������Ŀ:End-to-End Object Detection with Transformers 2020
?���ĸ��ֿɲο�:��Ŀ���� | DETR:����transformers�˵��˵�Ŀ����_����|????�IJ���-CSDN����
���ĵ�ַ:2005.12872.pdf (arxiv.org)?
Ŀ¼
2.2.��ͷע����multi-head attention:
2.3.λ�ñ���Positional encoding:
3.1.��ƪ�����봫ͳ��transformer��������ʲô?
3.2.encoder��Ϊʲôֻ��qk����λ�ñ���(v��û��)?
?һ:���ķ���

?ժҪ
���������һ�ֽ���������Ϊֱ�Ӽ���Ԥ��������·��������ǵķ������˼�ⷽʽ,��Ч�������˶������˹���Ƶ����������,�����������ƹ���(NMS)��ê������,��Щ�����ȷ�ر��������ǹ����������ǰ֪ʶ���¿�ܵ���Ҫ�ɷֳ�ΪDEtection TRansformer��дΪDETR,�ǻ��ڼ��ϵ�ȫ�����,ͨ������ƥ��ǿ�ƽ��ж��ص�Ԥ��,�Լ�transformer������ - �������ܹ�������һ��̶���ѧϰ�����ѯ,DETR ���������ȫ��ͼ�������ĵĹ�ϵ,��ֱ�Ӳ���������յ�Ԥ�⼯�������������ִ�̽������ͬ,��ģ���ڸ����Ϻܼ�,����Ҫר�ŵĿ⡣DETR �ھ�����ս�Ե� COCO ���������ݼ�����ʾ��ȷ�Ժ�����ʱ�����������Ҹ߶��Ż��ĸ��� RCNN �����൱������,DETR���Ժ����ط���,��ͳһ�ķ�ʽ����ȫ���ָ���DZ���,���ı����������ھ������ߡ�ѵ�������Ԥѵ��ģ�Ϳ��� https://github.com/facebookresearch/detr ��á�
1 ����
? �������Ŀ����Ϊÿ������Ȥ������Ԥ��һ��߽�������ǩ�����еļ�����Լ�ӵķ�ʽ����������Ԥ��������Լ�ӵķ�ʽ����������Ԥ�������,�������ڴ����Ľ���[37,5]��ê��[23]������[53,46]�϶�������ع�ͷ������⡣���ǵ������ܵ��������������Ӱ��,��Щ������������۵������ظ���Ԥ��,ê�㼯����ƺ�����ʽ������Ŀ�������ê[52]��Ϊ�˼���Щ�ܵ������������һ��ֱ�ӵļ���Ԥ�ⷽ�����ƹ������������ֶ˵��˵������Ѿ��ڸ��ӵĽṹ��Ԥ��������ȡ�����ش��չ,��������������ʶ��,����û����������:��ǰ�ij���[43,16,4,39]Ҫô������������ʽ������֪ʶ,Ҫôû�б�֤���ھ�����ս�ԵĻ�����ǿ��Ļ��߾���������ּ���ֲ���һ��ࡣ
? ����ͨ���������⿴����һ��ֱ�ӵļ���Ԥ����������ѵ��Ԥ�����⡣���Dz����˻���transformers�ı�����-�������ܹ�[47],����һ�����е�����Ԥ��ܹ���transformers����ע�����,����ȷ��ģ����������Ԫ��֮������гɶԻ���,ʹ��Щ�ܹ��ر��ʺ��ڼ�Ԥ����ض�����,��ȥ���ظ���Ԥ�⡣
? ���ǵļ��任��(DETR,��ͼ1)һ��Ԥ�����е����塣һ����Ԥ�����е�����,��ͨ���趨����ʧ�������ж˵��˵�ѵ��,��Ԥ�������͵�����ʵ����֮���������ƥ�䡣DETRͨ����������ֹ���Ƶı�������֪ʶ����������ܵ�������֪ʶ,��ռ�ê������ѹ�ơ����������еļ�ⷽ����ͬ,DETR����Ҫ�κζ��ƵIJ�,��˿��Ժ��������κεط����ơ����,�������κΰ�����CNN��ת������Ŀ�������ɸ��֡�
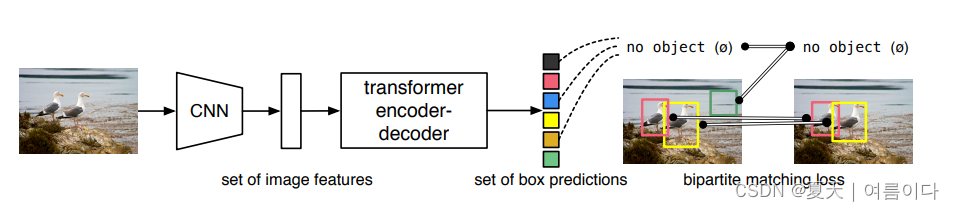 ͼ1:DETR?ͨ�����һ����ͨ��CNN��transformer�ܹ�,ֱ��Ԥ��(����)���յļ�⼯�ϡ�
ͼ1:DETR?ͨ�����һ����ͨ��CNN��transformer�ܹ�,ֱ��Ԥ��(����)���յļ�⼯�ϡ�
��ѵ��������,����ƥ���һ���ؽ�Ԥ�����з��䡣û��ƥ���Ԥ��Ӧ�ò���һ�� "����"(?)��Ԥ�⡣
??����ǰ���������ֱ�Ӽ�Ԥ��Ĺ������,DETR����Ҫ�ص��ǽ���˶�Ԫƥ����ʧ��transformers��(���Իع�)���н���[29,12,10,8]�����֮��,��ǰ�Ĺ�����������RNN�����Իع����[43,41,30,36,42]�����ǵ�ƥ����ʧ����Ψһ�ؽ�Ԥ�����������ʵԤ��ֵ,���Ҷ�
��Ԥ�����ı����Dz����,�������ǿ��Բ��е�ӳ�����ǡ�
??�����������е����������ݼ�COCO[24]֮һ��������DETR,��dz��о�������Faster R-CNN����[37]���жԱȡ�Faster RCNN�����˶����Ƶ���,��������������������õ��˼������ߡ��������������,�����ܵõ��˼���ĸ��ơ����ǵ�ʵ�����,���ǵ���ģ��ʵ�����൱�����ܡ���ȷ�е�˵,DETR���ֳ��ڴ��������ϵ��������Ը���,��һ�����������transformers�ķǾֲ����㡣Ȼ��,����С�����ϻ�õ����ܽϵ͡�����ϣ��δ���Ĺ����ܹ������ⷽ������
����FPN[22]��Faster R-CNN�Ŀ���һ����
??DETR��ѵ�������ڶ�������������̽������ͬ����ģ����Ҫ������ѵ��ʱ���,����transformer�ĸ���������ʧ�л��档���dz���̽������Щ�������չʾ������������Ҫ��
DETR����������������չ�������ӵ����������ǵ�ʵ����,���DZ���һ���ķָ�ͷ��Ԥѵ����DETR�Ļ����Ͻ���ѵ��,��Panoptic Segmentation[19]�ϳ����˾����Ļ��ߡ�����һ�������ս�Ե����ؼ�ʶ������,����Ѿ��õ����ռ���
2.��ع���
?���ǵĹ��������ڼ�����������й���֮��:���ڼ���Ԥ���˫��ƥ����ʧ,����transformer�ı�����-�������ܹ���ƽ�н���,�Լ������ⷽ����
2.1.����Ԥ��
? û�е��͵����ѧϰģ�Ϳ���ֱ��Ԥ�⼯�ϡ������ļ���Ԥ��Ļ��������Ƕ��ǩ����(����,��[40,33]�й��ڼ�����Ӿ��IJο�����)�����еĻ��߷���,һ��һ,���������ڼ�������,����Щ������,Ԫ��֮�������һ�������ṹԪ��(��������ͬ�ĺ���)֮��Ľṹ����Щ�����еĵ�һ��������Ҫ������Ƶ��ظ���Ŀǰ����������ʹ�ú���,�������ȵ�����������������,����ֱ�ӵļ���Ԥ���Dz���Ҫ������������Ҫȫ����������,������Ԥ��Ԫ��֮�������ý��н�ģ������Ԥ��Ԫ��֮��������,�Ա������ࡣ���ں㶨��С�ļ���Ԥ��,�ܼ���ȫ��������[9]���㹻��,���ɱ��ܸߡ�һ��һ��ĵķ�����ʹ���Զ��ع������ģ��,��ݹ�������[48]�������е������,��ʧ����Ӧ���Dz����,��ΪԤ��ı仯�Dz���ġ�ͨ���Ľ�����������������㷨[20]�Ļ��������һ����ʧ,���ҵ�����ʵ����Ԥ��֮���˫��ƥ�䡣��ͼ�ǿ�˱���IJ�����,����֤ÿ��Ŀ��Ԫ����һ��Ψһ��ƥ�䡣���Dz�����˫��ƥ�����ʧ������Ȼ��,��������ǰ�Ĺ�����ͬ,���ǰ������Իع�ģ��,��ʹ����transformer�벢�н���,���ǽ�������������
2.2.transformer��ƽ�н���
?transformer����Vaswani����[47]�����,��һ���µĻ���ע�����Ļ���������¹�����ע��������[2]�Ǿۺ���������������Ϣ��������㡣transformer����������ע���,��DZ���������[49]����,��ɨ�����е�ÿ��Ԫ��,��ͨ���ۺ��������е���Ϣ��������������ע������ģ�͵���Ҫ����֮һ�����ǵ�ȫ�ּ���������ļ���,��ʹ�����DZ�RNNs���ʺ��ڳ����С�transformer����������Ȼ���Դ��������������ͼ�����Ӿ�������������ȡ����RNNs[8,27,45,34,31]��? ? ? ?transformer���ȱ������Զ��ع�ģ��,��ѭ���ڵ�����-����ģ��[44],��һ���������ǡ�Ȼ��,��������ȴ���������ɱ�(��������ȳ�����,������������)�����˲����������ɵķ�չ,����Ƶ����[29]����������[12,10],���ʱ�ʾѧϰ[8],�Լ����������ʶ��[6]�����ǻ���transformer��ƽ�н���������,��Ϊ�����ڼ���ɱ���ִ��ȫ�ּ��������֮��������ʵ���Ȩ�⼯Ԥ�������ȫ�ּ����������
2.3.Ŀ����
? ������ִ������ⷽ���������һЩ��ʼ�²����Ԥ��ġ����μ�ⷽ��[37,5]������Ϊ����Ԥ�ⷽ��,�����η�������ê��[23]����ܵ�������������[53,46]����Ԥ�⡣����Ĺ���[52]����,��Щϵͳ������������Щϵͳ�����������ںܴ�̶���ȡ������Щ��ʼ�²��ȷ�����÷�ʽ�������ǵ�ģ����,�����ܹ����������ֹ������Ĺ���,��ͨ��ֱ��Ԥ����о�������ļ�⼯�������̡�Ԥ������ͼ��,������һ��ê��
? ���ڼ��ϵ���ʧ��һЩ��������[9,25,35]ʹ����˫��ƥ��ġ�Ȼ��,����Щ���ڵ����ѧϰģ����,��ͬ��Ԥ��֮��Ĺ�ϵ֮��Ĺ�ϵֻ�þ������ȫ���Ӳ�����ģ,�������ֹ���Ƶ�NMS�������ֹ���Ƶ�NMS����������������ܡ�����ļ����[37,23,53]ʹ���˻�����ʵ��Ԥ��֮��ķ�Ψһ��������Լ�NMS��
? ��ѧϰ��NMS����[16,4]��ϵ����[17]��ȷ��ģ����ע�ⲻͬԤ��֮��Ĺ�ϵ��ʹ��ֱ�Ӽ�����ʧ�����Dz���Ҫ�κκ������衣Ȼ��,��Щ�������ö�����ֹ�����������������,�罨������������Ч��ģ��̽��֮��Ĺ�ϵ,������Ѱ�ҵĽ�������Ǽ�����ģ���б��������֪ʶ��
? �ݹ������������ǵķ�����ӽ����Ƕ˵��˼���Ԥ������������[43]��ʵ���ָ�[41,30,36,42]�����������ơ�����ʹ�û���CNN����ı�����-�������ܹ���˫����ƥ����ʧ��ֱ�Ӳ���һ��Ԥ�⡣CNN�ļ�����ֱ�Ӳ���һ��߽��Ȼ��,��Щ����ֻ��С���ݼ��Ͻ���������,��û������ִ����ߡ��ر���,�����ǻ����Իع�ģ��(��ȷ�е�˵,��RNN)����������û����������IJ��н����transformer��
3.DETRģ��
? ����е�ֱ�Ӽ���Ԥ��������Ҫ��:(1)һ������Ԥ����ʧ,��ʹԤ��͵�����ʵ֮���Ψһƥ�䡣(2)һ����Ԥ��(����)һ�����岢�����ϵ���н�ģ�Ľṹ��������ͼ2����ϸ���������ǵļܹ���
3.1.�����⼯Ԥ����ʧ
3.2.DETR�ܹ�
? DETR������ṹ����ؼ�,��ͼ2��������������������Ҫ����,���ǽ��������������:һ��CNN����,������ȡһ�����յ�������ʾ,һ������-������ת����,�Լ�����CNN���ɡ���ȡһ�����յ�������ʾ,һ��������-������ת����,һ����ǰ������(FFN),�������յļ��Ԥ�⡣
? �������ִ��������ͬ,DETR�������κ����ѧϰ�����ʵ��,�ÿ���ṩ��һ��ͨ�õ�CNN�Ǹɺ�һ�����м����е�ת�����ܹ�ʵ�֡�DETR���������������PyTorch[32]���ò���50��ʵ�֡�����ϣ�����ǵķ����ļ����ܹ������µ��о���Ա������������
??
?ͼ2:?DETRʹ��һ����ͳ��CNN������ѧϰһ������ͼ��Ķ�ά��ʾ����ģ�Ͷ�����б�ƽ������,���ڽ��䴫�ݸ��任��������֮ǰ��λ�ñ�����в��䡣���䴫�ݸ�һ��transformer��������Ȼ��,transformer��������ѧϰ��������λ��Ƕ����Ϊ���롣���dz���Ϊ�����ѯ,���ڽ����������������̶�������λ��Ƕ�롣�����ע����������������ǽ���������ÿ�����Ƕ�봫�ݸ�һ��������ǰ������(FFN),������Ԥ��һ�����(���ͱ߽��)�� "������ "�ࡣ
? �������硣�ӳ�ʼͼ��Ximg��R 3��H0��W0(��3��ɫͨ��),һ����ͳ��CNN�Ǹ���������һ���ϵͷֱ��ʵļ���ͼf��R C��H��W������ʹ�õĵ���ֵ��C = 2048,H, W =H0/32 ,W0/32 .
??Transformer������������,һ��1x1�ľ�����������ͼf��ͨ��ά�ȴ�C���ٵ���С��ά��d��
�µ�����ͼz0��R d��H��W��������ϣ����һ��������Ϊ����,������ǽ�z0�Ŀռ�ά���۵���һ��ά��,�Ӷ��õ�һ��d��HW������ͼ��ÿ���������㶼��һ�����Ľṹ,��һ����ͷ������ע��ģ���һ��ǰ������(FFN)�����ڱ任���ṹ�Dz����,�����ù̶���λ�ñ���[31,3],��Щ���뱻���ӵ�ÿ��ע������������С����Ǽܹ�����ϸ���彫�Ƴٵ����������,����ѭ[47]�е�������
? Transformer����������������ѭת�����ı��ṹ��transformer�ı��ṹ,ʹ�ö�ͷ���Ժ�
������-������ע����ơ���ԭʼת������������,���ǵ�ģ����ÿ�����������N��������в��н��롣��Vaswani����[47]ʹ��һ���Իع�ģ��(autoregressive model),ÿ��Ԥ�������˳��һ��Ԥ��һ��Ԫ�ء������벻��Ϥ��Щ����Ķ��߲ο�������ϡ����������ڽ�����Ҳ�ǻ�������ġ�N������Ƕ������Dz�ͬ��,�Բ�����ͬ�Ľ������Щ����Ƕ����ѧϰ����λ�ñ���,���ǽ����Ϊ�����ѯ�������������,���ǽ��������ӵ�ÿ��ע������������С�N�������ѯ��������ת��Ϊ���Ƕ�롣Ȼ��,���DZ�һ��ǰ����������ؽ���Ϊ�������������ǩ��һ��ǰ������(����һС��������),����N�����յ�Ԥ�⡣ʹ�����Һͱ�����-����������ЩǶ��Ĺ�ע����ģ��ʹ�óɶԵĹ�ϵ�������������ȫ������֮��Ĺ�ϵ,ͬʱ�ܹ�ʹ������ͼ����Ϊ������
??����Ԥ��ǰ������(FFNs)�����յ�Ԥ������һ������ReLU�����������ά��d��3���֪����һ������ͶӰ�����ġ�FFNԤ����ǹ�һ�����������ꡢԤ���ĸ߶ȺͿ���(���������ͼ��),�����Բ���ʹ��softmax����Ԥ������ǩ����������Ԥ�����һ���̶���С��N���߽��,��Nͨ����ͼ���и���Ȥ�������ʵ������Ҫ��ö�,����һ��������������ǩ?��������ʾ��һ������û�м��κ����塣�������������������ⷽ���е� "���� "�����ƵĽ�ɫ��
? ����������ʧ�����Ƿ�����ѵ��������ʹ�ø�����ʧ[1]�Խ��������а���,�ر��ǰ���ģ�����ÿ��������ȷ�����Ķ���������ÿ�������֮������Ԥ���FFN����������ʧ����������֮�����е�Ԥ��FFNs�������ǵIJ���������ʹ��һ������Ĺ�����淶���淶���Բ�ͬ������Ԥ��FFN�����롣
4.ʵ��
? ���DZ���,��Faster R-CNN���,DETR��COCO��������ȡ�����о������Ľ����Ȼ��,�����ṩ��һ����ϸ�����ڼܹ�����ʧ����ϸ�о�,���ṩ����Ͷ��Խ�������,Ϊ�˱���DETR��һ����ܺͿ���չ��ģ��,������������½������չʾ����ȫ���ָ��ϵĽ��,ֻ�ڹ̶���DETR��ѵ����һ��С����չ�������ṩ�����Ԥѵ����ģ�����������ǵ�ʵ��,��ַ��:https://github.com/facebookresearch/detr��
���ݼ���������COCO 2017����ȫ���ָ����ݼ�[24,18]�Ͻ�����ʵ��,����118kѵ��ͼ���5k��֤ͼ��ÿ��ͼ���б߽���ȫ���ָ��ע�͡�ÿ��ͼ��ƽ����7��ʵ��,��ѵ������ͼ���������63��ʵ��,����ͬ��ͼ���д�С���ȡ����û��ָ��,���ǽ�AP����Ϊbbox AP,�������ֵ�Ļ���ָ�ꡣΪ����Faster R-CNN���бȽ�,���DZ��������һ��ѵ��ʱ����֤AP,��������,���DZ��������10�ε���֤�������λ��epochs��
����ϸ�ڡ�������AdamW[26]ѵ��DETR,����ʼ��ѹ����ѧϰ������Ϊ10-4,������Ϊ10-5
,��Ȩ��˥��Ϊ10-4.����ת������Ȩ�ض�����Xavier init [11]��ʼ����,�Ǹ���������Torchvision��ImageNet-pretrained ResNetģ��[15]�Ͷ����batchnorm�㡣���DZ�����������ͬ�ǸɵĽ��:ResNet50��ResNet101����Ӧ��ģ�ͷֱ𱻳�ΪDETR��DETR-R101����[21]֮��,���ǻ�ͨ�������һ��������һ����������������ֱ��ʡ��ڹǸ��������һ����������һ������,��������εĵ�һ��������ɾ����һ����ȡ��εĵ�һ������,�Ӷ���������ֱ��ʡ���Ӧ��ģ�ͷֱ𱻳�ΪDETR-DC5��DETR-DC5-R101(���ŵ�C5��)�������Ľ��ֱ��������2��,�Ӷ�����˶�С��������ܡ����������,�������DZ����������ҹ�ע�������16���������������ɱ�����2����ȫ��Ƚ���Щģ�ͺ�Faster R-CNN��FLOPs��ȫ��Ƚϼ���1��
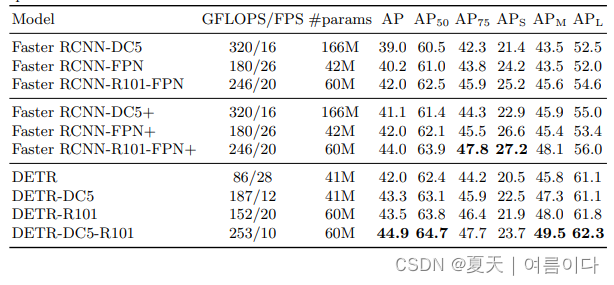
?��1:�����ResNet-50��ResNet-101���ɵ�Faster R-CNN����COCO��֤���ϵıȽϡ����˲�����ʾ��Faster R-CNNģ����Detectron2[50]�еĽ��,�м䲿����ʾFaster R-CNNģ����
GIoU[38]���������ѵ��ʱ������Ӻͳ���9��ѵ���ƻ���Faster R-CNNģ�͵Ľ����DETRģ��ȡ�������ضȵ�����Faster R-CNN�����൱�Ľ�����нϵ͵�APS,����������APL������ʹ��torchscript Faster R-CNN��DETRģ��������FLOPS��FPS��������û��R101�Ľ����Ӧ��ResNet-50��
����ʹ�ñ�����ǿ��,��������ͼ��Ĵ�С,ʹ����̵�һ������Ϊ480,���Ϊ800����,�����һ��Ϊ1333[50]����������480,�����800����,�������1333[50]��Ϊ��ͨ��������������ע��������ѧϰȫ�ֹ�ϵ�����ǻ���ѵ��������Ӧ��������ü���ǿ,����˴�Լ1��AP�����ܡ�������˵,ѵ��ͼ�ü�Ϊ����0.5�ü���һ������ľ��ΰ߿�,Ȼ���ٴε�����СΪ
800-1333. �任����ѵ��Ĭ��Ϊ0.1���˲�����������ʱ,��Щ�۵�Ԥ���ǿ��ࡣΪ���Ż�AP,�����õڶ��߷ֵ�����������Щ�۵�Ԥ��,ʹ����Ӧ�����Ŷȡ�����˵��ղ����,�����������2�ֵ�AP������ѵ��������������A.4�����ҵ����������ǵ�����ʵ����,����ʹ����300�ֵ�ѵ���ƻ�,ѧϰ����200�ֺ��½���10����200�ֺ�,ѧϰ���½�10��,����һ����ʱ�Ƕ�����ѵ��ͼ���һ�δ��ݡ���16��V100 GPU��ѵ��300��epochs�Ļ���ģ����Ҫ3��ʱ��,ÿ̨GPU��4��ͼ��(��������δ�СΪ64)������������Faster R-CNN���бȽϵĽϳ���ʱ���,����ѵ����500��epochs400�ֺ�,ѧϰ���½�����϶̵ļƻ����,������1.5��AP��
4.1.��Faster R-CNN�ıȽ�
transformersͨ������Adam��Adagrad�Ż�������ѵ����,ѵ��ʱ��ܳ���dropout,���DETRҲ����ˡ�Ȼ��,R-CNN����SGD����ѵ����,��������С,�������ǻ�û�з���Adam��Dropout�ijɹ�Ӧ�á����Dz�֪��Adam��dropout�ijɹ�Ӧ�á����ܴ�����Щ����,���ǻ�����ͼʹFaster R-CNN�Ļ��߸���ǿ��Ϊ����DETR����һ��,���ǽ������IoU[38]���ӵ�������ʧ��,ͬ����������Ӻͳ�ʱ���ѵ��,��֪���Ը��ƽ��[13]������ڱ�1���г���������IJ���,������ʾ��Faster R-CNN�Ľ����3��ʱ���ѵ����ģ��,����Detectron2 Model Zoo [50]����
�м䲿��������ʾ����ͬģ�͵Ľ��(�� "+"),��ѵ������9����ʱ���(109��)����������ǿ��ʩ,�ܹ�������1-2��AP���ڱ�1�����һ��,������ʾ�˶��DETRģ�͵Ľ����Ϊ���ڲ����������Ͼ��пɱ���,����ѡ����һ������6����ѹ����6����������ģ��,����Ϊ256,��8��ע��ͷ�������FPN��Faster R-CNһ��,���ģ����41.3M�IJ���,����23.5M�IJ������ڷֱ��С�����23.5M��ResNet-50��,17.8M�ڱ任���С�����Faster R-CNN��DETR���п���ͨ������ʱ���ѵ������һ��ѵ��,���ǿ��Եó�����,DETR��������ͬ�IJ�����������Faster R-CNN����,��COCOֵ�Ӽ��ϴﵽ42��AP��DETRʵ����һĿ��ķ��������APL(+7.8),����Ҫע�����ģ����APS������Ȼ���(-5.5)��DETR-DC5����ͬ�IJ����������Ƶ�FLOP���µIJ��������Ƶ�FLOP���и��ߵ�AP,����APS������Ȼ����������R-CNN�ʹ���ResNet-101���ɵ�DETR��ʾ�˵Ľ��Ҳ���൱�ġ�
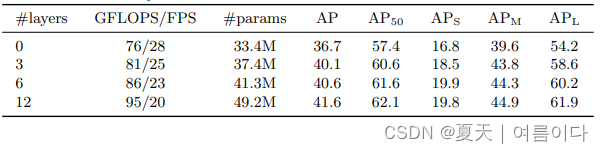
��2:�������ߴ��Ӱ�졣ÿһ�ж���Ӧ��һ�����в�ͬ�����ı����������̶��Ľ�����������ģ��,������������ű��������������ӡ�
4.2.����ʵ��?
4.3.����
4.4.����ȫ���ָ��DETR
5.����
6.��л
A ��¼
A.1.����:��ͷע������
��ͷ:
A.2.��ʧ
A.3.ϸ�ڼܹ�
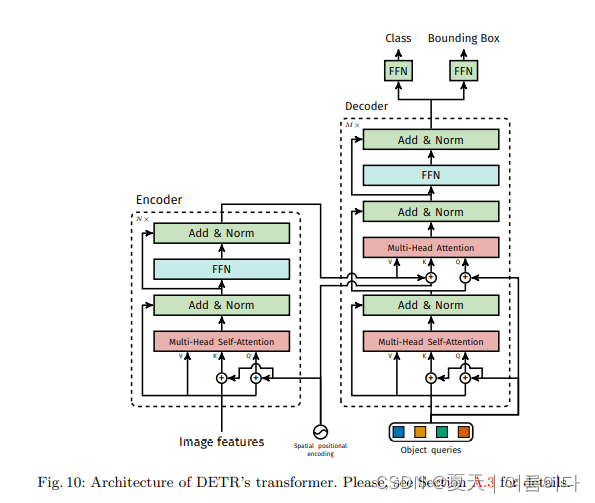
ͼ10��������DETR��ʹ�õ�transformer����ϸ����,��ÿ��ע��㶼��λ�ñ��봫�ݡ�����CNN���ɵ�ͼ������ͨ��transformer������,ͬʱ���пռ�λ�ñ���,��Щ���뱻���ӵ�ÿ����ͷ����ע���IJ�ѯ����Կ�С�Ȼ��,���������ղ�ѯ(�������Ϊ��)�����λ�ñ���(�����ѯ)�ͱ������ڴ�,ͨ�������ͷ����ע��ͽ�����-������ע��������յ�Ԥ�����ǩ�ͱ߽��һ����ע����еĵ�һ������������Ա�������
A.6.PyTorch ��������
Ϊ��֤���÷����ļ���,�������嵥1�м�������������,���а����嵥1�е�PyTorch��Torchvision�⡣�ô�����Python 3.6���ϰ汾�����С�PyTorch 1.4��Torchvision 0.5����ע��,����֧��������,�����ֻ������������ʹ�÷ֲ�ʽ���ݲ��е�ѵ��,ÿ��GPU��һ��ͼ����ע��,Ϊ���������,��δ����ڱ�������ʹ����ѧϰ����λ�ñ���,���DZ���,�����ǹ̶��ı���,����λ�ñ���ֻ�����ӵ�������,��������ÿ������ʱ����������ÿ��ת��������λ�ñ��롣����Щ�ı���Ҫ��ԽPyTorch�Ա任����ʵ��,������˿ɶ��ԡ�������Щʵ���ȫ�����뽫�ڻ���ǰ������
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def__init__(self,num_classes,hidden_dim,nheads,num_encoder_layers,num_decoder_layers):
super().__init__()
self.backbone=nn.Sequential(*list(resnet50(pretrained=True),children())[:-2])
self.conv=nn.Conv2d(2048,hidden_dim,nheads,num_encoder_layers.num_decoder_layers)
self.linear_class=nn.Linear(hidden_dim,num_class+1)
self.linear_bbox=nn.Linear(hidden_dim,4)
self.query_pos=nn.Parameter(torch.rand(100,hidden_dim))
self.row_embed=nn.Parameter(torch.rand(50,hidden_dim//2))
self.col_embed=nn.Parameter(torch.rand(50,hidden_dim//2))
def forward(self,inputs):
x=self.backbone(inputs)
h= self.conv(x)
H,W=h.shape[-2:]
pos=torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),
self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr=DETR(num_classes=91,hidden_dim=256,nheads=8,num_encoder_layers=6,num_decoder_layers=6)
detr.eval()
inputs=torch.randn(1,3,800,1200)
logits,bboxs=detr(inputs)�嵥1:DETR PyTorch�������롣Ϊ��������,���ڱ�������ʹ����ѧϰ����λ�ñ���,�����ǹ̶���,����λ�ñ��뱻���ӵ��������ж�������ÿ���任�����С�����Щ�ı���Ҫ��Խ
PyTorch�Ա任����ʵ��,������˿ɶ��ԡ�������������ʵ���ȫ�����뽫�ڻ���ǰ�ṩ��
*��:�ؼ�֪ʶ��
2.1.����-����Encoder-Decoder:
Encoder����������??ӳ�䵽һ��������ʾ����,���ڱ���õ���z,Decoderÿ�ν�������һ������,ֱ�������������������:?������ÿһ������,ģ�Ͷ����Իع��,����������һ������ʱ����ǰ���ɵķ�����Ϊ�������롣
Class Encoder(nn.Module)
��init����(��ʼ��)�дģ�͵Ļ������,��:one-hot��������,λ�ñ�����Ϣ����,encoder�ڲ��ܹ��Ķѵ�;
��forward����(ʵ��)����������������ʽ���б�д�������enc_outputs��������������һ������,��������������(��Ϊ������ͷ�������Ľ��)
- ����encoder,�������״��[batch_size * source_len]��batch*���ӳ���
- ����������ת��Ϊ��Ӧ������?
- ������������(������������Ӧ�ľ���)����λ�ñ����,�ٽ��õ���λ�ñ�����Ϣ,����������(����Ϣ����Ϊ:������+λ�ñ���)λ�ñ����ʵ�ֿɼ�����PositionalEncoding
- �˹�pad��Ϣ
- ��ѭ����encoderlayer�ѵ�����,��������Ϊ��һ�����Ϣ����Щ��pad��Ϣ��
Class EncoderLayer(nn.Module)
��init����(��ʼ��)�дģ�͵Ļ������,��:��ͷ��ע�������Ʋ�,ǰ���������
��forward����(ʵ��)����������������ʽ���б�д�����Ƚ����ͷ��ע�������Ʋ�,�������״��(q*k*v*pad��Ϣ)
2.2.��ͷע����multi-head attention:
Class MultiHeadAttention(nn.Module)
��init����(��ʼ��)�дģ�͵Ļ������,��:3��ӳ�����Q,K,V;���ұ�֤3������ͷ����ͬ,,�����LayerNorm
��forward����(ʵ��)����������������ʽ���б�д��?
- ���Ƚ���ӳ���ͷ,ע��q��k��ά��Ҫһ��,��������˼���(�����DotProductAttention�����������ǵ�attention_scores)��
- ��������ÿ��ͷ������pad����Ϣ,�Ա����Ǻ����ļ�����Ч�ԡ�
-?������ʵ�ֵ��DotProductAttention�ļ���attention_scores,��������ע�����÷ֵõ����µ�Ȩ�غ�ľ�������һ��֮�����������pad��Ϣ�Ĺ��㻯��
2.3.λ�ñ���Positional encoding:
-λ�ñ�����һ���������,���������?
-forward����(ʵ��)��,ִ�е������ǽ�������������һ��������λ�ñ������(����Ϣ����,����Ϊ:������+λ�ñ���)?
-�����ġ�attention is all you need������ϸ����
- �ɲο���3��
class PositionalEncoding(nn.Module):
def __init__(self, dim, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
if dim % 2 != 0:
raise ValueError("Cannot use sin/cos positional encoding with "
"odd dim (got dim={:d})".format(dim))
"""
����λ�ñ���pe
pe��ʽΪ:
PE(pos,2i/2i+1) = sin/cos(pos/10000^{2i/d_{model}})
"""
pe = torch.zeros(max_len, dim) # max_len �ǽ��������ɾ��ӵ���ij���,������ 10
position = torch.arange(0, max_len).unsqueeze(1)
div_term = torch.exp((torch.arange(0, dim, 2, dtype=torch.float) *
-(math.log(10000.0) / dim)))
pe[:, 0::2] = torch.sin(position.float() * div_term)
pe[:, 1::2] = torch.cos(position.float() * div_term)
pe = pe.unsqueeze(1)
self.register_buffer('pe', pe)
self.drop_out = nn.Dropout(p=dropout)
self.dim = dim
def forward(self, emb, step=None):
emb = emb * math.sqrt(self.dim)
if step is None:
emb = emb + self.pe[:emb.size(0)]
else:
emb = emb + self.pe[step]
emb = self.drop_out(emb)
return emb
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1)
self.transformer = nn.Transformer(hidden_dim, nheads,
num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1)
self.linear_bbox = nn.Linear(hidden_dim, 4)
#object query
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim))
#position embedding
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
#inputs��[1,3,800,1200]
x = self.backbone(inputs)
#x��[1,2048,25,38]
h = self.conv(x)
#h��[1,256,25,38]
H, W = h.shape[-2:]
pos = torch.cat([
self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1)
#pos��[950,1,256]
#self.query_pos��[100,256]
#src��encoder����,tgt��decoder����
h = self.transformer(src = pos + h.flatten(2).permute(2, 0, 1),
tgt = self.query_pos.unsqueeze(1)
)
#h��[100,1,256]
return self.linear_class(h), self.linear_bbox(h).sigmoid()
#coco��91����, hidden dimension��256, ��ͷע������8, encoder,decoder layer����6
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
print(logits, bboxes)
#logits��[100,1,92]
#bboxes��[100,1,4]pytorch�´�������������
import torch
from torch import nn
'''torch.atleast_1d(*��)
����ÿ������������һά��ͼ,��ά��Ϊ�㡣����һ������ά�ȵ�����������ԭ�����ء�
����
����(�����������б�) �C
����
���(����������Ԫ��)'''
x = torch.randn(2)
print(x)
torch.atleast_1d(x)
x = torch.tensor(1.)
print(x)
torch.atleast_1d(x)
x = torch.tensor(0.5)
y = torch.tensor(1.)
torch.atleast_1d((x,y))
print(x,y)
#############################Transformer#######################################
'''����
d_model �C ������/������������Ԥ�ڹ��ܵ�����(Ĭ��ֵΪ 512)��
nhead �C ��ͷע��ģ���е�ͷ��(Ĭ��ֵΪ 8)��
num_encoder_layers �C ���������ӱ���������(Ĭ��ֵΪ 6)��
num_decoder_layers �C ���������ӽ������������(Ĭ��ֵΪ 6)��
dim_feedforward �C ǰ������ģ�͵�ά��(Ĭ��ֵΪ 2048)��
�ѧ �C �ѧֵ(Ĭ��ֵΪ 0.1)��
���� �D ������/�������м��ļ����, �������ַ��� (��relu�� �� ��gelu��) ��һԪ�ɵ��õġ�Ĭ��ֵ:����
custom_encoder �C �Զ��������(Ĭ��ֵΪ���ޡ�)��
custom_decoder �C �Զ��������(Ĭ��ֵΪ���ޡ�)��
layer_norm_eps �C ��淶������е� eps ֵ(Ĭ��ֵΪ 1e-5)��
batch_first �C ��� ,����������������Ϊ (��������seq������)�ṩ��Ĭ��ֵ:(���С�������������)��TrueFalse
norm_first �C ��� �������ͽ������㽫������ע���ǰ������֮ǰִ�� LayerNorms,������֮��ִ�С�Ĭ��ֵ:(֮��)��TrueFalse
'''
#����
transformer_model=nn.Transformer(nhead=16,num_encoder_layers=12)
#�ɸı��ͷ�ĸ����ͱ������,�����������ͬ
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
print(src,tgt)
############################Encoder#######################################
#Transformer�������� N ����������Ķ�ջ
'''����
encoder_layer �C ת������������() ��(����)��ʵ����
num_layers �C �������е��ӱ���������(����)��
norm �C ���һ������(��ѡ)��
enable_nested_tensor �C ���Ϊ True,���뽫�Զ�ת��ΪǶ������(�������ʱת����)���⽫��������ʽϸ�ʱ��߱�ѹ�����������������ܡ�Ĭ��ֵ:(����)��False'''
encoder_layer = nn.TransformerEncoderLayer(d_model=512, nhead=8)
transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=6)
src = torch.rand(10, 32, 512)
out = transformer_encoder(src)
print(src.shape)
############################Decoderͬ��#######################################2.4.�ռ�ê��Spatial anchors
2.5.FFN Prediction feed-forward networks
2.6.����ͼƥ��(bipartite matching)
DETRʹ����һ�����ڶ���ͼƥ��(bipartite matching)����ʧ����,�������ͼ�ǻ���ground truth��Ԥ���bounding box����ƥ���,������ƥ��Ľ������loss����ģ�ͽ����Ż�������ʹ��������ƥ���㷨���õ�ground truth��bounding box�����Ŷ�����ƥ�䷽����
������ƥ��:ѧϰ�С�����
*��:��������
3.1.��ƪ�����봫ͳ��transformer��������ʲô?
�����е��õ���torch.nn.Transformer��ģ��,��ԭ�е����������ط�:
A.λ�ñ���ͨ��MHattention����
B.�ڱ�����ĩ�˵�layerNorm�㱻�Ƴ���
C.���������ؽ��������м���������
����,�Ƴ�encoder layerĩ�˵�layerNorm(����ģ��)�Լ���decoder layer���븨����ʧ����(Auxiliary decoding losses)������������ϵ��ټ��ɡ���ԭ������Ȼ���Դ�����Ӧ�õ�transformer����ṹ���IJ�ͬ����position embedding layer��
3.2.encoder��Ϊʲôֻ��qk����λ�ñ���(v��û��)?
3.3.
self-attention����ôʵ�ֵ�?
*��:�ܽ�
4.1.DETR����Ҫ�����������:backbone layers(������ȡ��)->ͼƬԤ�������̡�transformer layers(����������)��prediction layers(Ԥ������)��
4.2.��DETR��������,���߽�ԭͼ�ָ�Ϊ32*32��С��ͼ���,����������,������Ȼ���Դ����о��ӵ��ʵ��������ޡ�
4.3.��DETR��,��patch image features embedding �� position embedding ֱ�����,Ȼ����transformer ��������ѵ����
4.4.��һ���CNN��,�����������ȡ,������ǰ�����������ȡ��С,����Transformer��,�������л�,����Ҫ�ܵ�֮ǰ�Ľ��Ӱ�졣��Ŀ��������Ҳ���һ�� Set Prediction ����,��һ����Ԥ��һ������,�����ǰ��� RNN һ��һ��һ��Ԥ�⡣
4.5.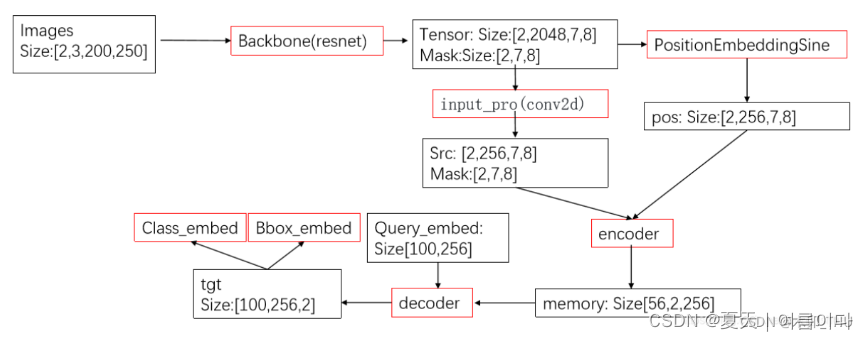
?4.6.��ͬ��Transformer���õı��뷽ʽ��ͬ
Transformer Position Embedding(PE), -sin-cos-1d
PE������Կ����������������,һ��������pos(/���),��һ��������i(/�ұ�),�����к�ż�����ٷֱ��sin��cos.
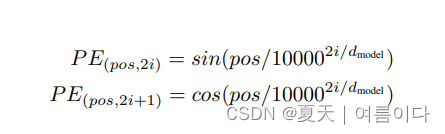
?ͨ��������PE,����ʵ������λ��ͨ�����е�λ�ñ���������ϱ�ʾ,��Ҫ��ż������sin,��������cos,Ҳ����ǰһ����sin,��һ����cos.
import torch
# 1d����sin_cos����
def create_1d_absolute_sin_cos_embedding(pos_len, dim):
assert dim % 2 == 0, "wrong dimension!"
position_emb = torch.zeros(pos_len, dim, dtype=torch.float)
# i����
i_matrix = torch.arange(dim//2, dtype=torch.float)
i_matrix /= dim / 2
i_matrix = torch.pow(10000, i_matrix)
i_matrix = 1 / i_matrix
i_matrix = i_matrix.to(torch.long)
# pos����
pos_vec = torch.arange(pos_len).to(torch.long)
# �������,pos���������,i_matrix���������
out = pos_vec[:, None] @ i_matrix[None, :]
# ��/ż����
emb_cos = torch.cos(out)
emb_sin = torch.sin(out)
# ��ֵ
position_emb[:, 0::2] = emb_sin
position_emb[:, 1::2] = emb_cos
return position_emb
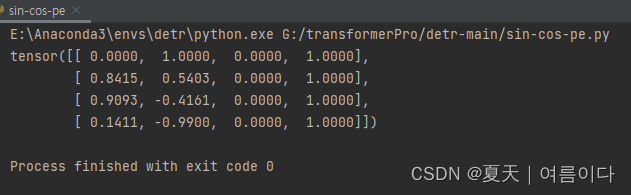
if __name__ == '__main__':
print(create_1d_absolute_sin_cos_embedding(4, 4))
?���:
?VIT PE - trainable 1d
�����position embedding��˼������word embedding,��һ��table��embbeding��
�����table�������ʼ����,��ģ�����ǿ�ѧϰ��
ʵ�־ͱȽϼ���,ʹ��nn.Embedding���ɡ�
import torch
import torch.nn as nn
def create_1d_learnable_embedding(pos_len, dim):
pos_emb = nn.Embedding(pos_len, dim)
# ��ʼ����ȫ0
nn.init.constant_(pos_emb.weight, 0)
return pos_emb
?Swin Transformer PE - trainable relative bias 2d
ʹ�õ��ǿ�ѧϰ�Ķ�ά�����λ�ñ���, bias������patch�����λ��ƫ��,���λ��ƫ��bias�ӵ�ÿ��head�ϼ������ƶ�
bias����������bias_emb_table������ҳ�һ����ѧϰ����B, B�ӵ�Q��K�Ľ����,Q��K shape��[seqL, seqL],���B��shape��[num_head, seqL, seqL]
import torch
import torch.nn as nn
def create_2d_relative_bias_trainable_embedding(n_head, h, w, dim):
pos_emb = nn.Embedding((2*w-1)*(2*h-1), n_head)
nn.init.constant_(pos_emb.weight, 0.)
def get_2d_relative_position_index(height, width):
# m1/m2.shape = [h, w],m1������ֵ��ͬ,m2����������ͬ
m1, m2 = torch.meshgrid(torch.arange(height), torch.arange(width))
# [2, h, 2]
coords = torch.stack([m1, m2], dim=0)
# ��h��wά����ֱ,[2, h*w]
coords_flatten = torch.flatten(coords, start_dim=1)
# ���3ά������[2, h*w, 1] ��ȥ 3ά������,�õ������ֵ
# relative_coords_bias.shape = [2, h*w, h*w],��Ӧ���������κ�������֮��IJ�ֵ
relative_coords_bias = coords_flatten[:, :, None] - coords_flatten[:, None, :]
# �����������,bias �� [0, 2(h - 1)]/[0, 2(w - 1)]
relative_coords_bias[0, :, :] += height - 1
relative_coords_bias[1, :, :] += width - 1
# ����������ת��һ����������, [i, j] -> [i*cols + j]
relative_coords_bias[0, :, :] *= relative_coords_bias[1, :, :].max()+1
return relative_coords_bias.sum(0) # [h*w, h*w]
relative_pos_bias = get_2d_relative_position_index(h, w)
# �������biasȥEmbedding��ȥ��
bias_emb = pos_emb(relative_pos_bias.flatten()).reshape([h*w, h*w, n_head])
# ת��һ��n_head,�ŵ���0ά
bias_emb = bias_emb.permute(2, 0, 1).unsqueeze(0) # [1, n_head, h*w, h*w]
return bias_emb
emb = create_2d_relative_bias_trainable_embedding(1, 2, 2, 4)
print(emb.shape)
MAE PE - sin-cos-2d
ʹ�õ�2ά��fixed��sine-cosine PE,û�������λ�ú�layer scaling
import torch
import trainable_1d_pe
def create_2d_absolute_sin_cos_embedding(h, w, dim):
# �����к�ż����sin_cos,����h��w����,���ά����4�ı���
assert dim % 4 == 0, "wrong dimension"
pos_emb = torch.zeros([h*w, dim])
m1, m2 = torch.meshgrid(torch.arange(h), torch.arange(w))
# [2, h, 2]
coords = torch.stack([m1, m2], dim=0)
# �߶ȷ����emb
h_emb = trainable_1d_pe.create_1d_learnable_embedding(torch.flatten(coords[0]).numel(), dim // 2)
# ���ȷ����emb
w_emb = trainable_1d_pe.create_1d_learnable_embedding(torch.flatten(coords[1]).numel(), dim // 2)
# ƴ������
pos_emb[:, :dim//2] = h_emb.weight
pos_emb[:, dim//2:] = w_emb.weight
return pos_emb
create_2d_absolute_sin_cos_embedding(2, 2, 4)
4..�ض�����Attention is all you need2017;An Image is Worth 16��16 Words: Transformers for Image Recognition at Scale2020 (Vision Transformers);
�����:
��1��?���ѧϰ֮Ŀ����(ʮһ)--DETR���_ľî_THU�IJ���-CSDN����_detr
��2��DETR��� - ֪�� (zhihu.com)?-���ӻ�����
��3��Transformer Architecture: The Positional Encoding - Amirhossein Kazemnejad's Blog