目标检测 二阶段原始模型从rcnn到fasterrcnn
目标检测模型
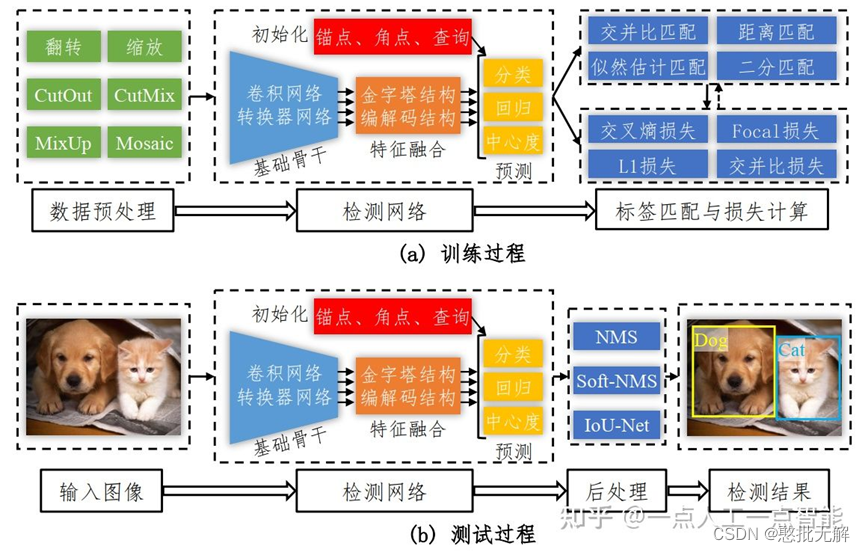
1.1Rcnn
1.使用selective search方法找出图片中可能存在目标的侯选区域region proposal。
2.进行图片大小调整为了适应AlexNet网络的输入图像的大小227×227,通过CNN对候选区域提取特征向量,2000个建议框的CNN特征组合成2000×4096维矩阵。
3.将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘(20种分类,SVM是二分类器,则有20个SVM),获得2000×20维矩阵。
4.分别对2000×20维矩阵中每一列即每一类进行非极大值抑制(NMS:non-maximum suppression)剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
5.(IoU超过阈值的修正,没超过丢弃)修正bbox,对bbox做回归微调。
1.2SPPNet

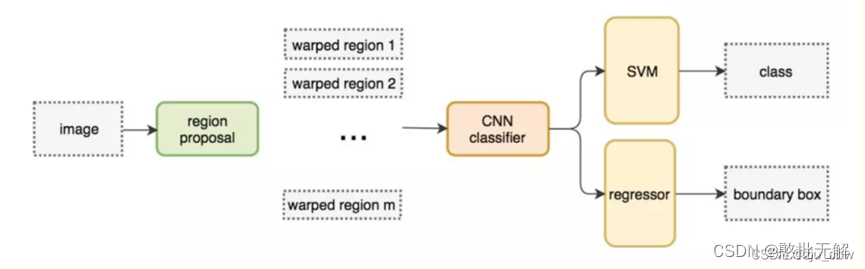
- SPP的核心在于使用多个不同尺寸sliding window pooling(上图中的蓝色44、青色22、灰色1*1窗口)对上层(卷积层)获得的feature maps 进行采样(池化,文中使用最大池化),将分别得到的结果进行合并就会得到固定长度的输出。
- 上图可以看出SPP层就是在前一卷积层得到的feature maps上进行了3个池化操作(实际情况根据自己设定的池化个数,控制全连接层的输入,下面会讲)。最右边的就是原图像,中间的是把图像分成大小是4的特征图,最右边的就是把图像分成大小是16的特征图。这样每一个feature map就会变成固定的21(16+4+1)个feature maps。
通俗的讲,SPP就相当于标准通道层,不管任何大小的图像,我都用一套标准的pool(文中说叫: l-level pyramid)对图像进行池化,最后组合成一列相同大小的特征,作为全连接层的输入,这一组相同大小的特征是固定的,可以提前进行计算,计算的方法和规则下面进行讲解。
1.3Fast R-CNN
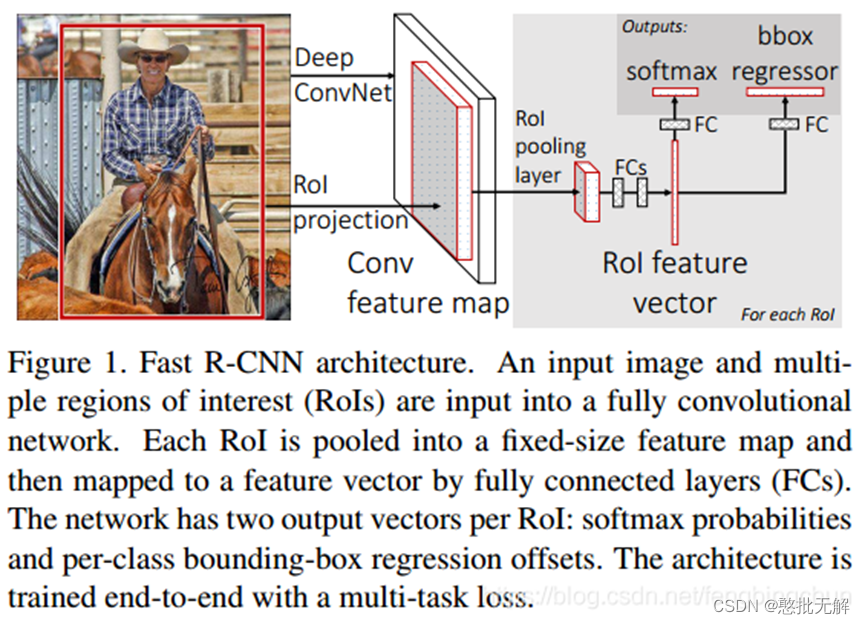
Fast R-CNN的主要创新点有:将最后一个卷积层的SSP Layer改为RoI Pooling Layer;另外提出了多任务损失函数(Multi-task Loss),将边框回归直接加入到CNN网络中训练,同时包含了候选区域分类损失和位置回归损失。
1.4Faster R-CNN
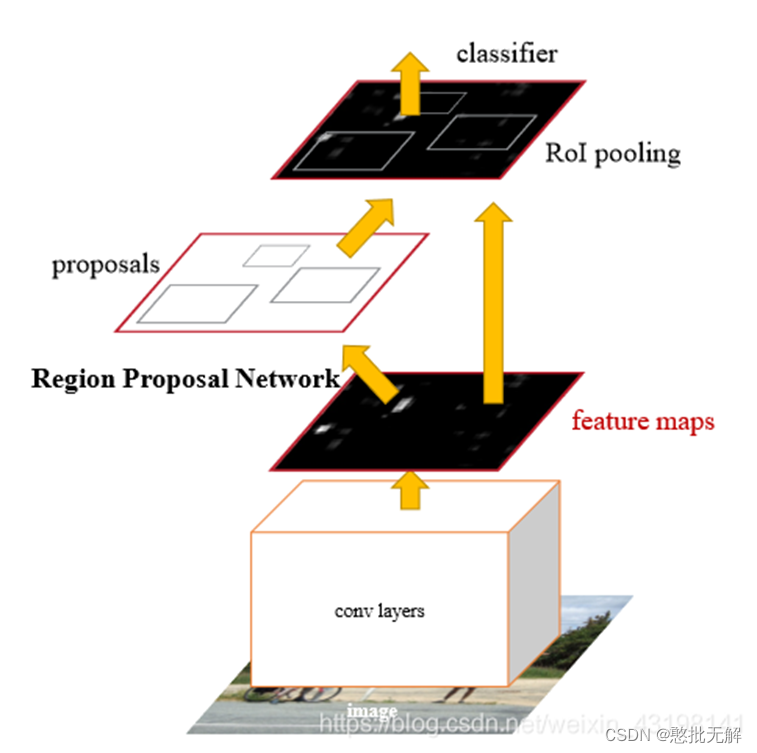
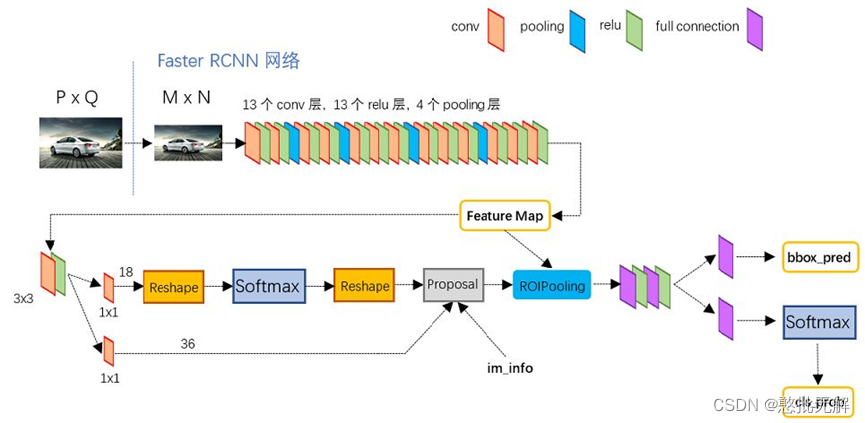 (1)输入测试图像;
(1)输入测试图像;
(2)将整张图片输入CNN,进行特征提取;
(3)用RPN先生成一堆Anchor box,对其进行裁剪过滤后通过softmax判断anchors属于前景(foreground)或者后景(background),即是物体or不是物体,所以这是一个二分类;同时,另一分支bounding box regression修正anchor box,形成较精确的proposal(注:这里的较精确是相对于后面全连接层的再一次box regression而言)
(4)把建议窗口映射到CNN的最后一层卷积feature map上;
(5)通过RoI pooling层使每个RoI生成固定尺寸的feature map;
(6)利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练.
目标检测中的其他技术
2.1 SelectiveSearch 选择性搜索
首先将每个像素作为一组。然后,计算每一组的纹理,并将两个最接近的组结合起来。但是为了避免单个区域吞噬其他区域,我们首先对较小的组进行分组。我们继续合并区域,直到所有区域都结合在一起。下图第一行展示了如何使区域增长,第二行中的蓝色矩形代表合并过程中所有可能的 ROI。

SelectiveSearch在一张图片上提取出来约2000个侯选区域,需要注意的是这些候选区域的长宽不固定。 而使用CNN提取候选区域的特征向量,需要接受固定长度的输入,所以需要对候选区域做一些尺寸上的修改。
2.2NMS 非极大值抑制
非极大值抑制的流程:所谓非极大值抑制:依靠分类器得到多个候选框,以及关于候选框中属于类别的概率值,根据分类器得到的类别分类概率做排序,具体算法流程如下:
(1)将所有框的得分排序,选中最高分及其对应的框
(2)遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除。(为什么要删除,是因为超过设定阈值,认为两个框的里面的物体属于同一个类别,比如都属于狗这个类别。我们只需要留下一个类别的可能性框图即可。)
(3)从未处理的框中继续选一个得分最高的,重复上述过程。
2.3修正候选区域(边框回归)
解释版本1:
回归用于修正筛选后的候选区域,使之回归于ground-truth,默认认为这两个框之间是线性关系,因为在最后筛选出来的候选区域和ground-truth很接近了
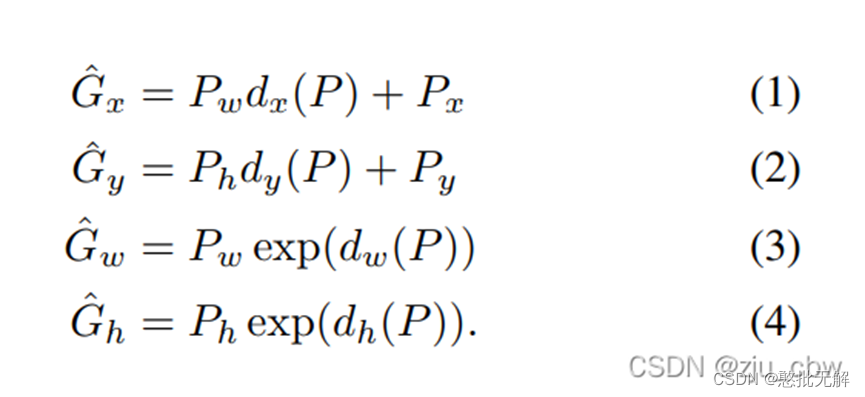

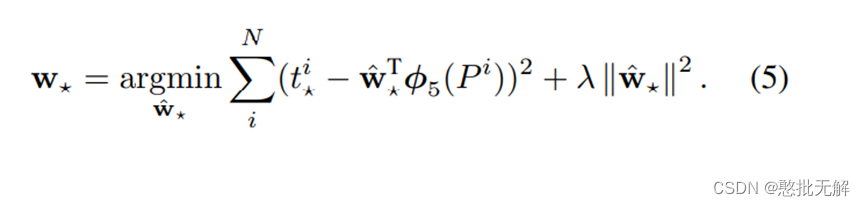
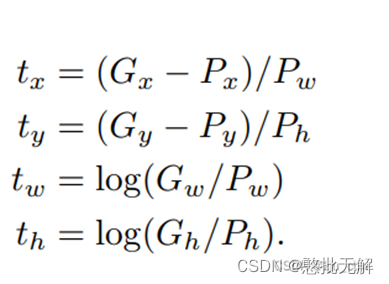
解释版本2:
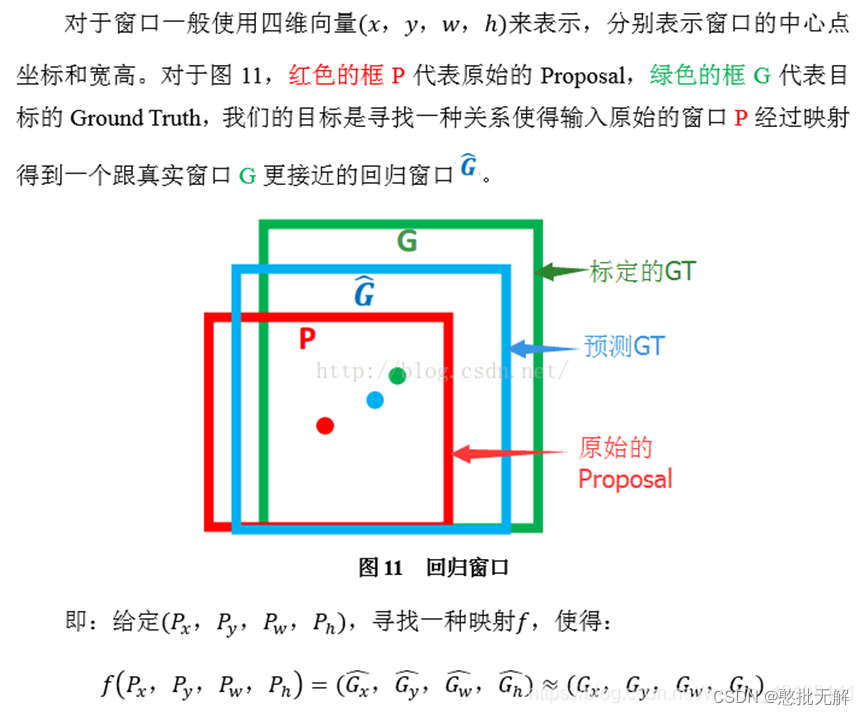




2.4 特征金字塔
2.5 空间金字塔 SSP layer
空间金字塔的优点:
- 不管输入尺寸是怎样,SPP 可以产生固定大小的输出
- 使用多个窗口(pooling window)
- SPP 可以使用同一图像不同尺寸(scale)作为输入, 得到同样长度的池化特征。
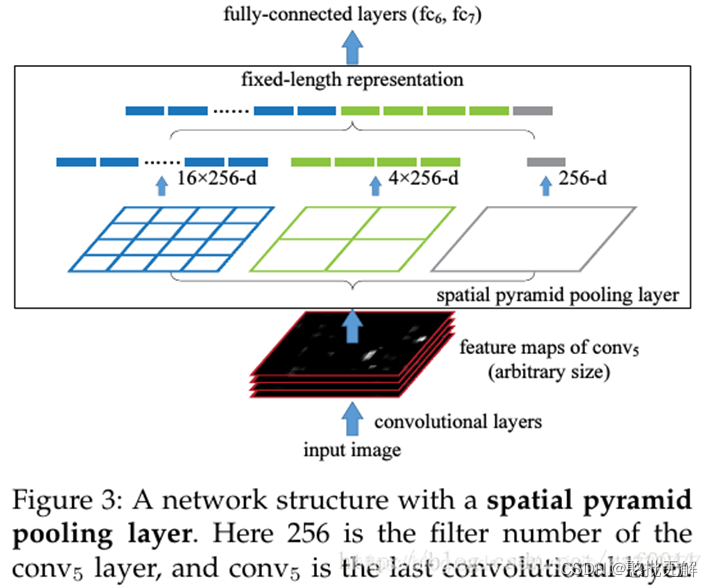
假设
? 输入数据大小是(c,hin,win)(c,hin,win),分别表示通道数,高度,宽度
? 池化数量:(n,n)
那么则有
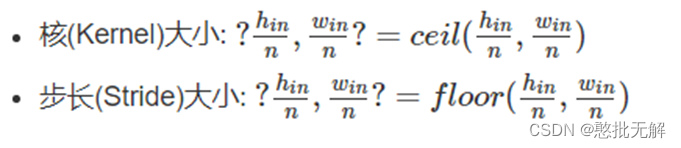
2.6 RoI Pooling Layer与SPP Layer对比
RoI Pooling Layer:实际上是SPP Layer的简化版,SPP Layer对每个候选区域使用了不同大小的金字塔映射,即SPP Layer采用多个尺度的池化层进行池化操作;而RoI Pooling Layer只需将不同尺度的特征图下采样到一个固定的尺度(例如77)。例如对于VGG16网络conv5_3有512个特征图,虽然输入图像的尺寸是任意的,但是通过RoI Pooling Layer后,均会产生一个77512维度的特征向量作为全连接层的输入,即RoI Pooling Layer只采用单一尺度进行池化。如下图所示:
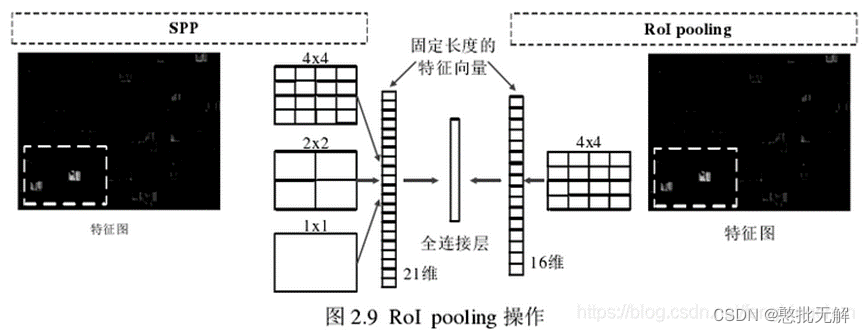
对于每一个虚线窗口内的卷积特征,SPP层采用3种尺度池化层进行下采样,将每个虚线框分别分成11bin, 22bin, 44bin,对每个bin内的特征分别采用max pooling,这样一共21个bin共得到21维的特征向量,然后将该特征向量送入全连接层中。而对于RoI pooling层则采用一种尺度的池化层进行下采样,将每个RoI区域的卷积特征分成4*4个bin,然后对每个bin内采用max pooling,这样就得到一共16维的特征向量。SPP层和RoI pooling层使得网络对输入图像的尺寸不再有限制,同时RoI pooling解决了SPP无法进行权值更新的问题。RoI pooling层有两个主要作用:第一个:将图像中的RoI区域定位到卷积特征中的对应位置;第二个:将这个对应后的卷积特征区域通过池化操作固定到特定长度的特征,然后将该特征送入全连接层。
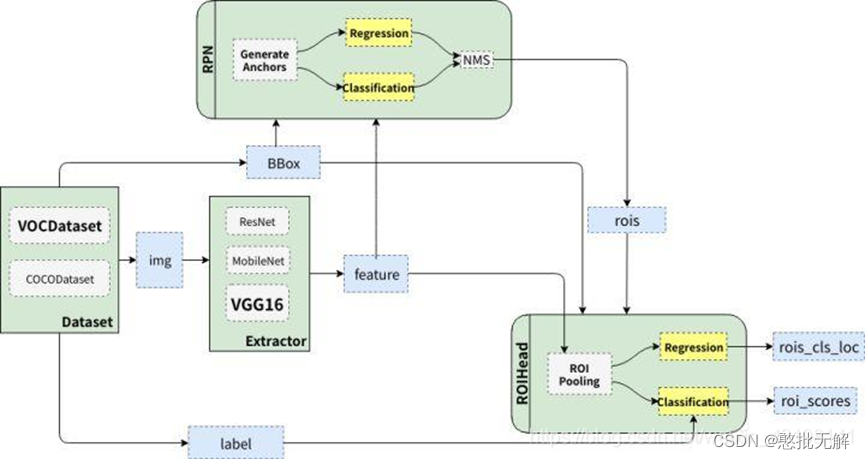
2.7 Region Proposal Networks(RPN)
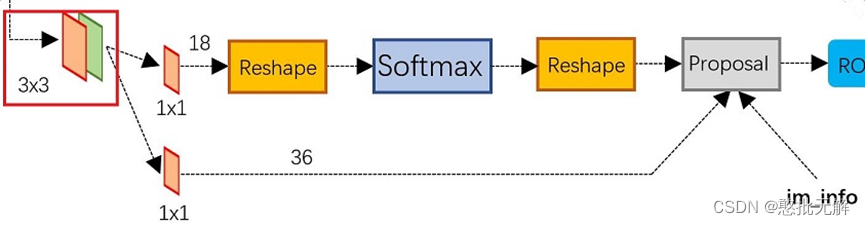
可以看到RPN网络实际分为2条线,上面一条通过softmax分类anchors获得positive和negative分类,下面一条用于计算对于anchors的bounding box regression偏移量,以获得精确的proposal。而最后的Proposal层则负责综合positive anchors和对应bounding box regression偏移量获取proposals,同时剔除太小和超出边界的proposals。其实整个网络到了Proposal Layer这里,就完成了相当于目标定位的功能
生成Anchors:anchor是固定尺寸的bbox。具体做法是:把feature map每个点映射回原图的感受野的中心点当成一个基准点,然后围绕这个基准点选取k个不同的尺寸和比例的anchor。对于W×H大小的卷积feature map(通常为2400),总共有W×H×k个锚点。默认使用3个尺度和3个纵横比,在每个滑动位置上产生k=9个anchor。在feature map上的每个特征点预测多个region proposals。例如对于像素点个数为 51×39 的一幅feature map上就会产生 51×39×9 个候选框。虽然anchors是基于卷积特征图定义的,但最终的 anchors是相对于原始图片的。
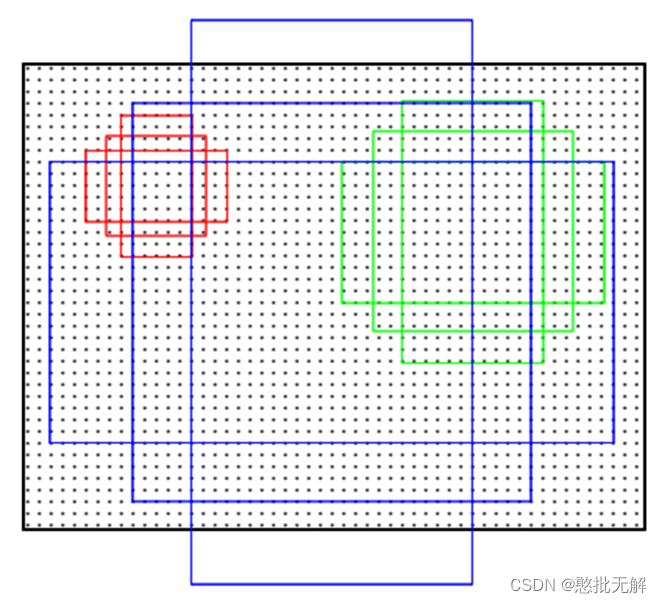
对该像素点的每个候选框需要判断其是不是目标区域,如果是目标区域,其边框位置如何确定,具体过程如图2所示,在RPN头部 ,通过以下结构生成 k个anchor。
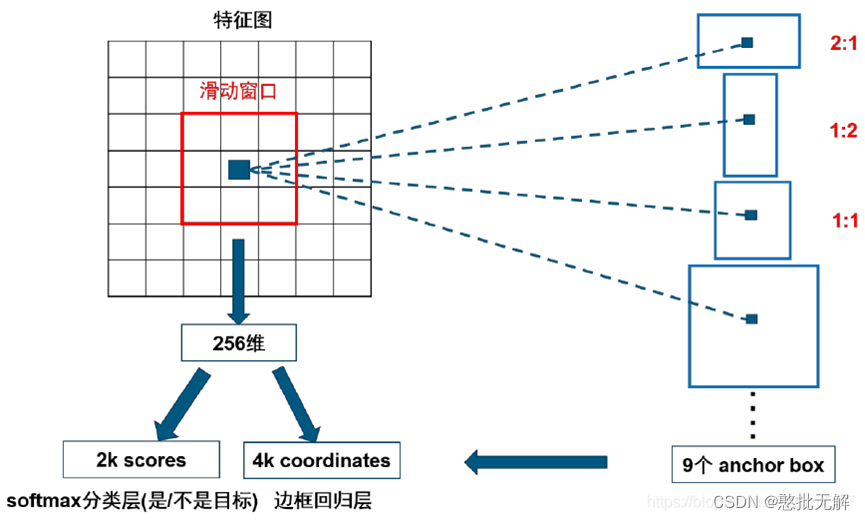
针对特征图中的某一个位置的像素点,对应会有9个候选框。因为输入RPN中有256个通道的特征图,所以要同时对每个通道该位置的像素点都使用不同的3×3的滑动窗口进行卷积,最后将所有通道得到的该位置像素点的卷积值都加起来,得到一个新的特征值,最终使用256组这样的3×3的卷积核,就会得到一个新的256维的向量,这个256维的向量就是用来预测该位置的像素点的,该像素点对应的9个候选框共享这256维向量。
256维向量后面对应两条分支,一条目标和背景的二分类(classification),通过1×1×256×18的卷积核得到 2k 个分数,k等于候选框的个数9,表示这9个anchor是背景的score和anchor是目标的score。如果候选框是目标区域,就去判断该目标区域的候选框位置在哪,这个时候另一条分支就过1×1×256×36的卷积核得到4k个坐标,每个框包含4个坐标(x,y,w,h),就是9个候选区域对应的框应该偏移的具体位置Δxcenter,Δycenter,Δwidth,Δheight。如果候选框不是目标区域,就直接将该候选框去除掉,不再进行后续位置信息的判断操作。