����Ŀ¼
֧��������(SVM)
֧��������(Support Vector Machine),������ѧϰ�������С���ǿ����㷨ģ��,û��֮һ��
�����䱳���ģ��˼�롢��ѧԭ����Ϊ��ɬ�Ѷ�,���Ա�ƪ���¾���ʹ��ͨ�����Խ���֧��������������ԭ������ѧ�Ƶ���
ֱ�۵ı�������
���Ƕ�֪��,֧��������(SVM)�ֵ�Ӧ�ó�����Ϊ��������,�������Ч�طֿ����ֲ�ͬ�����
����,������������ͼ,������ɫ����ɫ�ֱ�Ϊ��ͬ�������ݵ�,��λ�һ��ֱ���ܹ��ֿ�������������? �����������µ����ݵ�,��ֱ���Ƿ�����ȷ�ػ�����?
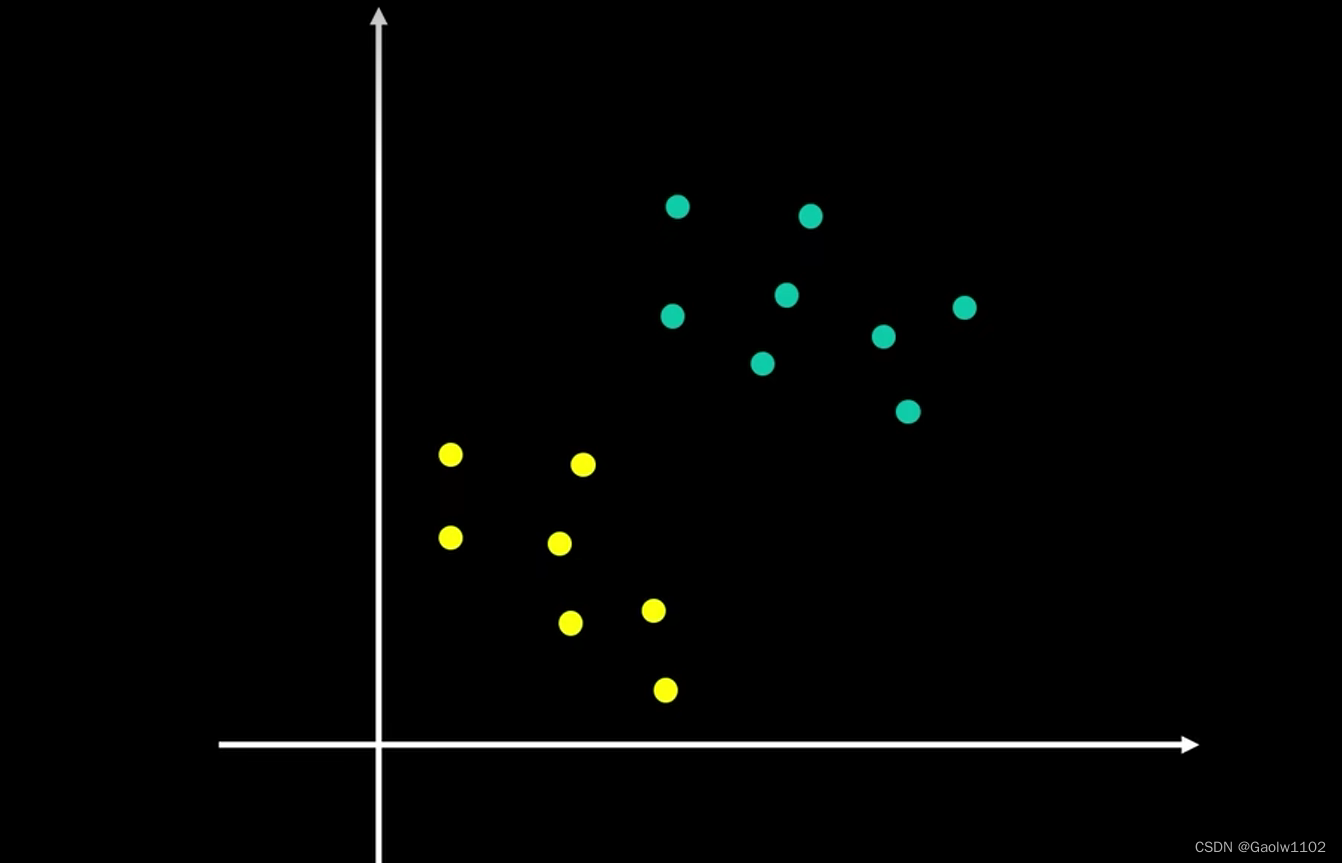
���������µ����ֻ���,��������ȷ�������������ݵ�,���������ݼ�������ʱ,���Ǹ�ѡ�����ֻ�����?
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-rL8n4AD2-1662989561592)(attachment:QQ%E6%88%AA%E5%9B%BE20220912100150.png)]](https://img-blog.csdnimg.cn/34c10241d76c4a0aae83fb50366df820.png)
��������ѡ��ֱ��1���������������,���ܻ���������������:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Bae9BDbF-1662989561593)(attachment:QQ%E6%88%AA%E5%9B%BE20220912095324.png)]](https://img-blog.csdnimg.cn/ac2e9640a13a4d0aa7122491f20abce6.png)
���������ӵĵ����ʵ���Ϊ��ɫ,���Ǹ���ֱ��1�Ļ��ַ�ʽԤ�������ӵ����Ϊ��ɫ,�����ͻ����Ԥ�����,������ֱ��1�ķ�ʽ�з��Dz������ġ�
ͬ��,����ֱ��3�Ļ��ַ�ʽҲ�Dz���ѧ�ġ�������ѡ��ֱ��2�Ļ��ַ�ʽ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-sNLQKZy3-1662989561594)(attachment:QQ%E6%88%AA%E5%9B%BE20220912105546.png)]](https://img-blog.csdnimg.cn/974ed54980f3409eaf1369b9e9c18448.png)
��������Ҳ�����ƹ㵽3ά�ռ�,�����Ǹ�ά�ռ�, ����ͼ3ά�ռ������Dz������»��ַ�ʽ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-hu9igBTw-1662989561597)(attachment:QQ%E6%88%AA%E5%9B%BE20220912094620.png)]](https://img-blog.csdnimg.cn/ee0fe769c7594e2bbbc80a5c5dfc0193.png)
��������ı��ʾ�����һ��nά������������,���Ǹ�������һ�����Ż���n-1ά��ƽ��( W 1 X 1 + W 2 X 2 + . . . + W n X n + B = 0 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B = 0 W1?X1?+W2?X2?+...+Wn?Xn?+B=0)ȥ���ֲ�ͬ�������ݡ�
֮��Ԥ����������ʱ,ͨ�����ź��� s i g n ( W 1 X 1 + W 2 X 2 + . . . + W n X n + B ) sign(W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B) sign(W1?X1?+W2?X2?+...+Wn?Xn?+B)���������ݽ��з��ࡣ
������������
������˵��һЩ����,�������ܸ�������������ģ�͵Ĺ���ԭ����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-OwlGhAkd-1662989561598)(attachment:QQ%E6%88%AA%E5%9B%BE20220912112439.png)]](https://img-blog.csdnimg.cn/9e6cd471d54c4263ba5f257857a76b23.png)
���߳�ƽ��
���߳�ƽ��(Decision Hyperplane),����ͼ,�����������ֲ�ͬ������ݵij�ƽ��(��2ά�����м�Ϊֱ��)��
����ƽ��
����( W 1 X 1 + W 2 X 2 + . . . + W n X n + B > = 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B >= 1 W1?X1?+W2?X2?+...+Wn?Xn?+B>=1)���е�λ������ƽ��, �ڸó�ƽ���ڵ����ݵ���������Ϊһ�����
����ƽ��
����( W 1 X 1 + W 2 X 2 + . . . + W n X n + B < = ? 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B <= -1 W1?X1?+W2?X2?+...+Wn?Xn?+B<=?1)���е�λ�ڸ���ƽ��, �ڸó�ƽ���ڵ����ݵ���������Ϊ��һ���
���߽߱�
�ھ����������ͳ�Ʒ���������,���߽߱�(Decision Boundary)����߱����dz�����,�佫���������ռ仮��Ϊ��������,һ�����ϡ� ������(SVM) �����߽߱�һ������е����Ϊ����һ����,������һ������е����Ϊ������һ���ࡣ(�ٶȰٿ�)
֧������
֧������(Support Vector)��λ�ھ��߽߱��ϵ��������ݵ�,�����������,����볬ƽ�������
��֧����������,���볬ƽ�������������һ�������ļ���ѵ�������㱻��Ϊ֧��������
Ӳ���
Ӳ���(Hard Margin),���������߽߱�֮��ľ���,�������������ų�ƽ������Ѱ��һ���߱� ���Ӳ���(Max Hard Margin) �����⡣
Ӳ��������������쳣�ĵ�,�������������������߽߱������߳�ƽ��֮�ڵĵ�,ͨ�������������������״̬�µ�,��֮��Ե����������
�����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Ooltx2YX-1662989561600)(attachment:QQ%E6%88%AA%E5%9B%BE20220912114225.png)]](https://img-blog.csdnimg.cn/37d1ca02abd04334ad5b02961bbad691.png)
�����(Soft Margin),�߱�һ�����ݴ���,�ܹ����������������쳣ֵ�ij���,����ͼ�ڼ������ʹ����С֮��Ѱ��һ��ƽ�⡣
����Ӳ�������Ϊ����,�쳣����(��ʧloss)����Ϊ�ɱ�,��ô�������Ϊ ���� - �ɱ� = ����,����ͼѰ���������ֵ,����������(Max Soft Margin)��
���߳�ƽ������(SVMģ�͵��Ƶ�)
�����Ͽ�֪,SVM�ĺ����������Ѱ�����ų�ƽ������,Ҳ��Ѱ�����߽߱�������������
��� Ӳ���(Hard Margin) �µľ��߳�ƽ��(���������)��,���߳�ƽ��( W 1 X 1 + W 2 X 2 + . . . + W n X n + B = 0 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B = 0 W1?X1?+W2?X2?+...+Wn?Xn?+B=0)��������÷��ź�������������Ԥ����ࡣ
���Ӳ�����Ѱ���빫ʽ����
����,������ѡȡ����֧������ x n , x m x_n, x_m xn?,xm?,�ֱ����������ͬ�����,����ͼ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-SFO6tzzb-1662989561601)(attachment:QQ%E6%88%AA%E5%9B%BE20220912131546.png)]](https://img-blog.csdnimg.cn/6954a29e85af4344932d9e3447338298.png)
��Ϊ��������ھ��߽߱���,�ʱض��������·���ʽ
{ w 1 x 1 m + w 2 x 2 m + b = 1 ( 1 ) w 1 x 1 n + w 2 x 2 n + b = ? 1 ( 2 ) \begin{cases} w_{1}x_{1m} + w_{2}x_{2m} + b = 1\qquad\qquad\qquad\left (1)\right.\\ w_{1}x_{1n} + w_{2}x_{2n} + b = -1\qquad\qquad\qquad\left (2)\right. \end{cases} {w1?x1m?+w2?x2m?+b=1(1)w1?x1n?+w2?x2n?+b=?1(2)?
����ʽ(1) - ��ʽ(2),�ɵõ�ʽ(3)����
w 1 x 1 m ? w 1 x 1 n + w 2 x 2 m ? w 2 x 2 n = 2 w_{1}x_{1m} - w_{1}x_{1n} + w_{2}x_{2m} - w_{2}x_{2n} = 2 w1?x1m??w1?x1n?+w2?x2m??w2?x2n?=2
( w 1 x 1 m + w 2 x 2 m ) ? ( w 1 x 1 n + w 2 x 2 n ) = 2 (w_{1}x_{1m} + w_{2}x_{2m}) -(w_{1}x_{1n} + w_{2}x_{2n}) = 2 (w1?x1m?+w2?x2m?)?(w1?x1n?+w2?x2n?)=2
ת��Ϊ�����˻���ʽ(�����ʽ),���ɵù�ʽ(3)
w ? ? x m ? ? w ? ? x n ? = w ? ? ( x m ? ? x n ? ) = 2 ( 3 ) \vec{ w } \cdot \vec{x_m} - \vec{w} \cdot \vec{x_n} = \vec{ w } \cdot (\vec{x_m} - \vec{x_n}) = 2\qquad\qquad\qquad(3) w?xm???w?xn??=w?(xm???xn??)=2(3)
������ӻ���ʾ,��Ϊ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-SFsAFb5T-1662989561602)(attachment:QQ%E6%88%AA%E5%9B%BE20220912135421.png)]](https://img-blog.csdnimg.cn/f07d250727114e91a485d1909699c9b0.png)
�����ٴ�ѡ�������� x p , x o x_p,x_o xp?,xo?,����ͼ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-64KyT3fx-1662989561603)(attachment:QQ%E6%88%AA%E5%9B%BE20220912134013.png)]](https://img-blog.csdnimg.cn/b5ec8b64b94b4bf6a8973f2b18589dca.png)
���� x p , x o x_{p}, x_{o} xp?,xo?���ھ��߳�ƽ����,�ʱ��������µ�ʽ
{ w 1 x 1 p + w 2 x 2 p + b = 0 ( 4 ) w 1 x 1 o + w 2 x 2 o + b = 0 ( 5 ) \begin{cases} w_1x_{1p} + w_2x_{2p} + b = 0\qquad\qquad\qquad(4)\\ w_1x_{1o} + w_2x_{2o} + b = 0\qquad\qquad\qquad(5) \end{cases} {w1?x1p?+w2?x2p?+b=0(4)w1?x1o?+w2?x2o?+b=0(5)?
������ʽ(4) - ��ʽ(5),�ɵù�ʽ(6)����
w 1 x 1 p ? w 1 x 1 o + w 2 x 2 p ? w 2 x 2 o = 0 w_1x_{1p} - w_1x_{1o} + w_2x_{2p} - w_2x_{2o} = 0 w1?x1p??w1?x1o?+w2?x2p??w2?x2o?=0
( w 1 x 1 p + w 2 x 2 p ) ? ( w 1 x 1 o + w 2 x 2 o ) = 0 (w_1x_{1p} + w_2x_{2p}) - (w_1x_{1o} + w_2x_{2o}) = 0 (w1?x1p?+w2?x2p?)?(w1?x1o?+w2?x2o?)=0
ת��Ϊ�����˻���ʽ(�����ʽ),���ɵù�ʽ(6)
w ? ? x p ? ? w ? ? x o ? = w ? ? ( x p ? ? x o ? ) = 0 ( 6 ) \vec{ w } \cdot \vec{x_p} - \vec{w} \cdot \vec{x_o} = \vec{ w } \cdot (\vec{x_p} - \vec{x_o}) = 0\qquad\qquad\qquad(6) w?xp???w?xo??=w?(xp???xo??)=0(6)
�Ѹù�ʽ���ӻ����ֳ���,��Ϊ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-OWwXXRuf-1662989561605)(attachment:QQ%E6%88%AA%E5%9B%BE20220912135613.png)]](https://img-blog.csdnimg.cn/149d67f78ef14a14b0e04e4f6270b784.png)
�ɹ�ʽ(6)��֪,���� w ? \vec{w} w������ x o ? ? x p ? \vec{x_o} - \vec{x_p} xo???xp??���ڻ�Ϊ0,���������ڻ�������֪,�ڻ�Ϊ0,��������ֱ��
����Ϊ���� x o ? �� x p ? \vec{x_o} �� \vec{x_p} xo??��xp??�ھ��߳�ƽ����,������ w ? \vec{w} w��ֱ�ھ��߳�ƽ����
���ǰѹ�ʽ(3)��ʽ(6)������������п��ӻ�,����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-npLREg1y-1662989561606)(attachment:QQ%E6%88%AA%E5%9B%BE20220912141028.png)]](https://img-blog.csdnimg.cn/a4f41938422f49ce862e8c6540b5545f.png)
�ɹ�ʽ(6)��֪,���� w ? \vec{w} w��ֱ�ھ��߳�ƽ��,�������������Ϊ L, �� L = �O �O x m ? ? x n ? �O �O ? cos ? �� ||\vec{x_m} - \vec{x_n}|| * \cos{\theta} �O�Oxm???xn??�O�O?cos��,���ʱ L ��Ϊ�������
����Ϊ��ʽ(3)Ϊ w ? ? ( x m ? ? x n ? ) = 2 \vec{ w } \cdot (\vec{x_m} - \vec{x_n}) = 2 w?(xm???xn??)=2,��Ϊ �O �O w ? �O �O ? cos ? �� ? �O �O x m ? ? x n ? �O �O ||\vec{ w }|| * \cos{\theta} * ||\vec{x_m} - \vec{x_n}|| �O�Ow�O�O?cos��?�O�Oxm???xn??�O�O = 2,�� cos ? �� ? �O �O x m ? ? x n ? �O �O = 2 �O �O w ? �O �O \cos{\theta} * ||\vec{x_m} - \vec{x_n}|| = \frac{2}{||\vec{ w }||} cos��?�O�Oxm???xn??�O�O=�O�Ow�O�O2?��
����,���Եõ� ���������Ϊ
L = 2 �O �O w ? �O �O L = \frac{2}{||\vec{ w }||} L=�O�Ow�O�O2?
����ת��һ��˼·,�� max ? L = 2 �O �O w ? �O �O \max{L = \frac{2}{||\vec{ w }||}} maxL=�O�Ow�O�O2?,��Ϊ��
min ? �O �O w ? �O �O \min{||\vec{w}||} min�O�Ow�O�O
������Լ������,����Ϊ��������ƽ���ϵ����ݵ������ W 1 X 1 + W 2 X 2 + . . . + W n X n + B > = 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B >= 1 W1?X1?+W2?X2?+...+Wn?Xn?+B>=1,�Ҷ�Ӧ����� Y i = 1 Y_i = 1 Yi?=1
��������ƽ���ϵ����ݵ������ W 1 X 1 + W 2 X 2 + . . . + W n X n + B < = ? 1 W_{1}X_{1} + W_{2}X_{2} + ... + W_{n}X_{n} + B <= -1 W1?X1?+W2?X2?+...+Wn?Xn?+B<=?1,�Ҷ�Ӧ����� Y i = ? 1 Y_i = -1 Yi?=?1
������Լ������ʽΪ
y i ? ( w ? ? x ? + b ) > = 1 y_i * (\vec{w}\cdot\vec{x} + b) >= 1 yi??(w?x+b)>=1
�����������ǵ��ռ�Ŀ�������!������Լ�������µ���Сֵ �O �O w ? �O �O ||\vec{w}|| �O�Ow�O�O����,����
{ min ? �O �O w ? �O �O y i ? ( w ? ? x ? + b ) > = 1 , ���� i = 1 , 2 , . . . , S ( S Ϊȫ�������� ) \begin{cases} \min{||\vec{w}||}\\ y_i * (\vec{w}\cdot\vec{x} + b) >= 1, ���� i = 1, 2, ... , S(SΪȫ��������) \end{cases} {min�O�Ow�O�Oyi??(w?x+b)>=1,����i=1,2,...,S(SΪȫ��������)?
�������ճ�������Ӧ��
���ǰ������ֵ����������任��,���� �O �O w ? �O �O = w 1 2 + w 2 2 ||\vec{w}|| = \sqrt{w_1^2 + w_2^2} �O�Ow�O�O=w12?+w22??,���Զ�����ƽ���ٳ�2,����Ӱ����Сֵ�����,��ʱ����ɱ仯Ϊ
{ min ? �O �O w ? �O �O 2 2 y i ? ( w ? ? x ? + b ) > = 1 , ���� i = 1 , 2 , . . . , S ( S Ϊȫ�������� ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b) >= 1, ���� i = 1, 2, ... , S(SΪȫ��������) \end{cases} {min2�O�Ow�O�O2?yi??(w?x+b)>=1,����i=1,2,...,S(SΪȫ��������)?
�ٶԸ��������н�һ��ת��
{ min ? �O �O w ? �O �O 2 2 y i ? ( w ? ? x ? + b ) ? 1 > = 0 , ���� i = 1 , 2 , . . . , S ( S Ϊȫ�������� ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b)-1 >= 0, ���� i = 1, 2, ... , S(SΪȫ��������) \end{cases} {min2�O�Ow�O�O2?yi??(w?x+b)?1>=0,����i=1,2,...,S(SΪȫ��������)?
�趨 p i 2 p_i^2 pi2? >= 0,��Լ���IJ���ʽת��Ϊ��ʽԼ������,�Ӷ�ʹ���������ճ��ӷ���⼫ֵ��
��ʱ��Լ�������µļ�ֵ����ת��Ϊ
{ min ? �O �O w ? �O �O 2 2 y i ? ( w ? ? x ? + b ) ? 1 = p i 2 , ���� i = 1 , 2 , . . . , S ( S Ϊȫ�������� ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b)-1 = p_i^2, ���� i = 1, 2, ... , S(SΪȫ��������) \end{cases} {min2�O�Ow�O�O2?yi??(w?x+b)?1=pi2?,����i=1,2,...,S(SΪȫ��������)?
��ʱ�Ϳ���Ӧ���������ճ�������,�ȹ����������ճ�������ʽ����:
L ( w , b , �� i , p i 2 ) = �O �O w ? �O �O 2 2 ? �� i = 1 s �� i ? ( y i ? ( w ? ? x ? + b ) ? 1 ? p i 2 ) L(w,b,\lambda_i, p_i^2) = \frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x} + b) -1 - p_i^2) L(w,b,��i?,pi2?)=2�O�Ow�O�O2??i=1��s?��i??(yi??(w?x+b)?1?pi2?)
Ϊ�����������շ���ʽ�ļ�ֵ,���Ƕ� w��b�� �� i �� p i \lambda_i��p_i ��i?��pi?��ƫ��������Ϊ0,�ɵ�
( 1 ) �� L �� w = w ? ? �� i = 1 s �� i ? y i ? x ? = 0 \quad(1)\qquad\frac{\delta{L}}{\delta{w}} = \vec{w} - \sum\limits_{i=1}^s{\lambda_i} * y_i \cdot \vec{x} = 0 (1)��w��L?=w?i=1��s?��i??yi??x=0
( 2 ) �� L �� b = ? �� i = 1 s �� i ? y i = 0 \quad(2)\qquad\frac{\delta{L}}{\delta{b}} = -\sum\limits_{i=1}^s{\lambda_i} * y_i = 0 (2)��b��L?=?i=1��s?��i??yi?=0
( 3 ) �� L �� �� i = ? ( y i ? ( w ? ? x ? + b ) ? 1 ? p i 2 ) = ( y i ? ( w ? ? x ? + b ) ? 1 ? p i 2 ) = 0 \quad(3)\qquad\frac{\delta{L}}{\delta{\lambda_i}} = -(y_i * (\vec{w}\cdot\vec{x} + b) - 1 - p_i^2) = (y_i * (\vec{w}\cdot\vec{x} + b) - 1 - p_i^2) =0 (3)����i?��L?=?(yi??(w?x+b)?1?pi2?)=(yi??(w?x+b)?1?pi2?)=0
( 4 ) �� L �� p i = ? 2 p i �� i = 0 \quad(4)\qquad\frac{\delta{L}}{\delta{p_i}} = -2p_i\lambda_i = 0 (4)��pi?��L?=?2pi?��i?=0
��ʽ(4)Ҳ����ת��Ϊ �� i p i 2 = 0 \lambda_ip_i^2 = 0 ��i?pi2?=0,
����ʽ(3)���뵽��ʽ(4)��ɵ�, �� i ? ( y i ? ( w ? ? x ? + b ) ? 1 ) = 0 \lambda_i * (y_i * (\vec{w}\cdot\vec{x} + b) - 1) = 0 ��i??(yi??(w?x+b)?1)=0
���� y i ? ( w ? ? x ? + b ) ? 1 > = 0 y_i * (\vec{w}\cdot\vec{x} + b) - 1 >= 0 yi??(w?x+b)?1>=0,���DZ��������µIJ���:
- �� �� i = 0 \lambda_i = 0 ��i?=0ʱ, y i ? ( w ? ? x ? + b ) ? 1 > = 0 y_i * (\vec{w}\cdot\vec{x} + b)-1 >= 0 yi??(w?x+b)?1>=0���Գ�����
- �� �� i �� 0 \lambda_i \neq 0 ��i?��=0ʱ, y i ? ( w ? ? x ? + b ) ? 1 = 0 y_i * (\vec{w}\cdot\vec{x} + b)-1 = 0 yi??(w?x+b)?1=0���Գ�����
- ��
��
i
<
0
\lambda_i < 0
��i?<0ʱ,��
y
i
?
(
w
?
?
x
?
+
b
)
?
1
<
0
y_i * (\vec{w}\cdot\vec{x} + b)-1 < 0
yi??(w?x+b)?1<0������Լ������ʱ,��
��
i
=
1
s
��
i
?
(
y
i
?
(
w
?
?
x
?
+
b
)
?
1
?
p
i
2
)
>
0
\sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x} + b) -1 - p_i^2) > 0
i=1��s?��i??(yi??(w?x+b)?1?pi2?)>0,
L ( w , b , �� i , p i 2 ) = �O �O w ? �O �O 2 2 ? �� i = 1 s �� i ? ( y i ? ( w ? ? x ? + b ) ? 1 ? p i 2 ) L(w,b,\lambda_i, p_i^2) = \frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x} + b) -1 - p_i^2) L(w,b,��i?,pi2?)=2�O�Ow�O�O2??i=1��s?��i??(yi??(w?x+b)?1?pi2?)���ø�С,���ͬ�ڱ�������Υ��Լ��ȥ��ø�Сֵ,����Ȼ�Dz����ϳ�����
����ֻ�� �� i > = 0 \lambda_i >= 0 ��i?>=0����,��ô��������Ѿ��õ���5������,Ҳ����KKT����(�������Դ�����),����
( 1 ) w ? ? �� i = 1 s �� i y i ? x ? = 0 \quad(1)\qquad\vec{w} - \sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x} = 0 (1)w?i=1��s?��i?yi??x=0
( 2 ) ? �� i = 1 s �� i y i = 0 \quad(2)\qquad-\sum\limits_{i=1}^s{\lambda_i} y_i = 0 (2)?i=1��s?��i?yi?=0
( 3 ) y i ? ( w ? ? x ? + b ) ? 1 > = 0 \quad(3)\qquad y_i * (\vec{w}\cdot\vec{x} + b) - 1 >= 0 (3)yi??(w?x+b)?1>=0
( 4 ) �� i ( y i ? ( w ? ? x ? + b ) ? 1 ) = 0 \quad(4)\qquad \lambda_i (y_i * (\vec{w}\cdot\vec{x} + b) - 1 )= 0 (4)��i?(yi??(w?x+b)?1)=0
( 5 ) �� i > = 0 \quad(5)\qquad \lambda_i >= 0 (5)��i?>=0
����KKT����,���ǾͿ���������յľ��߳�ƽ����,������SVMģ����,Ϊ�˸������ʹ�ú˼��� Kernel Trick,����ͨ��ʹ��ԭ�������ż������������⡣
��Ϊ�ü�ֵ�������� KKT����,������ǿ��ż����(��Ҫ����),��ֱ��ʹ�ö�ż��������
ʹ�ö�ż�������
�����ٴλص���������ļ�ֵ�������ʽ��
{ min ? �O �O w ? �O �O 2 2 y i ? ( w ? ? x ? + b ) ? 1 > = 0 , ���� i = 1 , 2 , . . . , S ( S Ϊȫ�������� ) \begin{cases} \min{\frac{||{\vec{w}}||^2}{2}}\\ y_i * (\vec{w}\cdot\vec{x} + b)-1 >= 0, ���� i = 1, 2, ... , S(SΪȫ��������) \end{cases} {min2�O�Ow�O�O2?yi??(w?x+b)?1>=0,����i=1,2,...,S(SΪȫ��������)?
���Ķ�ż����Ϊ(����������Ҳ���Ǻ����������,��Ҫ����ѧ����̫�����������,�����㶮�˻Ჹ����,����Ȥ��С�������аٶ�)
m a x ( q ( �� i ) ) = m a x ( m i n ( �O �O w ? �O �O 2 2 ? �� i = 1 s �� i ? ( y i ? ( w ? ? x i ? + b ) ? 1 ) ) ) , �� i > = 0 , i = 1 , 2 , . . . , s max(q(\lambda_i)) = max(min(\frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x_i} + b) -1))), \lambda_i>= 0, \qquad i=1,2,...,s max(q(��i?))=max(min(2�O�Ow�O�O2??i=1��s?��i??(yi??(w?xi??+b)?1))),��i?>=0,i=1,2,...,s
���������Ѿ���õ� KKT ����,���м�(�˴��õ��˹�ʽ(1��2))
m a x ( q ( �� i ) ) = m a x ( m i n ( �O �O w ? �O �O 2 2 ? �� i = 1 s �� i ? ( y i ? ( w ? ? x i ? + b ) ? 1 ) ) ) max(q(\lambda_i)) = max(min(\frac{||{\vec{w}}||^2}{2} - \sum\limits_{i = 1}^s{\lambda_i} * (y_i * (\vec{w}\cdot\vec{x_i} + b) -1))) max(q(��i?))=max(min(2�O�Ow�O�O2??i=1��s?��i??(yi??(w?xi??+b)?1)))
= m a x ( m i n ( �� i = 1 s �� i y i ? x i ? ? �� j = 1 s �� j y j ? x j ? 2 ? �� i = 1 s �� i ? y i ? ( w ? ? x i ? ) + �� i = 1 s �� i ) ) = max(min(\frac{\sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x_i} * \sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i} * y_i * (\vec{w}\cdot\vec{x_i}) + \sum\limits_{i = 1}^s{\lambda_i})) =max(min(2i=1��s?��i?yi??xi???j=1��s?��j?yj??xj????i=1��s?��i??yi??(w?xi??)+i=1��s?��i?))
= m a x ( �� i = 1 s �� i y i ? x i ? ? �� j = 1 s �� j y j ? x j ? 2 ? �� i = 1 s �� i ? y i ? ( �� j = 1 s �� j y j ? x j ? ? x i ? ) + �� i = 1 s �� i ) = max(\frac{\sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x_i} * \sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i} * y_i * (\sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}\cdot\vec{x_i}) + \sum\limits_{i = 1}^s{\lambda_i}) =max(2i=1��s?��i?yi??xi???j=1��s?��j?yj??xj????i=1��s?��i??yi??(j=1��s?��j?yj??xj???xi??)+i=1��s?��i?)
= m a x ( ? �� i = 1 s �� i y i ? x i ? ? �� j = 1 s �� j y j ? x j ? 2 + �� i = 1 s �� i ) = max(-\frac{\sum\limits_{i=1}^s{\lambda_i} y_i \cdot \vec{x_i} * \sum\limits_{j=1}^s{\lambda_j} y_j \cdot \vec{x_j}}{2} + \sum\limits_{i = 1}^s{\lambda_i}) =max(?2i=1��s?��i?yi??xi???j=1��s?��j?yj??xj???+i=1��s?��i?)
= m a x ( ? �� i = 1 s �� j = 1 s �� i �� j y i y j ? x i ? ? x j ? 2 + �� i = 1 s �� i ) = max(-\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} + \sum\limits_{i = 1}^s{\lambda_i}) =max(?2i=1��s?j=1��s?��i?��j?yi?yj??xi???xj???+i=1��s?��i?)
����֮�����ܹ�ȥ�� min ��Сֵ����,����Ϊ�Ѿ����������ճ���������ļ�Сֵʱ�IJ����������,��ֵ��Ϊ��Сֵ��
��������ֵõ���һ������ֵ����,������Ҳ�߱�����Լ������
�� i = 1 s �� i y i = 0 , K K T ��ʽ ( 2 ) \sum\limits_{i=1}^s \lambda_i y_i = 0, \qquad KKT��ʽ(2) i=1��s?��i?yi?=0,KKT��ʽ(2)
�� i > = 0 , K K T ��ʽ ( 5 ) \lambda_i >= 0, \qquad KKT��ʽ(5) ��i?>=0,KKT��ʽ(5)
Ϊ�˷��ϳ���,���ǰ����յ� �� \lambda �� ���ֵ����ת��Ϊ��Сֵ����,��
m a x ( q ( �� ) ) = m a x ( ? �� i = 1 s �� j = 1 s �� i �� j y i y j ? x i ? ? x j ? 2 + �� i = 1 s �� i ) = m i n ( �� i = 1 s �� j = 1 s �� i �� j y i y j ? x i ? ? x j ? 2 ? �� i = 1 s �� i ) max(q(\lambda)) = max(-\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} + \sum\limits_{i = 1}^s{\lambda_i}) = min(\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i}) max(q(��))=max(?2i=1��s?j=1��s?��i?��j?yi?yj??xi???xj???+i=1��s?��i?)=min(2i=1��s?j=1��s?��i?��j?yi?yj??xi???xj????i=1��s?��i?)
���������ڵõ����յ�Լ��������ֵ����:
{ q ( �� i ) = m i n ( �� i = 1 s �� j = 1 s �� i �� j y i y j ? x i ? ? x j ? 2 ? �� i = 1 s �� i ) , �� i = 1 s �� i y i = 0 , �� i > = 0 , i = 1 , 2 , . . . , s \begin{cases} q(\lambda_i) = min(\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i}),\\ \sum\limits_{i=1}^s \lambda_i y_i = 0,\\ \lambda_i >= 0, \qquad i=1,2,...,s \end{cases} ? ? ??q(��i?)=min(2i=1��s?j=1��s?��i?��j?yi?yj??xi???xj????i=1��s?��i?),i=1��s?��i?yi?=0,��i?>=0,i=1,2,...,s?
ʹ���������ճ�������� �� i \lambda_i ��i?,�ٸ��� KKT(��ʽ1) ��� w ? \vec{w} w,�ٸ��ݾ��߳�ƽ�� y i ? ( w ? ? x i ? + b ) ? 1 = 0 y_i*(\vec{w}\cdot\vec{x_i} + b) - 1 = 0 yi??(w?xi??+b)?1=0���b,����
w ? = �� i = 1 s �� i y i ? x i ? \vec{w} = \sum\limits_{i=1}^s{\lambda_i}{y_i}\cdot\vec{x_i} w=i=1��s?��i?yi??xi??
b = 1 y i ? w ? ? x i ? b = \frac{1}{y_i} - \vec{w}\cdot\vec{x_i} b=yi?1??w?xi??
���ɹ������߳�ƽ��
w ? ? x ? + b = 0 \vec{w} \cdot \vec{x} + b = 0 w?x+b=0
�����������ߺ���
f ( x i ) = s i g n ( w ? ? x ? + b ) f(x_i) = sign(\vec{w} \cdot \vec{x} + b) f(xi?)=sign(w?x+b)
һ��С����(�����߳�ƽ������ߺ���)
ǰ���Ƶ�����ô�ʽԭ��,������ЩС�����Ȼû���ܹ�����,�������Լ�Ҳ�����κ�����,�����������ĵؿ����ܲ��ܼ�ס��
����������һ��С������Ϊ��β,ϣ���ܶԴ������������
������3�����ݵ�ֱ�Ϊ X 1 ( 1 , 1 ) , X 2 ( 3 , 2 ) , X 3 ( 2 , 4 ) X_1(1, 1), X_2(3,2), X_3(2,4) X1?(1,1),X2?(3,2),X3?(2,4) ,���ǵ�ʵ�ʷ���Ϊ y 1 = 1 , y 2 = 1 , y 3 = ? 1 y_1 = 1,y_2 = 1,y_3 = -1 y1?=1,y2?=1,y3?=?1,����ʹ�� ֧���������㷨(SVM) ������߳�ƽ�� w ? ? x ? + b = 0 \vec{w} \cdot \vec{x} + b = 0 w?x+b=0 (�˴�Ϊֱ��),��Ԥ�����ݵ� X ( 2 , 1 ) X(2, 1) X(2,1)��ֵ��
��:
�����Ƚ������������� X 1 , X 2 , X 3 , y 1 , y 2 , y 3 X_1, X_2, X_3, y_1, y_2, y_3 X1?,X2?,X3?,y1?,y2?,y3?�������յ�֧����������ֵ��ʽ q ( �� i ) = m i n ( �� i = 1 s �� j = 1 s �� i �� j y i y j ? x i ? ? x j ? 2 ? �� i = 1 s �� i ) q(\lambda_i) = min(\frac{\sum\limits_{i=1}^s\sum\limits_{j=1}^s{\lambda_i}{\lambda_j} y_i y_j * \vec{x_i} \cdot \vec{x_j}}{2} - \sum\limits_{i = 1}^s{\lambda_i}) q(��i?)=min(2i=1��s?j=1��s?��i?��j?yi?yj??xi???xj????i=1��s?��i?),��
q ( �� 1 , �� 2 , �� 3 ) = 1 2 ( �� 1 2 ? 1 ? 2 + �� 1 �� 2 ? 1 ? 5 + �� 1 �� 3 ? ( ? 1 ) ? 6 + �� 2 �� 1 ? 1 ? 5 + �� 2 2 ? 1 ? 13 + �� 2 �� 3 ? ( ? 1 ) ? 14 + �� 3 �� 1 ? ( ? 1 ) ? 6 + �� 3 �� 2 ? ( ? 1 ) ? 14 + �� 3 2 ? 1 ? 20 ) ? ( �� 1 + �� 2 + �� 3 ) \begin {aligned} q(\lambda_1,\lambda_2,\lambda_3) = \frac{1}{2}(\lambda_1^2*1*2 + \lambda_1 \lambda_2*1*5 + \lambda_1 \lambda_3*(-1)*6 + \lambda_2 \lambda_1*1*5 + \lambda_2^2*1*13 + \lambda_2 \lambda_3*(-1)*14 \\ + \lambda_3 \lambda_1*(-1)*6 + \lambda_3 \lambda_2*(-1)*14 + \lambda_3^2*1*20) - (\lambda_1 + \lambda_2 + \lambda_3) \end {aligned} q(��1?,��2?,��3?)=21?(��12??1?2+��1?��2??1?5+��1?��3??(?1)?6+��2?��1??1?5+��22??1?13+��2?��3??(?1)?14+��3?��1??(?1)?6+��3?��2??(?1)?14+��32??1?20)?(��1?+��2?+��3?)?
��������,�ɵ�
q ( �� 1 , �� 2 , �� 3 ) = 1 2 ( 2 �� 1 2 + 13 �� 2 2 + 20 �� 3 2 + 10 �� 1 �� 2 ? 12 �� 1 �� 3 ? 28 �� 2 �� 3 ) ? ( �� 1 + �� 2 + �� 3 ) \begin {aligned} q(\lambda_1,\lambda_2,\lambda_3) = \frac{1}{2}(2\lambda_1^2 + 13\lambda_2^2 + 20\lambda_3^2 + 10\lambda_1 \lambda_2 - 12\lambda_1 \lambda_3 - 28 \lambda_2 \lambda_3) - (\lambda_1 + \lambda_2 +\lambda_3) \end {aligned} q(��1?,��2?,��3?)=21?(2��12?+13��22?+20��32?+10��1?��2??12��1?��3??28��2?��3?)?(��1?+��2?+��3?)?
����Ϊ��Լ������ �� i = 1 s �� i y i = 0 \sum\limits_{i=1}^s \lambda_i y_i = 0 i=1��s?��i?yi?=0,��֪
�� 1 + �� 2 ? �� 3 = 0 \lambda_1 + \lambda_2 - \lambda_3 = 0 ��1?+��2??��3?=0
��
�� 1 + �� 2 = �� 3 \lambda_1 + \lambda_2 = \lambda_3 ��1?+��2?=��3?
����������������ʽ����,�ɵ�
q ( �� 1 , �� 2 ) = 1 2 ( 2 �� 1 2 + 13 �� 2 2 + 20 ( �� 1 + �� 2 ) 2 + 10 �� 1 �� 2 ? 12 �� 1 ( �� 1 + �� 2 ) ? 28 �� 2 ( �� 1 + �� 2 ) ) ? 2 ( �� 1 + �� 2 ) = 1 2 ( 10 �� 1 2 + 5 �� 2 2 + 10 �� 1 �� 2 ) ? 2 ( �� 1 + �� 2 ) \begin {aligned} q(\lambda_1,\lambda_2) &= \frac{1}{2}(2\lambda_1^2 + 13\lambda_2^2 + 20(\lambda_1 + \lambda_2)^2 + 10\lambda_1 \lambda_2 - 12\lambda_1 (\lambda_1 + \lambda_2) - 28 \lambda_2 (\lambda_1 + \lambda_2)) - 2(\lambda_1 + \lambda_2)\\ &= \frac{1}{2}(10\lambda_1^2 + 5\lambda_2^2 + 10\lambda_1 \lambda_2) - 2(\lambda_1 + \lambda_2) \end {aligned} q(��1?,��2?)?=21?(2��12?+13��22?+20(��1?+��2?)2+10��1?��2??12��1?(��1?+��2?)?28��2?(��1?+��2?))?2(��1?+��2?)=21?(10��12?+5��22?+10��1?��2?)?2(��1?+��2?)?
�������� �� 1 , �� 2 \lambda_1,\lambda_2 ��1?,��2?�ֱ���ƫ��,������Ϊ 0,��
{ F �� 1 1 = 10 �� 1 + 5 �� 2 ? 2 = 0 F �� 2 1 = 5 �� 1 + 5 �� 2 ? 2 = 0 \begin{cases} F_{\lambda_1}^1 = 10\lambda_1 + 5\lambda_2 - 2 = 0\\ F_{\lambda_2}^1 = 5\lambda_1 + 5\lambda_2 - 2 = 0 \end{cases} {F��1?1?=10��1?+5��2??2=0F��2?1?=5��1?+5��2??2=0?
���, �� 1 = 0 , �� 2 = 0.4 , �� 3 = 0.4 \lambda_1 = 0,\lambda_2 = 0.4,\lambda_3 = 0.4 ��1?=0,��2?=0.4,��3?=0.4(�������� �� i > = 0 \lambda_i >=0 ��i?>=0)
���������ݸ�ʽ�� w ? = �� i = 1 s �� i y i ? x i ? \vec{w} = \sum\limits_{i=1}^s{\lambda_i}{y_i}\cdot\vec{x_i} w=i=1��s?��i?yi??xi??,��� w ? \vec{w} w,��
w ? = �� i = 1 s �� i y i ? x i ? = �� 1 ? y 1 ? x 1 ? + �� 2 ? y 2 ? x 2 ? + �� 3 ? y 3 ? x 3 ? = 0.4 ? ( 3 , 2 ) ? 0.4 ? ( 2 , 4 ) = ( 0.4 , ? 0.8 ) \begin {aligned} \vec{w} &= \sum\limits_{i=1}^s{\lambda_i}{y_i}\cdot\vec{x_i}\\ &= \lambda_1 * y_1 \cdot \vec{x_1} + \lambda_2 * y_2 \cdot \vec{x_2} + \lambda_3 * y_3 \cdot \vec{x_3}\\ &= 0.4 * (3,2) - 0.4 * (2, 4)\\ &= (0.4, -0.8) \end {aligned} w?=i=1��s?��i?yi??xi??=��1??y1??x1??+��2??y2??x2??+��3??y3??x3??=0.4?(3,2)?0.4?(2,4)=(0.4,?0.8)?
���� b = 1 y i ? w ? ? x i ? b = \frac{1}{y_i} - \vec{w}\cdot\vec{x_i} b=yi?1??w?xi??���b,�ɵ�(����ѡi,��ֵb����ͬ)
b = 1 y 1 ? w ? ? x 1 ? = 1 ? ( 0.4 , ? 0.8 ) ? ( 1 , 1 ) = 1.4 \begin {aligned} b &= \frac{1}{y_1} - \vec{w} \cdot \vec{x_1}\\ &= 1 - (0.4,-0.8) \cdot (1,1)\\ &= 1.4 \end {aligned} b?=y1?1??w?x1??=1?(0.4,?0.8)?(1,1)=1.4?
����,���ǵõ������߳�ƽ��Ϊ
0.4 X 1 ? 0.8 X 2 + 1.4 = 0 0.4X_1 - 0.8X_2 + 1.4 = 0 0.4X1??0.8X2?+1.4=0
���ߺ���Ϊ
f ( x ) = s i g n ( 0.4 X 1 ? 0.8 X 2 + 1.4 ) f(x) = sign(0.4X_1 - 0.8X_2 + 1.4) f(x)=sign(0.4X1??0.8X2?+1.4)
����Ԥ��� X ( 2 , 1 ) X(2,1) X(2,1), ��
f ( X ) = s i g n ( 0.4 ? 2 ? 0.8 ? 1 + 1.4 ) = s i g n ( 1.4 ) = 1 f(X) = sign(0.4*2 - 0.8*1 + 1.4) = sign(1.4) = 1 f(X)=sign(0.4?2?0.8?1+1.4)=sign(1.4)=1
���ǿ��Խ��������������;��߳�ƽ�滭��,�ж�Ԥ�����Ƿ���ȷ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-B05URHSd-1662989561607)(attachment:QQ%E6%88%AA%E5%9B%BE20220912211201.png)]](https://img-blog.csdnimg.cn/817c333eac784030b46839550b27ad7a.png)
��ͼ�ɼ�,Ԥ������ȷ��
��ϸ�۲�,���Է���һ��Сϸ��,�� X 2 , X 3 X_2,X_3 X2?,X3?��Ϊ֧������,���Ӧ�� �� 2 , �� 3 \lambda_2,\lambda_3 ��2?,��3?��Ϊ0, X 1 X_1 X1?����֧������,���Ӧ�� �� 1 \lambda_1 ��1?���õ���0��
���ö�Ӧ��KKT�����е� �� i ( y i ? ( w ? ? x ? + b ) ? 1 ) = 0 \lambda_i (y_i * (\vec{w}\cdot\vec{x} + b) - 1 )= 0 ��i?(yi??(w?x+b)?1)=0��ʽ,��
- �� X i X_i Xi? ����֧������, y i ? ( w ? ? x ? + b ) ? 1 �� 0 , �� i = 0 �� y_i * (\vec{w}\cdot\vec{x} + b) - 1 \neq 0,\lambda_i = 0�� yi??(w?x+b)?1��=0,��i?=0��
- �� X i X_i Xi? ��֧������, y i ? ( w ? ? x ? + b ) ? 1 = 0 , �� i �� 0 �� y_i * (\vec{w}\cdot\vec{x} + b) - 1 = 0,\lambda_i \neq 0�� yi??(w?x+b)?1=0,��i?��=0��
���仰˵, �� i \lambda_i ��i? ֻ���֧������������,����֧���������ľ��߳�ƽ������ģ����Ч�ʲ���̫����
��
���ڱ�����ѧˮƽ����,�������������Ҳ��һ֪���,���������ճ���������ż�����,ϣ��С�����ָ������֮����
��ƪ���µĺ��ı����ǽ�������Ƴ�֧�������������߳�ƽ�������Լ����ߺ���,�Ӷ��ﵽ���Ż������Ч��,ϣ���ܸ���Ҵ���������