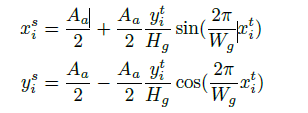Spatial-Aware Feature Aggregation for Cross-View Image based Geo-Localization
-
Spatial-Aware Feature Aggregation for Cross-View Image based Geo-Localization
-
时间
- 2019
-
作者
- Shi Yujiao
-
motivation
-
现在的卷积神经网络,通常将这种问题视作一种metric embedding task,现在由于low recall rates低召回率,表现得并不良好
-
原因如下
- 巨大的域差异,包括外观visual appearance 以及几何配置geometric difference,而这些都是被现在的方法忽视的,现在的方法就只是暴力训练,然后表现较差
-
-
idea
-
研究了一个,着重观察这些被无视的天生的inherent differences的特点
-
作者观察到,就是位于空域图像上的同一方向角的像素点,一般都位于对应的地域的图像的垂直方向上
-
提出了一个两阶段的方法
-
应用一个regular polar transform 常规的极坐标转化
- 这是一个 pure geometric transformation纯粹的几何变换,跟场景的内容无关,所以必然不可能把两个空域对齐 alignment
-
后面又嵌入了自注意力机制,attention mechanism,这样可以使得不同的域更为接近
-
为了提高特征表示的鲁棒性,我们引入了一种通过学习多个空间嵌入的特征聚合策略。 a feature aggregation strategy via learning multiple spatial embeddings
-
现在的方法把这个问题当作一个深度矩阵的学习任务,然后特征上的学习就只是基于图像的内容,但是,两个不同的视角的图片的联系却没有被考虑
-
事实上,同一个物体的位置,在两个图片里是有强烈的联系的
-
去研究这些东西,可以显著减少迷惑性,也是这篇论文的关键
-
对 aerial images 空域的图像采用了polar coordinate transform 极坐标转化,使得能够对齐
-
极坐标转化后,嵌入了一个 Siamese - type network 孪生神经网络,因为极坐标转换并没有将场景的内容纳入考虑
-
在空间嵌入模块里添加了自注意力机制
-
后面又加了一个triplet loss
-
-
Contributions
-
实现了有区别的深度表示 discriminative deep representation,让跨视角视觉定位更精确
-
在精度上有着巨大的提升
-
-
Related work
-
Jegou 将本地的特征聚合成聚类,被称为VLAD descriptors
-
就是把本地的特征集合成一个histogram 直方图,
-
被证明是好用的了
-
然而,手作的特征仍然是表现不好的
-
-
Shi等人[15]提出了一个特征传输模块,以弥合地面和航空图像之间的空间和特征响应域差异,但是,对于这个网络来说,可能同时探索特征和几何关系太难了,只是通过metric learning objective
-
作者结构了构建联系的特征
-
-
实施
-
极坐标转换
-
把空域的图片转换,然后简略地评估geometric correspondence gap
-
简化了学习的难度,并且只需要学习一个简单的特征对应任务
-
把每个空域图片的中心作为极坐标的原点ijinorth direction
-
这里没有 ad hoc(点对点的) pre centering 预先设置中心,也没有假设被检索的地面的图片和空域图片中心一致对应
-
小的偏移量并不影响极坐标转化的结果,并且通过SPE 模型可以减少这方面的影响
-
当产生大的偏移量的时候,这个就是一个negative sample
-
把所有的需要被转化的图片转换成相同的Wg×HgW_g × H_g Wg?×Hg??????????? ,原来的图片尺寸是 Aa×AaA_a × A_aAa?×Aa?????????? ,下面这个是及坐标转换的公式
-
经过极坐标转化,还是会有很多的差别,但是已经很好了
-
-
-
Spatial aware Feature Aggregation
-
一开始布置了一个backbone network,16层的 VGG 19,来提取地面和极坐标转换过的空域的特征
-
嵌入了attention mechanism 注意力机制,来提取salient features 显著的特征,所以开发了一个SAFA module,来减轻扭曲
-
我们的这个模型是基于一个孪生神经网络的输出结果建立的
-
Spatial aware Position Embedding Module
-
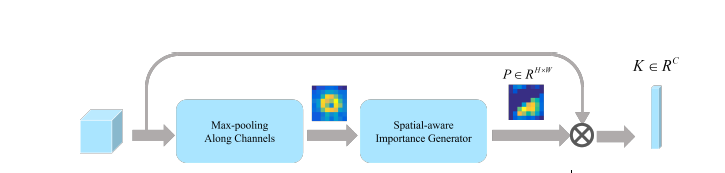
SPE 用来编码被CNN获取的物体的特征的相关位置,输入特征图,SPE就能自动决定一个编码的位置地图
-
这个是自注意力之,没有任何的监督
-
下面这个是一个流程图,先用了一个最大池化操作,选择那些最割裂的特征,然后采用一个Spatial- aware Importance Generator (这里有两个全连接层,)来生成一个特征编码地图。
-
-
这个方法可以减轻极坐标转化带来的割裂的影响,特征不仅能表现特定的对象的出现,也能反映这个对象的位置
-
计算公式
-
通过聚合我们的编码的特征,可以提升我们的特征表示
-
使用了多重Mulitiple Position - Embedded Feature Aggregation
- 就是做了好多个,通过赋予不同的权重,来关注不同的内容,比如有的关注路,有的关注树
-
-
-
-
训练
-
应用了一个metric learning 度量学习
-
应用triplet loss来使得详尽的对子更近,不匹配的对子更远
-
-
实验
-
数据集
- 训练用的CVUSA 和 CVACT
-
先用VGG 16, 然后结果输出到SAFA 里
-
-
评估
- 用的 Top K recall accuracy
-
结果
-
选取的是CVM-NET 和 Liu & Li的方法进行比较
-
全部都远远超过
-
-
Ablation Study 消融实验,就是设置对照组
-
就是分别去掉极坐标转换和SPE模型,然后测试一下效果
-
然后还可以测试一下我们这个算法,在其他人的论文模型上的应用是否可以提升数据
-
-
-