论文:Improving Passage Retrieval with Zero-Shot Question Generation
作者:Devendra Singh Sachan1,2?, Mike Lewis3, Mandar Joshi4, Armen Aghajanyan3, Wen-tau Yih3, Joelle Pineau1,2,3, Luke Zettlemoyer3,4 1McGill University; 2Mila - Quebec AI Institute 3Meta AI; 4University of Washington
任务:re-ranking模型,改善open QA中的passage retrieval阶段
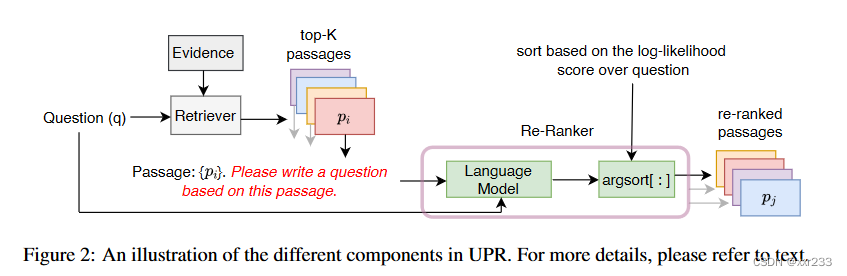
方法:使用预训练模型GPT,T5使用zero-shot手段,在候选段落后添加prompt: “Passage: { pi }.?Please write a question based on this passage”,从而基于段落生成问题,并以真正的问题作为模型输入,计算基于段落生成问题token的平均概率。以此概率作为该段落的排序位置。如图所示
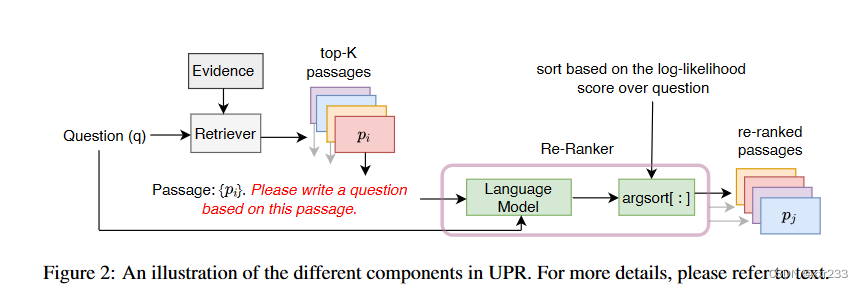
优势:该方法可以在任何检索方法(例如基于神经网络或基于关键字)的基础上应用,不需要任何特定于域任务的训练(因此,预计将更好地推广到不同数据中),并在query和passage之间提供丰富的cross-attention(它必须解释问题中的每个令牌)
评估效果:在无监督检索模型方面提高了6%-18%,在强有力的监督模型上就TOP-20通道检索准确性而言最多可提高12%。我们将我们的re-ranker模型简单的加在以往的模型上在full open domain QA上获得了SOTA
以下是原文
1 introduction
模型思路:“introduce a re-ranker based on zero-shot question generation with a pre-trained language model. Our re-ranker, which we call Unsupervised Passage Re-ranker (UPR), re-scores the retrieved passages by computing the likelihood of the input question conditioned on a retrieved passage”
这一部分都在夸这个模型与其他模型相比多么多么好!
在某种程度上,UPR模型受到传统查询评分模型-基于计数语言模型的启发。但我们将语言模型替换为预训练语言模型。现有的很多关于re-ranker工作都在question-passage对上微调预训练模型以获得更好的相关标签,有时也会联合生成问题任务和生成标签任务。我们的模型UPR使用现成的预训练模型而不需要任何训练数据或者微调,但是仍然获得了不错的效果,可以跨数据集、跨预训练模型、跨检索器。
据我们所知,这是第一项表明完全无监督的pippline(由retriever和re-ranker组成)可以极大地超过诸如DPR之类的密集检索模型。随着语言模型继续迅速改善,UPR的性能可能会随着时间的推移而看到相应的增长。 UPR不需要带注释的数据,并且仅使用通用的预训练模型,这意味着很容易应用于广泛的检索问题。听起来好牛皮!!
2 methods
我们的新的无监督re-ranker模型可以用于任何retriever之上。
2.1 retriever
第一阶段检索使用BM25或者DPR模型从大量的段落中检索中K个最相关的段落,re-ranker是重新排序他们使得正确答案的排序竟可能高。
2.2 UPR
给定段落文本z,生成问题q的概率,通过贝叶斯条件概率可得
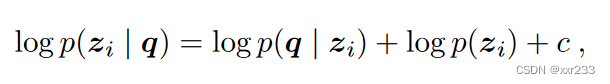
其中p(zi)是段落检索的先验概率,是固定的,所以可以忽略,那么公式简化为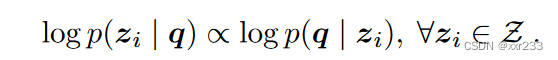
其中log p(q|zi)计算方式为:计算以段落为条件的问题tokens的平均对数似值:|q|代表问题的token数量

我们应用预训练模型的zero-shot方法在passage后添加指令““Please write a question based on this passage””,这里使用生成预训练模型,在已有的段落文本下预测问题token出现的概率。
然后基于logp(q|z)的值为初始段落排序,这让我们使用现成的语言模型re-rank段落而不需任何问题-段落训练对和预训练。
3 实验
3.1 open-domain QA
数据集
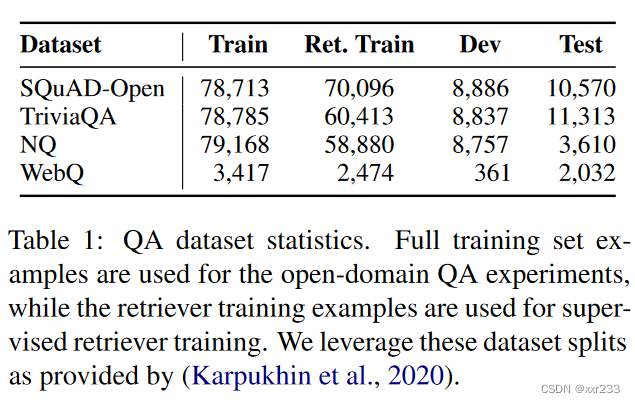
“Evidence Passages D”::我们使用Karpukhin等人发布的从2018年12月开始的预处理英语Wikipedia作为我们的证据段落。每篇Wikipedia文章都分为非重叠的100个单词段落。总g共超过2100万个passages。
3.2 以关键字为中心的数据集
“Entity Questions”::根据Wikipedia的事实,包含有关指定实体的22k简短问题。该数据集上的先前工作表明,dpr难以检索相关段落,而BM25之类的稀疏方法更成功
“BEIR Benchmark”:是检索算法benchmark,由多个数据集组成,每个数据集都由测试集查询,证据文档和相关文件标注组成(Thakur等,2021)。这些数据集包含不同类型的检索任务,例如事实检查,问答等。以及包括新闻,技术和维基百科在内的各种领域,使其成为具有挑战性的基准。
3.3 retrievers
分为有监督有无监督两个部分
-
无监督:
BM25
MSS:是一个稠密检索器通过mask 命名实体的预训练任务得来,被证明可以帮助提高监督检索工作。“(Sachan et al., 2021a).”
Contriever:使用动量对比训练来从文本段落中学习稠密向量的检索器。此类培训已证明可以在许多基准测试中获得强大的零射击检索性能。“(Izacard et al., 2021).”
2. 有监督
DPR
MSS-DPR:先使用MSS任务预训练模型,再在DPR上检索
3.4 预训练模型
T5
GPT
3.5 实现细节
“V10032GB GPUs”
pytorch
BM25:使用pyserini库实现
MSS,DPR:使用(Sachan et al., 2021a).开源库
预训练模型:Huggingface
4 实验:段落检索
因此,在第一阶段,通过检索前1000个段落来获取较大的候选人名单。然后,在第二阶段,除非另有指定,否则将这些段落重新排列(top-{20,100})
“top-K retrieval accuracy”
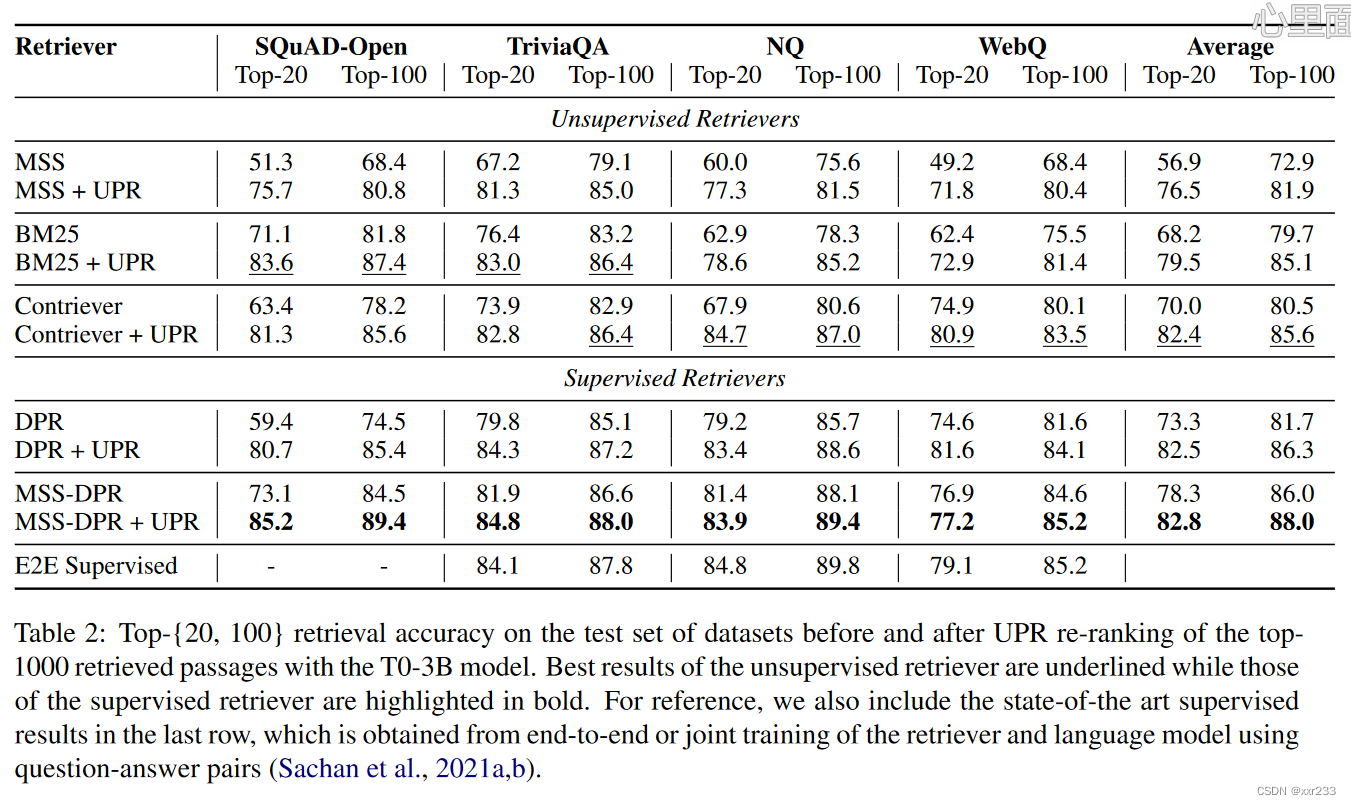
UPR方法在无监督模型上提高了6%-18%,在有监督的top-20上最高提高了12%。
无监督的contriever+UPR方法在所有数据集上有监督的DPR相比,top-20平均提高9%,top-100提高4%。这表明无监督的retriever和re-ranker pipeline优于强壮的监督模型比如DPR
离散向量模型BM25仍然表现出强劲的竞争力,在几个数据集上优于contriever MSS
我们还将 contriever+UPR和MSS-DPR+UPR和目前最先进的模型对比,我们的模型性能更好且不需要花费巨大的训练。
4.2 消融实验
-
问题生成模型的重要性
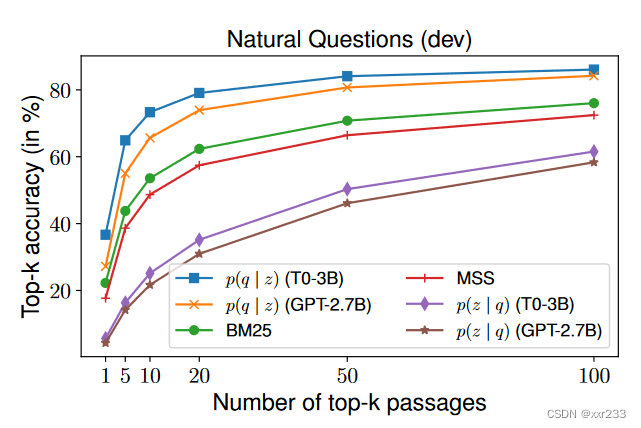
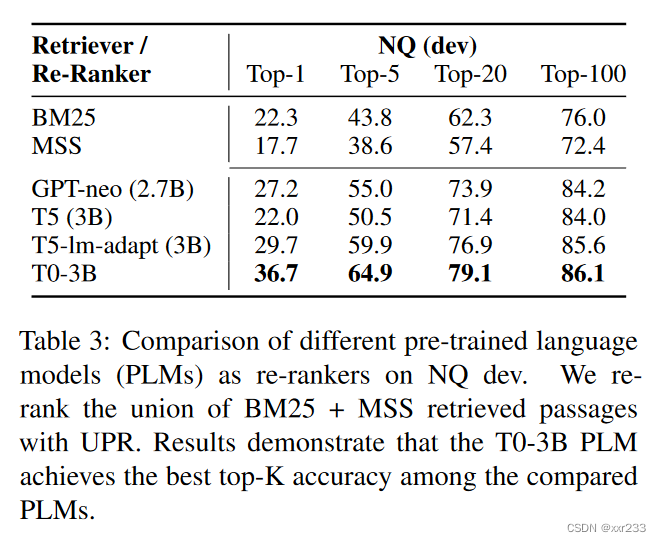
2. 预训练模型的选择
3.段落候选大小与时间的关系
我们研究要re-ranker的候选者数量以及所花费的时间的效果。为此,我们考虑了NQ开发集,将从BM25获得的前1000段重新排列,并使用TOP-20精度作为评估标准。
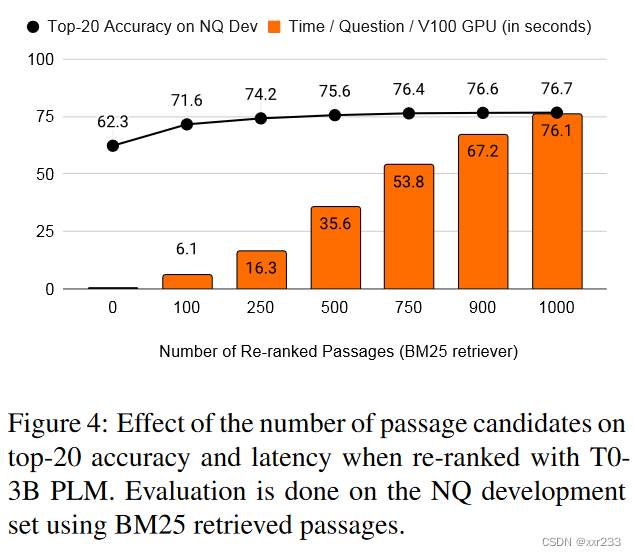
实验证明越多的段落候选数有助于提高准确率。但是,收益往往会随着段落的数量而平稳
4.3 在关键字数据集上评估
更多内容详见原文