由于信息在现实世界中以各种形式存在,多模态信息之间的有效交互和融合对于计算机视觉和深度学习研究中多模态数据的创建和感知起着关键作用。
近期 OpenAI 发布的 DALLE-2 和谷歌发布的 Imagen 等实现了令人惊叹的文字到图像的生成效果,引发了广泛关注并且衍生出了很多有趣的应用。而文字到图像的生成属于多模态图像合成与编辑领域的一个典型任务。多模态图像合成和编辑在建模多模态信息之间的交互方面具有强大的能力,近年来已成为一个热门的研究课题。
本篇文章是阅读Multimodal Image Synthesis and Editing: A Survey的精读笔记,论文发表于2021年12月,是一篇值得一读的综述。
论文地址:https://arxiv.org/abs/2112.13592v1
项目地址:https://github.com/fnzhan/MISE.
一、介绍
人类能够自然而然地能根据文本或音频描述对场景进行成像。然而,对于计算机而言,因为视觉线索和真实图像之间的模态内间隙和非视觉线索和实际图像之间的跨模态间隙,人工智能存在视觉感知上的模态隔阂。从不同模式的数据中有效地检索和融合异构信息仍然是图像合成和编辑中的一大挑战。
多模态图像合成和编辑(MISE)的任务旨在模拟现实世界中的人类想象力和创造力,为深入了解神经网络如何将多模态信息与图像属性相关联提供了深刻的见解。图像合成和编辑旨在创建真实图像或编辑具有自然纹理的真实图像。
二、跨模态引导
信息的每一种来源或形式都可以称为一种模态。例如,人们有触觉、听觉、视觉和嗅觉;信息媒介包括语音、视频、文本等,以及由各种传感器(例如雷达、红外和加速度计)记录的数据。上述每个数据形式都可以称为一种模态(或模式)。在图像合成和编辑方面,我们将引导模态分为视觉引导、文本引导、音频引导和其他模态。以下小节将详细描述每种模态以及相关处理方法。
2.1、视觉引导
视觉引导包括从一些视觉线索如分割图、关键点、渲染几何、边缘图、场景布局图、鼠标轨迹、光线图等等视觉引导生成真实图像,因为视觉线索可以被视为某种类型的图像,其允许使用卷积层直接编码以产生目标生成或编辑。由于视觉信息中的精确和清晰引导,视觉引导可以与图像合成中的真实图像配对或不配对。

通过编辑视觉引导,例如语义图,图像合成方法可以直接适用于图像操作任务。此外,视觉引导的图像合成和编辑可以应用于许多低级视觉任务。例如,我们可以通过将灰度图像作为视觉引导,将相应的彩色图像作为基本事实来实现图像着色,还可以应用于图像超分辨率、图像去雾、图像去雨等等领域
2.2、文本引导
与视觉引导(如边缘和对象遮罩)相比,文本引导提供了一种更灵活的方式来表达视觉概念。文本到图像合成任务旨在生成清晰、照片逼真的图像,与相应的文本指南具有高度语义相关性。这项任务非常具有挑战性,因为文本描述通常是模糊的,并且可能导致大量具有正确语义的图像。
此外,图像和文本具有异构特征,这使得很难学习跨两种模式的精确和可靠映射。因此,学习文本描述的精确嵌入在文本引导的图像合成和编辑中起着重要作用。
用文本引导合成和编辑图像首先需要从文本表示中学习有用的编码,传统文本编码器有Word2Vec、Bag-of-Words,随着深度神经网络的普及,Reed等人提出使用字符级卷积递归神经网络(char-CNN-RNN)随着自然语言处理领域中预训练模型的发展,一些研究[81]、[82]也探索了利用大规模预训练语言模型(如BERT)进行文本编码。
最近,对比语言图像预训练(CLIP)通过从大量图像和文本对中学习图像和相应字幕的对齐,实现了SOTA。如图所示,CLIP联合优化了文本编码器和图像编码器,以最大化正对之间的余弦相似度,并最小化负对的余弦相似性,从而产生信息性文本嵌入:

2.3、音频引导
Harwath等人探索从自然图像和描述图像的相应语音波形中学习神经网络嵌入。学习模型允许执行跨语言语音检索。声音不仅可以与视觉内容交互,还可以捕获丰富的语义信息。例如,通过转移来自其他预训练场景和对象识别模型的知识,SoundNet(声音识别的深度模型)可以学习仅使用听觉内容来识别场景和对象。
对应音频编码器可以从给定视频生成音频序列,其中采用深度卷积网络从视频截图中提取特征,然后使用LSTM生成相应输入视频的音频波形。输入音频段也可以由一系列特征来表示,这些特征可以是频谱图、FBANK和mel频率倒谱系数(MFCC),以及预训练音网模型的隐藏层输出。对于面部生成,还广泛采用动作单元(AU)来将驱动音频转换为用于面部生成的相干视觉信号。
2.4、其他引导
场景图:场景图将场景表示为有向图,其中节点是对象,边给出对象之间的关系。基于场景图的图像生成允许推理显式对象关系并合成具有复杂场景关系的真实图像。引导的场景图可以通过图卷积网络编码,该图卷积网预测对象边界框以产生场景布局。为了推导每个单独的主谓宾语关系,Vo等人建议进一步预测对象之间的关系单位,通过卷积LSTM将其转换为视觉布局。
三、多模态图像合成和编辑方法
多模态图像合成和编辑(MISE)的方法大致分为五类:基于GAN的方法(3.1)、自回归方法(3.2)、基于扩散的方法(3.3)、基于神经网络的方法(3.4)和其他方法(3.5)。
3.1、基于GAN的方法
基于GAN的方法已被广泛用于各种MISE任务,通过开发具有特定多模态输入的条件GAN或反转无条件GAN以产生目标潜在代码。一般将基于GAN的方法分为三类,包括具有模态内条件的方法、具有跨模态条件的方法和GAN反演方法。
3.1.1、具有模态内条件的方法
模态内引导为图像合成和编辑提供了某些视觉线索(如场景图、分割图、边缘图等),他们是很强的引导条件,可以无需配对训练数据就可以实现合成和编辑。可以将具有模态内条件的方法分为具有配对数据的方法和具有非配对数据的。其中:
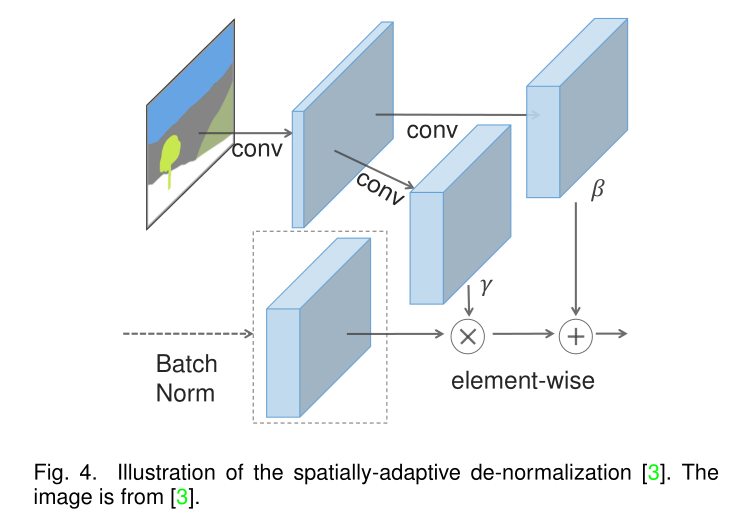
- 配对数据:配对数据所提供的引导伴随着相应的真实图像,以提供一定的直接监督。Isola等人首先研究了条件GAN,将其作为一个称为Pix2Pix的通用框架,用于各种图像翻译任务(例如,从边缘到图像、从白天到夜晚以及从语义到图像)。为了缓解Pix2Pix中高分辨率图像合成的限制,Wang等人提出了Pix2PixHD,允许合成2048×1024的图像。然而,当存在非常不同的视图或严重变形时,Pix2Pix及其变体无法编码制导和真实图像之间的复杂场景结构关系。另一方面,以前的方法直接用深度网络对视觉引导进行编码,以便进一步生成,这是次优的,因为引导信息的一部分往往在归一化层中丢失。SPADE被设计为通过如下图所示的空间自适应归一化从而有效地注入引导特征。SEAN引入了语义区域自适应归一化层,以实现区域风格注入。Shaham等人提出了ASAPNet用于翻译高分辨率图像的轻量级但高效的网络,Zhang等人和Zhan等人引入了基于示例的图像翻译框架,该框架在示例和条件输入之间建立了密集的对应关系,以提供准确的指导。Zhou等人建议利用GRU协助的补丁匹配以高效地建立高分辨率的通信。Zhan等人引入了一种双层对齐方案,以降低内存成本,同时建立密集的对应关系。
 2. 非配对数据:非配对图像合成利用非配对训练图像将图像从一个域转换到另一个域。Zhu等人设计了一个循环一致性损失,以通过确保输入图像可以从翻译结果中恢复来保存图像内容。然而,循环阻抗损失对于图像翻译来说限制太大,因为它假设两个域之间的双射关系。Park等人提出通过噪声对比估计最大化正对的互信息,以保存未配对图像翻译中的内容。Andonian等人引入对比学习来测量未配对图像翻译中的图像间相似度。然而,异构域通常具有映射,其中一个域中的单个图像在映射后可能与其在另一个域的表示不共享任何特征。因此,TravelGAN提出将域内向量变换保存在由连体网络学习的潜在空间中,学习跨异构域的映射。
2. 非配对数据:非配对图像合成利用非配对训练图像将图像从一个域转换到另一个域。Zhu等人设计了一个循环一致性损失,以通过确保输入图像可以从翻译结果中恢复来保存图像内容。然而,循环阻抗损失对于图像翻译来说限制太大,因为它假设两个域之间的双射关系。Park等人提出通过噪声对比估计最大化正对的互信息,以保存未配对图像翻译中的内容。Andonian等人引入对比学习来测量未配对图像翻译中的图像间相似度。然而,异构域通常具有映射,其中一个域中的单个图像在映射后可能与其在另一个域的表示不共享任何特征。因此,TravelGAN提出将域内向量变换保存在由连体网络学习的潜在空间中,学习跨异构域的映射。
3.1.2、跨模态条件引导的方法
典型的基于GAN的跨模态合成任务有:文本到图像合成和音频驱动的图像编辑。
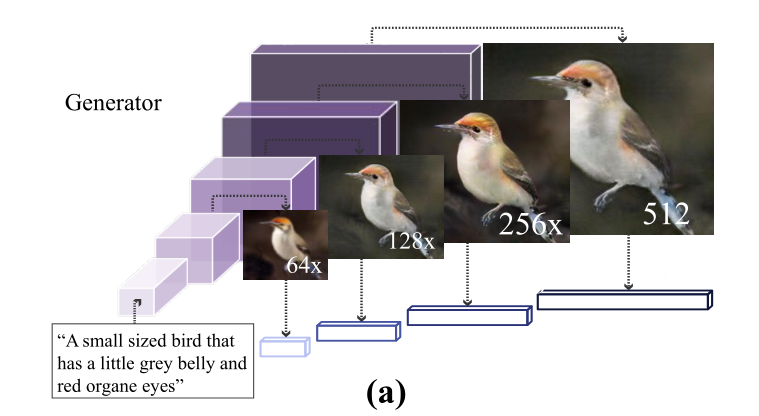
- 文本生成图像:文本到图像合成旨在生成能够准确反映文本描述语义的图像。Reed等人是第一个扩展条件GAN以实现文本到图像合成的人。由于GANs在图像合成方面的进步,该任务在采用堆叠架构、循环一致性和注意力机制方面取得了重大进展。如堆叠结构:StackGAN、StackGAN++、HDGAN;循环一致性:PPGN、CycleGAN、MirrorGAN;注意力机制:AttnGAN、SEGAN、ControlGAN、RiFeGAN;这也是我正在研究的领域,感兴趣可以深入查看专栏:文本生成图像专栏
- 音频驱动的图像编辑:由于其在实际应用中的价值,当前的音频驱动图像编辑方法侧重于说话面部生成音频驱动的说话面部生成的任务旨在合成说出给定音频剪辑的说话面部,这在数字面部动画、电影制作、视频配音等方面具有广泛的应用。音频驱动的谈话面部生成的一个基本挑战是如何将音频内容准确地转换为视觉信息。利用生成性对抗模型,Chung等人学习原始音频和视频数据的联合嵌入,并使用解码器将其投影到图像平面,以生成说话人脸;Zhou等人提出了一种DA-VS,它学习一种解纠缠的视听表示,这有助于提高合成的说话人脸的质量。Song等人介绍了一种条件RNN网络,用于对抗性地生成对话人脸。Chen等人设计了一种分层结构,将音频剪辑映射到面部地标中,进一步利用这些地标来生成会说话的面部。Zhou等人介绍了MakeItTalk,它从语音内容中预测说话人感知的面部标志,以更好地保留说话人的特征。,Yi等人提出将音频内容映射到3DMM参数,用于引导姿势可控的生成谈话面部;Zhou等人提出了一种PC-AVS,它通过学习姿势、身份和语音内容的分离特征空间来实现姿势可控的谈话面部生成。
3.1.3、GAN的逆映射
利用预先训练的GAN模型,一系列研究探索将给定图像反转回GAN的潜在空间,这被称为GAN逆映射。GAN逆映射将图像映射回潜在空间,通过将潜空间馈入预训练的GAN以通过优化重建图像来实现。在多模态图像合成和编辑方面,基于GAN逆映射方法的关键在于如何根据相应的指南编辑或生成潜在代码,且基于反演的方法往往对模态不太敏感,因为反演是在非结构化一维潜在空间上进行的。
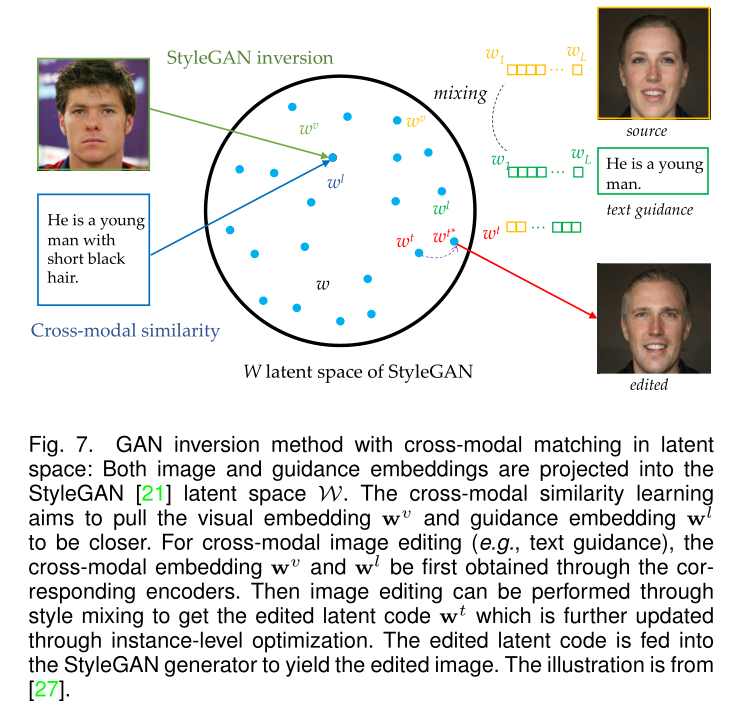
潜在空间里的跨模态匹配:多模态图像合成和编辑可以通过在公共嵌入空间中匹配图像嵌入和跨模态输入(例如,语义图、文本)来实现,具体而言,跨模态编码器被训练以学习具有视觉语言相似性损失和成对排序损失的嵌入。为了在编辑后保持身份,可以在目标中使用实例级优化模块,该模块允许根据文本描述修改目标属性。由于在StyleGAN潜空间中执行优化,该框架固有地允许从给定的多模态条件生成图像。条件图像操作也可以通过共享潜在空间中的样式混合来执行。
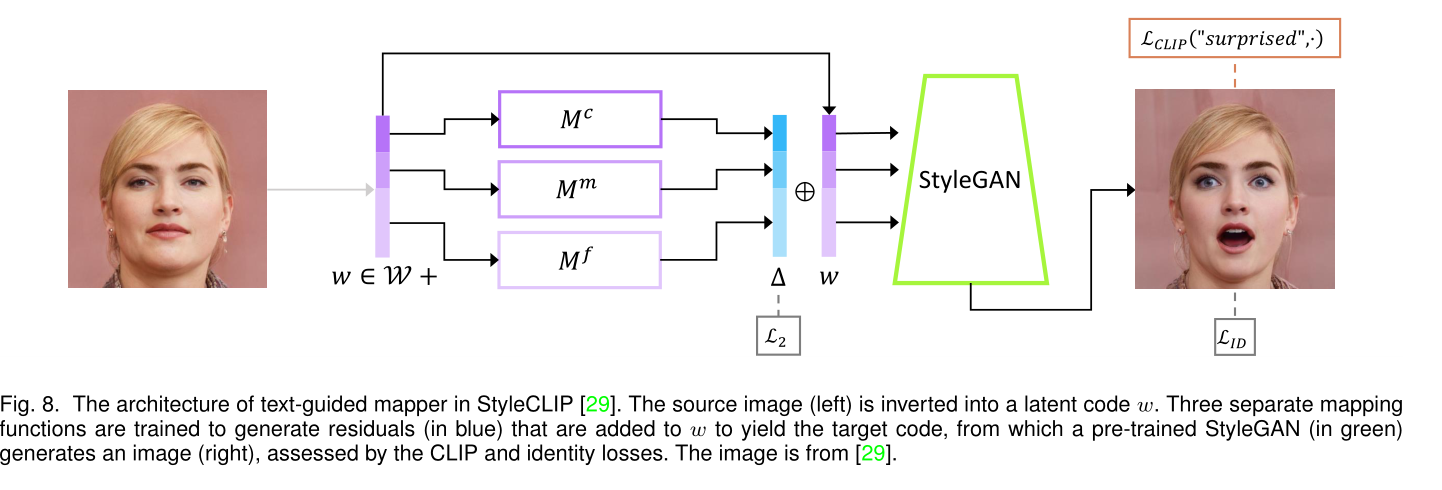
潜在空间中的图像编码优化:与将文本映射到潜在空间不同,一个流行的研究路线旨在直接优化原始图像的潜在代码,并以测量跨模态一致性的某些损失为指导。部分研究使用对比语言图像预训练(CLIP)来指导文本到图像合成的逆映射过程,而不是使用特定的属性预测器。针对文本引导的图像修复,Bau等人定义了基于剪辑的语义一致性损失,该剪辑优化了修复区域内的潜在代码,以实现与给定文本的语义一致。StyleClip和StyleMC使用预训练的剪辑作为丢失监督,以将操纵结果与文本条件匹配,如图所示。通过引入用于反事实图像操纵的基于剪辑的对比丢失、用于稳健性标准剪辑分数的AugCLIP分数,过参数化策略,以在潜在空间中导航优化。
3.2、自回归方法
Transformer模型利用其强大的注意力机制已成为序列相关建模的范例,受GPT模型在自然语言建模中的成功启发,图像GPT(iGPT)通过将展平图像序列视为离散标记,采用Transformer进行自回归图像生成。生成图像的合理性表明,Transformer模型能够模拟像素和高级属性(纹理、语义和比例)之间的空间关系。
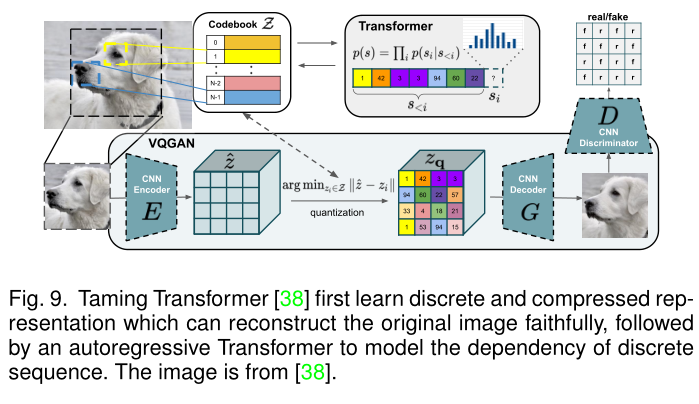
由于Transformer模型固有地支持多模态输入,所以很多研究也在探索基于变压器的自回归模型的多模态图像合成。基于Transformer的图像合成的流程包括实现离散表示和数据维度压缩的矢量量化过程,以及以光栅扫描顺序建立离散标记之间相关性的自回归建模过程。
3.2.1、图像矢量量化
使用Transformer直接将所有图像像素作为序列进行自回归建模在内存消耗方面是极为高的,因为自注意力机制在Transformer里产生了二次内存成本。因此,图像的压缩和离散表示对于基于变换器的图像合成和编辑至关重要。
Chen等人采用调色板将维数降低到512,同时保留原始图像的主要结构,然而,k均值聚类仅减少了码本维数的大小,但序列长度仍然不变。为此,矢量量化VAE(VQ-VAE)被广泛用于学习图像的离散和压缩表示。为了学习优秀的离散和压缩图像表示,在损失设计、网络结构和正则化方面,已经做出了一系列努力来改进VQ-VAE:
- 损失函数设计:为了实现重建图像的良好感知质量,Esser等人提出了一种VQGAN,该VQGAN结合了基于补丁的鉴别器的对抗性损失和用于图像重建的感知损失,Dong等人利用自监督网络用于学习深度视觉特征,以在dVAE训练期间增强感知相似性。由于额外的对抗性损失和感知损失,与图像重建中的原始像素损失相比,图像质量明显提高。Gafni等人在预训练人脸嵌入网络的激活过程中采用了矢量量化特征匹配损失;
- 网络架构:Yu等人提出了ViT VQGAN,用视觉变换器(ViT)代替CNN编码器和解码器。给定足够的数据(其中未标记的图像数据非常丰富),ViT VQGAN被证明不受卷积施加的归纳先验的约束,并且能够以更高的重建质量产生更好的计算效率。ViT VQGAN还提出了一种因式分解代码架构,该架构引入了从编码器输出到低维潜在变量空间的线性投影,用于代码索引查找,并大大提高了码本使用率。此外,NUWA-LIP探索了一种多视角编码,通过同时包含低级像素和高级标记来增强视觉信息;DiVAE采用基于扩散的解码器学习具有卓越图像重建性能的离散图像表示;
- 正则化:Shin等人验证了vanilla VQ-VAE在量化过程中不满足平移等变,导致文本到图像生成性能下降。因此,提出了一种简单但有效的TE-VQGAN,通过正则化码本嵌入中的正交性来实现平移等变。为了在多个域中实现条件图像生成的联合量化,Zhan等人设计了具有变分正则化子的集成量化VAE(IQ-VAE),以正则化跨域空间中的特征量化
3.2.2、自回归模型
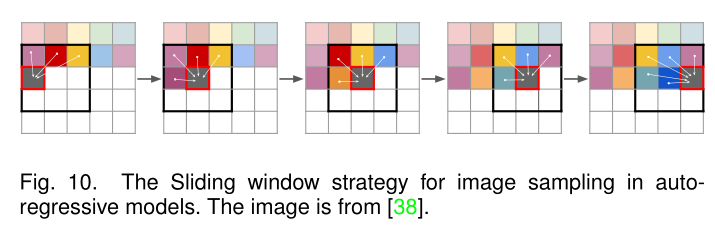
- 滑动窗口采样:为了加速自回归图像生成,Esser等人采用滑动窗口策略从图所示的训练变压器模型中进行采样。滑动窗口策略仅利用局部窗口内的预测,而不是利用所有先前预测来估计当前结果,这显著减少了推断时间。只要空间条件信息可用或数据集统计数据近似空间不变,滑动窗口中的局部上下文就足以对图像序列进行建模;
- 双向上下文:以前的方法通过只关注上一代结果,将图像上下文合并到光栅扫描顺序中,它的策略是单向的,忽略了大量上下文信息,存在顺序偏差。它还忽略了不同尺度下的许多上下文信息,因为它只在单个尺度上处理图像。基于上述观察,ImageBART在统一框架中提出了一种从粗到精的方法,解决了自回归建模的单向偏差和相应的曝光偏差。对于图像的压缩上下文信息,应用扩散过程以连续消除信息,产生表示的层次结构,其通过多项式扩散过程进一步压缩,通过对马尔可夫转移自回归建模,并注意到前面的分层状态,可以为每个单独的自回归步骤利用关键的全局上下文。作为替代方案,还广泛探索了双向变换器,以结合双向上下文,并伴有掩蔽视觉令牌建模(MVTM)或掩蔽语言建模(MLM)机制;
- 更好的自注意力机制:为了以统一的方式处理不同任务中的语言、图像和视频,NUWA提出了一种具有统一的3D邻近自我注意力(3DNA)的3D转换器框架,该框架不仅降低了全注意力的复杂性,而且显示了优越的性能;
- 模型架构:为了探索自回归文本图像合成的局限性,Parti将Transformer的参数大小缩放至20B,并观察到图像质量和文本图像对齐方面的一致质量改进。Huang等人不是从文本到图像的单向建模,而是第一个提出了一种具有Transformer的双向图像和文本框架,该框架可生成多个不同的字幕和图像。
3.3、扩散模型
去噪扩散概率模型(DDPM)是一种潜在变量模型,包括正向扩散过程和反向扩散过程。
3.3.1、条件扩散模型
为了启动多模态图像合成和编辑(MISE)任务,可以通过将条件信息与噪声图像直接连接作为去噪网络的输入,自然地导出条件扩散模型。最近,一系列设计极大地推动了条件扩散模型的性能。
- 无分类器制导:分类器引导的缺点在于需要额外的分类器模型,而这会导致复杂的训练管道。最近,Ho等人通过使用无分类器引导,在没有单独训练分类器的情况下取得了令人信服的结果,无分类器引导是一种引导形式,在有和无标签的扩散模型预测之间进行插值。在这一研究范围内,GLIDE比较了文本引导图像合成扩散模型中的剪辑引导和无分类器引导,并得出结论,无分类器引导产生更好的性能,35亿参数的扩散模型在人类评估方面优于DALL-E。此外,Tang等人探讨了离散去噪扩散模型的无分类器引导采样,引入了无分类器引导的有效实现;
- 合并模型:DALL-E 2首先从文本标题生成CLIP图像嵌入,然后使用扩散解码器生成以图像嵌入为条件的图像,而不是直接限制条件嵌入,Wang等人提出通过空间自适应归一化将语义映射提供给解码器,这提高了生成图像的质量和语义一致性;Zhu通过对比学习最大化条件和生成的输出之间的互信息,从而确保条件和生成输出之间的对应关系;
- 模型架构:基于Transformer在理解文本方面的能力,Imagen在基于扩散的方法中实现了SOTA文本到图像的生成性能,并发现在仅文本语料库上预训练的通用大型语言模型(例如T5)在编码图像合成文本方面出人意料地有效。为了理解场景中的合成概念,Liu等人提出了一种基于扩散的图像合成的合成架构,该架构通过合成一组扩散模型来生成图像。观察到扩散模型的成功很大程度上是由于训练成本的大幅增加,Blattmann等人提出了一种基于检索的方法来补充扩散模型,该方法产生了较低的计算成本;
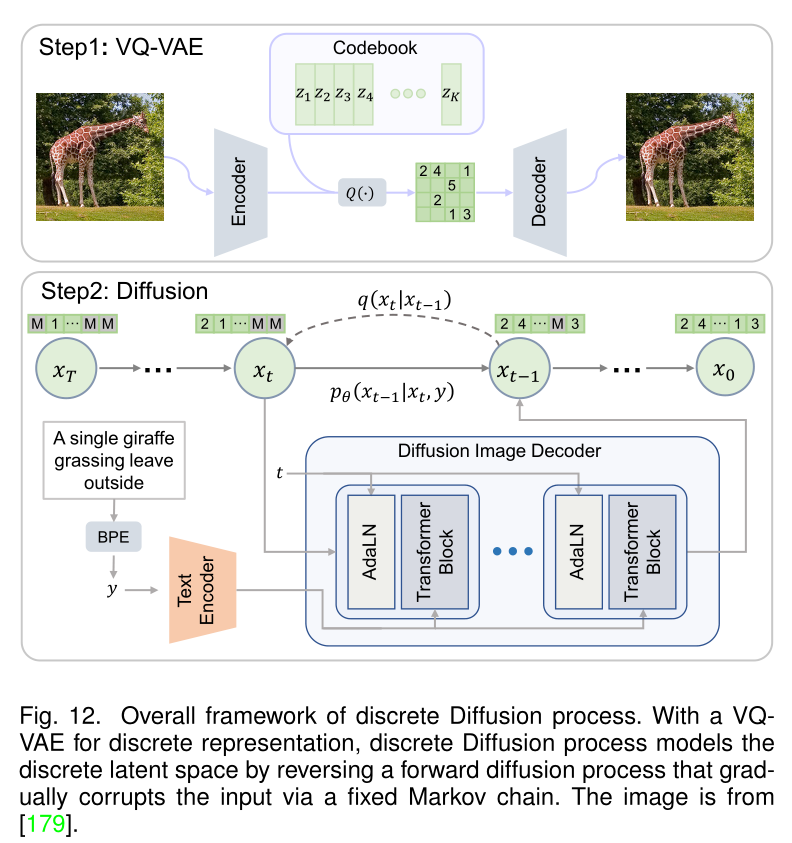
- 离散扩散:为了使扩散模型能够在有限的计算资源上进行训练,同时保持其质量和灵活性,一些工作探索在如图所示的VQ-VAE的潜在空间中进行扩散过程。通过在具有解码器吸收的量化层的VQGAN变体的潜在空间上训练扩散模型,潜在扩散模型(LDM)是第一个在复杂度降低和细节保持之间实现接近最佳点的工作,极大地提高了视觉保真度。类似地,Gu等人通过使用去噪扩散概率模型(DDPM)的条件变量学习参数模型,提出了用于文本到图像生成的矢量量化扩散(VQ扩散)模型。Tang等人通过引入高质量推理策略来缓解联合分布问题,进一步改进了VQ扩散。在VQ扩散之后,引入了Text2Human,通过使用基于扩散的Transformer对分层离散潜在空间建模,实现高质量的文本驱动的人类生成。
3.3.2、预训练扩散模型
条件扩散模型需要从头开始重新训练,这学院较高的计算成本,因此部分研究如逆映射GAN一样探索了反转预训练扩散模型以实现条件生成。Dhariwal等人使用分类器引导增强了扩散模型,该分类器引导允许从分类器标签生成条件。Kim等人提出了一种用于文本驱动的图像操纵的扩散模型DiffusionCLIP,该模型采用预训练扩散模型,使用CLIP损失来将编辑转向给定的文本提示,
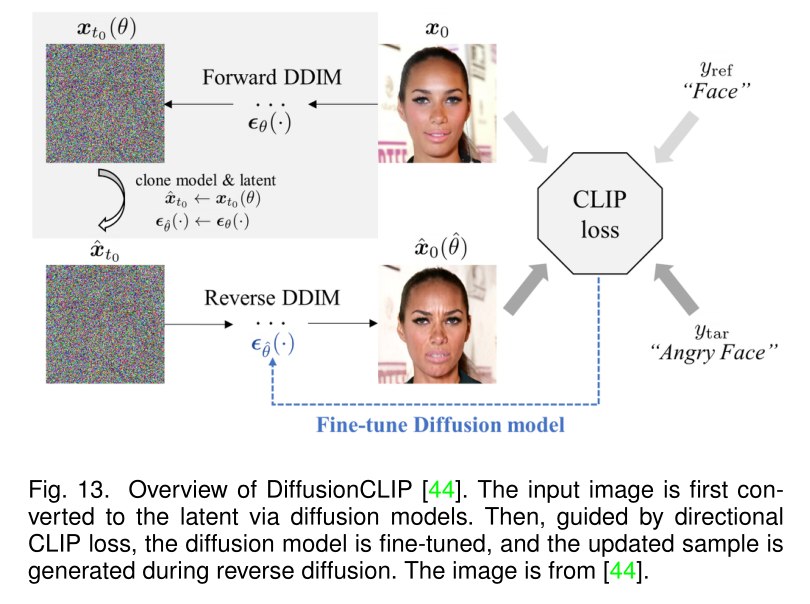
由于CLIP是在干净图像上训练的,因此在去噪扩散过程中,期望有一种从带噪潜在空间估计干净图像的方法。具体而言,Liu等人引入了无文本注释的剪辑自监督微调,以强制从干净和有噪图像中提取的特征之间对齐。阿夫拉哈米等人提出了一种在去噪扩散过程中从潜在噪声中估计干净图像的方法。然后,基于CLIP的损失可以定义为文本提示的剪辑嵌入和估计的干净图像的嵌入之间的余弦距离。此外,为了实现图像编辑的局部指导,Avrahami等人仅考虑输入掩模下的CLIP梯度。在CLIP引导扩散中提出了一种类似的估计方法,其中噪声潜在和预估的干净图像嵌入的线性组合用于为扩散提供全局指导。
3.4、基于NeRF的方法
神经辐射场(NeRF)通过使用神经网络定义隐式场景表示,实现了令人印象深刻的新视图合成性能。特别是,NeRF采用全连接神经网络,将空间位置(x,y,z)和相应的观察方向(θ,φ))作为输入,将体积密度和相应的发射辐射作为输出。为了从隐式3D表示中渲染2D图像,使用数值积分器执行可微分体积渲染,以近似难以处理的体积投影积分。然后,可以通过渲染图像和相应的地面真实图像之间的光度损失来优化NeRF。由用于3D场景表示的NeRF提供动力,可以通过使用多视图监控优化每个场景的NeRF、在单目图像上训练生成NeRF或反转预训练的生成NeRF来实现3D感知MISE。
3.4.1、 Per-scene优化NeRF
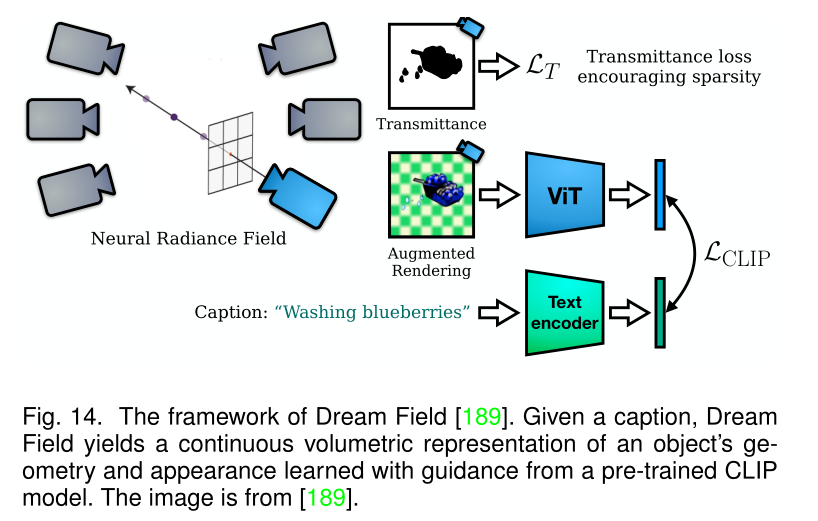
与最初的NeRF一致,许多作品关注单个场景的隐式表示。在文本驱动的3D感知图像合成中,Jain等人引入了Dream Fields,其利用预训练的图像文本模型优化神经辐射场,NeRF被优化以根据预训练的CLIP模型引入了简单的几何先验,包括稀疏诱导透射正则化、场景边界和新的MLP架构,呈现具有目标文本描述的高得分的多视图图像。
作为音频驱动图像编辑的扩展,AD NeRF通过使用一个目标人的音轨在视频序列上训练神经辐射场,实现高保真的说话人合成。与先前基于中间表示桥接音频输入和视频输出的方法不同,AD-NeRF将音频特征直接馈送到隐式函数中,以产生动态神经辐射场,进一步利用该辐射场通过体绘制合成伴随音频的高保真说话面部视频。
NeuS探索结合SDF和NeRF的优点,以实现高质量的表面重建。Hong等人将Neu作为化身的基本表示,AvatarCLIP实现用于3D化身生成和动画的零镜头文本驱动框架。利用预训练片段来监督神经人体生成,包括3D几何、纹理和动画。
3.4.2、生成性NeRF
与Per-scene优化NeRF不同的是,生成性NeRF需要场景的姿态多视图图像进行训练,RAF是第一个通过采用基于多尺度面片的鉴别器引入辐射场生成训练的对抗性框架。最近已经投入了大量的努力来改进生成NeRF,例如,GIRAFFE用于在特征级别引入体绘制并以可控的方式分离对象实例;Pi-GAN用于具有SIREN架构的基于薄膜的调节方案;StyleNeRF用于集成基于样式的生成器,以实现高分辨率图像合成;EG3D用于有效的三平面表示。
最近,Jo等人提出了一种条件生成神经辐射场(CG NeRF),它可以生成反映额外输入条件(例如图像或文本)的多视图图像,如图所示。具体而言,采用预训练剪辑模型提取条件图像和文本特征作为NeRF的输入。虽然生成的NERF可以保持视图一致性,但它们生成的图像不可本地编辑。为了克服这些限制,FENeRF提出了一种3D感知生成器,可以生成视图一致且可本地编辑的肖像图像。FENeRF使用两个解耦的潜在代码在具有共享几何结构的空间对齐的3D体积中生成相应的面部语义和纹理。得益于这种底层3D表示,Feneff可以联合渲染边界对齐的图像和语义掩模,并使用语义掩模通过GAN逆映射编辑3D体积。

3.4.3、生成器逆映射NeRF
根据3D感知图像合成生成神经网络函数的最新进展,一些工作探索了预训练生成神经网络因子的反演。伴随着旨在构建基于语义掩码的NeRF的新任务,Chen等人采用了基于编码器的反转,将语义映射映射到预训练的pi-GAN的潜在空间。
为了进一步提高逆映射的准确性,Sem2NeRF将新的区域感知学习策略集成到编码器和解码器的设计中,并使用提取的轮廓和距离场表示来增强输入语义掩码,IDE-3D针对具有形状和纹理局部控制的交互式3D感知图像编辑,提出训练3D语义感知生成模型,该模型同时生成视图一致的人脸图像和语义掩模,然后,使用两个反向编码器从语义图生成潜在代码映射,最后规范编码器,以实现规范视图中语义掩码的有效操作。
与上述基于编码器的反演不同,CLIPNeRF采用基于优化的反演,根据短文本提示实现神经辐射场的操作。在StyleCLIP中描述的基于剪辑的匹配损失的驱动下,剪辑NeRF通过使用两个代码映射器来优化潜在代码以实现目标操纵,从而桥接生成潜在空间和剪辑嵌入空间。
另一方面,由于包括了相机姿态,生成NeRF的反转仍然具有挑战性。为了实现稳定的文本引导图像编辑,StyleNeRF探索了结合基于编码器的反演和基于优化的反演,其中编码器预测相机姿态和通过逆优化进一步细化的粗样式代码。
3.5、其他方法
随着生成模型和神经渲染的发展,其他方法也实现了多模态图像合成和编辑(MISE),包括CLVA、CLIPstyler、Text2Mesh、CLIPMes等等,这里不再展开,具体请看原文。
3.6、方法比较
| 方法 | 优点 | 缺点 |
|---|---|---|
| GAN | 1、高保真的图像合成;2、快速的推理速度;3、高FID和IS分数; | 1、训练不稳定,容易模式崩塌;2、CNN架构难以以统一方式处理多模态数据 |
| 自回归模型 | 1、平稳性;2、易于扩展;3、可与扩散模型结合使用 | 推理速度慢 |
| 扩散模型 | 1、平稳性;2、易于扩展;3、建模扩散先验时优于自回归模型 | 推理速度慢 |
| 基于NeRF | 1、可以很好处理3D场景; | 1、限制较多;2、要求数据集的场景几何简单;3、需要具有摄像机姿态注释的多视图图像 |
此外,最先进的方法倾向于结合不同的生成模型以产生优异的性能。例如,Taming Transformer结合了VQ-GAN和自回归模型以实现高分辨率图像合成,StyleNeRF结合了NeRF和GAN以实现高保真度和3D感知的对抗性图像合成;ImageBart将自回归公式与多项式扩散过程相结合,以合并从粗到细的上下文信息层次;X-LXMERT将GAN集成到跨模态表示的框架中,以实现文本引导的图像生成。
四、实验部分
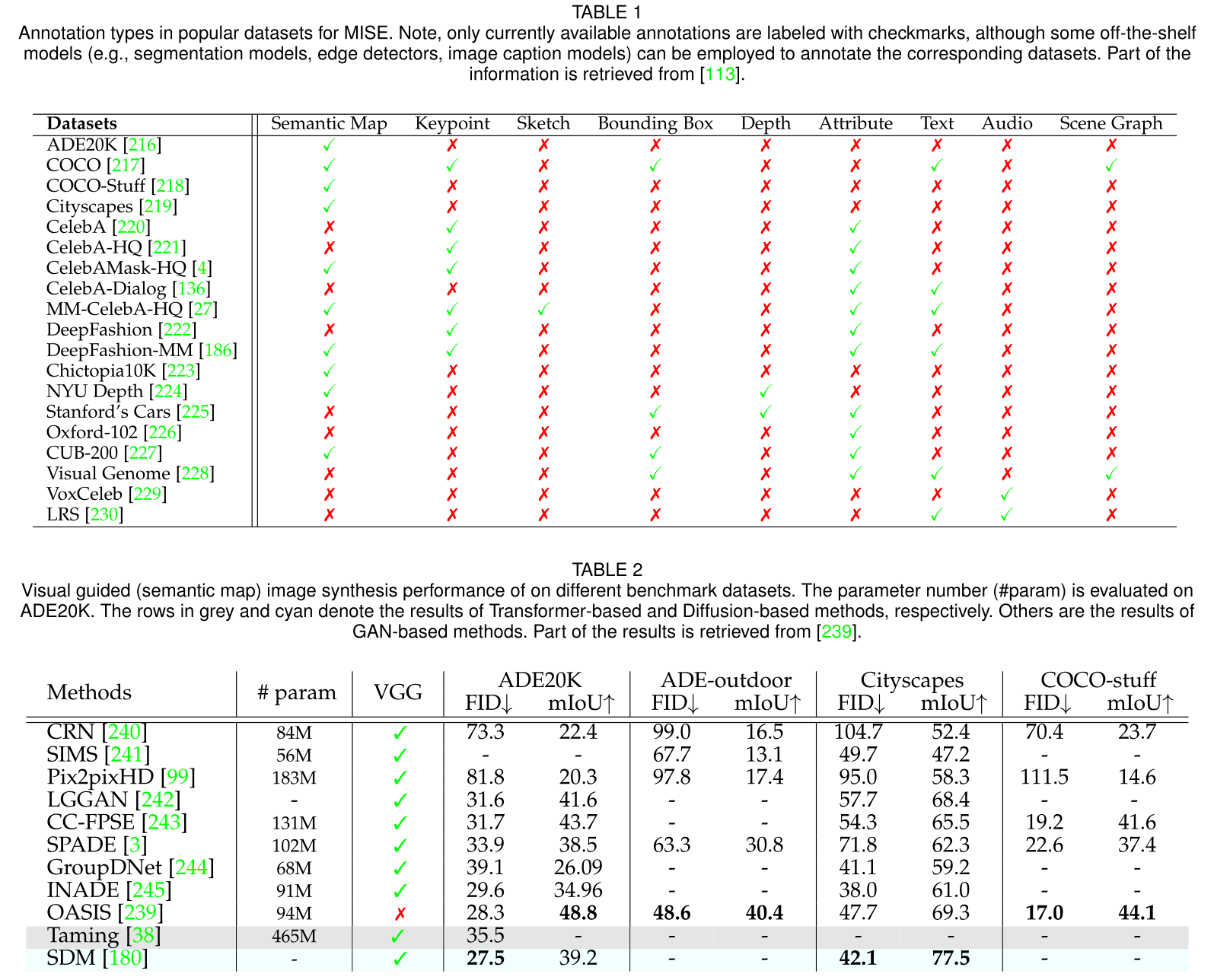
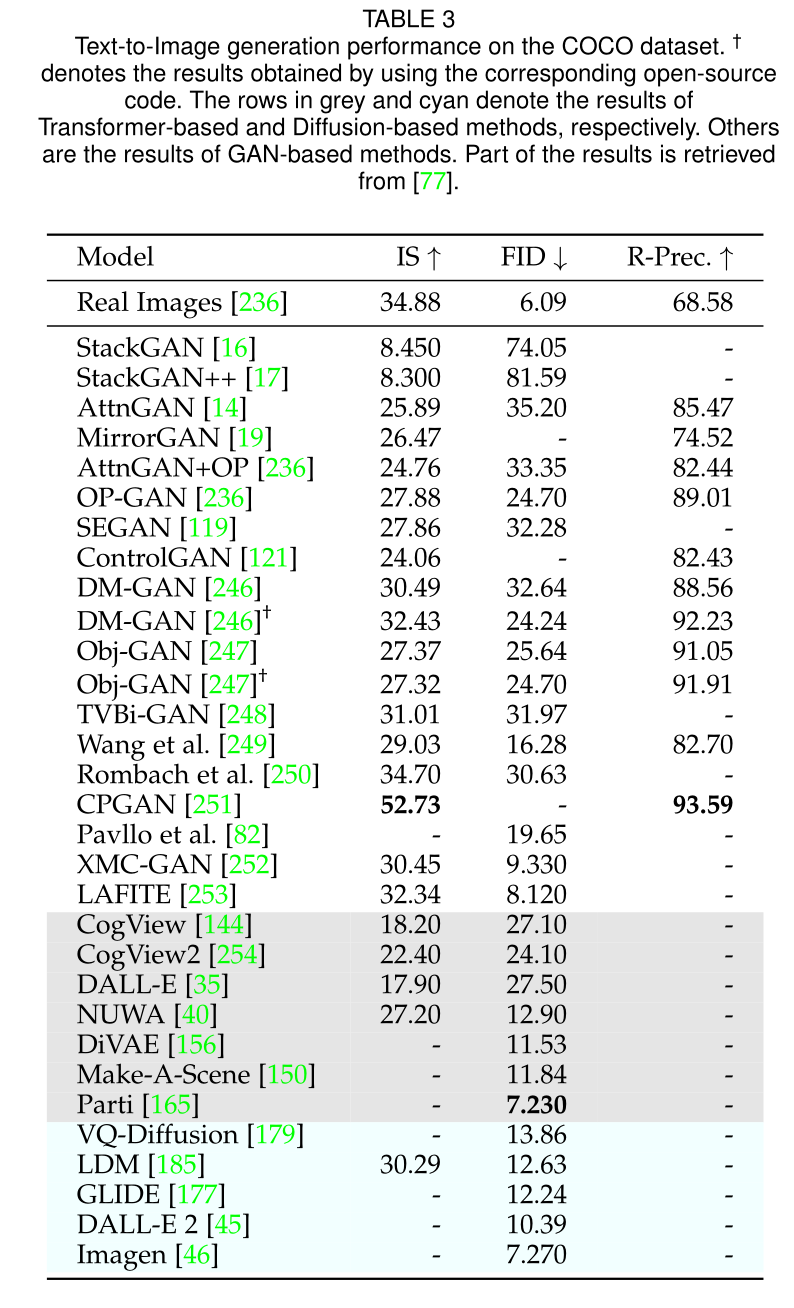
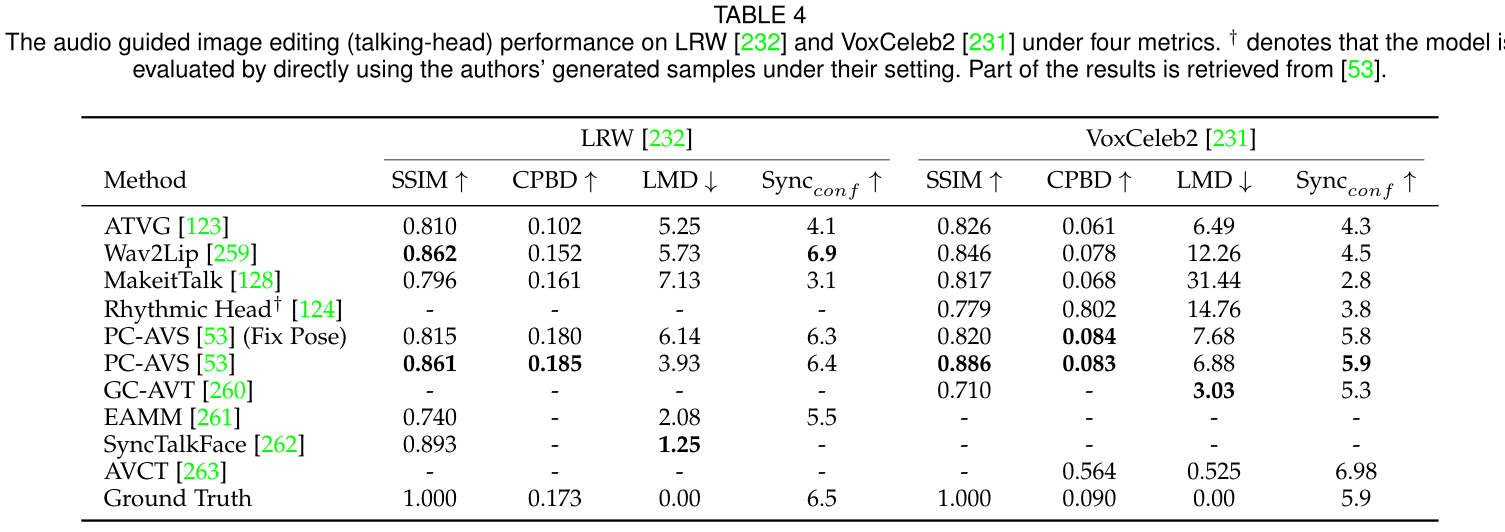
作者整理了大量的实验,具体实验请看原文,这里仅仅列出部分实验结果:
五、开放式挑战和未来探索
尽管多模态图像合成和编辑近年来取得了显著的进展,并取得了优异的性能,但仍存在一些未来探索的挑战。
6.1、面向大规模的多模态数据集
由于当前数据集主要以单一模态(例如视觉引导)提供注释,目前大多数实现MISE的模型是单一模态形式,比如文本生成图像,语义图像合成。
然而,人类拥有在多种模式的指导下同时创建视觉内容的能力。为了模拟人类智能,多模式输入有望在图像生成中同时有效融合和利用。
6.2、更可靠的评估指标
多模态图像合成和编辑的评估仍然是一个开放的问题。利用预训练模型进行评估(如FID)是对预训练数据集的约束,这往往会造成与目标数据集的差异。用户研究招募人类受试者直接评估合成图像,但这通常是主观的。因此,设计准确而忠实的评估度量对于多模态图像合成和编辑的发展非常有意义和关键。
最近,为了评估文本到图像合成中的跨模态对齐,已使用预训练CLIP来测量文本和相应生成图像之间的相似度。值得注意的是,当前在多模态学习方面的进步使跨模态一致性更为精确,这可能有助于未来开发可靠的评估指标。
6.3、高效的网络体系结构
由于对多模态输入的固有支持和强大的生成建模,基于变换器的自回归模型或扩散模型已成为统一多模态图像合成和编辑的新范式。然而,自回归模型和扩散模型都存在推理速度慢的问题,这在高分辨率图像合成中更为严重。最近的一些工作探索了加速自回归模型和扩散模型,而实验仅限于具有低分辨率的试验数据集,如CIFAR-10。如何加快自回归模型和扩散模型在实际应用中的推理速度,仍然是未来探索的重大挑战。
另一方面,基于GAN的方法具有更好的推理速度,而广泛采用的CNN架构阻碍了它对多模态输入的统一处理。最近,一些工作探索了在GANs中采用基于Transformer的架构,这可能为开发用于统一处理MISE任务的GANs提供一些见解。
6.4、面向3D
随着神经场景表示模型特别是NeRF的出现,3D感知图像合成和编辑有可能成为MISE的下一个突破点,因为它模拟了真实世界的3D几何。随着对抗性损失的加入,生成性NeRF对MISE具有显著的吸引力,因为它与潜在空间相关。
当前的生成性NeRF模型(如StyleNeRF、EG3D)能够从一组未定位的2D图像中建模具有简单几何体(如人脸、汽车)的场景,就像无条件GAN(如Stylgan)的训练一样。
在这些努力的推动下,已经探索了一些3D感知MISE任务,例如文本到NeRF和语义toNeRF。然而,当前生成的NERF仍然在具有复杂几何变化的数据集上挣扎,例如DeepFashion和ImageNet。
仅仅依靠对抗性损失来从未定位的2D图像中学习复杂的场景几何结构确实是困难和具有挑战性的。一种可能的解决方案是提供场景的更多先验知识,例如,通过现成的重建模型获得先验场景几何,为生成性人体建模提供骨架先验。
值得注意的是,在3D感知风格转换和NeRF泛化的一些近期工作中,已经探索了先验知识的力量。另一种可能的方法是提供更多的监督,例如,创建具有多视图注释或几何信息的大型数据集。一旦3D感知生成建模成功应用于复杂自然场景,一些有趣的多模态应用将成为可能,例如DALL-E的3D版本。
六、应用与影响
6.1、应用
多模态图像合成和编辑技术可应用于艺术创作和内容生成,可广泛惠及设计师、摄影师和内容创作者。此外,它们可以在日常应用中被民主化,作为流行娱乐的图像生成或编辑工具。此外,作为合成和编辑的中间表示的各种条件大大简化了方法的使用,并提高了用户交互的灵活性。总的来说,这些技术大大降低了公众的障碍,释放了他们在内容生成和编辑方面的创造力。
6.2、滥用
另一方面,不断增强的编辑能力和生成真实感也为出于恶意目的生成或操纵图像提供了机会。滥用合成和编辑技术可能传播虚假或恶意信息,并导致负面社会影响。
为了防止潜在的滥用,一种潜在的方法是开发检测用于自动识别GAN生成或伪图像的技术,该技术已被社区积极研究。同时,在部署多模态图像合成和编辑技术时,应仔细考虑足够的栅栏、标签和访问控制,以尽量减少误用风险。
6.3、环境
作为基于深度学习的方法,当前的多模型生成方法不可避免地需要GPU和大量的能量消耗用于训练和推理,这可能在大规模使用可再生能源之前对环境和全球气候产生负面影响。弱化对计算资源需求的一个方向在于积极探索模型泛化、轻量化。例如,在各种数据集中推广的预训练模型可以大大加快训练过程,或为下游任务提供语义知识。
本综述涵盖了多模态图像合成和编辑的主要方法。其概述了不同的引导模式,包括视觉引导、文本引导、音频引导和其他模式引导(如场景图)。然后详细介绍了主要的图像合成和编辑范式:基于GAN的方法、自回归方法、基于扩散的方法和基于NeRF的方法。全面讨论了相应的优势和劣势,以激发利用现有框架优势的新范式。还对基于不同指导模式的MISE数据集和评估指标进行了全面调查。然后,我们将现有方法在不同MISE任务中的性能制成表格并进行比较。最后提供了与整合所有模式、综合数据集、评估指标、模型架构和3D感知相关的当前挑战和未来方向的观点。
论文地址:https://arxiv.org/abs/2112.13592v1
项目地址:https://github.com/fnzhan/MISE.
最后
💖 个人简介:人工智能领域研究生,目前主攻文本生成图像(text to image)方向
📝 关注我:中杯可乐多加冰
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏??+留言📝