ǰ��
Ϊ���˽�ģ�͵ķ�������,���ж�ģ�͵ĺû�,������Ҫ��ij��ָ��������,��������ָ��,�Ϳ��ԶԱȲ�ͬģ�͵�����,��ͨ�����ָ������һ�������Ż�ģ�͡����ڷ���ͻع�����ලģ��,�ֱ��и��Ե����б���
��ͬ������Ͳ�ͬ�����ݼ������в�ͬ��ģ������ָ��,�����������,���ݼ����ƽ�������¿���ʹ��ȷ����Ϊ����ָ��,������ʵ�е����ݼ������������ƽ���,����һ�㶼�Dz��� AP ��Ϊ���������ָ��,�ֱ����ÿ������ AP,�ټ���mAP��
һ,��ȷ�ʡ��ٻ�����F1
1.1,ȷ��
ȷ��(����) �C Accuracy,Ԥ����ȷ�Ľ��ռ�������İٷֱ�,��������:
ȷ�� = ( T P + T N ) / ( T P + T N + F P + F N ) ȷ�� = (TP+TN)/(TP+TN+FP+FN) ȷ��=(TP+TN)/(TP+TN+FP+FN)
�����ʺ;�����Ȼ����,���Dz�������������������������������Ϊ��,�����ũ����һ������,������ѵ���õ�ģ�Ͷ����Ͻ����б�,���羫��ֻ�ܺ����ж��ٱ��������ϱ������ж������ȷ(����:�ùϡ�����)�����������Ǹ��ӹ��ĵ��ǡ��������������ж��ٱ����Ǻùϡ�,���ߡ����кù����ж��ٱ�������������,��ô���Ⱥʹ��������ָ����Ȼ�Dz����õġ�
��Ȼȷ�ʿ����ж��ܵ���ȷ��,������������ƽ��������,��������Ϊ�ܺõ�ָ��������������ٸ�������,������һ����������,������ռ 90%,������ռ 10%,���������ز�ƽ��ġ������������,����ֻ��Ҫ��ȫ������Ԥ��Ϊ���������ɵõ� 90% �ĸ�ȷ��,��ʵ�������Dz�û�к����ĵķ���,ֻ���������һ�ֶ��ѡ����˵����:����������ƽ�������,�����˵õ��ĸ�ȷ�ʽ�����кܴ��ˮ�֡������������ƽ��,ȷ�ʾͻ�ʧЧ��
1.2,��ȷ�ʡ��ٻ���
��ȷ��(����)P���ٻ���(��ȫ��)R �ļ����漰����������Ķ���,���������������:
| ���� | ���� |
|---|---|
True Positive(������, TP) | ������Ԥ��Ϊ������ |
True Negative(�渺��, TN) | ������Ԥ��Ϊ������ |
False Positive(������, FP) | ������Ԥ��Ϊ������ �� �� (Type I error) |
False Negative(�ٸ�����, FN) | ������Ԥ��Ϊ������ �� ©�� (Type II error) |
�������ȫ�ʼ��㹫ʽ:
- ����(��ȷ��) P = T P / ( T P + F P ) P = TP/(TP+FP) P=TP/(TP+FP)
- ��ȫ��(�ٻ���) R = T P / ( T P + F N ) R = TP/(TP+FN) R=TP/(TP+FN)
���ʺ�ȷ�ʿ���ȥ��Щ����,������ȫ��ͬ������������ʴ���������������е�Ԥ��ȷ�̶�,��ȷ������������Ԥ��ȷ�̶�,�Ȱ���������,Ҳ������������
��ȷ��������ģ���ж�,����Ԥ��Ϊ�����Ľ����,�ж�����������;�ٻ�����������ģ���ж�ȫ,����Ϊ���������,�ж��ٱ����ǵ�ģ��Ԥ��Ϊ��������ȷ�ʺ��ٻ��ʵ�����������ĸ��ͬ,һ����ĸ��Ԥ��Ϊ����������,��һ����ԭ�����������е�����������
1.3,F1 ����
�����Ҫ�ҵ� P P P �� R R R ����֮���һ��ƽ���,���Ǿ���Ҫһ���µ�ָ��: F 1 F1 F1 ������ F 1 F1 F1 ����ͬʱ�����˲��ʺͲ�ȫ��,�ö���ͬʱ�ﵽ���,ȡһ��ƽ�⡣ F 1 F1 F1 ���㹫ʽ����:
����� F 1 F1 F1 ��������Զ�����ģ��,���������� F 1 F1 F1 �ļ����뿴���档
F 1 = 2 �� P �� R P + R = 2 �� T P �������� + T P ? T N F1 = \frac{2\times P\times R}{P+R} = \frac{2\times TP}{��������+TP-TN} F1=P+R2��P��R?=��������+TP?TN2��TP?
F 1 F1 F1 ������һ����ʽ: F �� F_{\beta} F��?,�������DZ�����Բ���/��ȫ�ʵ�ƫ��, F �� F_{\beta} F��? ���㹫ʽ����:
F �� = 1 + �� 2 �� P �� R ( �� 2 �� P ) + R F_{\beta} = \frac{1+\beta^{2}\times P\times R}{(\beta^{2}\times P)+R} F��?=(��2��P)+R1+��2��P��R?
���� �� > 1 \beta >1 ��>1 �Բ�ȫ���и���Ӱ��, �� < 1 \beta < 1 ��<1 �Բ����и���Ӱ�졣
��ͬ�ļ�����Ӿ�����,����������в�ͬ��ƫ��,������ijһ�������һ����ֵ�������,Ŭ��������һ�������Ŀ������,mAP(mean Average Precision)��Ϊһ��ͳһ��ָ�꽫�����ִ����˿��ǡ�
�ܶ�ʱ�����ǻ��ж����������,������ж��ѵ��/����,ÿ�ζ��ܵõ�һ����������;�������ڶ�����ݼ��Ͻ���ѵ��/����,ϣ�������㷨�ġ�ȫ�֡�����;�ֻ�����ִ�ж��������,ÿ�����������϶���Ӧһ����������;���ܶ���˵,����ϣ������ n n n ������������������ۺϿ��Dz��ʺͲ�ȫ�ʡ�
һ��ֱ�ӵ����������ڸ����������Ϸֱ��������ʺͲ�ȫ��,��Ϊ
(
P
1
,
R
1
)
,
(
P
2
,
R
2
)
,
.
.
.
,
(
P
n
,
R
n
)
(P_1,R_1),(P_2,R_2),...,(P_n,R_n)
(P1?,R1?),(P2?,R2?),...,(Pn?,Rn?) Ȼ��ȡƽ��,�����õ����ǡ������(Macro-P)�����������(Macro-R)������Ӧ�ġ���
F
1
F1
F1(Macro-F1)��:
M
a
c
r
o
?
P
=
1
n
��
i
=
1
n
P
i
Macro\ P = \frac{1}{n}\sum_{i=1}^{n}P_i
Macro?P=n1?i=1��n?Pi?
M
a
c
r
o
?
R
=
1
n
��
i
=
1
n
R
i
Macro\ R = \frac{1}{n}\sum_{i=1}^{n}R_i
Macro?R=n1?i=1��n?Ri?
M
a
c
r
o
?
F
1
=
2
��
M
a
c
r
o
?
P
��
M
a
c
r
o
?
R
M
a
c
r
o
?
P
+
M
a
c
r
o
?
R
Macro\ F1 = \frac{2 \times Macro\ P\times Macro\ R}{Macro\ P + Macro\ R}
Macro?F1=Macro?P+Macro?R2��Macro?P��Macro?R?
��һ�������ǽ������������ӦԪ�ؽ���ƽ��,�õ�
T
P
��
F
P
��
T
N
��
F
N
TP��FP��TN��FN
TP��FP��TN��FN ��ƽ��ֵ,�ٻ�����Щƽ��ֵ����������ʡ�(Micro-P)������ȫ�ʡ�(Micro-R)�͡�
F
1
F1
F1��(Mairo-F1)
M
i
c
r
o
?
P
=
T
P
��
T
P
��
+
F
P
��
Micro\ P = \frac{\overline{TP}}{\overline{TP}+\overline{FP}}
Micro?P=TP+FPTP?
M
i
c
r
o
?
R
=
T
P
��
T
P
��
+
F
N
��
Micro\ R = \frac{\overline{TP}}{\overline{TP}+\overline{FN}}
Micro?R=TP+FNTP?
M
i
c
r
o
?
F
1
=
2
��
M
i
c
r
o
?
P
��
M
i
c
r
o
?
R
M
a
c
r
o
P
+
M
i
c
r
o
?
R
Micro\ F1 = \frac{2 \times Micro\ P\times Micro\ R}{MacroP+Micro\ R}
Micro?F1=MacroP+Micro?R2��Micro?P��Micro?R?
1.4,PR ����
���ʺ��ٻ��ʵĹ�ϵ������һ�� P-R ͼ��չʾ,�Բ��� P Ϊ���ᡢ��ȫ�� R Ϊ������ͼ,�͵õ��˲���-��ȫ������,��� P-R ����,PR �����µ��������Ϊ AP:
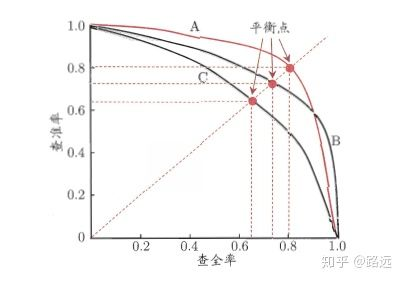
1.4.1,������� P-R ����
���Դ�������ģ�ͻ��߷���ģ�����⡣�����ع����,���ع�������һ�� 0 �� 1 ֮��ĸ�������,���,���������Ҫ������������ж��û��û��Ļ�,���Ǿͱ��붨��һ����ֵ ��ͨ������,���ع�ĸ���Խ��˵��Խ�ӽ� 1,Ҳ�Ϳ���˵���ǻ��û��Ŀ����Ը�����,���Ƕ�������ֵΪ 0.5,������С�� 0.5 �����Ƕ���Ϊ�Ǻ��û�,������ 0.5 ����Ϊ�ǻ��û������,������ֵΪ 0.5 �������,���ǿ��Եõ���Ӧ��һ�����ʺͲ�ȫ�ʡ�
��������:�����ֵ��������㶨���,���Dz���֪�������ֵ�Ƿ�������ǵ�Ҫ�� ���,Ϊ���ҵ�һ������ʵ���ֵ�������ǵ�Ҫ��,���Ǿͱ������ 0 �� 1 ֮�����е���ֵ,��ÿ����ֵ�¶���Ӧ��һ�Բ��ʺͲ�ȫ��,�Ӷ����Ǿ͵õ��� PR ���ߡ�
�������ҵ���õ���ֵ����? ����,��Ҫ˵���������Ƕ���������ָ���Ҫ��:����ϣ�����ʺͲ�ȫ��ͬʱ���dz��ߡ� ��ʵ����������ָ����һ��ì����,������˫�ߡ�ͼ�����Կ���,�������һ���dz���,��һ���϶���dz��͡�ѡȡ���ʵ���ֵ��Ҫ����ʵ������,����������Ҫ�ߵIJ�ȫ��,��ô���Ǿͻ�����һЩ����,�ڱ�֤��ȫ����ߵ������,����Ҳ����ô�͡���
1.5,ROC ������ AUC ���
PR��������RecallΪ����,PrecisionΪ����;��ROC����������FPRΪ����,TPRΪ����**��P-R ����Խ�������Ͻ�����Խ����PR���ߵ�����ָ�궼�۽�������PR����չʾ����Precision vs Recall������,ROC����չʾ����FPR(x ��:False positive rate) vsTPR(True positive rate, TPR)���ߡ�
- ROC ����
- AUC ���
��,AP �� mAP
2.1,AP �� mAP ָ������
AP ��������ѵ���õ�ģ����ÿ������ϵĺû�,mAP ��������ģ������������ϵĺû�,�õ� AP �� mAP �ļ���ͱ�úܼ���,����ȡ���� AP ��ƽ��ֵ��AP �ļ��㹫ʽ�Ƚϸ���(���Ե�����һ�½�����),��ϸ���ݲο����ġ�
mAP ��������в�ͬ�Ķ��塣�˶���ָ��ͨ��������Ϣ������ͼ������Ŀ��������Ȼ��������������� mAP �ķ�ʽȴ����ͬ����������̸ֻ��Ŀ�����е� mAP ���㷽����
mAP ����ΪĿ�����㷨������ָ��,������˵����,����ÿ��ͼƬ���ģ�ͻ�������Ԥ���(Զ����ʵ��ĸ���),����ʹ�� IoU (Intersection Over Union,������)�����Ԥ����Ƿ�Ԥ��ȷ�������ɺ�,����Ԥ��������,��ȫ�� R �ܻ�����,�ڲ�ͬ��ȫ�� R ˮƽ�¶�ȷ�� P ��ƽ��,���õ� AP,����ٶ������������ռ������ƽ��,���õ� mAP ָ�ꡣ
2.2,���Ƽ���AP
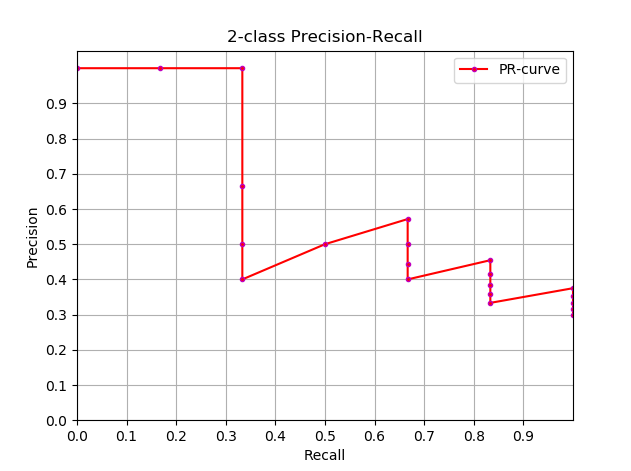
֪����AP �Ķ���,��һ����������AP�����ʵ��,�����Ͽ���ͨ������������AP,��ʽ����:
A
P
=
��
0
1
P
(
r
)
d
r
AP=\int_0^1 P(r) dr
AP=��01?P(r)dr
��ͨ������¶���ʹ�ý��ƻ��߲�ֵ�ķ���������
A
P
AP
AP��
A P = �� k = 1 N P ( k ) �� r ( k ) AP = \sum_{k=1}^{N}P(k)\Delta r(k) AP=k=1��N?P(k)��r(k)
- ���Ƽ���
A
P
AP
AP (
approximated average precision),���ּ��㷽ʽ��approximated��ʽ��; - ����Ȼλ��һ����ֱ���ϵĵ�Լ��� A P AP AP û�й���;
- ���� N N N Ϊ��������, k k k Ϊÿ�������������, �� r ( k ) = r ( k ) ? r ( k ? 1 ) ��r(k)=r(k)?r(k?1) ��r(k)=r(k)?r(k?1)��
���Ƽ��� AP �ͻ��� PR ���ߴ�������:
import numpy as np
import matplotlib.pyplot as plt
class_names = ["car", "pedestrians", "bicycle"]
def draw_PR_curve(predict_scores, eval_labels, name, cls_idx=1):
"""calculate AP and draw PR curve, there are 3 types
Parameters:
@all_scores: single test dataset predict scores array, (-1, 3)
@all_labels: single test dataset predict label array, (-1, 3)
@cls_idx: the serial number of the AP to be calculated, example: 0,1,2,3...
"""
# print('sklearn Macro-F1-Score:', f1_score(predict_scores, eval_labels, average='macro'))
global class_names
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(15, 10))
# Rank the predicted scores from large to small, extract their corresponding index(index number), and generate an array
idx = predict_scores[:, cls_idx].argsort()[::-1]
eval_labels_descend = eval_labels[idx]
pos_gt_num = np.sum(eval_labels == cls_idx) # number of all gt
predict_results = np.ones_like(eval_labels)
tp_arr = np.logical_and(predict_results == cls_idx, eval_labels_descend == cls_idx) # ndarray
fp_arr = np.logical_and(predict_results == cls_idx, eval_labels_descend != cls_idx)
tp_cum = np.cumsum(tp_arr).astype(float) # ndarray, Cumulative sum of array elements.
fp_cum = np.cumsum(fp_arr).astype(float)
precision_arr = tp_cum / (tp_cum + fp_cum) # ndarray
recall_arr = tp_cum / pos_gt_num
ap = 0.0
prev_recall = 0
for p, r in zip(precision_arr, recall_arr):
ap += p * (r - prev_recall)
# pdb.set_trace()
prev_recall = r
print("------%s, ap: %f-----" % (name, ap))
fig_label = '[%s, %s] ap=%f' % (name, class_names[cls_idx], ap)
ax.plot(recall_arr, precision_arr, label=fig_label)
ax.legend(loc="lower left")
ax.set_title("PR curve about class: %s" % (class_names[cls_idx]))
ax.set(xticks=np.arange(0., 1, 0.05), yticks=np.arange(0., 1, 0.05))
ax.set(xlabel="recall", ylabel="precision", xlim=[0, 1], ylim=[0, 1])
fig.savefig("./pr-curve-%s.png" % class_names[cls_idx])
plt.close(fig)
2.3,��ֵ���� AP
��ֵ����(Interpolated average precision)
A
P
AP
AP �Ĺ�ʽ���ݱ�������ﲻ������,������Բο���ƪ����,������Ĺ�ʽ��ͼҲ�Dzο������µġ�11 ���ֵ���㷽ʽ����
A
P
AP
AP ��ʽ����:
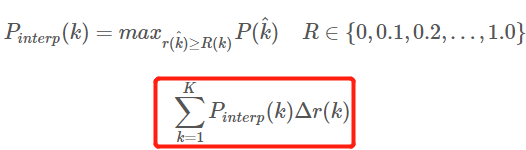
- ����ͨ�������ϵ�
11points_Interpolated��ʽ��AP,ѡȡ�̶��� 0 , 0.1 , 0.2 , �� , 1.0 {0,0.1,0.2,��,1.0} 0,0.1,0.2,��,1.011����ֵ,����� PASCAL2007 ��ʹ�� - ������Ϊ��������ֻ��
11����,���� K = 11 K=11 K=11,��Ϊ 11 points_Interpolated, k k k Ϊ��ֵ���� -
P
i
n
t
e
r
p
(
k
)
P_{interp}(k)
Pinterp?(k) ȡ��
k
k
k ����ֵ����Ӧ��������֮��������е����ֵ,ֻ�����������ֵ��������
0
,
0.1
,
0.2
,
��
,
1.0
{0,0.1,0.2,��,1.0}
0,0.1,0.2,��,1.0 ��Χ�ڡ�
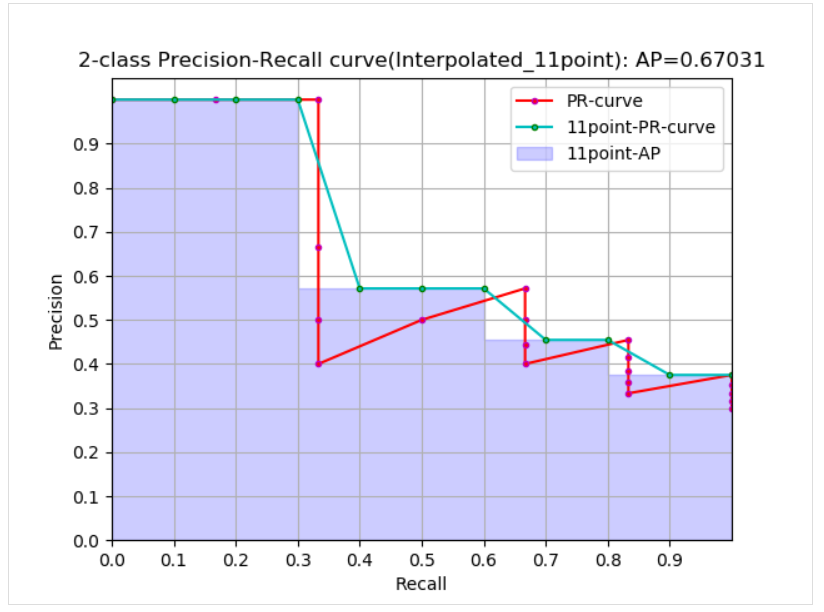
�������Ͽ�,��ʵ AP< approximated AP < Interpolated AP,11-points Interpolated AP ���ܴ�Ҳ����С,���������ܶ��ʱ���ӽ��� Interpolated AP,�� Interpolated AP ��ͬ,ǰ��Ĺ�ʽ�м��� AP ʱ���Ƕ� PR ���ߵ��������,PASCAL ������������Ĺ�ʽ���Ӽֱ���,ֱ�Ӽ���11 ����ֵ���� precision ��ƽ��ֵ��PASCAL ���ĸ����� 11 ����� AP �Ĺ�ʽ���¡�
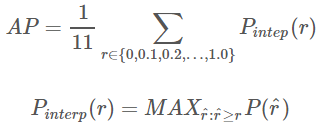
1, �ڸ��� recal �� precision �������¼��� AP:
def voc_ap(rec, prec, use_07_metric=False):
"""
ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap
2,����Ŀ�������ļ��Ͳ��Լ���ǩ�ļ� xml �ȼ��� AP:
def parse_rec(filename):
""" Parse a PASCAL VOC xml file
Return : list, element is dict.
"""
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections result file
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations file
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile)
# read list of images
with open(imagesetfile, 'r') as f:
lines = f.readlines()
imagenames = [x.strip() for x in lines]
if not os.path.isfile(cachefile):
# load annotations
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print('Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# save
print('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f:
pickle.dump(recs, f)
else:
# load
with open(cachefile, 'rb') as f:
try:
recs = pickle.load(f)
except:
recs = pickle.load(f, encoding='bytes')
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
if BB.shape[0] > 0:
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap
2.4,mAP ���㷽��
��Ϊ m A P mAP mAP ֵ�ļ����Ƕ����ݼ����������� A P AP AP ֵ��ƽ��,��������Ҫ���� m A P mAP mAP,���ȵ�֪��ijһ���� A P AP AP ֵ��ô��ͬ���ݼ���ij���� A P AP AP ���㷽����ͬС��,��Ҫ��Ϊ����:
(1)�� VOC2007,ֻ��Ҫѡȡ��
R
e
c
a
l
l
>
=
0
,
0.1
,
0.2
,
.
.
.
,
1
Recall >= 0, 0.1, 0.2, ..., 1
Recall>=0,0.1,0.2,...,1 �� 11 ����ʱ�� Precision ���ֵ,Ȼ��
A
P
AP
AP ������ 11 �� Precision ��ƽ��ֵ,
m
A
P
mAP
mAP �����������
A
P
AP
AP ֵ��ƽ����VOC ���ݼ��м���
A
P
AP
AP �Ĵ���(�õ��Dz�ֵ���㷽��,�������py-faster-rcnn�ֿ�)
(2)�� VOC2010 ���Ժ�,��Ҫ���ÿһ����ͬ�� Recall ֵ(���� 0 �� 1),ѡȡ����ڵ�����Щ Recall ֵʱ�� Precision ���ֵ,Ȼ����� PR �����������Ϊ
A
P
AP
AP ֵ,
m
A
P
mAP
mAP �����������
A
P
AP
AP ֵ��ƽ����
(3)COCO ���ݼ�,�趨��� IOU ��ֵ(0.5-0.95, 0.05 Ϊ����),��ÿһ�� IOU ��ֵ�¶���ijһ���� AP ֵ,Ȼ����ͬ IOU ��ֵ�µ� AP ƽ��,������������յ�ij���� AP ֵ��
��,Ŀ�������������
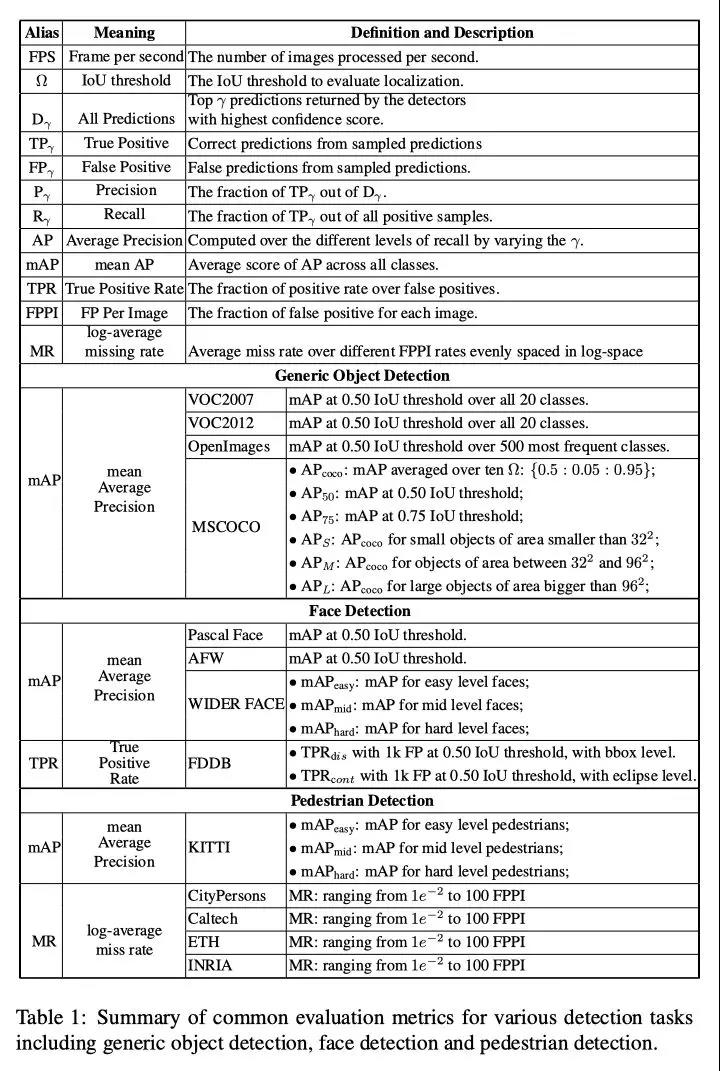
| ����ָ�� | ���弰���� |
|---|---|
mAP | mean Average Precision, ������� AP ��ƽ��ֵ |
AP | PR ���������,���Ļ���ϸ���� |
PR ���� | Precision-Recall ���� |
Precision | T P / ( T P + F P ) TP / (TP + FP) TP/(TP+FP) |
Recall | T P / ( T P + F N ) TP / (TP + FN) TP/(TP+FN) |
TP | IoU>0.5 �ļ�������(ͬһ Ground Truth ֻ����һ��,��ֵȡ 0.5) |
FP | IoU<=0.5 �ļ���,�����Ǽ�ͬһ�� GT �Ķ����������� |
FN | û�м��� GT ������ |