今天是100天计划的第31天,关于“AI智能量化,财富自由与个人成长”相关。
由于篇幅问题,后续“财富自由与个人成长”这个部分会独立成文,成体系。
这个百天计划,来自“持续行动”里的一个“N阶行动”的概念,就是10的N次方天,100天差不多三个月,可以实现一个小目标;
1000天差不多3年,足以让你在一个领域斩露头角。
过去的30天,我们完成了qlib的学习,这是微软开发和维护的一个智能量化的框架,接下来的这个30天,我们重点关注AI部分,就是AI如何从数据中提供知识,支持决策。
对于表格化的数据,gdbt是一个很好的工具。
我们结合kaggle比赛的真实案例,看gbdt如何使用数据来生成决策模型,进而后面我们把模型思路应用到qlib上做金融数据的建模。
01 数据预处理
业务数据复杂,不完整,以及异常值我们都需要自己处理。
非数值型的数据是无法直接参与模型训练的,需要把非数值型,转为数值型,比如离散的,使用字典编码等。
这个案例里的数据集,交易记录超过3000万条,200多M,在pandas单机计算,笔记本的内存(16G)已经有点吃不消了。
02 特征工程与特征选择
特征选择有一个比较简单的办法,就是特征与label的相关性(金融上就是IC值),选择ic值高的进行建模。
03 参数优化框架
参数优化有网络搜索,hyperopt和beyesian。
04? 时间序列
时间序列数据比之传统的表格数据,多了一个时间维度,信息更加丰富,除了树模型,像深度神经网络,CNN/LSTM都有了用武之地。
阿里天池有一个比赛,“预测地铁乘客流量”。
这个题目很有实际意义,因为超大城市,对地铁站的流量有预判,对于风险预警,防控,解决安全隐患有重大作用。
仔细读了kaggle关于这个案例的代码,对于数据预处理占了太大的篇幅,其次是针对性的“特征工程”。关于模型和参数优化的反倒不多。
进一步也验证了,如何获得高质量的数据和因子(也就是策略),比算法模型更为重要。
05 模型篇
qlib把前沿的模型基本都覆盖全了,而且还带来alpha158和alpha360两个因子库。

我们需要先把这些benchmark作为baseline跟通,然后在这之上做我们的优化,比如参数调优,或者补充新的alpha因子。
model的初始化与超参数都比较简单:
def load_lightGBM():
from qlib.contrib.model.gbdt import LGBModel
config ={
"loss": "mse",
"colsample_bytree": 0.8879,
"learning_rate": 0.2,
"subsample": 0.8789,
"lambda_l1": 205.6999,
"lambda_l2": 580.9768,
"max_depth": 8,
"num_leaves": 210,
"num_threads": 20,
}
model = LGBModel(**config)
return model
qlib内置了数据处理器alpha158,一共158个因子。
def load_alpha158_handler():
from qlib.contrib.data.handler import Alpha158, Alpha360
config={
"start_time": "2008-01-01",
"end_time": "2020-08-01",
#训练周期
"fit_start_time": "2008-01-01",
"fit_end_time": "2014-12-31",
"instruments": "csi300",
}
handler = Alpha158(config)
return handler
300支股票,158个因子,计算量比较大,需要把dataset缓存下来。
filename = 'alpha158_300.pkl'
if os.path.exists(filename):
with open(filename, "rb") as file_dataset:
ds = pickle.load(file_dataset)
else:
alpha158 = load_alpha158_handler()
print(alpha158)
ds = load_dataset(alpha158)
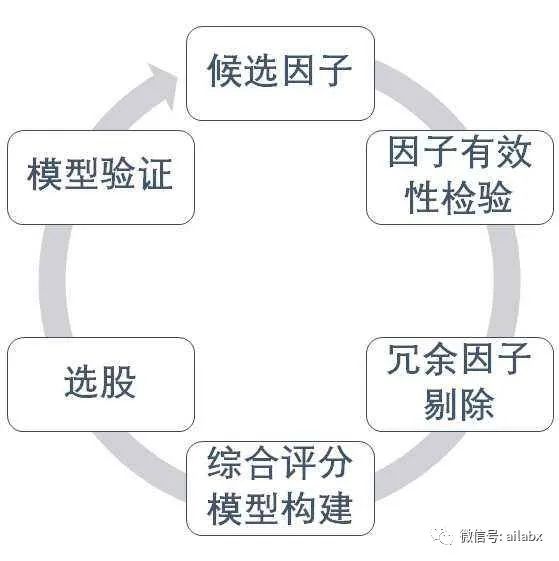
小结一下:
今天用kaggle案例分析,耽误了一点时间。
一是内存不足,二是kaggle的案例多花在数据预处理上,与我们金融量化参考价值有限。
明天回归到qlib因子,模型本身。