融合知识图谱和多模态的文本分类研究
- 摘要:传统文本分类方法主要是基于单模态数据所驱动的经验主义统计学习方法,缺乏对数据的理解能力,鲁棒性较差,单个模态的模型输入也难以有效分析互联网中越来越丰富的多模态化数据。针对此问题提出两种提高分类能力的方法:引入多模态信息到模型输入,旨在弥补单模态信息的局限性;引入知识图谱实体信息到模型输入,旨在丰富文本的语义信息,提高模型的泛化能力。模型使用Bert提取文本特征,改进的ResNet提取图像特征,TransE提取文本实体特征,通过前期融合方式输入到Bert模型中进行分类,在研究多标签分类问题的MM-IMDB数据集上F1值达到66.5%,在情感分析数据集Twitter15&17上ACC值达到71.1%,结果均优于其他模型。实验表明,引入多模态信息和实体信息能够提高模型的文本分类能力。
引言:
- 随着互联网技术的飞速发展和广泛普及,各种模态的数据井喷式涌现,信息的爆炸式增长也为人们带来了新的挑战:面对如此繁杂的多模态化数据,如何从中挖掘出被大众需要的、有价值的信息,是现阶段的一个重要课题。面对模态多样且价值密度低的海量数据,必须要同应用背景深度结合,运用自动化手段对数据进行分类,以便更好的挖掘数据中的价值。在这样的背景下,文本分类方法体现出愈发重要的研究价值。
- 文本分类是自然语言处理领域的一项经典子任务,指的是将一段文本归类到一个或多个类别之中。目前,文本分类方法主要分为基于机器学习的方法和基于深度学习的方法。常见的机器学习方法包括朴素贝叶斯分类[1]、支持向量机分类[2]、K近邻分类[3]等。
- 近年来,随着深度学习[4]的迅速发展,各种神经网络模型如雨后春笋般涌现,常见的神经网络模型包括卷积神经网络(ConvolutionalNeuralNetworks,CNN)[5]、循环神经网络(RecurrentNeuralNetwork,RNN)[6]等。深度学习的方法在图像、音频等领域都率先取得了惊人的成果,但在词向量模型出现之前,深度学习在自然语言处理领域发展并不理想,主要原因是神经网络难以处理高纬度、高稀疏的文本表示。Word2Vec[7]的提出为深度学习在NLP领域开辟了道路,它采用分布式表示的词向量代替传统的独热向量,解决了文本表示的问题,常见的词向量模型包括Word2Vec、ELMo[8]、GPT[9]、BERT[10]等。使用神经网络模型来训练词向量语言模型,可以自动提取词向量特征,免去了繁杂的人工特征工程,训练得到的词向量还可以进行灵活的迁移学习。
- 目前,依赖于大规模的训练数据以及高性能GPU、TPU提供的强大计算能力,以BERT为基线的神经网络模型大放异彩,在许多应用场景都取得了更好的效果。但是,目前的深度学习文本分类方法仍是单模态数据驱动的方法,数据中可挖掘的信息量存在一定局限性,模型的泛化能力和鲁棒性存在不足。针对这些问题,本文提出两种提高分类能力的方法:
- (1)引入多模态信息。随着互联网技术的发展,如今的信息呈现多模态化,每一种信息的来源或形式都是一种模态,比如文本模态、音频模态、图像模态等。然而,近来的文本分类方法大多仍处于单模态阶段,其中可挖掘的信息量存在一定的局限性。引入多模态,旨在弥补单模态信息的局限性,多模态之间的互补性与冗余性也削弱了单模态信息受噪声的影响,提高了整个模型的稳定性。
- (2)引入知识图谱。知识图谱是结构化的知识 表示系统,包含复杂的结构化信息,已经被广泛用于 搜索引擎、问答系统等领域。引入知识图谱,旨在为 模型提供额外的知识信息,让模型拥有理解能力、联想能力,提高模型的泛化能力。
1 相关工作
- 本节主要从三个角度阐述:①从单模态角度简述 文本分类方法的相关工作;②从知识图谱角度简述知识融合的相关工作;③从多模态角度简述多模态特征融合的相关工作。
1.1文本分类
- Word2Vec的提出使深度学习的文本分类方法成为了潮流。学者们开始结合词向量与神经网络模型来进行文本分类。RNN在处理当前时刻的状态时引入了上一时刻隐藏层的值,使模型拥有了一定的记忆能力,适合处理序列信息,在自然语言处理领域中更常用,但序列过长时会出现长期依赖问题。LSTM[11]模型是为了解决RNN的长期依赖问题提出的,在标准的RNN单元上添加门控机制,使得梯度问题得以缓解,但是这个问题仍然存在。CNN在文本分类上也有许多研究成果,Kim提出TextCNN[12]来进行文本分类,通过词向量构建了一个句子矩阵,每行都是一个词向量,随后通过CNN来进行特征提取,取得了不错的效果。Kalchbrenner等人[13]提出了动态CNN模型DCNN,模型在池化层使用了k-max-pooling和动态k-max-pooling,k-max-pooling可以在提取活跃特征的同时保持它们的相对顺序,动态k-max-pooling则在句子长度不同时提取出相应数量的特征,保证后续卷积层的统一。
- CNN和RNN在文本分类任务中都取得了很好的效果,但是其几乎不具备可解释性。注意力机制(Attention)是深度学习领域的一个核心技术,也被广泛应用于自然语言处理领域,它模仿人类的视觉注意力,能够计算出各个单词对结果的贡献,同时注意力机制有良好的可视化操作,能够为模型提供一定的可解释性。Bahdanau等人[14]使用Attention机制在机器翻译任务上,取得了显著的成果,第一次将Attention机制应用到自然语言处理领域中,随后Attention机制又被大量应用在基于CNN、RNN的网络模型上。2017年Google团队[15]提出了一种全新的神经网络架构Transformer,Transformer完全摒弃了RNN与CNN,仅使用基于self-attention的注意力机制,佐以多头注意力机制、位置编码、前馈神经网络、残差连接、层归一化等技术,在11项NLP领域任务上刷新了性能记录。目前以BERT为首的预训练语言模型就基于Transformer,BERT的出现在整个自然语言处理领域都是里程碑式的,在各项任务上都显著刷新了记录,后续的大量自然语言处理研究都是基于BERT的改进。
1.2知识融合
- 人类能够理解语言,一个重要原因是拥有相关的先验背景知识。目前的自然语言处理算法,主要基于海量数据的统计拟合来挖掘文本的语义信息,忽略了先验知识的作用,无法提取语言的深层关联与特征,一定程度上限制了其性能上限。因此,要实现具有理解能力的自然语言处理算法,还需要丰富的领域知识来引导和推理。
- 知识图谱是将知识结构化表示的知识系统,包含了复杂的领域知识、通用规则和其他的结构化信息,如WikiData[16]、YAGO[17]、DBpedia[18]、WordNet[19]等大规模知识图谱,被广泛应用于搜索引擎、问答系统等基于知识驱动的人工智能领域中。将知识图谱引入到自然语言处理中,能够让模型从知识图谱中提取额外的先验知识,例如文本中隐含的实体概念、实体关系、实体描述等信息,从而丰富文本的上下文语义信息。Wang等人[20]利用Microsoft提供的概念图谱将文本概念化,使用CNN联合训练文本向量与概念向量,得到了结合概念知识的文本特征表示。Chen等人[21]进一步使用双向LSTM和注意力机制来处理概念与文本的关系以及概念之间的关系,取得了更好的文本表示效果。得益于BERT的出现,一些基于BERT的结合知识图谱的预训练语言模型被提出,比如清华和华为提出的ERNIE[22],结合知识图谱使用TransE算法获得文本中包含的实体向量信息并嵌入到BERT中;北大和腾讯联合提出的K-BERT[23]将关联实体在知识图谱中的三元组信息注入到文本中,得到一个富含语义信息的句子树来进一步进行预训练,都取得了显著的效果。
1.3多模态融合
- 每一种信息的来源或形式都可以称作一种模态,例如人有触觉、听觉、嗅觉;信息的媒介有文字、语音、图像等,都是一种模态。多模态机器学习(MultiModalMachineLearning,MMML),旨在通过机器学习的方法实现处理和理解多模态信息的能力。目前比较热门的研究方向是图像、文字、音频、视频等模态之间的多模态学习。多模态学习的优势在于弥补了单模态信息的局限性,受单个模态中的噪声影响较小,各模态之间具有冗余性和互补性,合理处理多模态信息,就能得到具有更加丰富特征的信息,从而提升整个模型的性能。
- 多模态融合是多模态学习的主要研究方向之一,它将从不同模态数据中提取的信息集成到一个稳定的多模态表征中。多模态融合按照融合的层次划分,大致可以分为早期融合和晚期融合。Anastasopoulos等人[24]对不同模态的特征向量直接使用简单的拼接操作。Zadeh等人[25]提出了基于矩阵的TFN(TensorFusionNetwork),使用矩阵运算对不同模态的特征向量作外积来融合多模态信息。Nam等人[26]在多模态融合过程中加入注意力机制来捕捉视觉和语言模态间的联系,在VQA和图像文本匹配任务上达到了很好的效果。BERT在文本领域的成功,也让一些多模态预训练模型架构被提出,比如基于双流模型的ViLBERT[27]、基于单流模型的VisualBERT[28]等,它们将图像和文本数据一同输入到Transformer中,使用Transformer强大的特征提取能力提取融合的多模态特征,其中ViLBERT使用双流模型分别处理图像和文本数据,在后期进行特征融合,而VisualBERT等单流模型直接在前期将视觉特征和文本特征融合输入到模型中。后续研究中,Alberti等人[29]通过实验和详细的分析表明使用早期融合方式的单流模型更具有优势。随后Kiela等人[30]提出使用单模态预训练模型组件来构建多模态架构,不需要进行多模态任务上的预训练,直接在BERT模型上进行Fine-tuning就能取得与多模态预训练模型具有竞争力的性能。
- 在以上论述方法的启发下,本文针对目前的文本分类模型尚不能有效利用多模态信息,并且缺乏理解能力的问题,结合知识融合和多模态融合两种提升文本表征能力的方法,构建了一个融合知识图谱和多模态的文本分类模型,模型利用不同模态间的信息相互补充,提高了模型的稳定性,知识的引入也使模型能够利用大规模知识图谱中的结构化知识。实验证明,本文提出的方法能够提升模型的分类性能。
- 本文的主要贡献有:(1)提出了一种同时融合知识图谱、图像以及文本信息的多模态文本分类方法。(2)在图像的引入上,对ResNet模型进行了改进,提升了多模态模型的分类能力。(3)在知识图谱的引入上,提出了将知识图谱实体信息引入到多模态文本分类中的思想,并设计了一套完整的引入流程。(4)通过实验比较了早期融合与晚期融合方式的效果差异。
2 融合知识图谱和多模态的文本分类模型
- 本文提出的融合知识图谱和多模态的文本分类模型如图1所示。该模型充分结合了文本、实体、图像三种模态信息的特征表示,其中文本特征表示由BERT预训练语言模型生成,实体特征表示通过实体链接提取文本中包含的实体,利用TransE算法生成对应的实体向量,图像特征表示由基于ResNet152预训练模型的改进模型生成。
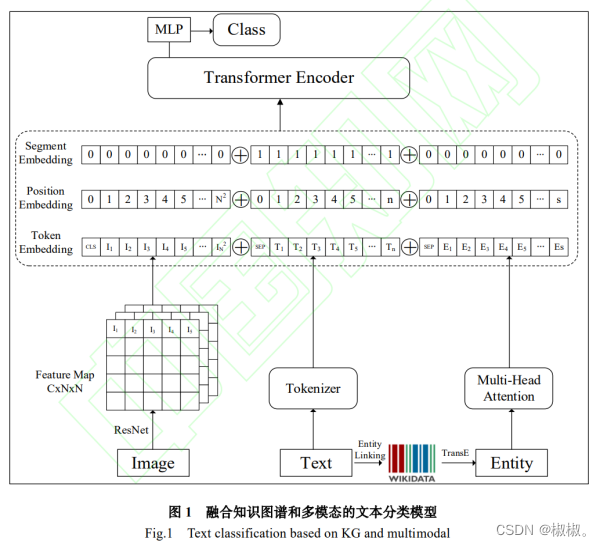
2.1文本特征表示
- BERT(BidirectionalEncoderRepresentationsfromTransformers)是在大规模语料库上进行自监督学习的预训练语言模型,通过在未标注文本上进行MLM随机掩盖和NSP预测下一句两种语言模型任务的预训练来学习语言的内部表征,既可以直接使用其进行下游任务,也可用来提取对下游任务有用的文本特征。本文使用bert-base-uncased模型来生成对应文本的词向量。
2.2实体特征表示
- 知识图谱本质上是一个基于图结构的语义网络,由节点和边组成,每个节点表示一个实体,每条边表示实体间的一种关系。实体可以是具体的事物,也可以是概念或属性。引入知识图谱中的外部知识到模型中主要有两个重要步骤:实体链接和实体表示学习。
- 实体链接的主要任务是将一段文本中提及到的关于实体的语言片段(mention)链接到知识图谱中对应的实体(entity)上。本文使用BLINK[31]来检索文本中提及的实体,对应的知识图谱为Wikidata。BLINK将实体链接任务分为两个阶段,首先使用Bi-encoder对mention及其上下文、entity及其描述分别编码得到各自的向量表示,并根据相似度排序获取候选实体candidate,然后将上阶段取得的candidate和mention特征向量连接并使用Cross-encoder编码排序,选出最优实体,模型各阶段使用的编码器都基于独立的预训练的BERT模型。通过BLINK,对于一段给定文本Text{t1,…tn,}可以得到文本对应的实体集Entity{e1,…es,}每个实体信息都记录着其在维基数据网站上的入口信息。利用这些入口信息,再结合一定的转换操作,就可以得到这些实体对应的Wikidata实体“QID”,比如JayChou对应Q238819。
- 实体表示学习的目的在于将以实体三元组为存储形式的知识图谱转化为深度学习常用的分布式表示向量形式。本文使用TransE模型[32]获取实体的分布式向量表示。TransE是Bordes等人提出的知识表示学习算法,是Trans系列方法的基础,它借鉴词向量的思想,将实体和关系映射到同一个低维向量空间中,关系被解释为实体之间在向量空间中的平移操作,这样对于一个三元组(h,r,t),其中h、r、t分别代表三元组的头实体、关系和尾实体的向量表示,TransE希望它们满足t=h+r。因此TransE定义了如下损失函数:
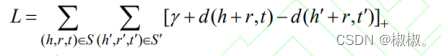
- 其中d(.)表示两个向量的距离,这个距离可以为L1或L2范数,S’表示负例三元组,通过将正例三元组的头实体或尾实体替换为其他随机实体来构造,[.]+表示只取结果为正的部分,r是一个超参数,用来控制正负例的距离。损失函数的目的是让正例三元组中(h+r)与t距离最小,同时正例三元组中实体尽可能远离负例三元组中的其他实体。本文使用OpenKE[33]来提取基于TransE的实体向量表示。
通过实体链接和实体表示学习,可以得到实体集的向量表示,再经过一层多头自注意力层处理得到实体特征表示。
2.3图像特征表示
-
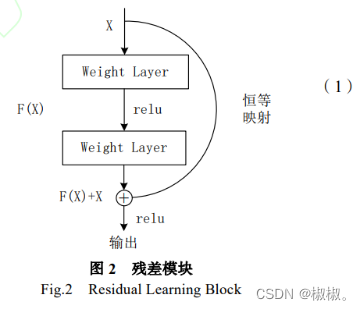
深度残差网络(DeepResidualNetwork,ResNet)[34]的出现是卷积神经网络在图像处理领域史上的里程碑事件,其提出的残差网络让深度学习的“深度”优势得以显现。理论上讲,更深层的神经网络能够进行更加复杂的特征提取,捕获更抽象的特征,深层网络应比浅层网络取得更好的效果,至少不会更差。然而事实上,56层的神经网络在CIFAR-10数据集上的效果远不如20层的神经网络,层数的加深反而使网络退化了。针对这个问题,ResNet提出了残差学习的思想,让层数的加深不会让网络效果变差,从而解决了深度网络的退化问题。
-
残差学习的思想假设一个神经网络已经在某一层取得最优结果,其后的深层网络是冗余的,如果能够让这些冗余层完成一个恒等映射,使冗余层的输入与输出不变,就能使网络一直保存最优层的输出结果。残差网络通过引入一个残差模块来达到恒等映射效果,残差模块如图2所示。对于一个冗余的网络层,假设输入为x,在引入残差模块前,网络学习到的参数应满足线性变换H(x)=x;引入残差模块后,H(x)=F(x),这样网络参数只需要满足令残差F(x)=0,相较于直接学习H(x)=x更加容易。
-
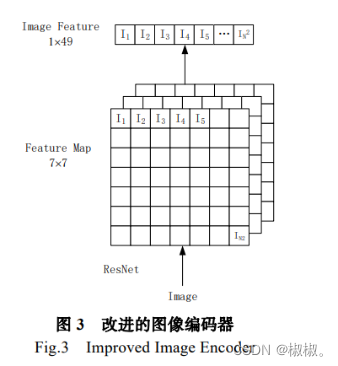
ResNet152模型在进行了大量的卷积操作后,直接对图像做了一次全局平局池化操作,将7×7的特征图压缩为1×1的矩阵,从而捕获特征图的全局特征用于分类。这种方法在一定程度上损失了图像中局部特征蕴含的语义信息和位置信息,本文借鉴了Vit[35]对图像的处理方式,将ResNet152卷积操作后最终提取的特征图分割为均等的子特征图,并将这些子特征图按照线性顺序排列作为图像的特征表示。本文改进后的图像特征提取模型结构如图3所示。
-
本文把将特征图分割为子特征图并线性排列的操作称为UP(UnfoldPatches),经过UP操作后,可以得到蕴含位置信息的图像特征表示,这些位置信息能够辅助Transformer模型更全面地理解图像,提取到图像中的语义信息,更好的辅助文本模态进行文本分类。
2.4输入层
- 正如1.3节所述,晚期融合的方式会忽略掉各模态之间的互信息。本文在多模态特征的融合方式上采用早期融合的方式,并利用Transformer模型的强大特征提取能力与多头自注意力机制来学习各模态的融合权重。类似于BERT对文本模态数据的处理方式,各个模态的输入向量由特征表示向量、位置编码向量和段向量叠加而成。由于在图像模态数据的特征表示方法中引入了UP操作,需要考虑子特征图的顺序关系,因此图像模态的输入向量中也需要叠加位置编码向量来学习这些位置信息。同时为了保持模型整体一致性,以及实体信息中可能蕴含的位置信息,模型在处理实体输入向量时也加入了位置编码。段向量的作用则是为了让BERT能够区分出输入向量分别来自不同的模态。
- 取得到各模态的输入向量后,以级联的方式将其拼接在一起,不同模态之间用特殊标记[SEP]分隔开,输入到预训练的BERT模型进行Fine-tuning训练。输入层的输入向量最终形式可表示为:
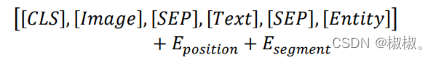
2.5训练与分类
- 各模态特征表示经过模型输入层处理后,输入到BERT模型中进行训练,选取模型输出的[CLS]标签位置的隐藏向量作为分类任务所需的特征向量,模型的最后用全连接层作为分类器,输出一个C维的向量,其中C为分类类别数,第i个维度表示输入被分为第i个类别的概率。
- 本文是一个多标签分类问题,使用BCE With LogitsLoss作为损失函数来训练模型,该损失函数是激活函数Sigmoid和二分类交叉熵BCELoss(BinaryCrossEntropy)的组合,并且使用了Log-Sum-Exp的技巧来增强数值稳定性。使用带有权重衰减修正的BertAdam优化器来更新模型参数。
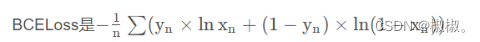
3实验
3.1数据集与评价方法
-
MM-IMDB数据集[36]由Arevalo等人提供,该数据集由IMDB网站提供的电影情节大纲与电影海报构成,并按照电影体裁对电影进行分类,每个电影都可能被分类为多种体裁,体裁共有25个种类,因此这是一个多标签分类问题。整个数据集包含25891条文本以及对应的海报图片。本文又在其基础上扩充了每条文本包含的实体信息。实验中数据集按照60%,10%,30%的比例被分为训练集、验证集与测试集。
-
在多标签分类问题中,模型性能的评价方法相较传统分类问题更复杂。本文选用了两种评价指标:MicroF1和MacroF1。其中MicroF1同时计算所有预测的F1值,MacroF1计算每个标签的F1值并取平均结果,各评价指标的计算公式如下:

-
其中precision为精确率,即被预测为正的样本中实际为正的比例,recall为召回率,即原本为正的样本中被预测为正的比例。F1值则权衡了精确率和召回率,是二者的调和平均数。N指的是标签的种类数。MicroPrecision和MicroRecall是同时计算所有类别的总精确率和总召回率。
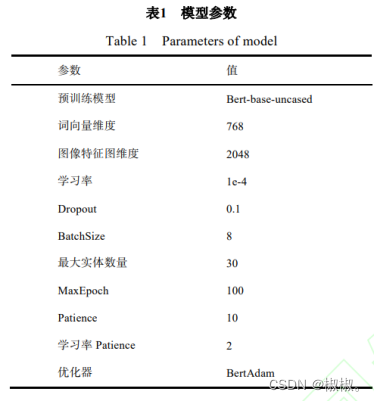
3.2 实验环境与模型参数
- 本文实验主要基于Pytorch深度学习框架与pytorch_pretrained_bert库,GPU为RTX3090,Cuda11.0,部分模型参数如表
1:
3.3对比实验结果与分析
-
本文分别使用单模态信息和多模态融合信息进行了一系列对比实验来验证本文方法的有效性:
1)Bert预训练模型(TextOnly).使用Bert预训练模型对单模态的文本数据进行训练与分类。
2)ResNet152预训练模型(ImageOnly).使用ResNet152预训练模型对单模态的图像数据进行训练与分类。
3)MMBT模型(MultimudalBitransformer).文献[30]所提出的多模态分类模型,也是本实验的基线模型之一。分别使用BERT提取文本特征表示,使用ResNet152提取图像特征表示,并级联拼接输入到BERT进行训练与分类。
4)UP_E_MMBT模型(UnfoldPatches-Entity-MMBT).本文提出的主要模型,在MMBT模型的基础上,在图像的特征提取中引入UP操作,得到了包含位置信息的图像特征表示。同时,本文还引入了实体向量,使用TransE方法训练Wikidata获得实体向量,进一步提升模型的性能。
5)晚期融合模型(LateConcat):晚期融合对不同模态的数据分别进行训练,然后再进行融合并输入分类器进行训练与分类。本实验将各模态的特征表示进行了一系列晚期融合实验。实验使用Bert作为文本的特征提取器,使用ResNet或基于ResNet改进的模型作为图像的特征提取器,使用TransE方法训练Wikidata提取实体特征。
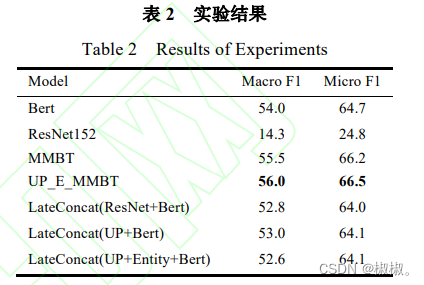
实验结果如表2所示,为验证方法的有效性,各模型的实验参数(除模型新增参数)和实验环境保持完全一致。
-
从实验结果可以看出:
-
1)单模态的情况下,文本信息的分类效果优于图像信息,一方面这是由于相较于图像,文本更容易挖掘出其蕴含的语义信息,另一方面则是由分类任务的性质决定的,多模态文本分类任务中的图像信息所表达的内容往往是抽象的、不具体的,仅依靠单模态的图像信息难以支撑模型进行有效的分类决策。
-
2)多模态融合的情况下,各模型的分类效果均优于单模态情况,这说明为模型引入图像信息和实体知识信息能够提升模型的分类性能。引入图像能够补充文本中没有的语义信息,引入实体知识能够使模型获取额外的先验知识,这些信息都可以帮助模型做出更科学的分类决策,提升模型的分类性能。
-
3)多模态早期融合的方式取得了更好的效果,这说明在多模态融合时利用自注意力机制进行早期融合能够让模型更好地学习到各模态对分类结果的贡献度。UP_E_MMBT的表现优于MMBT,说明本文对图像特征表示的改进,即对图像特征图的UP操作能够提取图像中更深层的语义信息。
-
4)多模态晚期融合的效果并不理想,甚至不如纯粹的Bert模型,这是因为直接拼接会忽略各模态对分类结果的贡献权重,但是从实验结果仍然可以看出,引入图像和实体知识以及引入图像UP操作后,模型性能会得到提升,这可以佐证本文提出方法的有效性。
4结术语
- 多模态学习为传统的基于单模态的分类模型带来了新的机遇与挑战,本文基于多模态和知识图谱两个新兴热点,提出了融合知识图谱和多模态的文本分类模型,使用各模态上先进的特征提取器提取特征向量,再通过Bert预训练模型提取各模态融合后的深层语义信息,取得了良好的效果。本文对ResNet模型做出了改进,在模型的尾部引入UP操作,获得了蕴含位置信息的图像特征表示,并取得了相较于原模型更好的效果。本文还提出了将实体知识应用到多模态模型的思想,并设计了一套引ComputerEngineeringandApplications9入实体的流程,取得了良好的效果。
- 需要注意的是,本文的工作还有进一步的空间,实验方面可以在其他数据集上进一步研究模型的有效性和泛化能力,模型细节上可以在连接各模态特征时进一步考虑各自的权重,文本的实体链接和特征表示方法可以采用更成熟的处理方式,知识图谱的选择上可以针对具体的下游任务选用更专业的领域知识图谱。
参考文献:
[1]贺鸣,孙建军,成颖.基于朴素贝叶斯的文本分类研究综述[J].情报科学,2016,34(7):147-154.HeMing,SunJian-jun,Chengying.TextClassificationBasedonNaiveBayes:AReview[J].InformationScience,2016,34(7):147-154.
[2]崔建明,刘建明,廖周宇.基于SVM算法的文本分类技术研究[J].计算机仿真,2013,30(2):299-302.CuiJian-ming,LiuJian-ming,LiaoZhou-yu.ResearchofTextCategorizationBasedonSupportVectorMachine[J].ComputerSimulation,2013,30(2):299-302.
[3]张宁,贾自艳,史忠植.使用KNN算法的文本分类[J].计算机工程,2005,31(8):171-172.ZhangNing,JiaZi-yan,ShiZhong-zhi.TextCategorizationwithKNNAlgorithm[J].ComputerEngineering,2005,31(8):171-172.
[4]HintonGE,SalakhutdinovRR.ReducingtheDimensionalityofDatawithNeuralNetworks[J].Science,2006,313(5786):504-507.
[5]LecunY,BottouL.Gradient-basedlearningappliedtodocumentrecognition[J].ProceedingsoftheIEEE,1998,86(11):2278-2324.
[6]LiuP,QiuX,HuangX.RecurrentNeuralNetworkforTextClassificationwithMulti-TaskLearning[J].AAAIPress,2016:2873-2879.
[7]MikolovT,ChenK,CorradoG,etal.EfficientEstimationofWordRepresentationsinVectorSpace[J].arXivpreprintarXiv:1301.3781,2013.
[8]PetersM,NeumannM,IyyerM,etal.DeepContextualizedWordRepresentations[C]//Proceedingsofthe2018ConferenceoftheNorthAmericanChapteroftheAssociationforComputationalLinguistics:HumanLanguageTechnologies(HLT-NAACL),Volume1(LongPapers).2018.2227-2237.
[9]RadfordA,NarasimhanK,SalimansT.ImprovingLanguageUnderstandingbyGenerativePre-Training[J/OL].https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf,2018
[10]DevlinJ,ChangMW,LeeK,etal.BERT:Pre-trainingofDeepBidirectionalTransformersforLanguageUnderstanding[J].arXivpreprintarXiv:1810.04805,2018.
[11]HochreiterS,SchmidhuberJ.LongShort-TermMemory[J].NeuralComputation,1997,9(8):1735-1780.
[12]KimY.ConvolutionalNeuralNetworksforSentenceClassification[J].arXivpreprintarXiv:1408.5882,2014.
[13]KalchbrennerN,GrefenstetteE,BlunsomP.Aconvolutionalneuralnetworkformodellingsentences[J].arXivpreprintarXiv:1404.2188,2014.
[14]BahdanauD,ChoK,BengioY.Neuralmachinetranslationbyjointlylearningtoalignandtranslate[J].arXivpreprintarXiv:1409.0473,2014.
[15]VaswaniA,ShazeerN,ParmarN,etal.Attentionisallyouneed[C]//AdvancesinNeuralInformationProcessingSystems(NIPS),2017:5998-6008.
[16]VrandecicD,KrtoetzschM.Wikidata:afreecollaborativeknowledgebase[J].CommunicationsoftheAcm,2014,57(10):78-85.
[17]SuchanekFM,KasneciG,WeikumG.YAGO:ACoreofSemanticKnowledgeUnifyingWordNetandWikipedia[C]//InternationalConferenceonWorldWideWeb(ICWWW),2007:697-706.
[18]AuerS,BizerC,KobilarovG,etal.DBpedia:ANucleusforaWebofOpenData[C]//ProceedingsofInternationalSemanticWebConference(ISWC),2007:722-735.[19]Miller,GeorgeA.WordNet:alexicaldatabaseforEnglish[J].CommunicationsoftheAcm,1995,38(11):39-41.
[20]WangJ,WangZ,ZhangD,et.al.Combiningknowledgewithdeepconvolutionalneuralnetworksforshorttextclassification[C]//InTwenty-SixthInternationalJointConferenceonArtificialIntelligence(AAAI),2017:2915-2921.
[21]ChenJ,HuY,LiuJ,etal.DeepShortTextClassificationwithKnowledgePoweredAttention[C]//ProceedingsoftheAAAIConferenceonArtificialIntelligence,2019,33(1):6252-6259.10ComputerEngineeringandApplications
[22]ZhangZ,HanX,LiuZ,etal.ERNIE:Enhancedlanguagerepresentationwithinformativeentities[J].arXivpreprintarXiv:1905.07129,2019.
[23]LiuW,ZhouP,ZhaoZ,etal.K-bert:Enablinglanguagerepresentationwithknowledgegraph[J].arXivpreprintarXiv:1909.07606,2019.
[24]AnastasopoulosA,KumarS,LiaoH.NeuralLanguageModelingwithVisualFeatures[J].arXivpreprintarXiv:1903.02930,2019.
[25]ZadehA,ChenM,PoriaS,etal.TensorFusionNetworkforMultimodalSentimentAnalysis[C]//empiricalmethodsinnaturallanguageprocessing,2017:1103-1114.
[26]NamH,HaJW,KimJ.DualAttentionNetworksforMultimodalReasoningandMatching[C]//ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition.2017:299-307.
[27]LuJ,BatraD,ParikhD,etal.ViLBERT:PretrainingTask-AgnosticVisiolinguisticRepresentationsforVision-and-LanguageTasks[J].arXivpreprintarXiv:1908.02265,2019.
[28]LiLH,YatskarM,DYin,etal.VisualBERT:ASimpleandPerformantBaselineforVisionandLanguage[J].arXivpreprintarXiv:1908.03557,2019.
[29]AlbertiC,LingJ,CollinsM,etal.FusionofDetectedObjectsinTextforVisualQuestionAnswering[J].arXivpreprintarXiv:1908.05054,2019.
[30]KielaD,BhooshanS,HFirooz,etal.SupervisedMultimodalBitransformersforClassifyingImagesandText[J].arXivpreprintarXiv:1909.02950,2019.
[31]WuL,PetroniF,JosifoskiM,etal.ScalableZero-shotEntityLinkingwithDenseEntityRetrieval[C]//Proceedingsofthe2020ConferenceonEmpiricalMethodsinNaturalLanguageProcessing(EMNLP).2020:6397-6407.
[32]BordesA,UsunierN,Garcia-DuranA,etal.TranslatingEmbeddingsforModelingMulti-relationalData[C]//InProceedingsofthe26thInternationalConferenceonNeuralInformationProcessingSystems(NIPS)-Volume2,2013:2787-2795.[33]HanX,CaoS,LvX,etal.OpenKE:AnOpenToolkitforKnowledgeEmbedding[C]//Proceedingsofthe2018ConferenceonEmpiricalMethodsinNaturalLanguageProcessing:SystemDemonstrations(EMNLP),2018:139-144.
[34]HeK,ZhangX,RenS,etal.DeepResidualLearningforImageRecognition[J].IEEE,2016:770-778.
[35]DosovitskiyA,BeyerL,KolesnikovA,etal.AnImageisWorth16x16Words:TransformersforImageRecognitionatScale[J].arXivpreprintarXiv:2010.11929,2020.
[36]ArevaloJ,SolorioT,MMontes-Y-Gómez,etal.GatedMultimodalUnitsforInformationFusion[J].arXivpreprintarXiv:1702.01992,2017.
[37]YuJ,JiangJ,XiaR.Entity-sensitiveattentionandfusionnetworkforentity-levelmultimodalsentimentclassification[J].IEEE/ACMTransactionsonAudio,Speech,andLanguageProcessing,2019,28:429-439.