前言
上一个博客简要介绍了CNN,接下来我们用CNN搭建一个神经网络,在做图像分类问题时,之前将二维图像平铺成一维矩阵,使用MLP来解决问题,当图像不大的时候,可以实现最终的要求,但是这样做有两个弊端:一是当图像像素高的时候,这样的方法会增加模型复杂度;二是这种二向箔一样的降维会使得图像特征丢失,因此我们希望直接能够将二维矩阵作为输入,保留图像特征,将这个二维矩阵作为神经网络的一个神经元,参与到神经网络的运算中,这就引出了上个世纪风靡的卷积神经网络:LeNet,如今仍广泛应用于米国的图像识别中。
LeNet介绍
下图是LeNet的架构图,通过上文的学习,可以比较容易的理解其中意思。
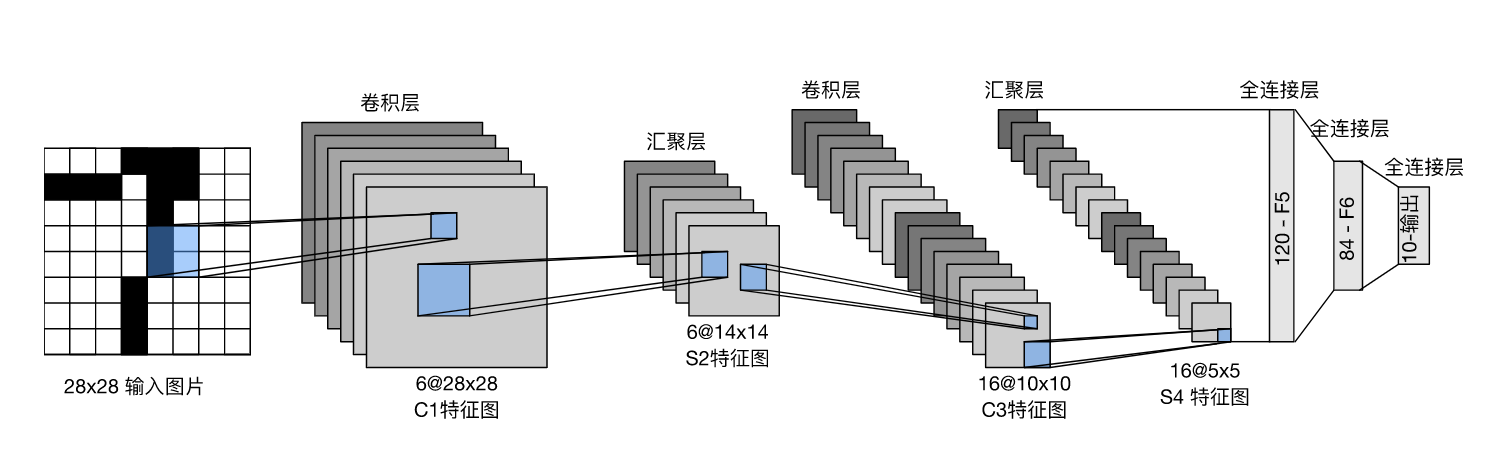
LeNet使用的是MNIST数据集,该数据集是一堆手写数字,希望通过算法将他们分成0-9十个类,下文会展示该算法在MNIST数据集上的效果。
该算法首先以28*28的图像作为二维矩阵输入,然后在卷积层中,将卷积核与图像的二维矩阵作互相关运算得到卷积层的结果,然后将该结果传入池化层,通过池化操作对卷积层的二维矩阵结果进一步缩小尺寸,然后再重复上述操作一次,可以将二维图像进一步缩小,然后将缩小后的二维图像矩阵通过平铺的方式降维,导入MLP中训练,整体就是这样一个流程,接下来通过代码来细化每一步操作。
import torch
from torch import nn
from d2l import torch as d2l
#初始图像28*28
net = nn.Sequential(
#输入1个二维矩阵图像,卷积第一层输出6个二维矩阵,这里二维矩阵可以类比MLP中的神经元
#卷积第一层类比隐藏层第一层
#padding=2,图像四周将两圈白边,相当于图像变成32*32
#kernel_size=5,卷积核5*5,这里的卷积核可以类比MLP中的权重,是一个可学习的参数
#通过与卷积核的互相关运算可以使得图像变成28*28
#Sigmoid使得该卷积神经网络非线性化
nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),
#池化层中的池化矩阵2*2,步长2,说明每次池化的图像不重叠,图像变成14*14
nn.AvgPool2d(kernel_size=2, stride=2),
#第二个卷积层&池化层,与上面类似,不再详细讲解
#第二卷积层有16个神经元输出,卷积核4*4,使得图像变成10*10
nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),
#池化2*2,步长2,使得图像变成5*5
nn.AvgPool2d(kernel_size=2, stride=2),
#二维矩阵图像降维,平铺
nn.Flatten(),
#转入MLP模型
#因为第二卷积层是16个输出通道,因此转入MLP后的一维矩阵是16*5*5作为输入
#后面就是MLP的操作了
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
#经过2个MLP隐藏层,输出10个结果类
nn.Linear(84, 10))
MNIST数据集实例展示
接下来我们运行一下当年LeNet跑的数据集
载入MNIST数据集
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
def load_data_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式
# 并除以255使得所有像素的数值均在0到1之间
trans = [transforms.ToTensor()]
#默认图像是28*28的尺寸,resize变量可以更改尺寸大小
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
#读取训练与测试数据
mnist_train = torchvision.datasets.MNIST(
root="../data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.MNIST(
root="../data", train=False, transform=trans, download=True)
#返回batch_size个训练和测试数据,shuffle变量表示是否要打乱下标,上一个blog有讲过
#打乱下标可以让每一次的迭代选取的顺序不一样,训练需要,测试一般不需要
#get_dataloader_workers表示需要几个进程来读取数据
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
def get_dataloader_workers(): #@save
"""使用4个进程来读取数据"""
return 4
batch_size = 256
train_iter, test_iter = load_data_mnist(batch_size=batch_size)
模型精度计算
之前讲到用GPU跑模型,相较于CPU,速度是有很大提升的,当然也取决于GPU的运行效率,本人用的是1050,速度也就快一倍…
这里除了计算精度外,就是将所有所需数据全部放到显存中。
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, nn.Module):
net.eval() # 设置为评估模式
if not device:
device = next(iter(net.parameters())).device
# 正确预测的数量,总预测的数量
metric = d2l.Accumulator(2)
with torch.no_grad():
for X, y in data_iter:
if isinstance(X, list):
# BERT微调所需的(之后将介绍)
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
训练函数
在之前MLP用的训练函数基础上,将神经网络放到了GPU上,损失函数用的是交叉熵损失函数。
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""用GPU训练模型(在第六章定义)"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# 训练损失之和,训练准确率之和,样本数
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
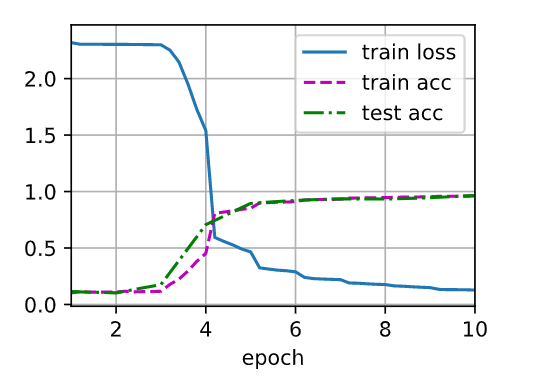
结果
可以看到精度还是挺高的,我的1050显卡每秒处理10000条数据,我的i5-7代CPU每秒5000条,提升一倍,好的GPU可以跑到60000+,深度学习需要钞能力。
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
结果:loss 0.128, train acc 0.960, test acc 0.965
10621.3 examples/sec on cuda:0
使用Fashion―MNIST实例
除了训练数据集不一样,其他操作都一样。
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
最终的精度结果在0.82,相比softmax回归可能还差点,这个模型还需要调整。
小结
LeNet卷积神经网络可以看作是CNN与MLP的一种结合,他的优点在于可以将二维图像作为模型的输入,可以避免降维带来的图像特征丢失,卷积神经网络在很多场景都可以使用,例如自然语言处理等等,使得我们的深度学习库变得更为丰富。