
1. 摘要
??最近通过对比学习取得的突破加快了在现实世界数据应用程序上部署无监督训练的步伐。然而,现实中未标记的数据通常是不平衡的,并且呈现出长尾分布,并且目前尚不清楚最新的对比学习方法在实际场景中的表现如何。本文建议通过称为自损对比学习 (SDCLR) 的原则框架明确解决这一挑战,以在不知道类别的情况下自动平衡表示学习。我们的主要灵感来自最近的发现,即深度模型具有难以记忆的样本,这些样本可能通过网络修剪暴露出来(Hooker 等人,2020)。更自然地假设由于示例不足,长尾样本也更难模型学习。因此,SDCLR 的关键创新是创建一个动态的自我竞争者模型来与目标模型进行对比,目标模型是后者的剪枝版本。在训练过程中,对比两个模型会导致对当前目标模型最容易忘记的样本进行自适应在线挖掘,并在对比损失中隐含地更多地强调它们。跨多个数据集和不平衡设置的大量实验表明,就全镜头和少镜头设置的线性评估而言,SDCLR 不仅显着提高了整体准确度,而且还显着提高了平衡性。
2. 动机及贡献
动机
??首先,DNN倾向于优先学习简单的模式,即DNN优化是内容感知的,利用更多训练示例共享的模式,因此倾向于记忆大多是样本。由于长尾样本在训练集中的代表性不足,它们往往记忆力较差,或者更容易被模型“遗忘”。人们可以利用这一特征以模型感知但与类别无关的方式从未标记数据中发现长尾样本。
??然而,如果可行的话,测量每个单独的训练样本在给定 DNN 中的记忆程度通常是乏味的。作者观察到,网络剪枝通常会去除训练过的 DNN 中的最小权重,但不会平等地影响所有学习的类或样本。相反,它倾向于不成比例地阻碍 DNN 记忆和泛化训练集中的长尾和最困难的图像。换句话说,长尾图像不能“很好地记住”,并且通过修剪模型很容易被“遗忘”,使网络修剪成为发现 DNN 尚未很好学习或表示的样本的实用工具。
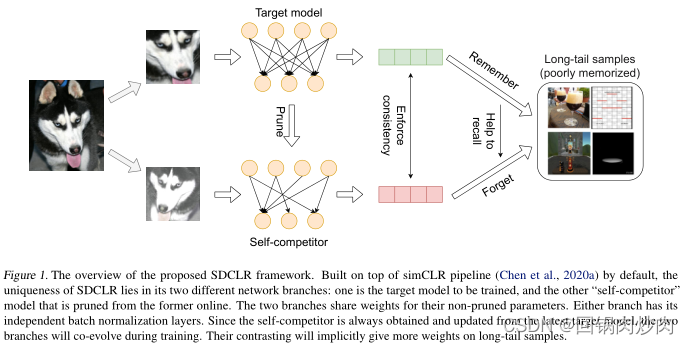
??受上述启发,我们提出了一个称为自损对比学习(SDCLR)的原则框架,在不知道类的情况下自动平衡表示学习。 SDCLR 的工作流程如图 1 所示。除了通过输入数据增强创建强烈的对比视图外,SDCLR 通过扰动目标模型的结构和/或当前权重,通过“模型增强”引入了另一个新的对比水平。特别是 SDCLR 的关键创新是通过在线修剪目标模型来创建动态的自我竞争者模型,并将修剪后的模型的特征与目标模型的特征进行对比。剪枝会削弱模型对稀有和非典型实例的准确预测能力,实践中的这些样本在剪枝和非剪枝模型之前也将具有最大的预测差异。这有效地提高了他们在对比损失中的权重,并导致隐式损失重新平衡。此外,由于自我竞争者总是从更新的目标模型中获得,这两个模型将共同进化,这使得目标模型能够在不同的训练阶段发现不同的记忆失败,并逐步学习更平衡的表示。
主要贡献
- 看到无监督对比学习不能免受不平衡数据分布的影响,我们设计了一个自毁对比学习 (SDCLR) 框架来应对这一新挑战。
- SDCLR 通过创新利用理解 DNN 记忆的最新进展。通过在训练期间修剪目标模型来在线创建和更新自我竞争者,SDCLR 提供了一个自适应在线挖掘过程,在整个训练过程中始终关注最容易忘记的(长尾)样本。
- 跨多个数据集和不平衡设置的大量实验表明,SDCLR 不仅可以显着提高学习表示的平衡性。
3. 方法
3.1 修剪已识别的样本
??Hooker 系统地研究了剪枝引入的模型输出变化,发现某些示例对稀疏性特别敏感。这些剪枝后影响最大的图像被称为剪枝识别样本 (PIE),代表训练中难以记忆的样本。此外,作者还证明了 PIE 经常出现在分布的长尾。我们首次将 Hooker 的 PIE 假设从监督分类扩展到无监督设置。此外,我们现在不是对经过训练的模型进行剪枝并暴露其 PIE,而是将剪枝作为在线步骤集成到训练过程中。通过修剪训练中的目标模型动态生成 PIE,我们希望它们在训练期间暴露不同的长尾示例,因为模型会继续训练。
3.2 自损对比学习
观察:对比学习不能免于不平衡 长尾分布在许多基于平衡基准的监督方法中都失败了,即使对比学习不依赖类标签,它仍然以数据驱动的方式学习变换不变性,并且会受到数据集偏差的影响。特别是对于长尾数据,人们自然会假设实例丰富的头类可能主导不变性学习过程,而使尾类学习不足。
??并行工作表明,使用对比损失可以获得所有类别具有相似可分性(和下游分类性能)的平衡表示空间,这得到了ImageNet LT和iNaturalist实验的支持。作者在此基础上进行了额外的实验。虽然这一结论可能适用于当前基准中提出的中等程度的不平衡,但我们构建了一些严重不平衡的数据设置,在这种情况下,对比学习将无法产生平衡的特征。在这种情况下,学习表示的线性可分性在头类和尾类之间可能有很大差异。我们认为,虽然(普通)对比学习可以在一定程度上缓解表征学习中的不平衡问题,但它并不具有完全的免疫力,需要进一步加强。
SDCLR 框架 图1概述了拟议的SDCLR框架的高级工作流。默认情况下,SDCLR构建在simCLR管道之上,并遵循其最重要的组件,如数据增强和非线性投影头。simCLR和SDCLR之间的主要区别在于,simCLR将两个增强图像馈送到同一目标网络主干中(通过权重共享);而SDCLR通过在线修剪目标模型来创建“自我竞争对手”,并让两个不同的分支使用两个增强图像来对比它们的特征。
??具体地说,在每次迭代中,使用最简单的基于幅度的剪枝,通过剪枝
N
1
N_1
N1?得到密集分支
N
1
N_1
N1?和稀疏分支
N
2
p
N_2^p
N2p?。理想情况下,在更新模型权重后,可以每次迭代更新
N
2
p
N_2^p
N2p?的剪枝掩码。在实践中,由于主干是一个大的DNN,其权重在一次或两次迭代中不会有太大变化,因此我们将剪枝掩码设置为在每个 epoch 开始时延迟更新,以节省计算开销;同一时期内的所有迭代都采用相同的掩码。由于自竞争对手总是从最新的目标模型中获得和更新,因此两个分支将在训练期间共同进化。
??对输入图像
I
I
I 采样并应用两个不同的增强链,创建两个不同的版本
[
I
^
1
,
I
^
2
]
[\hat I_1, \hat I_2]
[I^1?,I^2?]。它们由
[
N
1
,
N
2
p
]
[N_1,N_2^p]
[N1?,N2p?]编码,并且它们的输出特征
[
f
1
,
f
2
p
]
[f_1,f_2^p]
[f1?,f2p?]被馈送到非线性投影头中,以在 NT-Xent 损失下强制相似性。理想情况下,如果样本被
N
1
N_1
N1?很好地记住了,修剪
N
1
N_1
N1?不会“忘记”它――因此几乎不会引起额外的扰动,并且对比度与原始 simCLR 中的大致相同。否则,对于罕见和非典型的情况,SDCLR 将放大然后修剪和未修剪模型之间的预测差异――因此这些样本的权重将在整体损失中隐式增加。
??更新两个分支时,注意
[
N
1
,
N
2
p
]
[N_1,N_2^p]
[N1?,N2p?]将在未剪枝部分共享相同的权重,
N
1
N_1
N1?将独立更新剩余部分(对应于在
N
2
p
N_2^p
N2p?中剪枝为零的权重)。然而,我们凭经验发现,让任一分支都有其独立的批量归一化层会有所帮助,因为密集和稀疏的特征可能会显示不同的统计数据。
3.3 对SDCLR的讨论
- SDCLR 可以使用更具对比性的学习框架。 作者目前仅在simCLR上实现SDCLR以证明这一概念,但是SDCLR是可以与其他所有采用双分支设计的对比学习框架一起应用的。
- 修剪不是为了 SDCLR 中的模型效率。 在SDCLR中,修剪可以更好地描述为“选择性脑损伤”。它主要用于有效地发现当前模型还没有很好地记忆和学习的样本。
- SDCLR 的好处超出了标准的类不平衡。 。由于 SDCLR 完全不依赖标签信息,因此它很容易适用于处理实际数据中各种更复杂的不平衡形式,例如多标签属性不平衡。此外,即使在 ImageNet 等人工类平衡数据集中,也隐藏了更多固有形式的“不平衡”,例如类级难度变化或实例级特征分布。