1 论文简介
论文标题
Vision Transformer for Small-Size Datasets
暂时没有找到发表在哪个期刊或者会议。
只是在arxiv上公开了。
论文链接arxiv![]() https://arxiv.org/abs/2112.13492
https://arxiv.org/abs/2112.13492
论文署名单位
Inha University? ?仁荷大学? ?坐落于韩国仁川? QS: 531-540
论文代码链接
 https://github.com/aanna0701/SPT_LSA_ViT
https://github.com/aanna0701/SPT_LSA_ViT2 摘要Abstract
近年来,ViT模型将Transformer运用到图像分类任务中取得了超越卷积神经网络的效果。
但是ViT模型的优越表现依赖于大规模数据集上的预训练(例如在数据集JFT-300M上训练)。这种依赖被归因于较低的局部归纳偏移(low locality inuctive bias)。
本文提出了SPT(Shifted Patch Tokenization)和LSA(Locality Self-Attention)去解决这个问题,使得ViT模型能够在小数据集上从零开始训练。另外这两个模块是通用的,可以很容易的加到不同的ViT变种模型中去。
实验显示,加入了SPT和LSA后,ViT模型在Tiny-ImageNet数据集(代表性的小数据集)上的表现平均上升了2.96%。特别是SwinTransformer可以收获4.08%的精度上升。
3 总结Conclusion
为了能够在小数据集上使用ViT模型,本文提出了两个新的技术去提升模型的局部归纳偏置。
首先,使用SPT通过特定的转换给visual tokens嵌入丰富的空间信息。
第二,LSA通过带可学习参数的softmax给ViT引入局部性。
SPT和LSA单独使用都能给ViT模型带来提升,并且有着很大的兼容性。
4 论文思路
4.1 较低的局部归纳偏置Low Local Indective Bias
ViT模型在将图片变成词向量的过程中,感受野受限于划分patch时的卷积的卷积核大小。因此出现了本节标题中的问题。
以下等式代表视觉词向量visual tokens的感受野的计算
k是划分patch时的kernel size,j是stride,是词向量的感受野,
是transformer layer的感受野大小。
参考论文:?Computing receptive fields of convolutional neural networks
在词向量化后,transformer layer的操作并不影响感受野,因此,最后词向量的感受野就是kernel size,即patch size(ViT中划分patch的卷积的卷积核大小等于patch size)。
输入是[3, 224, 224]时,patch size是16,则普通ViT模型中词向量的感受野是16,而ResNet50是483(根据上面的参考论文)。两者相差了30倍,作者认为较小的感受野导致了低局部归纳偏置(具体代表什么有待进一步探究)。
解决办法:提出了SPT(Shifted Patch Tokenization)
4.2 标准ViT中自注意力分数的分布倾向于平滑
attention of standard ViT tend to be similar to each other regardless of relations.
输入x? ? [B, N+1, embed_dim]? ?N是patch的数量。
Q ? [B, N+1, embed_dim],? ?K ? [B, N+1, embed_dim],? ?V ? [B, N+1, embed_dim]
相似矩阵similarity matrix R
? ?[B, N+1, N+1]
注意力分数attention score
? ?[B, N+1, embed_dim]
- 在得到Q和K时,是通过不同的Linear 层从同样的输入x映射得来,Q和K倾向于拥有相似的大小。而R矩阵通过Q和K计算得到,因此R矩阵中token与自己的关系的值通常总是大于token之间的关系的值。进一步,在softmax输出的值中也会出现这种情况。
- 为了防止梯度消失,R矩阵会除以root(d_k),在root(d_k)的值较大时(softmax的温度大,参考链接),输出的注意力分数的分布会倾向于平滑
根据实验显示,输出的注意力分数趋于平滑会导致ViT模型的表现下降。
解决办法: 提出了LSA(Locality Self-Attention)
5 方法Method
5.1 SPT, Shifted Patch Tokenization
每个输入的图像都会经过平移策略S的处理,S会将图像向着四个方向(左上、右上、左下、右下)移动patch_size/2的距离。也可以使用其他不同的策略S。
移动后的图像会裁剪到输入图像的尺寸,然后与输入图像拼接起来。
然后拼接得到的特征会被划分为patch并且展平。
最后经过LayerNorn和Linear映射得到词向量tokens。
P代表划分Patch,代表根据策略S平移处理得到的第i个图像,
代表Linear映射的参数。
SPT的使用分为图像到词向量的转换、词向量变化为特征图然后下采样两种情况。
5.2?Locality SelfAttention Mechanism
LSA的核心技术包含对角线掩藏(Diagonal Masking)和可学习的温度放缩系数(learnable temperature scaling)。
5.2.1?Diagonal Masking
对角线掩藏的作用:在softmax操作中将tokens与自己之间的关系排除在外,从而增大tokens之间的关系的分数。
在之前介绍到的R矩阵中(4.2节),对角线的元素是tokens与自己的关系的分数,其他的元素是tokens之间的关系的分数。
在对角线掩藏的操作中,会强制将R矩阵的对角线元素赋值为负无穷。
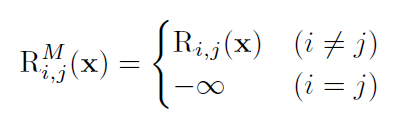
?5.2.2?学习的温度放缩系数 learnable temperature scaling
可学习的温度放缩系数的作用:允许ViT模型在训练的过程中根据情况觉得softmax的温度放缩系数。
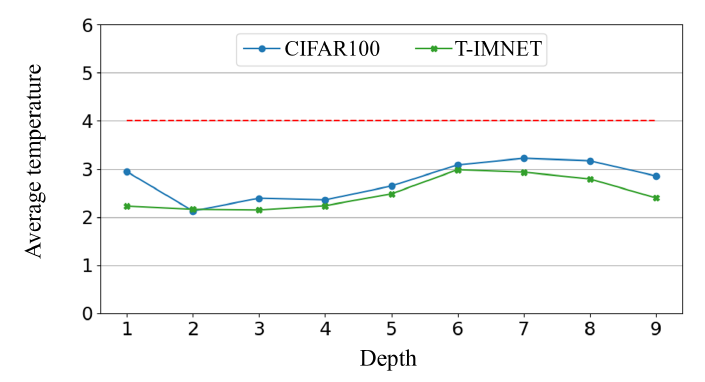
红色的虚线是以前使用的恒定值的温度放缩系数;其他的曲线是学习出来的温度系数与深度的关系(我猜测深度指softmax所在的transformer block所在的深度)。可以看到学习出来的基本低于设定的恒定值。
更低的温度系数使得自注意力分数的分布更加尖锐,不那么平滑。
5.2.3 结合了这两项技术的LSA
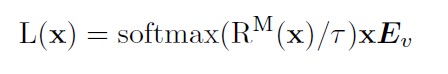
?是带对角线掩藏操作的R矩阵,
是可学习的温度系数。
LSA解决了自注意力分数的分布平滑的问题。
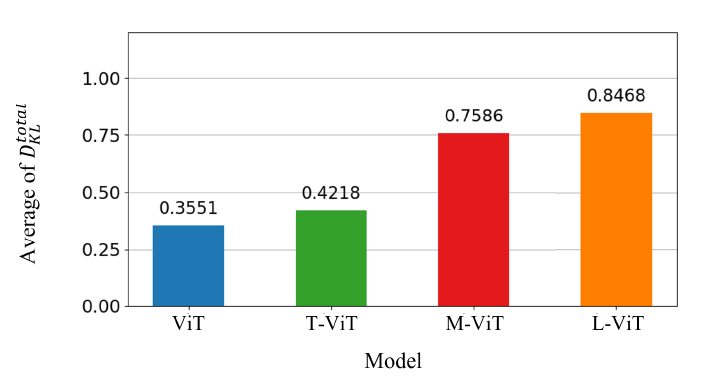
上面的图是自注意力分数的分布的KL散度与模型的关系。T-ViT是只带可学习的温度系数技术的ViT,M-ViT是只带对角线掩藏操作的技术,L-ViT是两个技术都有的模型。
KL散度越大,分布越尖锐。
6 实验
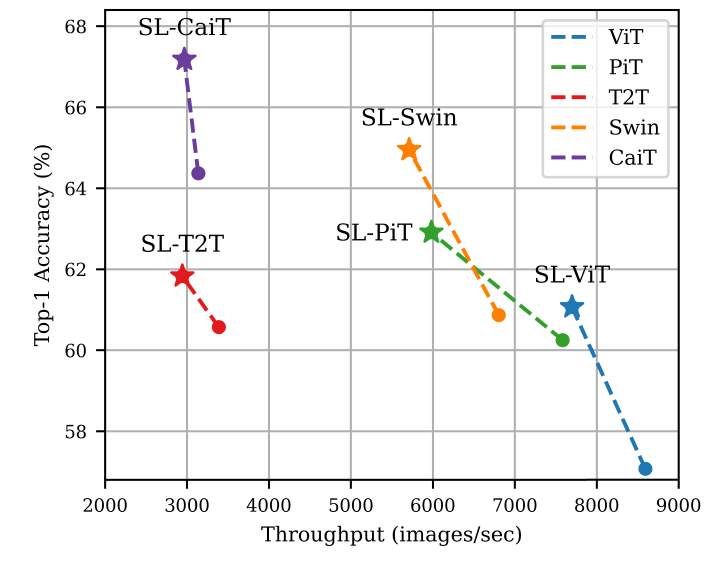

带SL-的模型是加入了本文的SPT和LSA模块的模型。 S_pool代表应用了SPT到池化层中。