ТлЮФЕижЗ:https://arxiv.org/pdf/2010.00904.pdf
ЯрЙиТлЮФ
ЁОздШЛгябдДІРэЁПЁОМьЫїЁПGENER:здЛиЙщЪЕЬхМьЫї
ЁОздШЛгябдДІРэЁПЁОЯђСПМьЫїЁПУцЯђПЊЗХгђГэУмМьЫїЕФЖрЪгНЧЮФЕЕБэЪОбЇЯА
ЁОздШЛгябдДІРэЁПЁОЖдБШбЇЯАЁПSimCSE:ЛљгкЖдБШбЇЯАЕФОфЯђСПБэЪО
вЛЁЂМђНщ
? ЭЈЙ§здШЛгябдРДДгДѓаЭжЊЪЖПтжаМьЫїе§ШЗЪЕЬхЕФФмСІ,ЪЧвЛаЉгІгУЕФЛљДЁФмСІЁЃДѓЖрЪ§ЕФЩЬвЕЭЦМіЯЕЭГЖМашвЊЖдЮФБОжаЕФЪЕЬхmentionНјааМьВтКЭЯћЦчЁЃСэвЛИіР§згЪЧСФЬьЛњЦїШЫКЭЮЪД№ЯЕЭГ,ЦфЭЈГЃЛсХфБИвЛаЉМьЫїзщМўгУРДЛёШЁЮЌГжЖдЛАЛђепЛиД№ЮЪЬтЕФ
KB
\text{KB}
KBЬѕФПЁЃ
? ЫфШЛЯШЧАгаДѓСПЕФЪЕЬхМьЫїЙЄзї,ЕЋЪЧетаЉЙЄзїЖМгавЛИіЙВЭЌЕФЩшМЦбЁдё:ЪЕЬхЛсБЛЙиСЊЕНЮЈвЛЕФБъЧЉ,ВЂЧвМьЫїЮЪЬтБЛНЈФЃЮЊетаЉБъЧЉЩЯЕФЖрЗжРрЮЪЬтЁЃЪфШыЮФБОКЭБъЧЉЕФЦЅХфЪЧЭЈЙ§вЛИіbi-encoderМЦЫуЕФ,МДЪфШыЮФБОЕФЯђСПгыЪЕЬхдЊаХЯЂжЎМфЕФЕуЛ§ЁЃетбљЕФаЮЪНПЩвдЪЙгУЯжДњЕФзюДѓФкЛ§ЫбЫїПтРДДяЕНДЮЯпадЕФЫбЫїаЇТЪЁЃ
? ЕЋЪЧ,етбљЕФЗНЪНвВгаМИИіШБЕуЁЃЪзЯШ,Г§ЗЧЪЙгУАКЙѓЕФcross-encoderНјааre-ranking,ЗёдђЕуЛ§ЕФЗНЪНЛсШБЩйЪфШыКЭЪЕЬхдЊаХЯЂМфЕФЯИСЃЖШНЛЛЅЁЃЕкЖў,ЮЊећИі
KB
\text{KB}
KBДцДЂЯђСПашвЊДѓСПЕФДцДЂПеМф,ВЂЧвЛсЫцзХаТЪЕЬхЕФдіМгЖјЯпаддіМгЁЃЕкШ§ЁЂдкЫљгаЪЕЬхЩЯМЦЫувЛИіОЋШЗЕФsoftmaxЪЧЗЧГЃАКЙѓЕФ,ЕБЧАЕФНтОіЗНАИЖМЪЧашвЊЖдИКбљБОНјааЯТВЩбљЕФЁЃЕїгХвЛзщЪЪЕБЕФФбИКбљБОЪЧОпгаЬєеНЧвКФЪБЕФЁЃзюКѓ,ЯЕЭГЛсдтЪмРфЦєЖЏЮЪЬт,вђЮЊЦфВЂВЛФмБэЪОГіФЧаЉУЛгаЪеМЏЕНГфЗжаХЯЂЕФЪЕЬх,БШШчЪЕЬхЕФЮФБОУшЪіЛђепЪЕЬхЕФвЛзщЙиЯЕЁЃ
? БОЮФзїепЬсГіСЫ
GENER(Generative?ENtitiy?REtrieval)
\text{GENER(Generative ENtitiy REtrieval)}
GENER(Generative?ENtitiy?REtrieval)ЁЃЕквЛИіРћгУsequence-to-sequenceМмЙЙВЂЛљгкЩЯЯТЮФздЛиЙщЗНЪНЩњГЩЪЕЬхУћГЦЕФЪЕЬхМьЫїЦїЁЃОпЬхЕи,
GENER
\text{GENER}
GENERРћгУЮЂЕї
BART
\text{BART}
BARTРДЩњГЩЪЕЬхУћГЦЁЃетжжМмЙЙФмЙЛБЃСєвЛЖЈГЬЖШЩЯБЃСєЪТЪЕжЊЪЖКЭгябдЗвыММЧЩ,етгажњгкЪЕЬхМьЫїЦїЁЃЕБШЛ,ЩњГЩЕФЪфГіПЩФмВЛзмЪЧгааЇЕФЪЕЬхУћГЦЁЃЮЊСЫНтОіетИіЮЪЬт,
GENER
\text{GENER}
GENERРћгУвЛИідМЪјНтТыЦїРДЧПжЦЩњГЩЕФУПИіУћзждкдЄЖЈвхЕФКђбЁМЏжаЁЃ
? здЛиЙщЕФаЮЪНПЩвджБНгВЖЛёЩЯЯТЮФКЭЪЕЬхУћГЦЕФЙиЯЕ,ВЂЧвФмЙЛЖдЩЯЯТЮФКЭЪЕЬхУћГЦНјаагааЇЕФНЛЛЅЁЃДЫЭт,ЫљашЕФДцДЂПеМфвВБШЕБЧАЕФЯЕЭГаЁКУМИИіЪ§СПМЏ,вђЮЊsequence-to-sequenceФЃаЭЕФВЮЪ§СПгыДЪБэЕФДѓаЁЯпадЯрЙи,ЖјВЛЪЧЪЕЬхЪ§СПЁЃеыЖдУПИіЪфГіЕФtokenЕФsoftmaxПЩвдБЛИпаЇМЦЫу,ДгЖјВЛашвЊНјааИКбљБОЯТВЩбљЁЃзюКѓ,
GENER
\text{GENER}
GENERВЛашвЊЗУЮЪЪЕЬхЕФШЮКЮдЊаХЯЂ,вђДЫаТЪЕЬхПЩвдЭЈЙ§ЯђКђбЁМЏЬэМгЮоЦчвхЕФУћГЦЁЃ
? зїепдкШ§жжШЮЮёЕФ20ИіЪ§ОнМЏЩЯЦРЙРСЫ
GENER
\text{GENER}
GENER:(1) ЪЕЬхЯћЦч;(2) ЖЫЕНЖЫЪЕЬхСДНг;(2) ЮФЕЕМьЫїЁЃБОЮФЕФЗНЗЈМИКѕдкЫљгаЪ§ОнМЏЩЯЖМЪЕЯжСЫstate-of-the-artЛђепЗЧГЃгаОКељСІЕФНсЙћЁЃДЫЭт,ЯрБШгкНќЦкЕФЗНЗЈ,
GENER
\text{GENER}
GENERашвЊИќЩйЕФДцДЂПеМф(ЦНОљаЁгк20БЖ)ЁЃ
ЖўЁЂЪЕЬхМьЫї
? МйЩшгавЛИіЪЕЬхМЏКЯ
E
\mathcal{E}
E,ЦфжаУПИіЪЕЬхЖМЪЧвЛИіжЊЪЖПтжаЕФЬѕФП(entry)ЁЃБОЮФвЊНтОіЕФЮЪЬтЪЧ:ИјЖЈвЛИіЮФБОЪфШыдД
x
x
x,вЛИіФЃаЭФмЙЛДг
E
\mathcal{E}
EжаЗЕЛигы
x
x
xзюЯрЙиЕФЪЕЬхЁЃМйЩшУПИі
e
ЁЪ
E
e\in\mathcal{E}
eЁЪEЛсБЛЗжХфвЛИіЮЈвЛЕФЮФБОБэЪО:вЛИіtokensађСа
y
y
yЁЃ
? ИУЮЪЬтЕФвЛИіЪЕР§ЪЧЪЕЬхЯћЦч
(Entity?Disambiguation,ED)
\text{(Entity Disambiguation,ED)}
(Entity?Disambiguation,ED),ИјЖЈвЛИіБЛБъзЂСЫmentionЕФЪфШыЮФБО
x
x
x,ЯЕЭГашвЊДг
E
\mathcal{E}
EжабЁдёГіmentionЖдгІЕФЪЕЬхЁЃСэвЛИіЪЕР§ЪЧЮФЕЕМьЫїЮФЕЕМьЫї
(Document?Retrieval,DR)
\text{(Document Retrieval,DR)}
(Document?Retrieval,DR),НЋЪфШыЮФБО
x
x
xзїЮЊquery,
E
\mathcal{E}
EЪЧЮФЕЕМЏКЯЁЃ
Ш§ЁЂЗНЗЈ
? БОЮФЭЈЙ§sequence-to-sequenceФЃаЭРДЩњГЩЪЕЬхЕФЮФБОБъЪЖЗћ,ДгЖјНтОіМьЫїЮЪЬтЁЃОпЬхРДЫЕ,
GENER
\text{GENER}
GENERЭЈЙ§вЛИіздЛиЙщЕФаЮЪНМЦЫувЛИіЗжЪ§,ШЛКѓРћгУЗжЪ§РДХХађ
e
ЁЪ
E
e\in\mathcal{E}
eЁЪE:
score
(
e
ЈO
x
)
=
p
ІШ
(
y
ЈO
x
)
=
ЁЧ
i
=
1
N
p
ІШ
(
y
i
ЈO
y
<
i
,
x
)
\text{score}(e|x)=p_\theta(y|x)=\prod_{i=1}^N p_\theta(y_i|y_{<i},x)
score(eЈOx)=pІШ?(yЈOx)=ЁЧi=1N?pІШ?(yi?ЈOy<i?,x),Цфжа
y
y
yЪЧ
e
e
eЕФБъЪЖЗћжа
N
N
NИіtokenЕФМЏКЯ,
ІШ
\theta
ІШЪЧФЃаЭВЮЪ§ЁЃ
GENER
\text{GENER}
GENERРћгУЮЂЕїЕФ
BART
\text{BART}
BARTдЄбЕСЗгябдФЃаЭ,ВЂЪЙгУБъзМЕФseq2seqФПБъКЏЪ§,МДзюДѓЛЏЪфГіађСаЕФЫЦШЛКЏЪ§ЁЂДјdropoutЕФе§дђЛЏКЭБъЧЉЦНЛЌЁЃОпЬхРДЫЕ ,ФПБъКЏЪ§ЪЧЕфаЭЕФЛњЦїЗвы,зюДѓЛЏ
log
?
p
ІШ
(
y
ЈO
x
)
\log p_\theta(y|x)
logpІШ?(yЈOx)ЁЃгЩгкВЩгУСЫвђзгЗжНт,ПЩвдБЛгааЇЕФМЦЫуЁЃ
1. ЛљгкдМЪј Beam?Search \text{Beam Search} Beam?Search
? дкВтЪдЪБ,ПЩвдМЦЫу
E
\mathcal{E}
EжаУПИідЊЫиЕФЦРЗжВЂНјааХХађЁЃВЛавЕФЪЧ,ЕБ
E
\mathcal{E}
EЬЋДѓЪБЦфПЩФмМЦЫуЬЋАКЙѓЁЃвђДЫ,зїепРћгУ
Beam?Search(BS)
\text{Beam Search(BS)}
Beam?Search(BS),вЛжжФмЙЛгааЇМьЫїЫбЫїПеМфжаНќЫЦНтТыВпТд ЁЃЯрБШгкЖд
E
\mathcal{E}
EжаЫљгаЪЕЬхНјааОЋШЗЕФЦРЗж,БОЮФЪЙгУОпга
k
k
kИіbeamsЕФ
BS
\text{BS}
BSРД
E
\mathcal{E}
EжаЫбЫїГі
top-k
\text{top-k}
top-kИіЪЕЬхЁЃзЂвт,ЪЙгУ
BS
\text{BS}
BSвтЮЖзХМьЫїЦїЕФЪБМфДњМлВЛвРРЕгк
E
\mathcal{E}
EЕФДѓаЁ,ЖјЪЧbeamsЕФГпДчКЭздЛиЙщЩњГЩЪЕЬхБэЪОЕФЦНОљГЄЖШЁЃЭЈГЃЪЕЬхБэЪОЕФЦНОљГЄЖШВЛЬЋГЄ,ВЂЧвБОЮФЪЙгУБъзМ
NMT
\text{NMT}
NMTЩшЖЈ,МД
k
k
kКмаЁЁЃ
? вђЮЊашвЊЪфГі
E
\mathcal{E}
EжаЕФЪЕЬх,ЫљвдВЛФмЪЙгУДЋЭГЕФ
BS
\text{BS}
BSНјааНтТыЁЃШЗЪЕ,дкУПИіНтТыВНжшжадЪаэЩњГЩДЪБэжаЕФШЮвтtokenПЩФмЛсЕМжТФЃаЭЩњГЩЕФзжЗћДЎВЂВЛЪЧгааЇЕФБъЪЖЗћЁЃвђДЫ,етРяЧѓжњгкдМЪј
BS
\text{BS}
BS,ЧПжЦНіНтТыГігааЇЕФБъЪЖЗћЁЃдкНтТыЙ§ГЬжа
BS
\text{BS}
BSНіФмПМТЧЧАвЛВН,вђДЫжЛФмЛљгкЩЯвЛИіtokenРДдМЪјЩњГЩЕБЧАЕФtokenЁЃзїепЪЙгУЧАзКЪї
T
\mathcal{T}
TРДЖЈвхдМЪј,ЪїжаЕФУПИіНкЕуЖМЪЧРДздгкДЪБэЁЃ
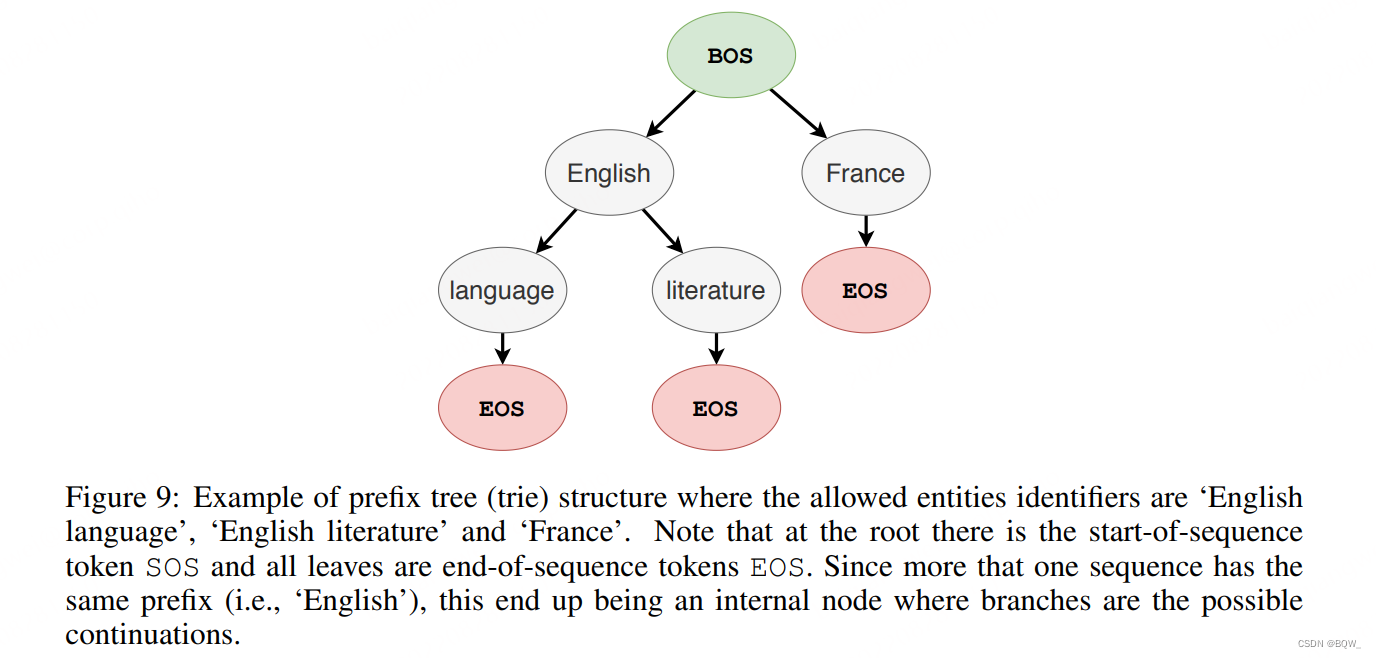
? ЩЯЭМЪЧвЛИіЧАзКЪї
(trie)
\text{(trie)}
(trie)ЕФР§згЁЃЕБЪфГіЕФЪ§СППЩПи,дђ
trie
\text{trie}
trieЯрЖдНЯаЁ,ПЩвдЬсЧАдЄМЦЫуВЂДцДЂдкФкДцжаЁЃЪЙгУдМЪјРДекБЮЮоаЇtokensЕФЖдЪ§ИХТЪ,ЖјВЛЪЧlogitsЁЃ
2. здЛиЙщЖЫЕНЖЫЪЕЬхСДНг

? БОЮФРЉеЙСЫздЛиЙщПђМмРДНтОіЖЫЕНЖЫЕФЪЕЬхСДНг
(Entity?Linking,EL)
\text{(Entity Linking,EL)}
(Entity?Linking,EL)ЁЃИјЖЈвЛИіЮФЕЕ,ЯЕЭГБиаыМьЫїГіЪЕЬхЬсМА,ВЂНЋетаЉЪЕЬхЬсМАСДНгжСжЊЪЖПтжаЕФЪЕЬхЁЃдкетжжЩшЖЈЯТ,ФЃаЭашвЊдЄВтДјгаБъзЂspanЕФдЪМЪфШы ,ВЂЪЙгУЬиЪтЕФtokensРДБъМЧspansЕФБпНчЁЃ
? ДјгаБъзЂЕФЪфГіПеМфЪЧжИЪ§МЖЕФДѓЁЃвђДЫ,дЄМЦЫувЛИіtrieгУгкНтТыЪЧЪЎЗжРЇФбЕФ,ЫљвдИФЮЊЖЏЬЌМЦЫуЁЃЩЯЭМеЙЪОСЫвЛИіР§зг ЁЃдкУПИіЩњГЩВНжшжа,НтТыЦївЊУДЩњГЩвЛИіmention spanЁЂвЊУДЩњГЩвЛИіmentionСДНгЁЂвЊУДМЬајЪфГіЪфШыдДЁЃЕБЩњГЩВНжшДІгкmentionЛђепentityжЎЭт,НтТыЦїНігаСНИібЁдё:(1) МЬајДгЪфШыдДПНБДЯТвЛИіtoken;(2) ЩњГЩвЛИіmentionЕФПЊЪМЗћ(Р§Шч[),ЦфЛсЪЙНтТыЦїНјШыmentionЩњГЩНзЖЮЁЃЕБДІгкЩњГЩmentionЪБ,НтТыЦїПЩвдДгЪфШыдДжаМЬајИДжЦЯТвЛИіtoken,ЛђепЪЧжБНгЩњГЩmentionЕФНсЪјЗћ(]),етЛсЪЙНтТыЦїНјШыЪЕЬхЩњГЩНзЖЮЁЃзюКѓ,ЕБДІгкЩњГЩЪЕЬхНзЖЮ,НтТыЦїЛсРћгУtrieКЭдМЪјBeam SearchЪЙЦфФмЙЛЪфГігааЇЕФЪЕЬхБъЪЖЗћЁЃ
ЫФЁЂЪЕбщ
-
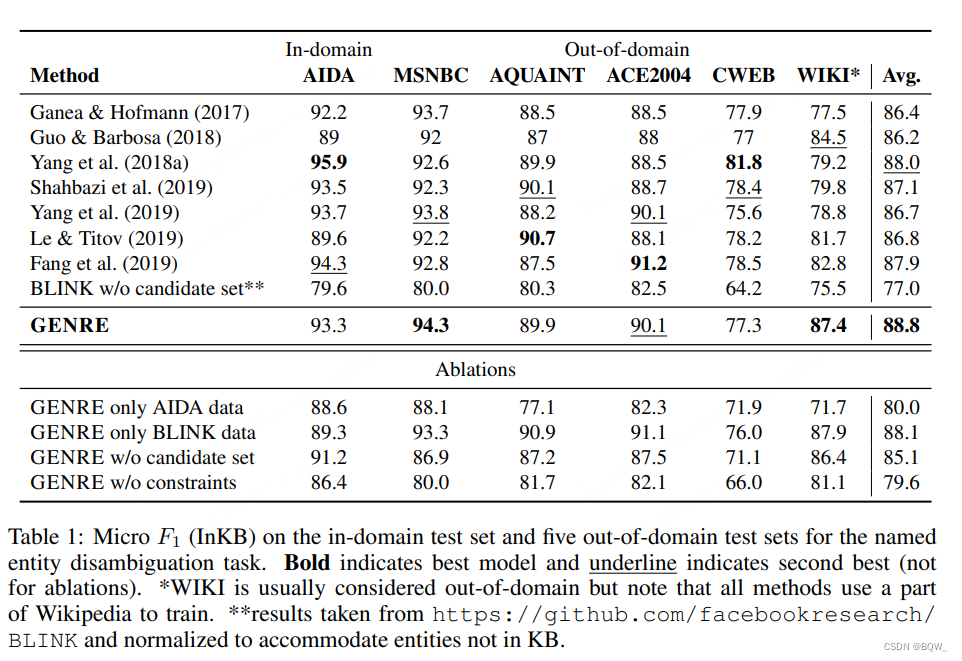
ЪЕЬхЯћЦч(Entity Disambiguation, ED)
-
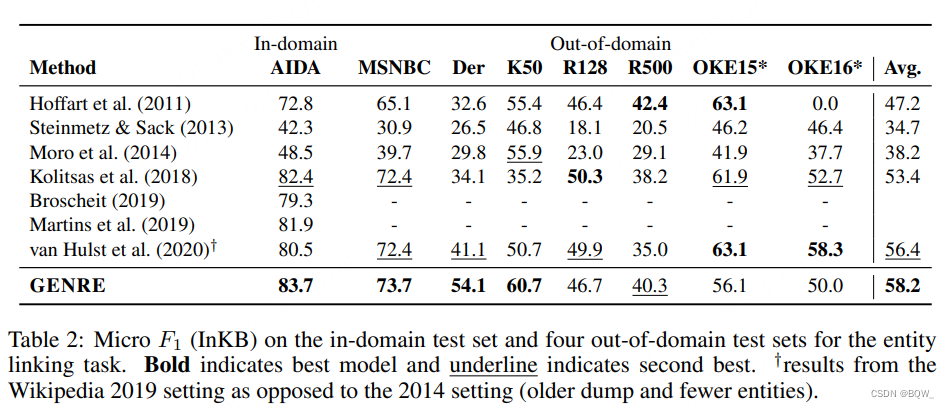
ЖЫЕНЖЫЪЕЬхСДНг(End-to-End Entity Linking, EL)
- вГМЖЮФЕЕМьЫї(Page-level Document Retrieval, DR)