵ��������̫�ٻ����е�����̫�ࡣ
����ϵij��������:
? ���1:ѵ�����ݴ�������,����ģ��ѧ��������,��������ʵ���ɡ�����ʹ��������ϴ�������������
? ���2:ʹ��ǿ��ģ��(��ʾ�ռ��)��ͬʱѵ������̫��,������ѵ�������ϱ������õĺ�ѡ����̫��,������һ���������ȷ���ļ��衣��������ģ�ͱ�ʾ����,�����ռ������ѵ�����ݡ�
������:
Ϊ�˷�ֹģ�����,��û�������������Ŀ�����,ֻ�ܽ���ģ�͵ĸ��Ӷ�,����ͨ�����Ʋ��������������ȡֵ(����ֵ����С)ʵ�֡�
������˵,��ģ�͵��Ż�Ŀ��(��ʧ)����Ϊ����Բ�����ģ�ijͷ��������Խ���ȡֵԽ��ʱ,�óͷ����Խ��ͨ�������ͷ����Ȩ��ϵ��,����ʹģ���ڡ���������ѵ����ʧ���͡�����ģ�͵ķ���������֮��ȡ��ƽ�⡣����������ʾģ����û�м�������������Ȼ��Ч��������Ĵ���,������ģ����ѵ�����ϵ���ʧ��
�ɽ�֧��Ϊ���в�������ͳһ��������,Ҳ֧��Ϊ�ض��IJ������������ǰ�ߵ�ʵ�����´�����ʾ,�����Ż���������weight_decay��������ʵ�֡�ʹ�ò���coeff�����������Ȩ��,Ȩ��Խ��ʱ,��ģ���Ӷȵijͷ�Խ�ߡ�
8.5 ���ӻ�����
- Matplotlib��:Matplotlib����Python��ʹ�õ�����2Dͼ�λ�ͼ��,����һ����ȫ����MATLAB�ĺ�����ʽ�Ļ�ͼ�ӿ�,ʹ����������PLT��(Matplotlib)��ͼ�Ƿdz��ġ�
- VisualDL:�������ʹ�ø���רҵ����ͼ����,���Գ���VisualDL,�ɽ����ӻ��������ߡ�VisualDL�ܹ���Ч��չʾ�ɽ������й����еļ���ͼ������ָ��仯���ƺ�������Ϣ��
9����д����ʶ��֮�ָ�ѵ��
ֻҪ��ʱ����ѵ�������е�ģ��״̬,��ʹѵ�������������ж�,Ҳ���ôӳ�ʼ״̬����ѵ����
ģ�ͻָ�ѵ��,��Ҫ��������,������Ҫ����AIStudio,����MnistDataset���ݶ�ȡ��MNIST���綨�塢Trainer���ִ���,��ִ��ģ�ͻָ�����
-
ʹ��
model.state_dict()��ȡģ�Ͳ����� -
ʹ��
opt.state_dict��ȡ�Ż�����ѧϰ����صIJ����� -
����
paddle.save���������浽���ء����ж�ģ���Ƿ�ȷ�Ļָ�ѵ����?����Ļָ�ѵ����ģ��״̬�ص�ѵ���жϵ�ʱ��,�ָ�ѵ��֮����ݶȸ��������Ǻͻָ�ѵ��ǰ���ݶ�������ȫ��ͬ�ġ����ڴ�,���ǿ���ͨ���ָ�ѵ�������ʧ�仯,�ж����������Ƿ���ȷ�Ļָ�ѵ��������epoch 0����ʱ�����ģ�Ͳ������Ż���״̬�ָ�ѵ��,У�����ѵ������ʧ�仯(epoch 1)�Ƿ�Ͳ��ж�ʱ��ѵ�����ࡣ
�ܽ�һ��:
- ����ģ��ʱͬʱ����ģ�Ͳ������Ż�������;
paddle.save(opt.state_dict(), 'model.pdopt')
paddle.save(model.state_dict(), 'model.pdparams')
- �ָ�����ʱͬʱ�ָ�ģ�Ͳ������Ż���������
model_dict = paddle.load("model.pdparams")
opt_dict = paddle.load("model.pdopt")
model.set_state_dict(model_dict)
opt.set_state_dict(opt_dict)
10 ����д����ʶ��֮��ת������
��̬ͼ ����ʽ���
��̬ͼ C++���� ��������
��̬ͼת��̬ͼѵ��
��̬ͼת��̬ͼѵ����ԭ����ͨ������Python����,����̬ͼ����תдΪ��̬ͼ����,���ڵײ��Զ�ʹ�þ�̬ͼִ�������С�
ʹ�÷���:��Ҫת���ĺ���(�ú���Ҳ�������û��Զ��嶯̬ͼLayer��forward����)ǰ����һ��װ���� @paddle.jit.to_static,ʹ��̬ͼ����ṹ�ھ�̬ͼģʽ�����С�
��̬ͼת��̬ͼģ�ͱ���
��̬ͼ�Ǽ�ʱִ�м�ʱ�õ����,�������¼ģ�͵Ľṹ��Ϣ����Ҫ�Ƚ���̬ͼģ��ת��Ϊ��̬ͼд��,����õ���Ӧ��ģ�ͽṹ�ٱ���
paddle.jit.save��paddle.jit.load�ӿ�
�����ļ�:����ģ�ͽṹ��.pdmodel�ļ�;���������ò�����.pdiparams�ļ��ͱ�����ݱ�����Ϣ��.pdiparams.info�ļ�*
paddle.jit.save API �����������洢Ϊ paddle.jit.TranslatedLayer ��ʽ��ģ��
it.to_static,ʹ��̬ͼ����ṹ�ھ�̬ͼģʽ�����С�
��̬ͼת��̬ͼģ�ͱ���
��̬ͼ�Ǽ�ʱִ�м�ʱ�õ����,�������¼ģ�͵Ľṹ��Ϣ����Ҫ�Ƚ���̬ͼģ��ת��Ϊ��̬ͼд��,����õ���Ӧ��ģ�ͽṹ�ٱ���
paddle.jit.save��paddle.jit.load�ӿ�
�����ļ�:����ģ�ͽṹ��.pdmodel�ļ�;���������ò�����.pdiparams�ļ��ͱ�����ݱ�����Ϣ��.pdiparams.info�ļ�*
paddle.jit.save API �����������洢Ϊ paddle.jit.TranslatedLayer ��ʽ��ģ��
paddle.jit.load�ӿ�,���Ѵ洢��ģ������Ϊ paddle.jit.TranslatedLayer��ʽ
paddlespeech����
1.��ʽ����ʶ�����
�����ʹ�÷���
�� PaddleSpeech/demos/streaming_asr_server Ŀ¼��������
paddlespeech_server start --config_file ./conf/ws_conformer_wenetspeech_application.yaml
ʹ�÷���:
paddlespeech_server start --help
����:
config_file: ����������ļ�,Ĭ��: ./conf/application.yaml
log_file: log �ļ�. Ĭ��:./log/paddlespeech.log
ע��:
Ĭ�ϲ����� cpu �豸��,����ͨ���ķ��������ļ��� device ���������� gpu �ϡ�
ASR �ͻ���ʹ�÷���
paddlespeech_client asr_online --server_ip 127.0.0.1 --port 8090 --input ./zh.wav
paddlespeech_client asr_online --help
����:
server_ip: �����ip��ַ,Ĭ��: 127.0.0.1��
port: ����˿�,Ĭ��: 8090��
input(��������): ����ʶ�����Ƶ�ļ���
sample_rate: ��Ƶ������,Ĭ��ֵ:16000��
lang: ģ������,Ĭ��ֵ:zh_cn��
audio_format: ��Ƶ��ʽ,Ĭ��ֵ:wav��
punc.server_ip ���Ԥ������ip��Ĭ����None��
punc.server_port ���Ԥ�����Ķ˿�port��Ĭ����None��
2.��ʽ�����ϳɷ���
ʹ��httpЭ�����ʽ�����ϳɷ���˼��ͻ���ʹ�÷���
���ն�:
paddlespeech_server start --config_file ./conf/tts_online_application.yaml
�͑���:
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input ������,��ӭʹ�ðٶȷɽ������ϳɷ��� --output output.wav
ʹ��websocketЭ�����ʽ�����ϳɷ���˼��ͻ���ʹ�÷���
�����������ļ� conf/tts_online_application.yaml, �� protocol ����Ϊ websocket��
paddlespeech_server start --config_file ./conf/tts_online_application.yaml
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8092 --protocol http --input ������,��ӭʹ�ðٶȷɽ������ϳɷ��� --output output.wav