TextCNN
1.理论
1.1 基础概念
在文本处理中使用卷积神经网络:将文本序列当作一维图像
一维卷积 -> 基于互相关运算的二维卷积的特例:

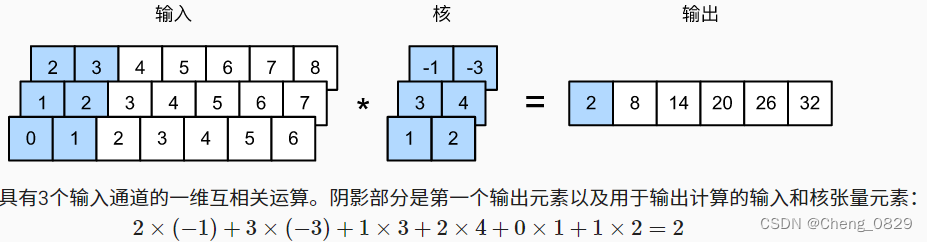
多通道的一维卷积:
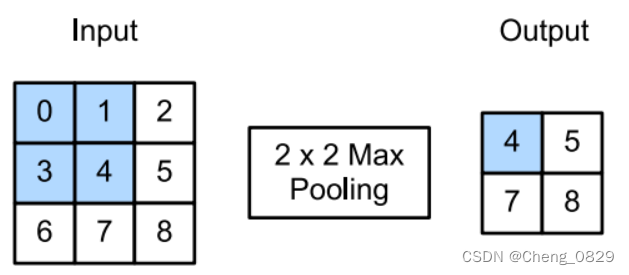
最大汇聚(池化)层:
1.2 textCNN模型结构
textCNN模型设计如下所示:
- 定义多个一维卷积核,并分别对输入执行卷积运算。具有不同宽度的卷积核可以捕获不同数目的相邻词元之间的局部特征
- 在所有输出通道上执行最大时间汇聚层(MaxPool),然后将所有标量汇聚输出连结为向量
- 使用全连接层将连结后的向量转换为输出类别。可以用torch.nn.Dropout(0.5)来减少过拟合。
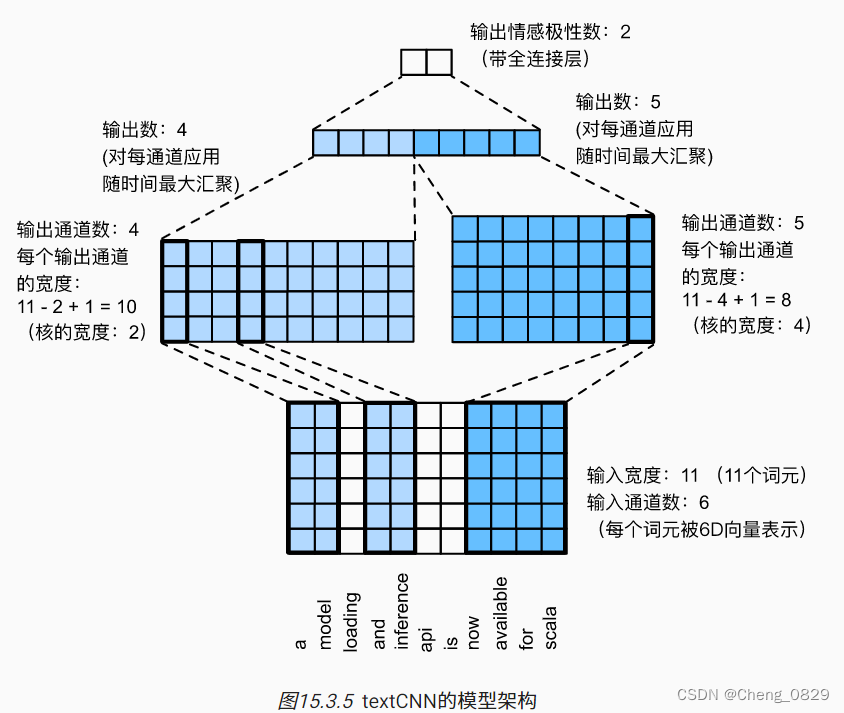
图15.3.5通过一个具体的例子说明了textCNN的模型架构。输入是具有11个词元的句子,其中每个词元由6维向量表示(即单词的嵌入向量长度为6)。定义两个大小为(6,4)和(6,4)的一维卷积核(长必须为嵌入向量长度),这两个卷积核通道数分别为4和5,它们分别4个产生宽度为11-2+1=10的输出通道和5个宽度为11-4+1=8的输出通道。尽管这4+5=9个通道的宽度不同,但最大时间汇聚层在所有输出通道上执行MaxPool,给出了一个宽度的4+5=9的一维向量,该向量最终通过全连接层被转换为用于二元情感预测的2维输出向量
- 和图片不同,由于词元具有不可分割性,所以卷积核的长度必须是嵌入向量长度
- 在文本处理中,卷积核的长度是嵌入向量维度(特征维度),而卷积核的宽度就是N-gram的窗口大小,代表了词元和上下文词之间的词距
2.实验
2.1 实验步骤
- 数据预处理,得到单词字典、样本数等基本数据
- 构建CNN模型,设置卷积核个数、输入输出通道数、宽度和输入嵌入向量的维度
- 训练
- 代入数据,经过卷积和池化,再压平全连接,最后得到类别
- 把模型输出值和真实值相比,求得误差损失函数,运用Adam动量法梯度下降
- 预测
2.2 算法模型
"""
Task: 基于TextCNN的文本情感分类
Author: ChengJunkai @github.com/Cheng0829
Date: 2022/09/06
"""
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
'''1.数据预处理'''
def pre_process(sentences):
# 最大句子长度:3
sequence_length = 0
for sen in sentences:
if len(sen.split()) > sequence_length:
sequence_length = len(sen.split())
# 根据最大句子长度,把所有句子填充成相同长度
for i in range(len(sentences)):
if sequence_length > len(sentences[i].split()):
sentences[i] = sentences[i] + \
(" " + "''") * (sequence_length - len(sentences[i].split()))
# 分词
# ['i', 'love', 'you', 'he', 'loves', 'me', 'she', 'likes', 'baseball', 'i', 'hate', 'you', 'sorry', 'for', 'that', 'this', 'is', 'awful']
word_sequence = " ".join(sentences).split()
# 去重
word_list = list(set(word_sequence))
# 生成字典
word_dict = {w: i for i, w in enumerate(word_list)} # 注意:单词是键,序号是值
# 词库大小:16
vocab_size = len(word_dict)
return word_sequence, word_list, word_dict, vocab_size, sentences, sequence_length
'''2.构建模型'''
class TextCNN(nn.Module): # nn.Module是Word2Vec的父类
def __init__(self):
'''super().__init__()
继承父类的所有方法(),比如nn.Module的add_module()和parameters()
'''
super().__init__()
"""输入层"""
'''W = nn.Embedding(num_embeddings,embedding_dim) -> 嵌入矩阵
Args:
num_embeddings (int): 嵌入字典的大小(单词总数) -> 嵌入向量个数(去重)
embedding_dim (int): 每个嵌入向量的维度(即嵌入向量的长度)
Returns:
X:(sequence_length, words) -> W(X):(sequence_length, words, embedding_dim)
W(X)相当于给X中的6*3个单词,每个输出一个长度为2的嵌入向量,构建真正的嵌入矩阵(按序,不去重)
'''
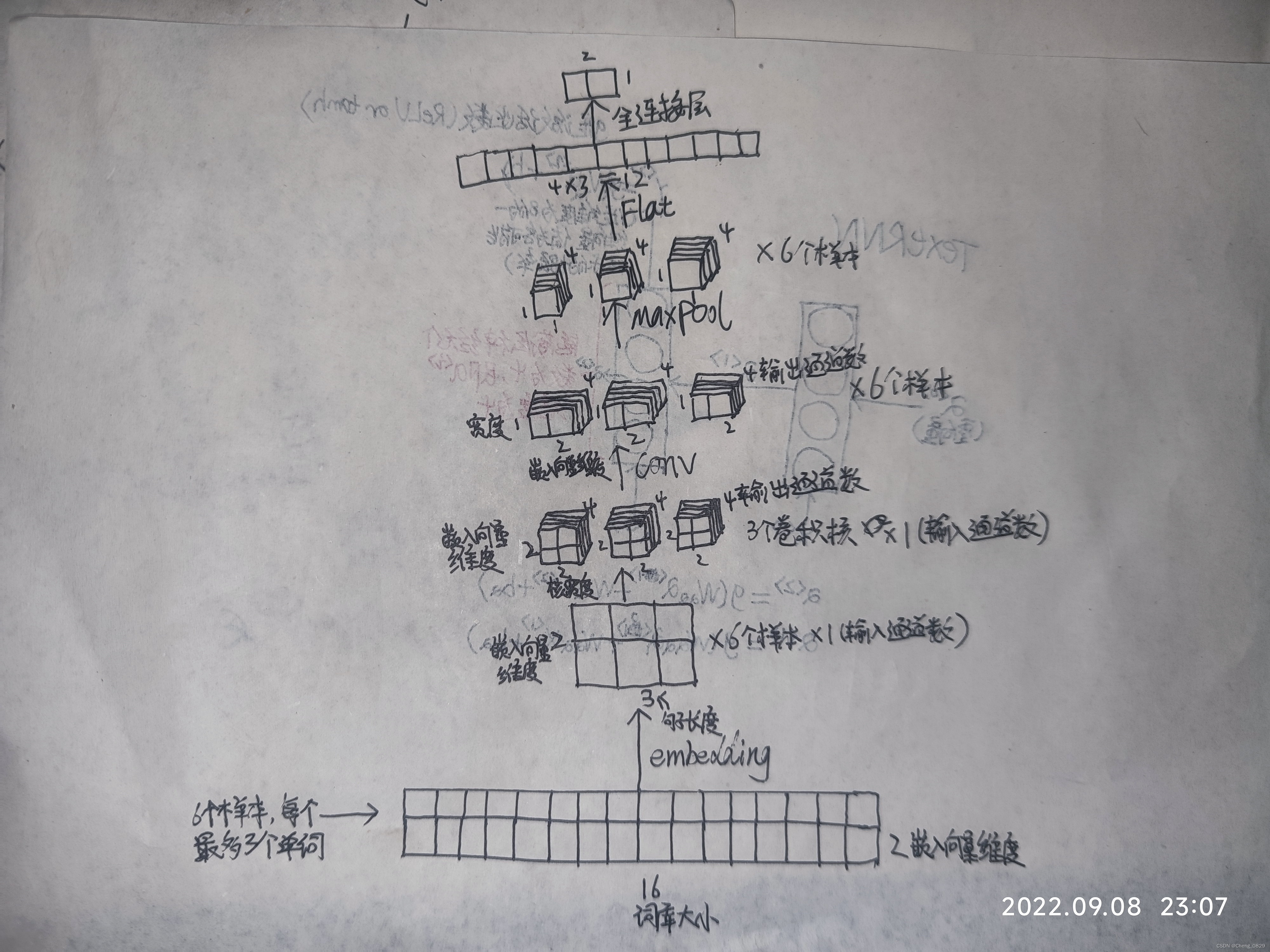
# (16,2) X:(6,3) -> W(X):[6,3,2]:[样本数, 样本单词数, 嵌入向量长度]
num_embeddings = vocab_size
self.W = nn.Embedding(num_embeddings, embedding_size) # (16,2)
"""卷积层"""
self.filter_sizes = filter_sizes # [2, 2, 2]卷积核宽度:2x2,双通道
self.sequence_length = sequence_length # 样本单词数
modules = []
'''nn.Conv2d(in_channels, out_channels, kernel_size)
对于通道数为in_channels的图像(嵌入矩阵),用out_channels个大小为kernel_size的核叠加卷积
Args:
in_channels (int): 输入图像中的通道数(即卷积时的层数,必须等于图像的通道数(层数))
out_channels (int): 卷积产生的通道数(即用几个卷积核叠加)
kernel_size (int or tuple): 卷积内核的大小
'''
# filter_sizes:卷积核宽度(即上下文词距) len(filter_sizes)即代表卷积核数量
for size in filter_sizes:
# 卷积核输出通道数num_channels=4, 嵌入向量维度embedding_size=2
# nn.Conv2d(卷积核输入通道数(层数), 卷积核输出通道数, (卷积核宽度, 嵌入向量维度))
# 和图片不同,由于词元具有不可分割性,所以卷积核的长度必须是嵌入向量维度
modules.append(nn.Conv2d(1, num_channels, (size, embedding_size))) # nn.Conv2d(1,4,2,2)
self.filter_list = nn.ModuleList(modules)
"""全连接层/输出层"""
# 卷积核输出通道数 * 卷积核数量 = 最终通道数(此实验中各卷积核完全一样,其实可以不同)
self.num_filters_total = num_channels * len(filter_sizes) # 4*3=12
# 通过全连接层,把卷积核最终输出通道转换为情感类别
self.Weight = nn.Linear(self.num_filters_total, num_classes, bias=False)
# nn.Parameter()设置可训练参数,用作偏差b
self.Bias = nn.Parameter(torch.ones(num_classes)) # (2,)
def forward(self, X): # X:(6,3)
"""输入层"""
# self.W(X):[batch_size, sequence_length, embedding_size]
'''W(X)相当于在(16,2)的嵌入矩阵W中,给X中的6*3个单词,每个输出一个长度为2的嵌入向量(不去重)'''
'''构建真正的嵌入矩阵(按序,不去重)'''
embedded_inputs = self.W(X) # W(16,2) X(6,3) -> W(X)[6,3,2]
'''unsqueeze(dim):升维
unsqueeze(dim)对于1维向量不起作用;同样的,squeeze(dim)也只对一维矩阵起作用:
例如(3,1) -> squeeze(1) -> (3,)
Args:
dim (int): dim表示新维度的位置
Examples:
>>> a = torch.ones(3,4)
>>> a.shape
(3,4)
>>> a.unsqueeze(0).shape
(1,3,4)
>>> a.unsqueeze(1).shape
(3,1,4)
>>> a.unsqueeze(2).shape
(3,4,1)
'''
# add input_channel(层数)(=1)
# [batch, input_channel(层数)(=1), sequence_length, embedding_size]
embedded_inputs = embedded_inputs.unsqueeze(1) # [6,1,3,2]
"""卷积层"""
pooled_outputs = []
# 遍历卷积核
for i, conv in enumerate(self.filter_list):
'''Conv2d(embedded_inputs) 二维卷积计算
Conv2d:[卷积核输入通道数(层数), 卷积核输出通道数, (卷积核宽度, 嵌入向量维度)] # (1,4,2,2)
1.卷积核输入通道数即卷积时的层数,必须等于图像的通道数(层数)
2.卷积核输出通道数即代表有几个卷积核叠加
Args:
embedded_inputs (array): [样本数, 卷积核输入通道数(层数), 样本单词数, 嵌入向量长度] # [6,1,3,2]
Returns:
[样本数, 卷积核输出通道数, (样本单词数-卷积核宽度+1, 1)] # [6,4,2,1]
'''
'''F.relu(input) relu激活函数
Args:
input (totch.Tensor): 输入,必须是张量
Returns:
a tensor (shape不变,对input中每个数进行relu计算)
'''
# conv:(1,4,2,2) & embedded_inputs:[6,1,3,2] -> [6,4,2,1]
'''6个样本,每个样本的嵌入向量矩阵大小为(3,2),层数为1;卷积核大小(2,2),层数也为1,输出通道为4'''
embedded_outputs = conv(embedded_inputs) # [6,4,2,1]
embedded_outputs = F.relu(embedded_outputs) # [6,4,2,1]
"""池化层"""
'''nn.MaxPool2d(kernel_size)
最大时间汇聚(池化)层在所有输出通道上执行MaxPool(相当于在一个通道上的所有词元中选择最大值),给出了一个宽度的4+5=9的一维向量
Args:
kernel_size (tuple): 池化的窗口大小
# (样本单词数-卷积核宽度+1, 1) 必须与嵌入层输出的大小一样
Returns:
An one-dimensional tensor # (样本单词数-卷积核宽度+1, 1)
'''
maxpool = nn.MaxPool2d((self.sequence_length-self.filter_sizes[i]+1, 1)) # (2,1)
pooled = maxpool(embedded_outputs) # [样本数, 卷积核输出通道数, 1, 1] # [6,4,1,1]
pooled_outputs.append(pooled)
'''torch.cat(tensor_list, dim) 把tensor_list列表中的张量在第dim维进行拼接'''
# [batch_size(=6), output_channel(=4)*3, output_height(=1), output_width(=1)]
pooled_output = torch.cat(pooled_outputs, 1) # dim = 1
# print(pooled_output.shape) # [6,4,1,12]
'''6个样本,1个样本3个卷积核,每个核4个输出通道,总共12个输出通道'''
pooled_output_flat = torch.reshape(pooled_output, [-1, self.num_filters_total]) # [6,12]
# print(pooled_output_flat.shape) # [6,12]
# [batch_size, num_classes]
"""输出层"""
output = self.Weight(pooled_output_flat) + self.Bias
# output : tensor([[1.1522, 1.2147]], grad_fn=<AddBackward0>)
return output
# num_channels, filter_sizes, vocab_size, embedding_size, sequence_length
if __name__ == '__main__':
'''本文没有用随机采样法,因此也就没有random_batch(),batch_size就等于样本数'''
embedding_size = 2 # 嵌入矩阵大小,即样本特征数,即嵌入向量的"长度"
num_classes = 2 # 情感类别数
# 卷积核宽度(即上下文词距) len(filter_sizes)即代表卷积核数量
filter_sizes = [2, 2, 2] # n-gram windows
num_channels = 4 # number of filters 卷积核输出通道数
sentences = ["i love you", "he loves me", "she likes baseball",
"i hate you", "sorry for that", "this is awful"]
labels = [1, 1, 1, 0, 0, 0] # 1 is good, 0 is not good.
'''1.数据预处理'''
word_sequence, word_list, word_dict, \
vocab_size, sentences, sequence_length = pre_process(sentences)
'''2.构建模型'''
# 构建输入输出矩阵向量
inputs = []
for sen in sentences:
inputs.append([word_dict[word] for word in sen.split()])
inputs = np.array(inputs) # (6,3)
targets = np.array(labels) # [1 1 1 0 0 0]
inputs = torch.LongTensor(inputs)
targets = torch.LongTensor(targets) # To using Torch Softmax Loss function
# 设置模型参数
model = TextCNN()
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam动量法
'''3.训练'''
# Training
for epoch in range(5000):
optimizer.zero_grad() # 把梯度置零,即把loss关于weight的导数变成0.
output = model(inputs)
# output : [batch_size, num_classes]
# targets: [batch_size,] (LongTensor, not one-hot)
loss = criterion(output, targets) # 将输出与真实目标值对比,得到损失值
loss.backward() # 将损失loss向输入侧进行反向传播,梯度累计
optimizer.step() # 根据优化器对W、b和WT、bT等参数进行更新(例如Adam和SGD)
if ((epoch+1) % 1000 == 0):
print('Epoch:%d' % (epoch+1), 'cost=%.6f' % loss)
'''4.预测'''
test_text = 'sorry hate you'
test_words = test_text.split()
tests = [np.array([word_dict[word] for word in test_words])]
tests = np.array(tests)
test_batch = torch.LongTensor(tests)
# Predict
# print(result)
# result : tensor([[1.1522, 1.2147]], grad_fn=<AddBackward0>)
'''result的两个值分别代表类别0和类别1'''
result = model(test_batch)
'''torch.tensor.data.max(dim,keepdim) 用于找概率最大的输出值及其索引
Args:
dim (int): 维度
keepdim (Boolean): 保持维度.
keepdim=True:当tensor维度>1时,得到的索引和输出值仍然保持原来的维度
keepdim=False:当tensor维度>1时,得到的索引和输出值为1维
'''
predict = result.data.max(1, keepdim=True)
predict = predict[1] # 索引
print(test_text+":%d" % predict[0][0])
# print(result.data.max(1, keepdim=True))
# print(result.data.max(1, keepdim=False))
# print(result.data.max(1, keepdim=True)[1])