ǰ��
ǰ���Ѿ�����ʵ���˾�����ͳػ���,�����������Щ��,�������д����ʶ���CNN��
�����CNN���繹�����¡�
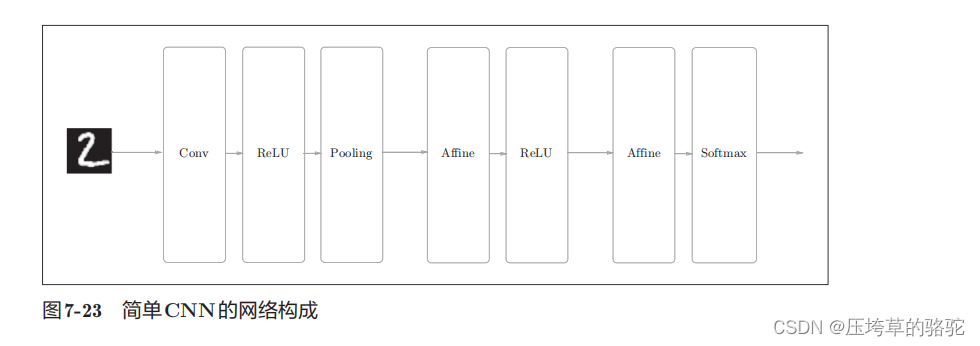
����Ĺ����ǡ�Convolution - ReLU - Pooling -Affine - ReLU - Affine - Softmax��,���ǽ���ʵ��Ϊ��ΪSimpleConvNet���ࡣ
������IJ���
? input_dim�D�������ݵ�ά��:(ͨ��,��,��)
? conv_param�D������ij�����(�ֵ�)��
�ֵ�Ĺؼ�������:
filter_num�D�˲���������
filter_size�D�˲����Ĵ�С
stride�D����
pad�D���
? hidden_size�D���ز�(ȫ����)����Ԫ����
? output_size�D�����(ȫ����)����Ԫ����
? weitght_int_std�D��ʼ��ʱȨ�صı���
������ij�����ͨ����Ϊconv_param���ֵ䴫�롣������������
��{��filter_num��:30,��filter_size��:5, ��pad��:0, ��stride��:1}��
���CNN����ij�ʼ����Ϊ�������֡�
��һ����:ȡ����ʼ�����������ij�����,�����������������С
class SimpleConvNet:
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5,'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) *(conv_output_size/2))
�ڶ�����:Ȩ�ز����ij�ʼ��,������һ������������ȫ���Ӳ��Ȩ�غ�ƫ�á��ֱ�ΪW1��b1��w2��b2��w3��b3
# ��ʼ��Ȩ��
self.params = {}
self.params['W1'] = weight_init_std * np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
������:���ɶ�Ӧ�IJ�,�������ֵ�(OrderedDict)��layers�����Ӳ㡣ֻ������SoftmaxWithLoss�㱻���ӵ���ı���lastLayer
# ���ɲ�
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
���Ͼ���SimpleConvNet�ij�ʼ���н��еĴ�����ÿһ��ĵ����ľ���ʵ���Ѿ���ǰ�������ᵽ,Ϊ����һ����CNN����,ÿһ���˾��ְ��
���������г�ʼ����,����������predict����������ʧ������loss�����������¡�
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""����ʧ����
����x���������ݡ�t�ǽ�ʦ��ǩ
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
predict������ͷ��ʼ���ε��������ӵIJ�,����������ݸ���һ�㡣
�������ǻ����������ݶ�
def gradient(self, x, t):
"""���ݶ�(������)
Parameters
----------
x : ��������
t : ��ʦ��ǩ
Returns
-------
���и�����ݶȵ��ֵ����
grads['W1']��grads['W2']��...�Ǹ����Ȩ��
grads['b1']��grads['b2']��...�Ǹ����ƫ��
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# �趨
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
��Ϊÿһ�����������ͷ����Ѿ��ڸ���ʵ��,Ҳ����forward()��backward()����,ֻ��Ҫ���ε���ÿһ��ķ�������,���ÿһ���и���Ȩ�ز������ݶȱ��浽grads�ֵ��С�
simple_convnet������
import sys, os
sys.path.append(os.pardir) # Ϊ�˵��븸Ŀ¼���ļ������е��趨
import pickle
import numpy as np
from collections import OrderedDict
from common.layers import *
from common.gradient import numerical_gradient
class SimpleConvNet:
"""��ConvNet
conv - relu - pool - affine - relu - affine - softmax
Parameters
----------
input_size : �����С(MNIST�������Ϊ784)
hidden_size_list : ���ز����Ԫ�������б�(e.g. [100, 100, 100])
output_size : �����С(MNIST�������Ϊ10)
activation : 'relu' or 'sigmoid'
weight_init_std : ָ��Ȩ�صı���(e.g. 0.01)
ָ��'relu'��'he'��������趨��He�ij�ʼֵ��
ָ��'sigmoid'��'xavier'��������趨��Xavier�ij�ʼֵ��
"""
def __init__(self, input_dim=(1, 28, 28),
conv_param={'filter_num':30, 'filter_size':5, 'pad':0, 'stride':1},
hidden_size=100, output_size=10, weight_init_std=0.01):
filter_num = conv_param['filter_num']
filter_size = conv_param['filter_size']
filter_pad = conv_param['pad']
filter_stride = conv_param['stride']
input_size = input_dim[1]
conv_output_size = (input_size - filter_size + 2*filter_pad) / filter_stride + 1
pool_output_size = int(filter_num * (conv_output_size/2) * (conv_output_size/2))
# ��ʼ��Ȩ��
self.params = {}
self.params['W1'] = weight_init_std * \
np.random.randn(filter_num, input_dim[0], filter_size, filter_size)
self.params['b1'] = np.zeros(filter_num)
self.params['W2'] = weight_init_std * \
np.random.randn(pool_output_size, hidden_size)
self.params['b2'] = np.zeros(hidden_size)
self.params['W3'] = weight_init_std * \
np.random.randn(hidden_size, output_size)
self.params['b3'] = np.zeros(output_size)
# ���ɲ�
self.layers = OrderedDict()
self.layers['Conv1'] = Convolution(self.params['W1'], self.params['b1'],
conv_param['stride'], conv_param['pad'])
self.layers['Relu1'] = Relu()
self.layers['Pool1'] = Pooling(pool_h=2, pool_w=2, stride=2)
self.layers['Affine1'] = Affine(self.params['W2'], self.params['b2'])
self.layers['Relu2'] = Relu()
self.layers['Affine2'] = Affine(self.params['W3'], self.params['b3'])
self.last_layer = SoftmaxWithLoss()
def predict(self, x):
for layer in self.layers.values():
x = layer.forward(x)
return x
def loss(self, x, t):
"""����ʧ����
����x���������ݡ�t�ǽ�ʦ��ǩ
"""
y = self.predict(x)
return self.last_layer.forward(y, t)
def accuracy(self, x, t, batch_size=100):
if t.ndim != 1 : t = np.argmax(t, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
tt = t[i*batch_size:(i+1)*batch_size]
y = self.predict(tx)
y = np.argmax(y, axis=1)
acc += np.sum(y == tt)
return acc / x.shape[0]
def numerical_gradient(self, x, t):
"""���ݶ�(��ֵ��)
Parameters
----------
x : ��������
t : ��ʦ��ǩ
Returns
-------
���и�����ݶȵ��ֵ����
grads['W1']��grads['W2']��...�Ǹ����Ȩ��
grads['b1']��grads['b2']��...�Ǹ����ƫ��
"""
loss_w = lambda w: self.loss(x, t)
grads = {}
for idx in (1, 2, 3):
grads['W' + str(idx)] = numerical_gradient(loss_w, self.params['W' + str(idx)])
grads['b' + str(idx)] = numerical_gradient(loss_w, self.params['b' + str(idx)])
return grads
def gradient(self, x, t):
"""���ݶ�(������)
Parameters
----------
x : ��������
t : ��ʦ��ǩ
Returns
-------
���и�����ݶȵ��ֵ����
grads['W1']��grads['W2']��...�Ǹ����Ȩ��
grads['b1']��grads['b2']��...�Ǹ����ƫ��
"""
# forward
self.loss(x, t)
# backward
dout = 1
dout = self.last_layer.backward(dout)
layers = list(self.layers.values())
layers.reverse()
for layer in layers:
dout = layer.backward(dout)
# �趨
grads = {}
grads['W1'], grads['b1'] = self.layers['Conv1'].dW, self.layers['Conv1'].db
grads['W2'], grads['b2'] = self.layers['Affine1'].dW, self.layers['Affine1'].db
grads['W3'], grads['b3'] = self.layers['Affine2'].dW, self.layers['Affine2'].db
return grads
def save_params(self, file_name="params.pkl"):
params = {}
for key, val in self.params.items():
params[key] = val
with open(file_name, 'wb') as f:
pickle.dump(params, f)
def load_params(self, file_name="params.pkl"):
with open(file_name, 'rb') as f:
params = pickle.load(f)
for key, val in params.items():
self.params[key] = val
for i, key in enumerate(['Conv1', 'Affine1', 'Affine2']):
self.layers[key].W = self.params['W' + str(i+1)]
self.layers[key].b = self.params['b' + str(i+1)]
�ο�
�����ѧϰ����:����Python��������ʵ�� ��ի�ٿ���