HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions ECCV2022
程序
视觉 Transformers 的最新进展在基于点积 self-attention 的新空间建模机制驱动的各种任务中取得了巨大成功。在本文中,我们展示了视觉 Transformer 背后的关键要素,即输入自适应、远程和高阶空间交互,也可以通过基于卷积的框架有效实现。我们提出了递归门控卷积(gnConv),它通过门控卷积和递归设计执行高阶空间交互。新操作具有高度的灵活性和可定制性,它兼容各种卷积变体,并将自注意力中的二阶交互扩??展到任意阶,而不会引入大量额外的计算。 gnConv 可以作为一个即插即用的模块来改进各种视觉 Transformer 和基于卷积的模型。基于该操作,我们构建了一个新的通用视觉骨干家族,名为 HorNet。在 ImageNet 分类、??COCO 对象检测和 ADE20K 语义分割方面的大量实验表明,在整体架构和训练配置相似的情况下,HorNet 的性能明显优于 Swin Transformers 和 ConvNeXt。 HorNet 还显示出对更多训练数据和更大模型大小的良好可扩展性。除了在视觉编码器中的有效性外,我们还展示了 gnConv 可以应用于特定任务的解码器,并以更少的计算量持续提高密集预测性能。我们的结果表明,gnConv 可以成为一个新的视觉建模基础模块,它有效地结合了视觉 Transformer 和 CNN 的优点。代码可在 https://github.com/raoyongming/HorNet 获得。
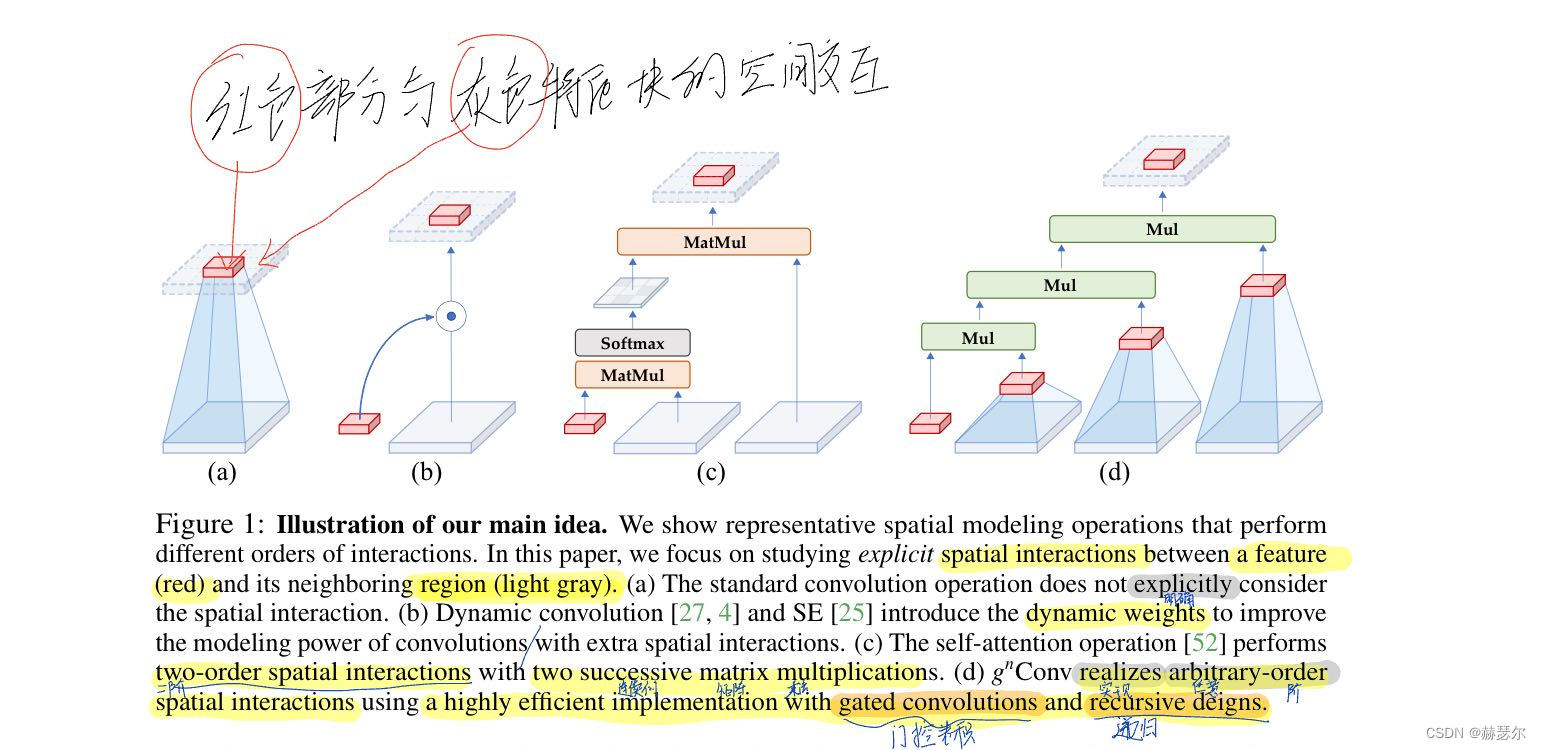
我们的主要思想的插图。我们展示了执行不同交互顺序的代表性空间建模操作。在本文中,我们专注于研究特征(红色)与其相邻区域(浅灰色??)之间的显式空间交互。 (a) 标准卷积运算没有明确考虑空间交互。 (b) 动态卷积 [27, 4] 和 SE [25] 引入了动态权重,以通过额外的空间交互来提高卷积的建模能力。 ? 自注意力操作 [52] 通过两个连续的矩阵乘法执行二阶空间交互。 (d) gnConv 使用具有门控卷积和递归设计的高效实现来实现任意阶空间交互。
Transformer[41] 对采用视觉 Transformer 的元架构来改进 CNN 进行了深入研究,并提出使用大型 7×7 内核来构建现代 CNN。 [44] 和 [14] 分别建议使用更大的内核来学习具有全局滤波器和高达 31×31 卷积的远程关系。 [20] 表明,输入自适应权重在视觉 Transformer 中起着关键作用,并与具有动态卷积的 Swin Transformer [4, 27] 实现了相似的性能。然而,尚未从高阶空间交互的角度分析点积自注意力在视觉任务中的有效性。
虽然由于非线性,在深度模型中的两个空间位置之间存在复杂且通常是高阶的交互,但自注意力和其他动态网络的成功表明,架构设计引入的显式和高阶空间交互有利于提高视觉模型的建模能力。如图 1 所示,普通卷积操作没有明确考虑空间位置(即红色特征)与其相邻区域(即浅灰色区域)之间的空间交互。动态卷积 [4, 27, 20] 等增强卷积操作通过生成动态权重引入了显式空间交互。 Transformers [52] 中的点积自注意力操作由两个连续的空间交互组成,通过在查询、键和值之间执行矩阵乘法。视觉建模的基本操作趋势表明,网络容量可以通过增加空间交互的阶数来提高。
在本文中,我们总结了视觉 Transformers 成功背后的关键因素是空间建模的新方法,该方法具有输入自适应、远程和高阶空间交互,由 self-attention 操作执行。虽然之前的工作已经成功地将视觉 Transformers 的元架构 [41、20、44、14]、输入自适应权重生成策略 [20] 和大范围建模能力 [44、14] 迁移到 CNN 模型,但更高阶的空间相互作用机制尚未研究。
我们表明,所有三个关键要素都可以使用基于卷积的框架有效地实现。我们提出了递归门控卷积(gnConv),它与门控卷积和递归设计执行高阶空间交互。 gnConv 不是简单地在 self-attention 中模仿成功的设计,而是有几个额外的优点:。
1)高效。基于卷积的实现避免了自注意力的二次复杂度。在执行空间交互期间逐渐增加通道宽度的设计也使我们能够实现具有有限复杂性的高阶交互;
2) 可扩展。我们将自注意力中的二阶交互扩??展到任意阶,以进一步提高建模能力。由于我们不对空间卷积的类型做出假设,因此 gnConv 兼容各种内核大小和空间混合策略,如 [44, 14];
3) 平移等变。 gnConv 完全继承了标准卷积的平移等效性,为主要视觉任务引入了有益的归纳偏差,并避免了局部注意力带来的不对称性 [40, 33]。
基于 gnConv,我们构建了一个新的通用视觉骨干家族,名为 HorNet。我们对 ImageNet 分类 [13]、COCO 对象检测 [37] 和 ADE20K 语义分割 [67] 进行了广泛的实验,以验证我们模型的有效性。凭借相同的 7×7 内核/窗口以及相似的整体架构和训练配置,HorNet 在不同复杂程度的所有任务上都大大优于 Swin 和 ConvNeXt。通过使用全局内核大小[44],可以进一步扩大差距。 HorNet 还显示出对更多训练数据和更大模型大小的良好可扩展性,在 ImageNet 上达到 87.7% 的 top-1 准确率,在 ADE20K val 上达到 54.6% mIoU,在使用 ImageNet-22K 预训练的 COCO val 上达到 55.8% 的边界框 AP。除了在视觉编码器中应用 gnConv 之外,我们还进一步测试了我们设计在特定任务解码器上的通用性。通过将 gConv 添加到广泛使用的特征融合模型 FPN [35] 中,我们开发了 HorFPN 来建模来自不同层次级别的特征的高阶空间关系。我们观察到 HorFPN 还可以以较低的计算成本持续改进各种密集预测模型。我们的结果表明,gnConv 可以成为视觉建模中自我注意的一种有前途的替代方案,并有效地结合了视觉 Transformer 和 CNN 的优点。
3.1 gnConv:递归门控卷积
在本节中,我们将介绍 gnConv,这是一种实现长期和高阶空间交互的有效操作。 gnConv 是使用标准卷积、线性投影和元素乘法构建的,但具有与自注意力相似的输入自适应空间混合功能。
与门控卷积的输入自适应交互:视觉变形金刚最近的成功主要取决于对视觉数据中空间交互的正确建模。与简单地使用静态卷积核聚合相邻特征的 CNN 3 不同,视觉 Transformer 应用多头自注意力来动态生成权重以混合空间标记。然而,二次复杂度w.r.t。自注意力的输入大小在很大程度上阻碍了视觉转换器的应用,尤其是在需要更高分辨率特征图的分割和检测等下游任务上。在这项工作中,我们没有像以前的方法 [40,9,53] 那样降低自注意力的复杂性,而是寻求一种更有效的方法来通过卷积和全连接层等简单操作执行空间交互。
我们方法的基本操作是门控卷积(gConv)。设 x ∈ RHW ×C 为输入特征,门控卷积的输出 y =gConv(x) 可以写成:

与大内核卷积的长期交互。视觉 Transformer 和传统 CNN 之间的另一个区别是感受野。传统的 CNN [47, 22] 通常在整个网络中使用 3×3 卷积,而视觉变换器在整个特征图 [16, 50] 或相对较大的局部窗口(例如 7×7)内计算自注意力。视觉 Transformers 的大感受野更容易捕捉长期依赖关系,这也被认为是视觉 Transformers 的关键优势之一。受这种设计的启发,最近有一些努力将大核卷积引入 CNN [14,41,44]。为了使我们的 gnConv 能够捕获长期交互,我们对深度卷积 f 采用了两种实现:
1)7×7 卷积。 7×7 是 Swin Transformers [40] 和 ConvNext [41] 的默认窗口/内核大小。 [41] 中的研究表明,内核大小在 ImageNet 分类和各种下游任务上产生了良好的性能。我们遵循这种配置来公平地与视觉变形金刚和现代 CNN 的代表性工作进行比较。
? 2)全局过滤器(GF)。 GF层[44]将频域特征与可学习的全局滤波器相乘,这相当于空间域中的卷积,具有全局内核大小和圆形填充。我们使用 GF 层的修改版本,使用全局滤波器处理一半通道,另一半使用 3×3 深度卷积处理,并且仅在后期使用 GF 层以保留更多局部细节。
视觉模型中的空间交互。我们从空间交互的角度回顾了一些具有代表性的视觉模型设计,如图 1 所示。具体来说,我们对特征 xi 与其相邻特征 xj 之间的交互感兴趣,j ∈ Ωi。通过使用 [32, 1] 中为解释交互效应 (IE) 而设计的工具,我们在附录 B 中提供了对显式空间交互顺序的直观分析。我们的分析揭示了视觉 Transformer 与以前的架构之间的关键区别。新视图,即视觉变形金刚在每个基本块中都有高阶空间交互。这一结果启发我们探索一种能够实现更高效、更有效的空间交互的架构,其中包含两个以上的订单。如上所述,我们提出的 gnConv 可以实现具有有限复杂度的任意阶交互。还值得注意的是,类似于深度模型中的其他比例因子,如宽度 [65] 和深度 [22],简单地增加空间交互的顺序而不考虑整体模型容量不会导致良好的权衡 [49] .在本文中,我们专注于基于对精心设计的模型的空间交互顺序的分析,开发更强大的可视化建模架构。我们相信对高阶空间相互作用进行更彻底和正式的讨论可能是未来的一个重要方向。
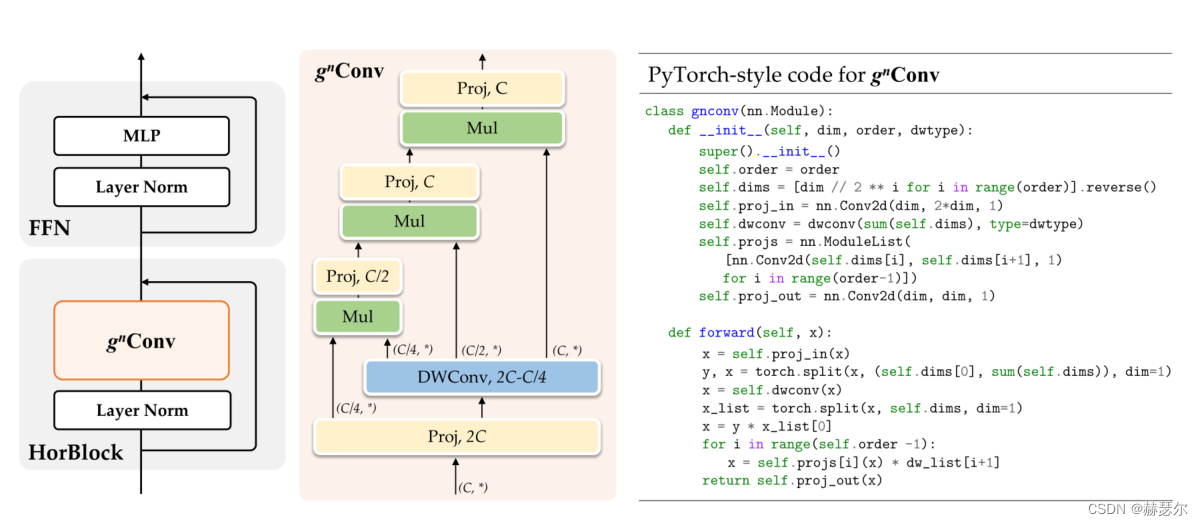
图 2:使用 gnConv 概述 HorNet 中的基本构建块。我们采用 Transformers [52] 的块设计,并用 gnConv 替换自注意力子层来开发我们的 HorNet(左)。我们还提供了 g3Conv 的详细实现(中)和任意顺序的 Pytorch 样式代码(右)。
3.2 Model Architectures
HorNet。 gnConv 可以替代视觉 Transformers [50, 40] 或现代 CNN [41] 中的空间混合层。我们遵循与 [52, 40] 相同的元架构来构建 HorNet,其中基本块包含空间混合层和前馈网络 (FFN)。根据模型大小和我们 gnConv 中深度卷积 fk 的实现,我们有两个系列的模型变体,分别称为 HorNet-T/S/B/L7×7 和 HorNet-T/S/B/LGF。我们将流行的 Swin Transformer [40] 和 ConvNeXt [41] 作为视觉 Transformer 和 CNN 基线,因为我们的模型是基于基于卷积的框架实现的,同时具有像视觉 Transformer 这样的高阶交互。为了与基线进行公平比较,我们直接遵循 Swin Transformers-S/B/L [40] 的块数,但在第 2 阶段插入一个额外的块以使整体复杂度接近,从而得到 [2, 3, 18 , 2] 所有模型变体中每个阶段的块。我们简单地调整基础通道数 C 来构建不同大小的模型,并按照惯例将 4 个阶段的通道数设置为 [C, 2C, 4C, 8C]。对于 HorNet-T/S/B/L,我们分别使用 C = 64、96、128、192。我们将每个阶段的交互顺序(即 gnConv 中的 n)默认设置为 2,3,4,5,使得最粗阶 C0 的通道在不同阶段是相同的
HorFP:除了在视觉编码器中使用 gnConv 之外,我们发现我们的 gnConv 可以成为标准卷积的增强替代方案,该标准卷积考虑了各种基于卷积的模型中的高阶空间交互。因此,我们用我们的 gnConv 替换 FPN [36] 中用于特征融合的空间卷积,以改善下游任务的空间交互。具体来说,我们在融合了不同金字塔级别的特征之后添加了我们的 gnConv。对于目标检测,我们将自顶向下路径之后的 3×3 卷积替换为每个级别的 gnConv。对于语义分割,我们只需将多级特征图连接后的 3×3 卷积替换为 gnConv,因为最终结果是直接从该连接特征预测的。我们还有两个实现,称为 HorFPN7×7 和 HorFPNGF,由 fk 的选择决定。
5 结论 我们提出了递归门控卷积 (gnConv),它与门控卷积和递归设计执行高效、可扩展和平移等变的高阶空间交互。 gnConv 可以作为各种视觉 Transformer 和基于卷积的模型中空间混合层的替代品。基于该操作,我们构建了一个新的通用视觉骨干系列 HorNet。大量实验证明了 gnConv 和 HorNet 在常用视觉识别基准上的有效性。我们希望我们的尝试能够激发未来的工作,以进一步探索视觉模型中的高阶空间交互。