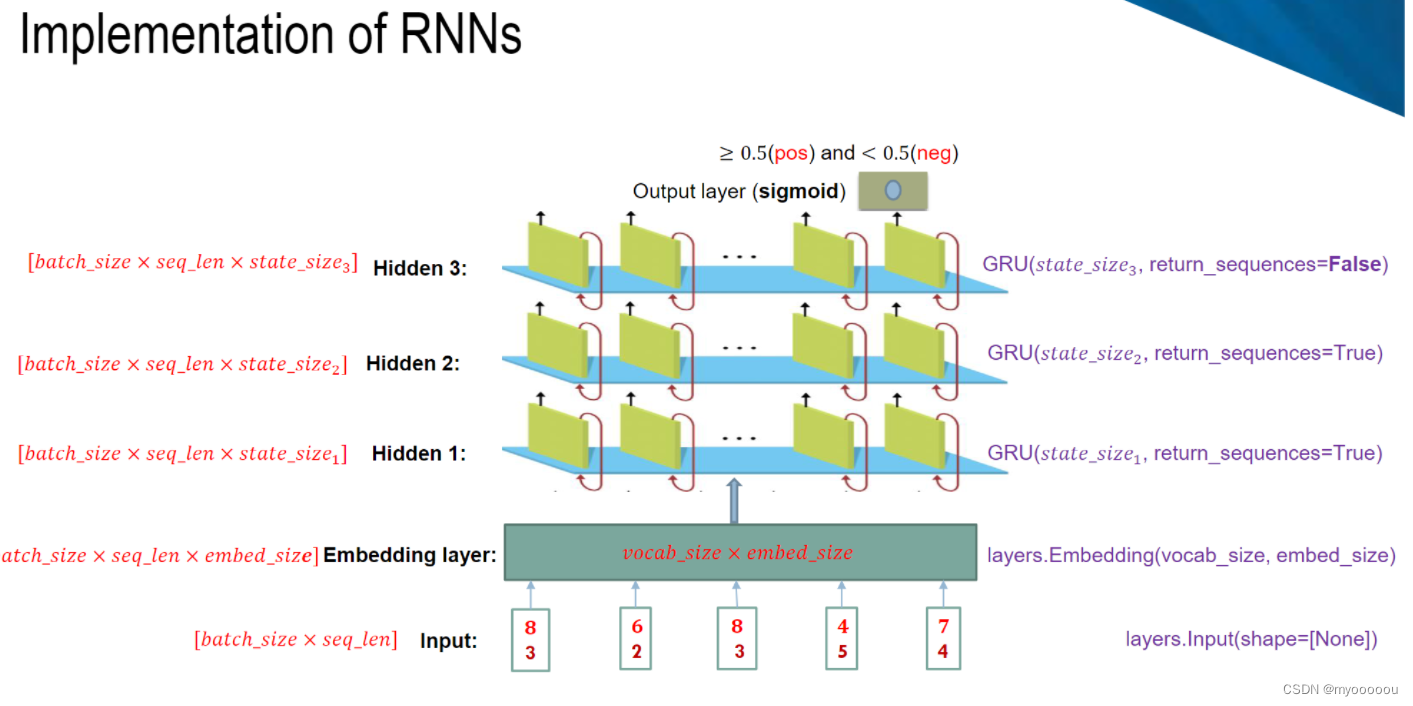
RNN
Introduction of sequential data
-
**Hidden Markov Model(隐马尔可夫模型)**详见NLP课件
-
Autoregressive Model(自回归模型)
RNN
思想:权值共享 haring parameters for each data of the time index
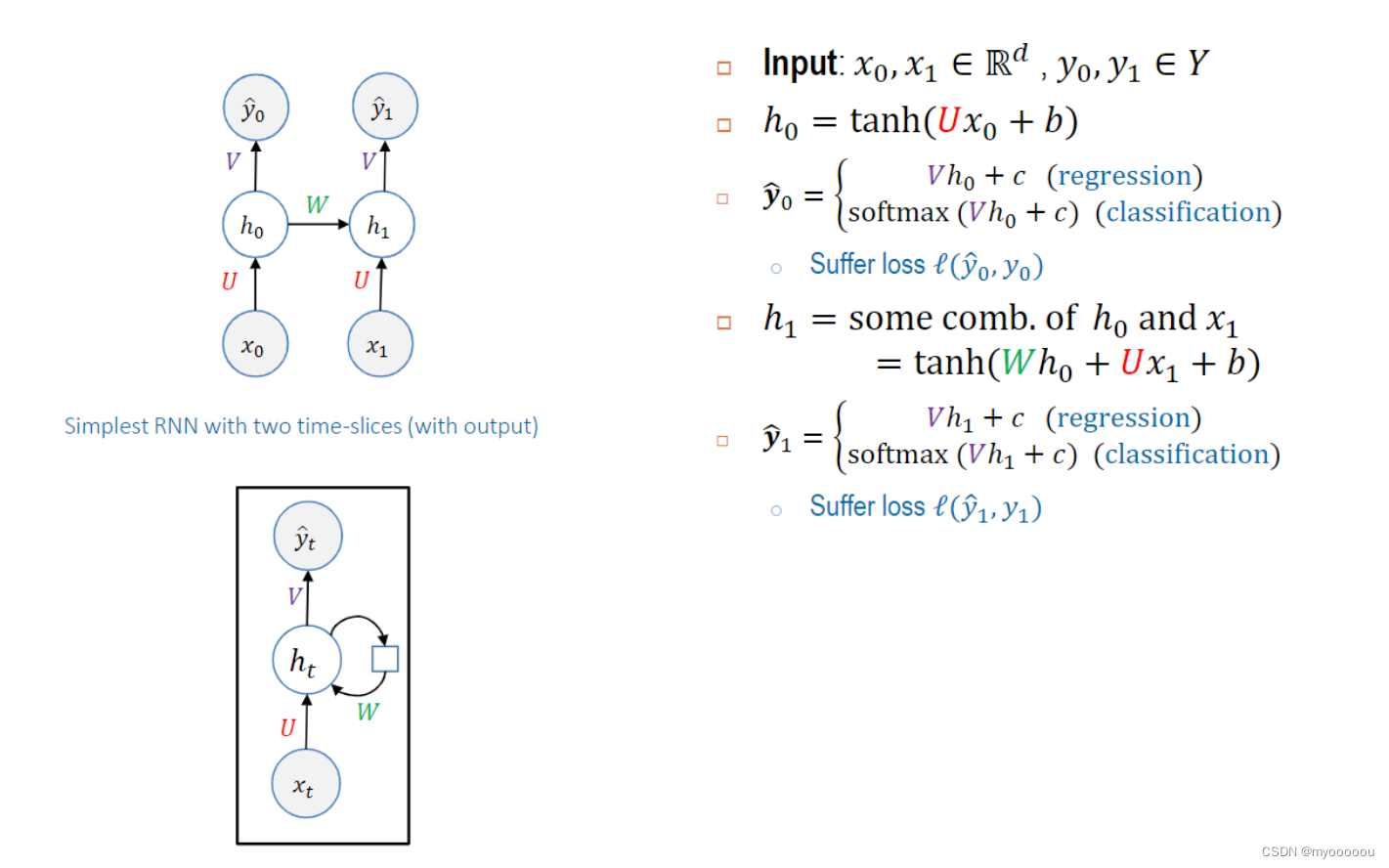
两个输入的RNN模型如下:
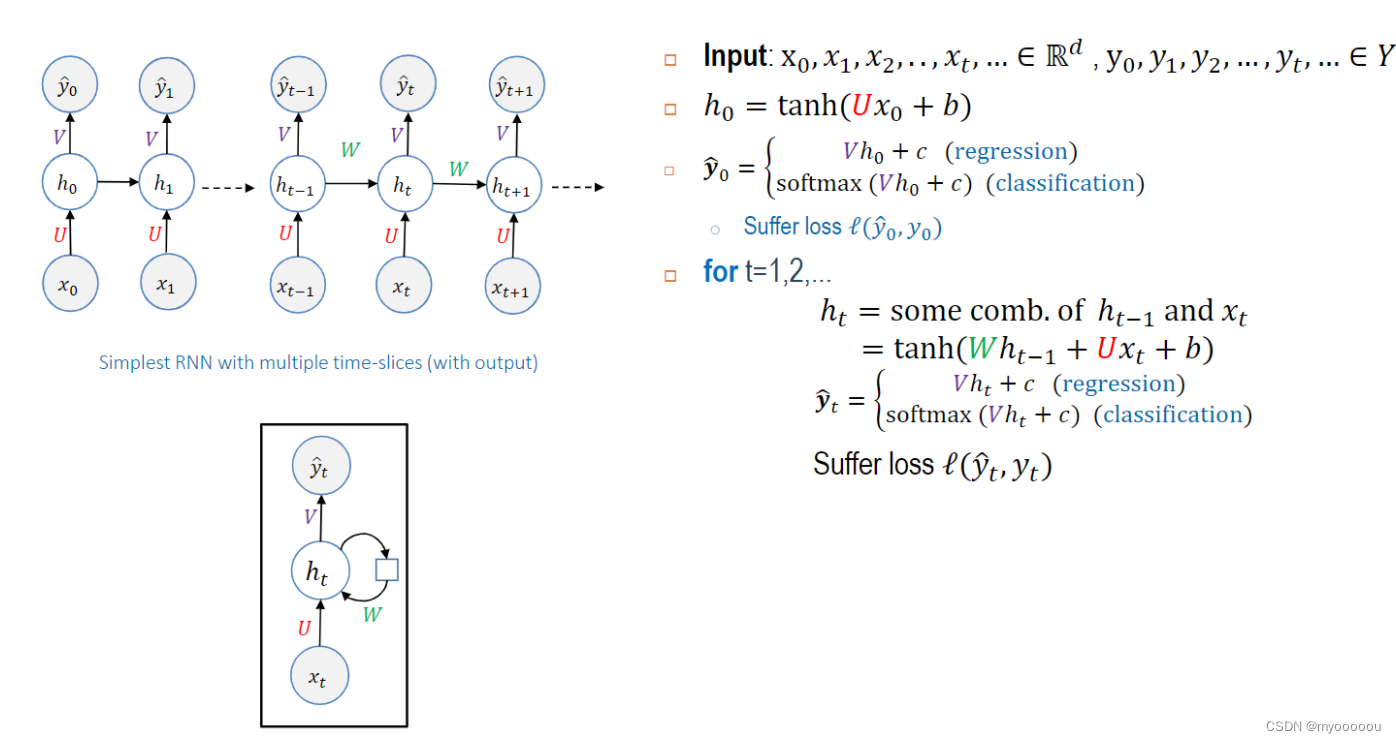
拓展到N个input的RNN模型:
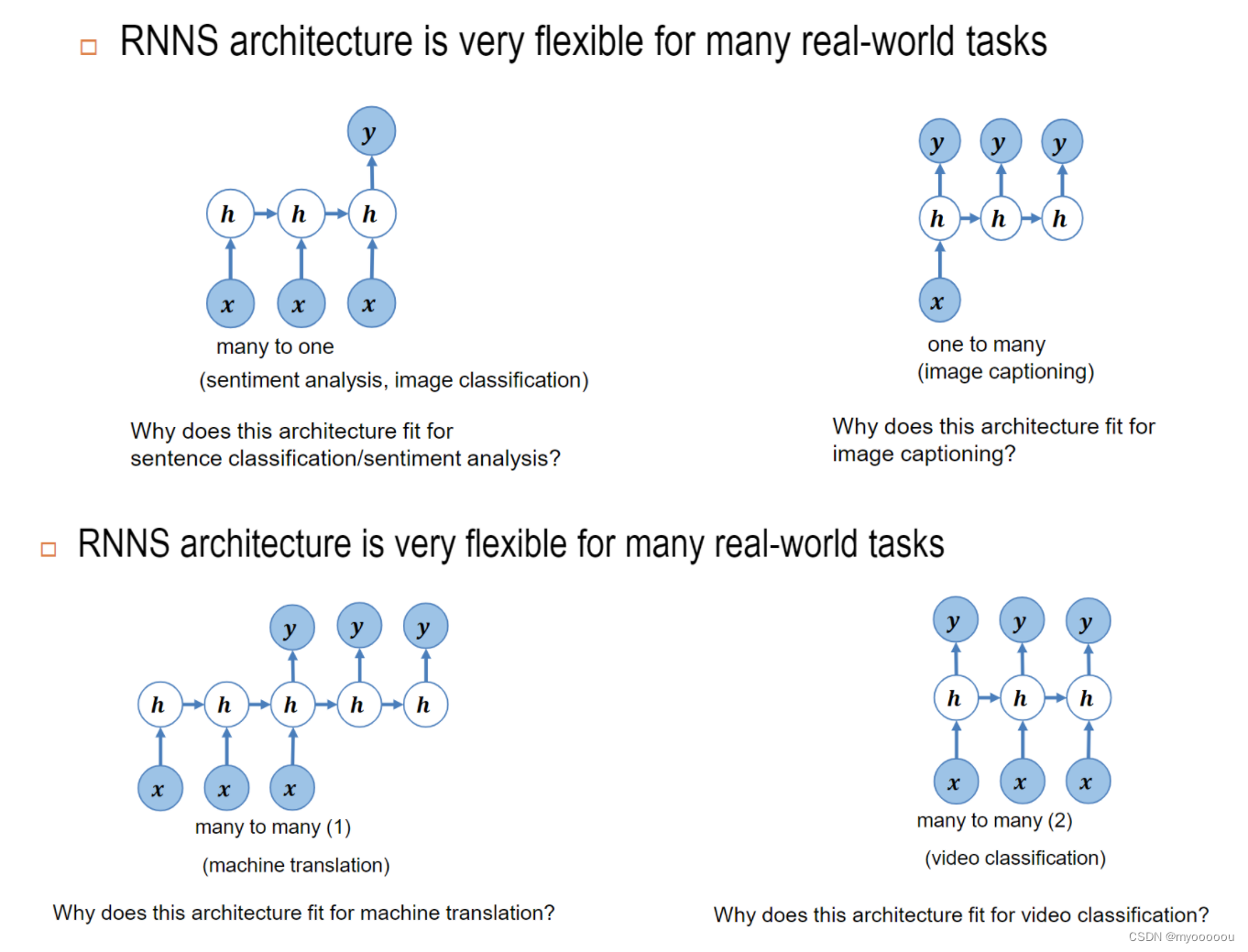
RNN architecture RNN结构
- many to one
- one to many
- many to many(1)
- many to many(2)
循环神经网络――RNN的训练算法:BPTT
BPTT算法是针对循环层的训练算法,它的基本原理和BP算法是一样的,也包含同样的三个步骤:
1.前向计算每个神经元的输出值;
2.反向计算每个神经元的误差项 δ j δ_j δj?值,它是误差函数E对神经元j的加权输入 n e t j net_j netj?的偏导数;
3.计算每个权重的梯度。
前向计算:
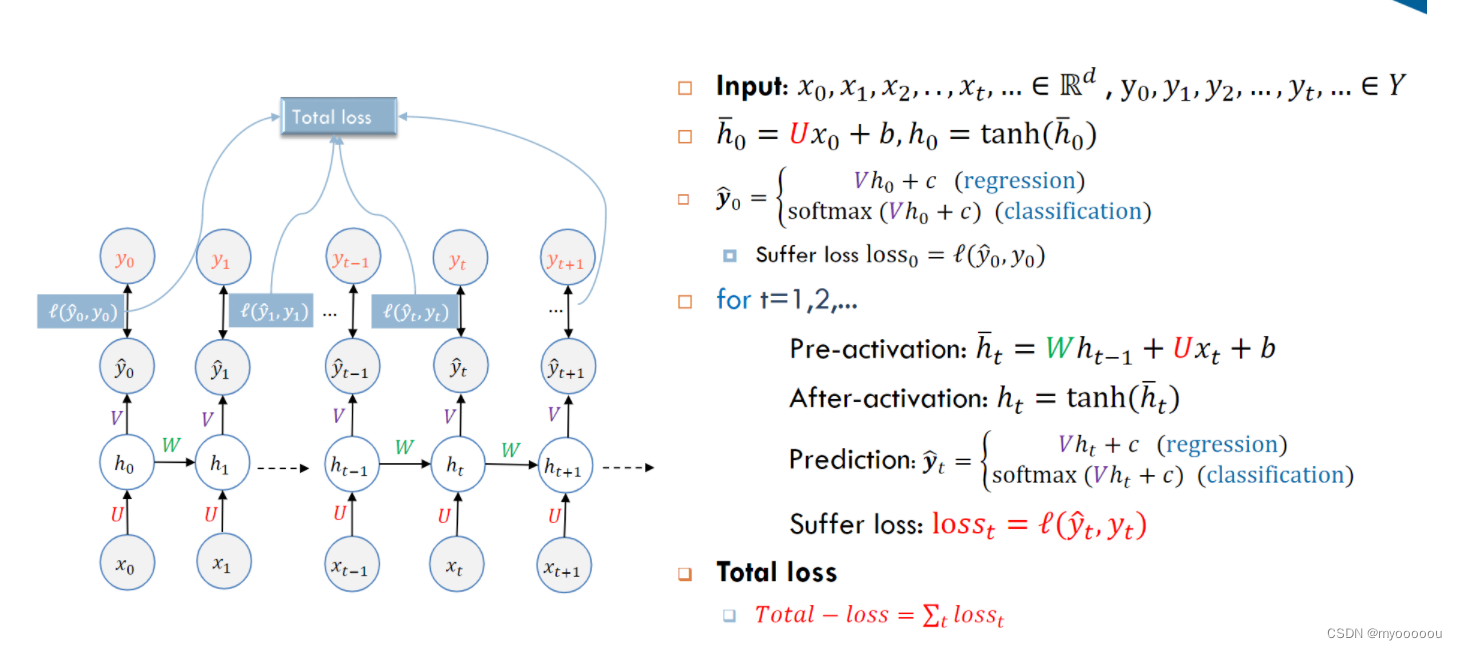
后向计算:
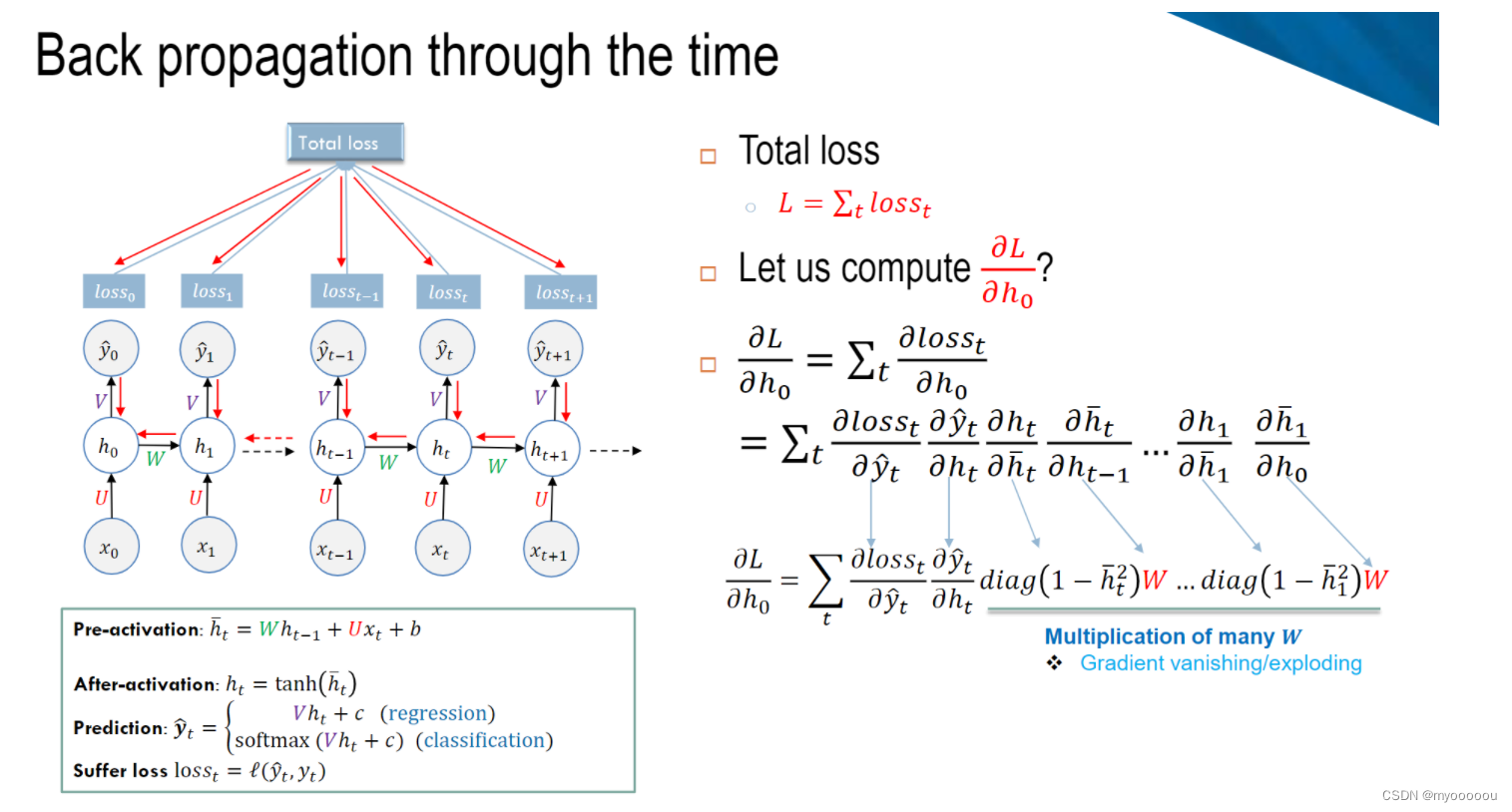
Q:Gradient vanishing/exploding问题如何解决?
A: Use tanh() activation as the squash function to scale the output to (-1, 1) at each time step
梯度消失和梯度爆炸解决方法
-
通常来说,梯度爆炸更容易处理一些。因为梯度爆炸的时候,我们的程序会收到NaN错误。我们也可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。
-
梯度消失更难检测,而且也更难处理一些。总的来说,我们有三种方法应对梯度消失问题:
- 合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。
- 使用relu代替sigmoid和tanh作为激活函数。
- 使用其他结构的RNNs,比如长短时记忆网络(LTSM)和Gated Recurrent Unit(GRU),这是最流行的做法。
RNN算法的缺陷
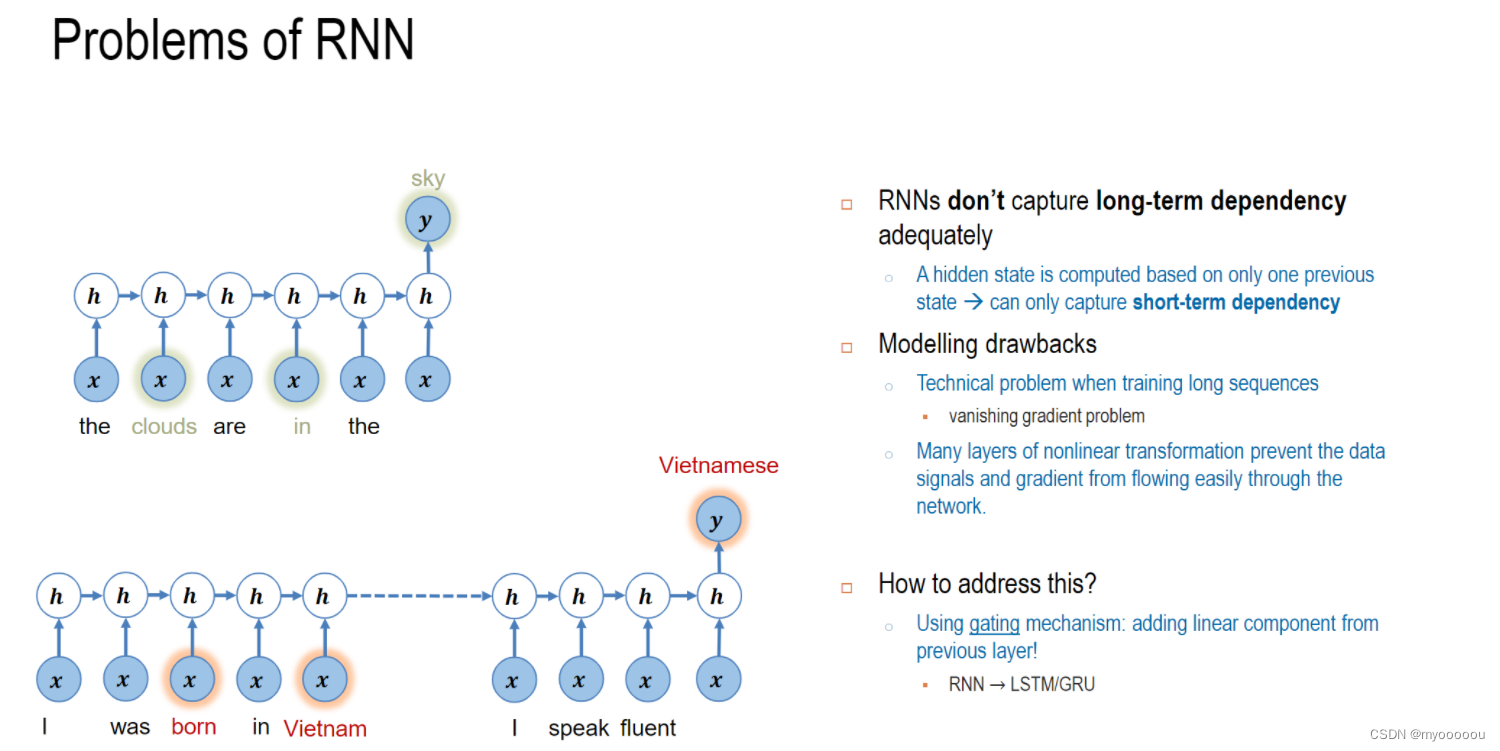
(1)无法支持长时间序列
RNN由于梯度消失,导致RNN网络的时间序列不能太长,因此,RNN网络只能有短期记忆, 无法支持常序列的记忆。这就意味着RNN网络,可能只能处理短句,无法处理又长篇文字组成的长文序列。虽然,RNN网络结构看起来是支持长文的。这就需要一种新的网络结构来支持长时间的序列输入。所谓无法记住“长序列”, 只能记住“短”时上下文,是指“长序列”梯度的消失。
(2)RNN网络不同词对当前输出的影响效果完全取决于“时间”
RNN网络,在时间是是串联关系,离当前时间越远的隐藏层的输出,对当前隐藏层的输出的影响越小。RNN无法根据不同词本身的重要性来对当前的输出产生影响 。
(3)RNN网络对所有序列输入是平等对待
RNN对所有输入具有同等的特征提取的能力,对于一句话中的所有单词,都会提取他们的特征 ,并作为下一特征的输入。也就是说RRN网络,记住了所有的信息,并没有区分哪些是有用信息,有哪些是无用信息,哪些是辅助信息。
Memory cells
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Mkiu3Ti6-1662628327768)(img/image-20220821235236106.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mZkkNEHm-1662628327769)(img/image-20220821235436692.png)]
LSTM


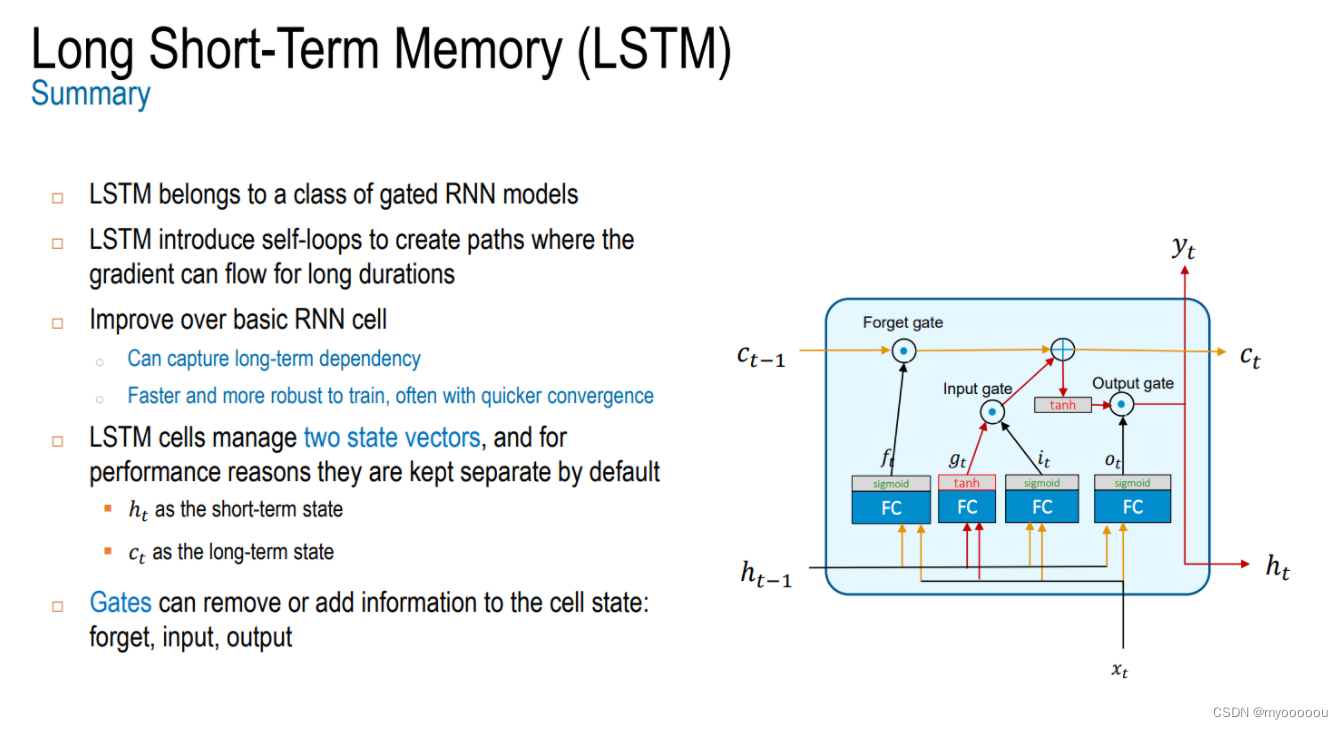
three gate controllers(input output forget)作用:
-
Use sigmoid to ensure outputs’ range between 0 and 1
使用Sigmoid确保输出的范围在0到1之间
-
Forget gate 𝑓𝑡: with element wise multiplication ⊙ control which parts of long-term state 𝑐𝑡?1 should be erased.
𝑓𝑡:使用乘法⊙控制应删除长期状态的哪些部分。
表示我们希望什么样的信息进行保留,什么样的信息可以通过,所以这里的激活函数是sigmoid。
-
Input gate 𝑖𝑡 controls which how much 𝑔𝑡 be remembered
决定什么值我们将要更新,接着用tanh建立一个候选值向量,并将其加入到状态中
-
Output gate 𝑜𝑡 controls how much long-term 𝑐𝑡 should be carried on to the next time slice:
- to contribute to short-term state: ?𝑡
- to contribute to the output: y ^ t \hat{y}_{t} y^?t?
- 决定来了多大程度的输出长期记忆小盒子中的信息。
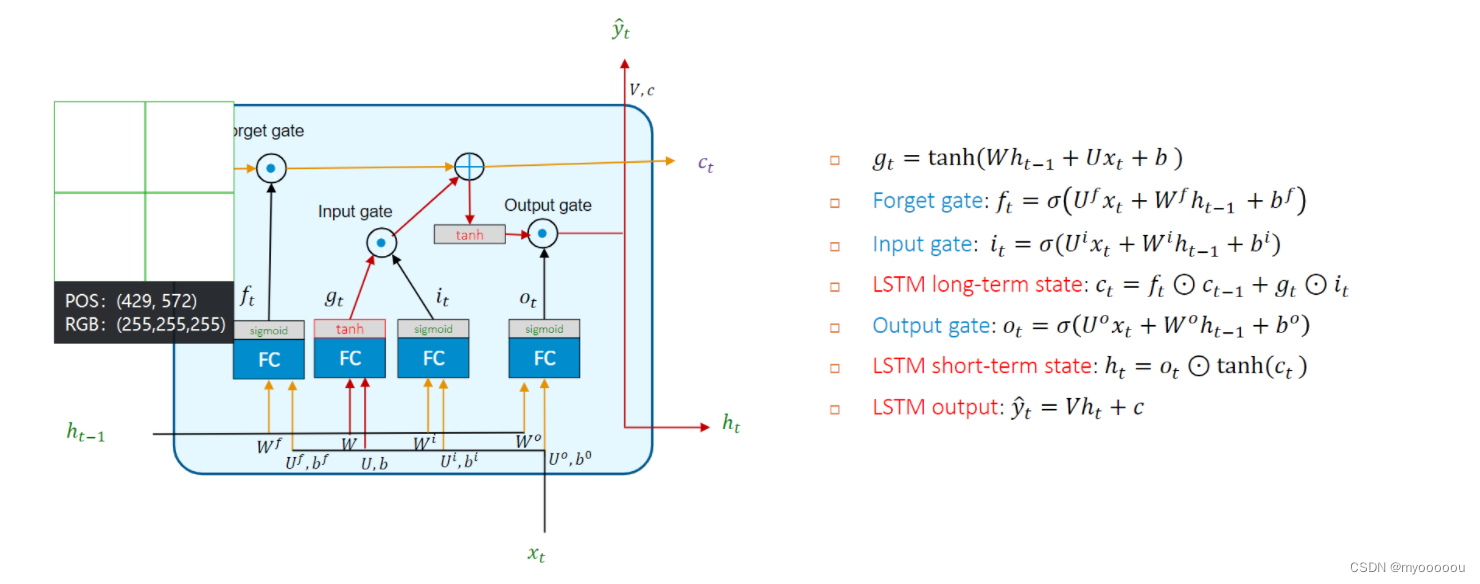
LSTM的两个状态 - 外部接口
- RNN只有一个隐藏状态(记忆信息)在相邻单元之间传递。
- LSTM具备两个状态信息(记忆信息)在两个相邻单元之间传递:一个长时记忆Ct, 一是上一时刻的短时记忆Ht(瞬时记忆)
总结
PPT week5 /43
LSTM 属于门控 RNN 模型的一类,是改进基本的 RNN 单元
LSTM 引入自循环来创建梯度可以长时间流动的路径
LSTM可以捕捉长期依赖,训练更快、更健壮,
通常使用更快的收敛 LSTM 单元管理两个状态向量,并且出于性能原因,它们默认保持分开:
? ? ?𝑡作为短期状态
? ? 𝑐𝑡作为长期状态
GRU
LSTM相比较最基本的RNN,在NLP的很多应用场景下都表现出了很好的性能,至今依然很常用。但是,LSTM存在一个问题,就是计算开销比较大,因为其内部结构相对复杂。GRU 也是为了旨在解决标准 RNN 中出现的梯度消失问题,可以看做是LSTM的一种变种。其实在大多数情况下GRU的性能和LSTM几乎相差无几(甚至有时候LSTM效果更好,且LSTM是1997年提出的,经受了更多的历史考验),但GRU最大的优势就是 简单(因为只有两个门),计算开销小,更加适用于大规模数据集。
-
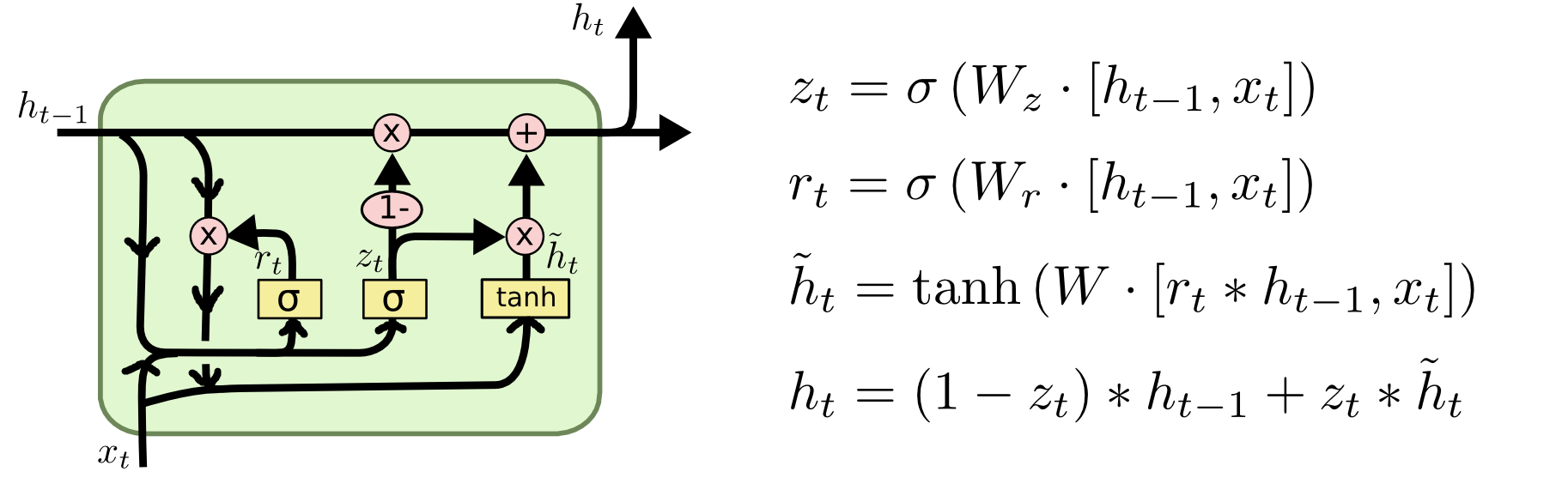
更新门(update gate)
decides how much the unitupdates its state
z t = σ ( U z x t + W z h t ? 1 ) z_{t}=\sigma\left(U^{z} x_{t}+W^{z} h_{t-1}\right) zt?=σ(Uzxt?+Wzht?1?)
-
重置门(reset gate)
controls which parts of the state get used to compute the next target state. 控制该州的哪些部分用于计算下一个目标状态
r t = σ ( U r x t + W r h t ? 1 ) r_{t}=\sigma\left(U^{r} x_{t}+W^{r} h_{t-1}\right) rt?=σ(Urxt?+Wrht?1?)
-
memory state当前时间步的记忆
a linear interpolation (插值)between ?𝑡?1 and 𝑔𝑡
h t = ( 1 ? Z t ) h t ? 1 + Z t ? g t h_{t}=\left(1-Z_{t}\right) h_{t-1}+Z_{t} \bigodot g_{t} ht?=(1?Zt?)ht?1?+Zt??gt?
where the candidate 𝑔𝑡 is pre-computed g t = tanh ? ( U g x t + W g ? ( r t ⊙ h t ? 1 ) ) g_{t}=\tanh \left(U^{g} x_{t}+W^{g} \cdot\left(r_{t} \odot h_{t-1}\right)\right) gt?=tanh(Ugxt?+Wg?(rt?⊙ht?1?))
When 𝑧 𝑡 𝑧_𝑡 zt? and 𝑟 𝑡 𝑟_𝑡 rt? are close to 1, GRU will be reduced to Basic RNN
当𝑧𝑡和𝑟𝑡接近1时,GRU将减少为基本RNN
例子
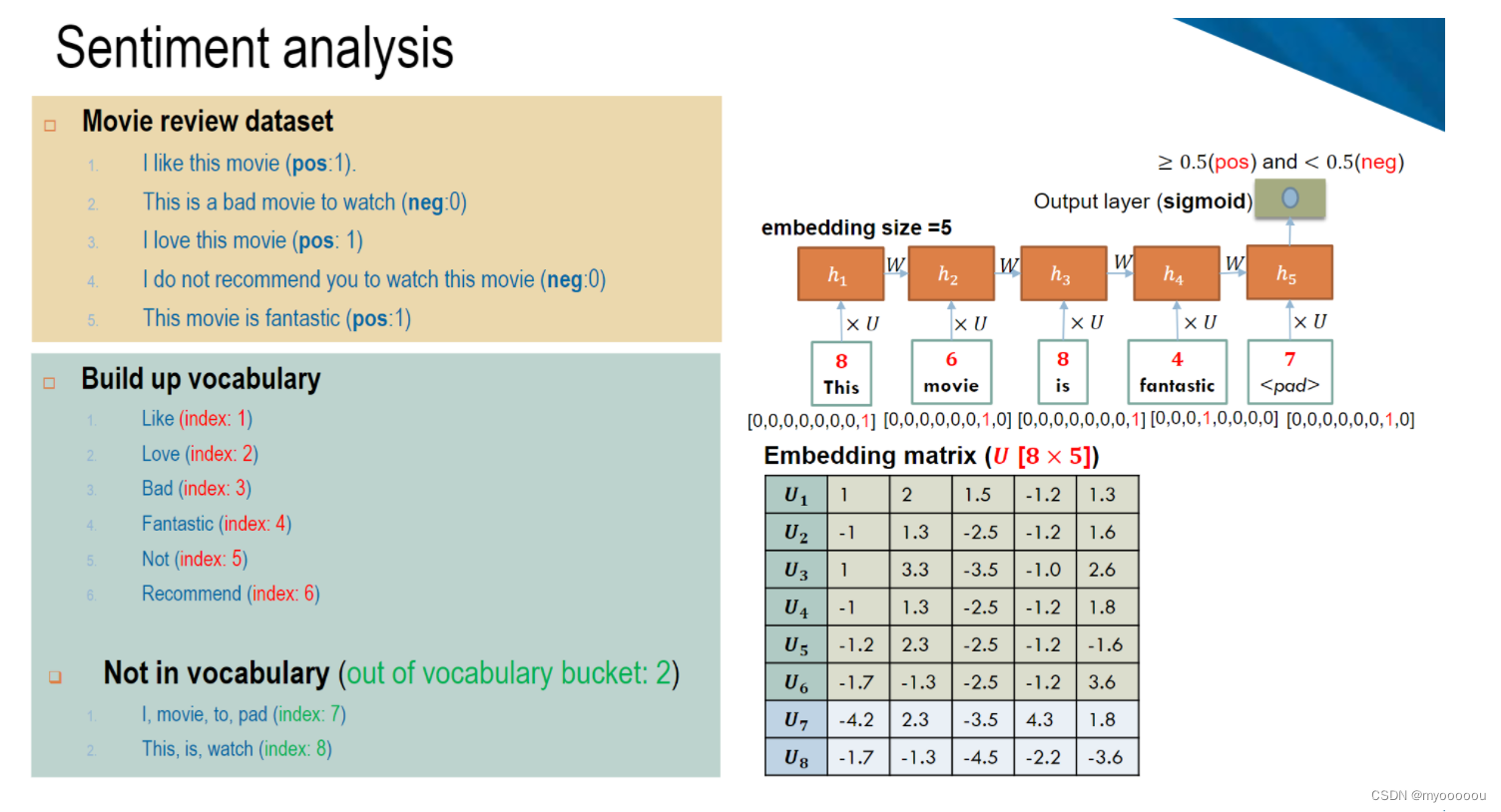
情感分析

Text generation
