Ӣ����Ŀ:DKPLM: Decomposable Knowledge-enhanced Pre-trained Language Model for Natural Language Understanding
������Ŀ:DKPLM:�ɷֽ������֪ʶ��ǿ��Ԥѵ������ģ��
���ĵ�ַ:https://arxiv.org/abs/2112.01047
����:��Ȼ���Դ���, ֪ʶͼ��
����ʱ��:2021.12
����:Taolin Zhang��,����ʦ����ѧ,�����Ŷ�
����:AAAI-2022
���������:https://github.com/alibaba/EasyNLP(������EasyNLP)
�Ķ�ʱ��:2022.09.11
�����
��Ȼ���Ժ�֪ʶͼ��ϵ�һ���³���,�����Ż������Ƚ�����˼�����������Գ�β��Ϣ�ķ���,����������:��ʹ���ලѧϰ�������,ҲҪ����ʹ����Ҫ������ѵ��ģ�͡�����,�������˾��巽��,����ʵ�����Ƶ�ʸ��ھ�ֵ,���������
����
����֪ʶ��ǿ����Ȼ����ģ�ͼ��KEPLM,����֪ʶͼ�е���Ԫ��ע��NLPģ��,������ģ�Ͷ����Ե�������������ģ��ʹ��ʱ��Ҫ֪ʶ�����ͱ���,��������
��������ɷֽ��֪ʶ��ǿ��ΪDKPLM,���巽����ʹ�ó�βʵ����Ϊ֪ʶע���Ŀ��,����ѵ��ʱ������ؽ�֪ʶ��Ԫ���֪ʶ����������ֻ��Ԥ��ѵ��ʱע����֪ʶ,�ھ���ģ�ͺ�Ԥ��ʱ�÷���BERTһ��,��Խ�ʡ��Դ����ͼ-1��ʾ:
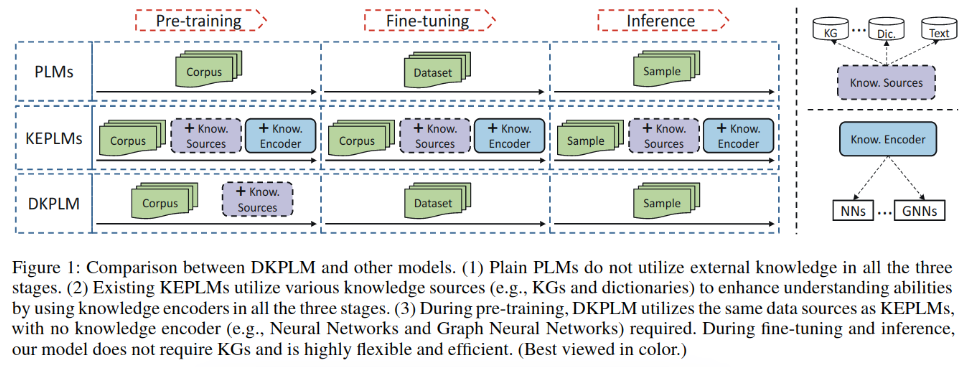
��Ԥѵ��ʱʹ��������Ҫ����:
- ����֪ʶ�ij�βʵ��̽��
- ����֪ʶͼ����Ԫ������αʵ���滻��βʵ��ѵ��ģ��,ģ���������Ӳ�����
- ������Ԫ���еĹ�ϵ,ͨ����ʵ�弰��ν���������Ӧʵ���е�ÿ��token��
ʵ��֤������zero_shot����,�Լ�Ԥ���ٶȶ�������������
����
����ܹ���ͼ-2��ʾ:
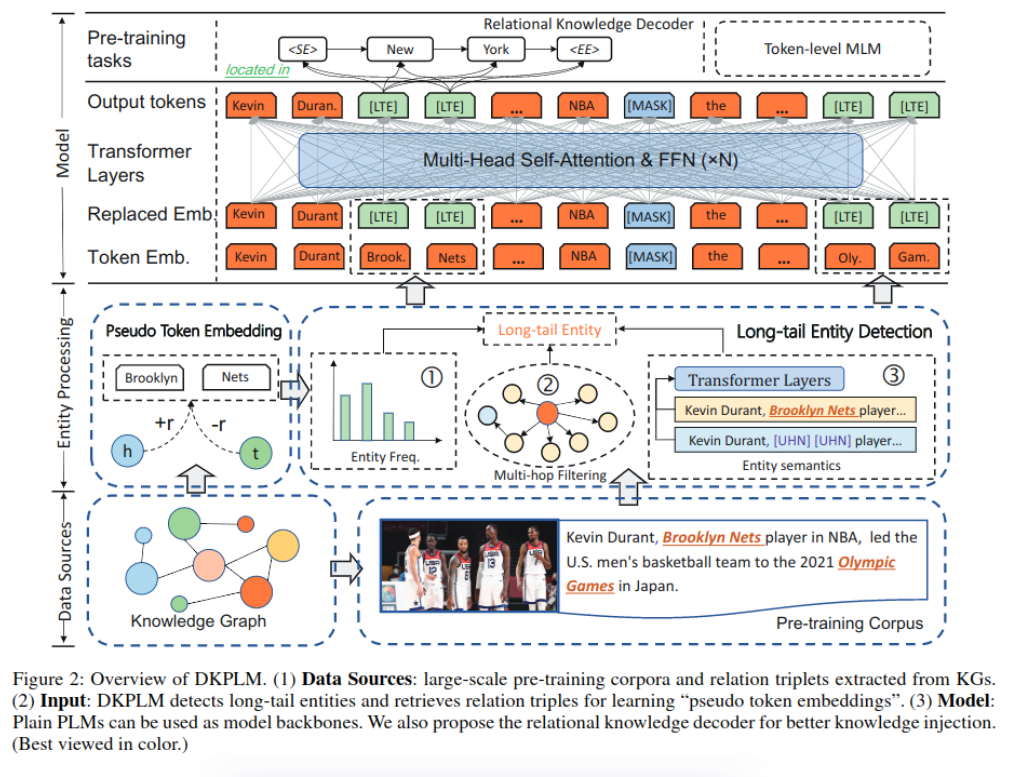
��βʵ����
ͨ����wiki���ݷ������Կ���ʵ����ֵ�Ƶ�ʷ������ɷֲ�,��ͼ-3��ʾ:
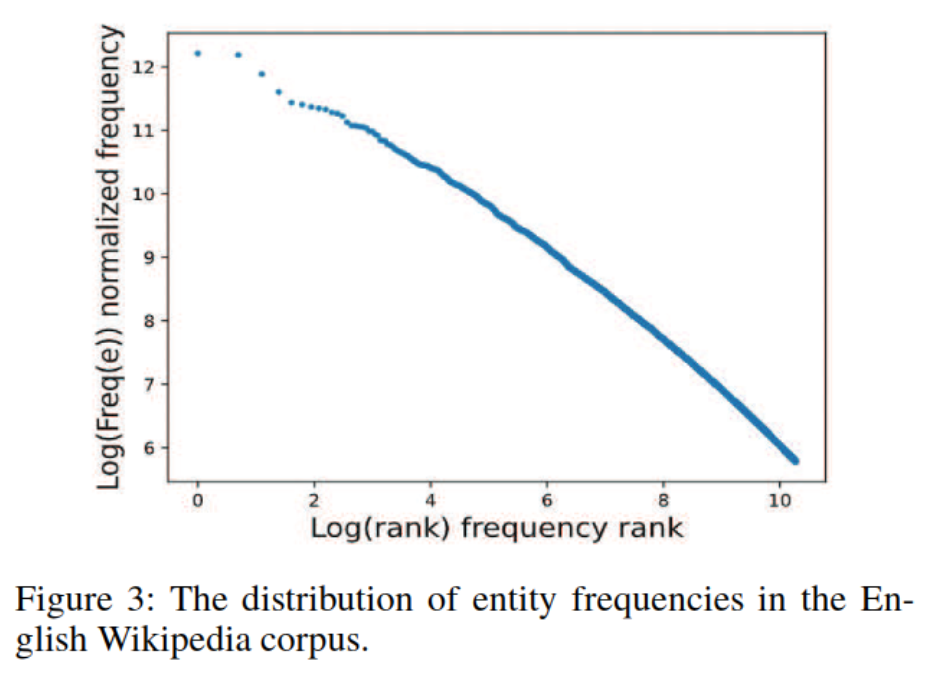
ֻ�к��ٵ�ʵ���Ƶ����,����ʵ����ִ�����,��ʹ����Ȼ����ģ�����Դ�����������Чѧϰ��֮ǰ�����ᵽע���Ƶ��Ԫ�鲻���������ڶ���������,����������ע�븺��֪ʶ����˸��õķ�����ע�볤βʵ��,ͬʱ����Ҫ����ʵ����֪ʶͼ�к;��е���Ҫ�ԡ����忼����������(ͼ-2�ڶ����Ҳ�):
- ʵ��Ƶ��:ʵ����Ԥѵ�����ݼ��г��ֵ�Ƶ��,����:Freq(e)��
- ������Ҫ��:ʵ���ھ��е���Ҫ��,����:SI(e)������SI����ʹ���������ƶ�,ͨ��ȥ�����е�ʵ��e��ı���hrep��ԭ�����ho�Ƚ�,ʶ���ʵ�����Ҫ�ԡ�
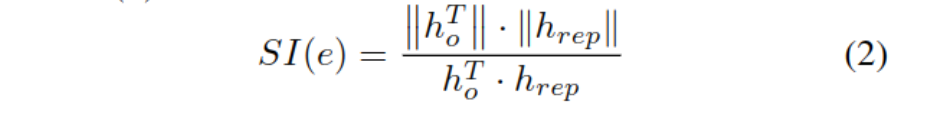
- ֪ʶ����:ʵ����֪ʶͼ�ж����ھӵĸ���,����:KC(e)������ʽ��ʾ,����Rmax,Rmin��Ԥ�������ֵ,|N|��ʾ�ھӸ���,Hopָ������

���ջ���֪ʶ�ij�βϵ��KLT��������:
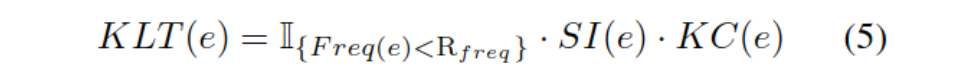
��I{x}Ϊ�����Ե�ָʾ����,��ʵ�����Ƶ�ʸ��ھ�ֵʱ,����Ը�ʵ�塣
(��������:��ѵ�����г��ִ���̫���ȥ��,��֪ʶͼ���ھ�̫���ȥ��,�ھ���������û����һ����ȥ��)
αTokenǶ���ע��
Ϊ������ģ�ͶԳ�βʵ�������,��֪ʶͼ�еĹ�ϵ����ģ��ѵ�������Ԥ��ѵ�������г�����ͷʵ��eh,��������صĹ�ϵν�ʺ�βʵ���滻����Ƕ��:
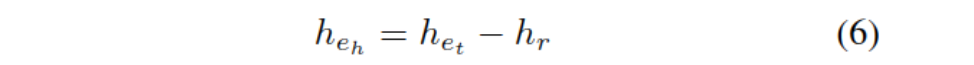
ͬ��,�������βʵ��,����ν�ʼ�ͷʵ������ʾ��
���滻ͷʵ��Ϊ��,�Թ�ϵ��βʵ�����:
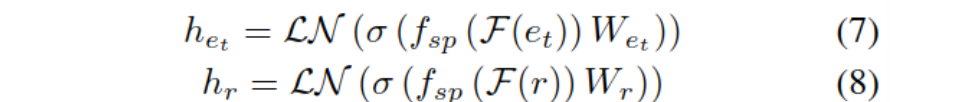
����F(e)��Ԥѵ��ģ��PLM�����,fsp����ע�����ػ�,LN�DZ�����,W��ģ�Ͳ�����
����βʵ���ϵν��ͨ�����Ƚ϶�,���ɵı�ʾ��������Ч��,��˻������˶�ͷʵ��������ı�����e_h^des,ʹ��Ԥѵ��ģ�Ͷ������,���յ�αʵ���ʾ����:
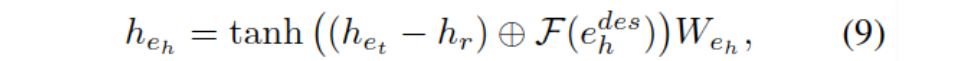
����Ĩ���ʾ������ͨ����������,�ٽ�ģ��ѧϰ֪ʶͼ�е���Ԫ�顣
���֪ʶ����
Ϊ�˸�ȷ������ģ��ѧϰע����Ϣ,�ֵ����˽�������������һ��,������ע�����ػ���ȡ��ʵ���ʵ�������ʾ��
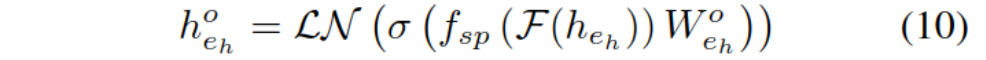
��ͷʵ�屾��ͨ��������ʽ���ɱ�ʾh_eho,�ټ���hr,Ŀ���ǽ���βʵ��,��h_di��ʾԤ��βʵ��ĵ�i��token��
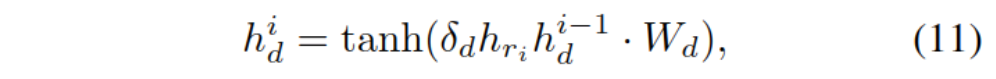
��ʽ�Ц�����������,h_d^0����h_eh_o��Ϊ��ʼ��������
���ڴʱ��ϴ�,ʹ�ò�����SoftMax���Ա�Ԥ��ֵ��ʵ��ֵ���������㷽������:
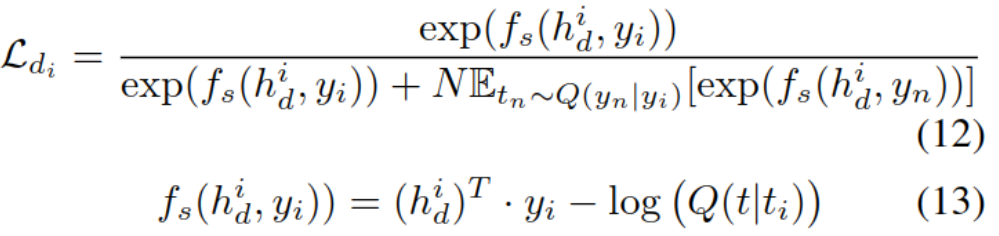
����yi��ʵ��token,yn�Dz����ĸ�token,Q�Ǹ���������,NΪ����������
ѵ��Ŀ�������������:��ص�֪ʶ�����BERT�Դ�����ģ������,������ʧ������������:
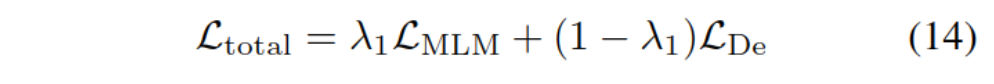
ʵ��
ģ�͵ײ��ܻ���RoBERTa,ʹ��Ӣ��Wikipedia��ѵ������,֪ʶͼ����3085345��ʵ��,822�ֹ�ϵ������ʵ��̫��,ʹ��PEPR�㷨ѡ��ʵ��,����N��Ϊ20,��1����ȡֵΪ0.5����ʵ��������:
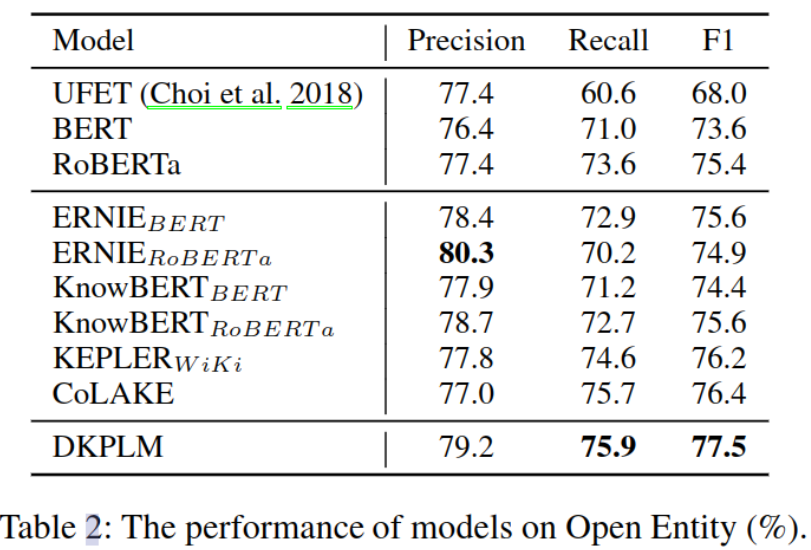
�ӱ�-4���Կ���,DKPLM�ٶ�������������֪ʶע��ģ��:
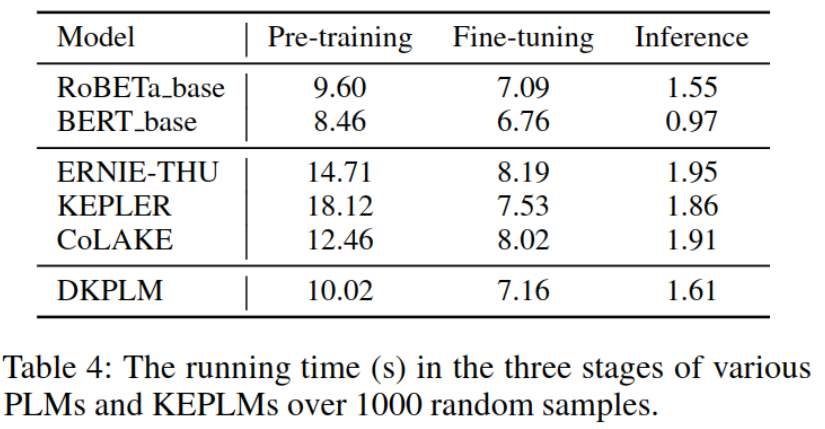
��ͼ-5������ʵ����Կ���,�����Ż��������ԵĹ���:
