ECCV2022|ИлжаЮФMM LabжЄУїFrozenЕФCLIP ФЃаЭЪЧИпаЇЪгЦЕбЇЯАеп
ЁОаДдкЧАУцЁП
ЪгЦЕЪЖБ№вЛжБвдЖЫЕНЖЫбЇЯАЗЖЪНЮЊжїЁЊЁЊЪзЯШЪЙгУдЄбЕСЗЭМЯёФЃаЭЕФШЈжиГѕЪМЛЏЪгЦЕЪЖБ№ФЃаЭ,ШЛКѓЖдЪгЦЕНјааЖЫЕНЖЫбЕСЗЁЃетЪЙЪгЦЕЭјТчФмЙЛДгдЄбЕСЗЕФЭМЯёФЃаЭжаЪмвцЁЃШЛЖј,еташвЊДѓСПЕФМЦЫуКЭФкДцзЪдДРДЮЂЕїЪгЦЕ,ВЂЧвжБНгЪЙгУдЄбЕСЗЕФЭМЯёЬиеїЖјВЛЮЂЕїЭМЯёжїИЩЕФЬцДњЗНЗЈЛсЕМжТНсЙћВЛМбЁЃавдЫЕФЪЧ,Contrastive VisionLanguage Pre-training (CLIP) ЕФзюаТНјеЙЮЊЪгОѕЪЖБ№ШЮЮёЕФаТТЗОЖЦЬЦНСЫЕРТЗЁЃетаЉФЃаЭдкДѓаЭПЊЗХДЪЛуЭМЯё-ЮФБОЖдЪ§ОнЩЯНјааСЫдЄбЕСЗ,бЇЯАСЫОпгаЗсИЛгявхЕФЧПДѓЪгОѕБэЪОЁЃдкБОЮФжа,зїепЬсГіСЫИпаЇЪгЦЕбЇЯА (EVL)ЁЊЁЊвЛжжгУгкжБНгбЕСЗОпгаЖГНс CLIP ЬиеїЕФИпжЪСПЪгЦЕЪЖБ№ФЃаЭЕФгааЇПђМмЁЃОпЬхРДЫЕ,зїепВЩгУСЫвЛИіЧсСПМЖЕФ Transformer НтТыЦїВЂбЇЯАСЫвЛИіВщбЏtoken,вдДг CLIP ЭМЯёБрТыЦїЖЏЬЌЪеМЏжЁМЖПеМфЬиеїЁЃДЫЭт,зїепдкУПИіНтТыЦїВужаВЩгУОжВПЪБМфФЃПщРДЗЂЯжРДздЯрСкжЁМАЦфзЂвтСІЭМЕФЪБМфЯпЫїЁЃзїепБэУї,ОЁЙмЪЙгУЖГНсЕФжїИЩНјаабЕСЗКмгааЇ,ЕЋБОЮФЕФФЃаЭдкИїжжЪгЦЕЪЖБ№Ъ§ОнМЏЩЯбЇЯАСЫИпжЪСПЕФЪгЦЕБэЪОЁЃ
1. ТлЮФКЭДњТыЕижЗ

Frozen CLIP Models are Efficient Video Learners
ТлЮФЕижЗ:https://arxiv.org/abs/2208.03550
ДњТыЕижЗ:https://github.com/opengvlab/efficient-video-recognition
2. Motivation
зїЮЊЪгЦЕРэНтЕФЛљБОзщГЩВПЗж,бЇЯАЪБПеБэЪОНќФъРДШдШЛЪЧвЛИіЛюдОЕФбаОПСьгђЁЃздЩюЖШбЇЯАЪБДњПЊЪМвдРД,вбОЬсГіСЫаэЖрМмЙЙРДбЇЯАЪБПегявх,Р§ШчДЋЭГЕФЫЋСїЭјТч,3D ОэЛ§ЩёОЭјТчКЭЪБПеTransformerЁЃгЩгкЪгЦЕЪЧИпЮЌЕФВЂЧвБэЯжГіДѓСПЕФЪБПеШпгр,вђДЫДгЭЗбЕСЗЪгЦЕЪЖБ№ФЃаЭаЇТЪЗЧГЃЕЭ,ПЩФмЛсЕМжТадФмЯТНЕЁЃжБЙлЕиЫЕ,ЪгЦЕЦЌЖЮЕФгявхвтвхгыЦфУПИіЕЅЖРЕФжЁИпЖШЯрЙиЁЃЯШЧАЕФбаОПБэУї,ЭМЯёЪЖБ№ЕФЪ§ОнМЏКЭЗНЗЈвВПЩвдЪЙЪгЦЕЪЖБ№ЪмвцЁЃгЩгкЭМЯёКЭЪгЦЕЪЖБ№жЎМфЕФУмЧаЙиЯЕ,зїЮЊГЃЙцЪЕМљ,ДѓЖрЪ§ЯжгаЕФЪгЦЕЪЖБ№ФЃаЭЖМРћгУдЄбЕСЗЕФЭМЯёФЃаЭНјааГѕЪМЛЏ,ШЛКѓвдЖЫЕНЖЫЕФЗНЪНжиаТбЕСЗЫљгаВЮЪ§вдНјааЪгЦЕРэНтЁЃ
ШЛЖј,ЖЫЕНЖЫЮЂЕїЛњжЦгаСНИіжївЊШБЕуЁЃЪзЯШЪЧаЇТЪЁЃЪгЦЕЪЖБ№ФЃаЭашвЊЭЌЪБДІРэЖрИіжЁ,ВЂЧвдкФЃаЭДѓаЁЗНУцБШЦфЭМЯёЖдгІЮяДѓМИБЖЁЃЮЂЕїећИіЭМЯёжїИЩВЛПЩБмУтЕиЛсВњЩњОоДѓЕФМЦЫуКЭФкДцЯћКФГЩБОЁЃвђДЫ,етИіЮЪЬтЯожЦСЫдкгаЯоМЦЫузЪдДЯТгУгкЪгЦЕЪЖБ№ЕФвЛаЉзюДѓЭМЯёМмЙЙЕФВЩгУКЭПЩРЉеЙадЁЃЕкЖўИіЮЪЬтдкЧЈвЦбЇЯАЕФБГОАЯТБЛГЦЮЊджФбадвХЭќЁЃдкЖдЯТгЮЪгЦЕШЮЮёНјааЖЫЕНЖЫЮЂЕїЪБ,ШчЙћЯТгЮЪгЦЕаХЯЂСПВЛзу,ПЩФмЛсЦЦЛЕДгЭМЯёдЄбЕСЗжабЇЯАЕНЕФЧПДѓЪгОѕЬиеїВЂЛёЕУЕЭгкБъзМЕФНсЙћЁЃетСНИіЮЪЬтЖМБэУї,ДгдЄбЕСЗЕФЭМЯёФЃаЭНјааЖЫЕНЖЫЮЂЕїВЂВЛзмЪЧвЛИіРэЯыЕФбЁдё,еташвЊвЛжжИќгааЇЕФбЇЯАВпТдРДНЋжЊЪЖДгЭМЯёзЊвЦЕНЪгЦЕЁЃ
ЭЈЙ§ЖдБШбЇЯА ЁЂmaskЪгОѕНЈФЃКЭДЋЭГЕФМрЖНбЇЯА,дкбЇЯАИпжЪСПКЭЭЈгУЕФЪгОѕБэЪОЗНУцвбОзіГіСЫЯрЕБДѓЕФХЌСІЁЃMAE ЕШmaskЪгОѕНЈФЃЗНЗЈбЕСЗБрТыЦї-НтТыЦїМмЙЙвджиНЈРДздЧБдкБэЪОКЭmask tokenЕФдЪМЭМЯёЁЃЛљгкМрЖНбЇЯАЕФЗНЗЈЪЙгУвЛзщЙЬЖЈЕФдЄЖЈвхРрБ№БъЧЉбЕСЗЭМЯёжїИЩЁЃгЩгкЫќУЧЭЈГЃЪЧЕЅФЃбЕСЗЕФ,вђДЫЫќУЧЖМШБЗІБэЪОЗсИЛгявхЕФФмСІЁЃЯрБШжЎЯТ,жюШч CLIPжЎРрЕФЖдБШЪгОѕгябдФЃаЭЪЧЪЙгУДѓЙцФЃПЊЗХДЪЛуЭМЯё-ЮФБОЖдНјаадЄбЕСЗЕФЁЃЫћУЧПЩвдбЇЯАгыИќЗсИЛЕФгябдгявхЯрвЛжТЕФИќЧПДѓЕФЪгОѕБэЪОЁЃ CLIP ЕФСэвЛИігХЪЦЪЧЦфгаЧАЭОЕФЬиеїПЩЧЈвЦад,етЮЊИїжжЯТгЮШЮЮёЕФвЛЯЕСаЧЈвЦбЇЯАЗНЗЈЕьЖЈСЫМсЪЕЕФЛљДЁЁЃ
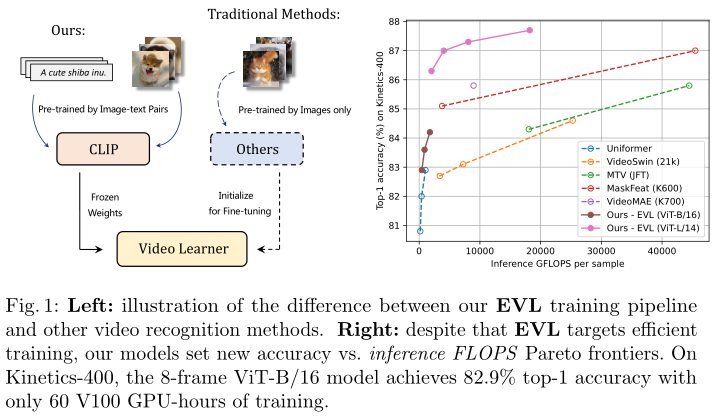
ЩЯЪідвђЦєЗЂзїепжиаТЫМПМЭМЯёКЭЪгЦЕЬиеїжЎМфЕФЙиЯЕ,ВЂЩшМЦгааЇЕФЧЈвЦбЇЯАЗНЗЈРДРћгУЖГНсЕФ CLIP ЭМЯёЬиеїНјааЪгЦЕЪЖБ№ЁЃЮЊДЫ,зїепЬсГіСЫвЛжжЛљгкЧсСПМЖ Transformer НтТыЦїЕФИпаЇЪгЦЕбЇЯА (EVL) ПђМм ЁЃ EVL гыЦфЫћЪгЦЕЪЖБ№ФЃаЭЕФЧјБ№ШчЩЯЭМзѓЫљЪОЁЃОпЬхРДЫЕ,EVL бЇЯАвЛИіВщбЏtoken,вдДг CLIP ЭМЯёБрТыЦїЕФУПвЛВуЖЏЬЌЪеМЏжЁМЖПеМфЬиеїЁЃзюживЊЕФЪЧ,зїепв§ШыСЫвЛИіОжВПЪБМфФЃПщ,дкЪБМфОэЛ§ЁЂЪБМфЮЛжУЧЖШыКЭПчжЁзЂвтСІЕФАяжњЯТЪеМЏЪБМфЯпЫїЁЃзюКѓ,ЪЙгУШЋСЌНгВуРДдЄВтЪгЦЕРрБ№ЕФЗжЪ§ЁЃзїепНјааСЫЙуЗКЕФЪЕбщРДжЄУїБОЮФЗНЗЈЕФгааЇад,ВЂЗЂЯж EVL ЪЧвЛжжМђЕЅгааЇЕФpipeline,ОпгаИќИпЕФзМШЗад,ЕЋбЕСЗКЭЭЦРэГЩБОИќЕЭ,ШчЩЯЭМгвЫљЪОЁЃБОЮФЕФЙБЯзШчЯТ:
-
жИГіСЫЕБЧАЖЫЕНЖЫЪгЦЕРэНтбЇЯАЗЖЪНЕФШБЕу,ВЂЬсГіРћгУЖГНсЕФ CLIP ЭМЯёЬиеїРДДйНјЪгЦЕЪЖБ№ШЮЮё
-
ПЊЗЂСЫ EVLЁЊЁЊвЛжжДгЭМЯёЕНЪгЦЕЪЖБ№ЕФИпаЇЧЈвЦбЇЯАpipeline,ЦфжазїепдкЙЬЖЈЕФПЩЧЈвЦЭМЯёЬиеїжЎЩЯбЕСЗСЫвЛИіЧсСПМЖЕФ Transformer НтТыЦїФЃПщ,вджДааЪБПеШкКЯЁЃ
-
ДѓСПЪЕбщжЄУїСЫ EVL ЕФгааЇадКЭаЇТЪЁЃгыЖЫЕНЖЫЮЂЕїЯрБШ,ЫќВњЩњЕФбЕСЗЪБМфвЊЖЬЕУЖр,ЕЋадФмШДОпгаОКељСІЁЃетЪЙЕУОпгаЦНОљМЦЫузЪдДЕФИќЙуЗКЩчЧјПЩвдЗУЮЪЪгЦЕЪЖБ№етИіШЮЮёЁЃ
3. ЗНЗЈ
БОЮФЕФЭМЯёЕНЪгЦЕЧЈвЦбЇЯАpipelineЕФШ§ИіжївЊФПБъЪЧ(1)змНсЖржЁЬиеїКЭЭЦЖЯЪгЦЕМЖдЄВтЕФФмСІ; (2) ПчЖрИіжЁВЖЛёдЫЖЏаХЯЂЕФФмСІ; (3) аЇТЪЁЃвђДЫ,зїепЬсГіСЫИпаЇЪгЦЕбЇЯА (EVL) ПђМм,НЋдкЯТУцЯъЯИНщЩмЁЃ
3.1 Overall Structure

ШчЩЯЭМЫљЪО,EVL ЕФећЬхНсЙЙЪЧЙЬЖЈ CLIP жїИЩжЎЩЯЕФЖрВуЪБПе Transformer НтТыЦїЁЃ CLIP жїИЩДгУПИіжЁжаЖРСЂЬсШЁЬиеїЁЃШЛКѓНЋжЁЬиеїЖбЕўвдаЮГЩЪБПеЬиеїСП,гУЪБМфаХЯЂЕїжЦ,ВЂРЁШы Transformer НтТыЦїЁЃ Transformer НтТыЦїжДааЖрВуЬиеїЕФШЋОжОлКЯ:бЇЯАЪгЦЕМЖЗжРрtoken [CLS] зїЮЊВщбЏ,ВЂНЋРДздВЛЭЌЙЧИЩПщЕФЖрИіЬиеїСПзїЮЊМќКЭжЕРЁЫЭЕННтТыЦїПщЁЃЯпадВуНЋзюКѓвЛИіНтТыЦїПщЕФЪфГіЭЖгАЕНРрдЄВтЁЃаЮЪНЩЯ,Transformer НтТыЦїЕФВйзїПЩвдБэЪОШчЯТ:
Y i = Temp ? i ( [ X N ? M + i , 1 , X N ? M + i , 2 , Ё , X N ? M + i , T ] ) q ~ i = q i ? 1 + MHA ? i ( q i ? 1 , Y i , Y i ) q i = q ~ i + MLP ? i ( q ~ i ) p = FC ? ( q M ) \begin{aligned} \mathbf{Y}_{i} &=\operatorname{Temp}_{i}\left(\left[\mathbf{X}_{N-M+i, 1}, \mathbf{X}_{N-M+i, 2}, \ldots, \mathbf{X}_{N-M+i, T}\right]\right) \\ \tilde{\mathbf{q}}_{i} &=\mathbf{q}_{i-1}+\operatorname{MHA}_{i}\left(\mathbf{q}_{i-1}, \mathbf{Y}_{i}, \mathbf{Y}_{i}\right) \\ \mathbf{q}_{i} &=\tilde{\mathbf{q}}_{i}+\operatorname{MLP}_{i}\left(\tilde{\mathbf{q}}_{i}\right) \\ \mathbf{p} &=\operatorname{FC}\left(\mathbf{q}_{M}\right) \end{aligned} Yi?q~?i?qi?p?=Tempi?([XN?M+i,1?,XN?M+i,2?,Ё,XN?M+i,T?])=qi?1?+MHAi?(qi?1?,Yi?,Yi?)=q~?i?+MLPi?(q~?i?)=FC(qM?)?
Цфжа X n , t \mathbf{X}_{n, t} Xn,t?БэЪОДг CLIP жїИЩЕФЕк n ВуЬсШЁЕФЕк t жЁЕФжЁЬиеї, Y i \mathbf{Y}_{i} Yi?БэЪОЪфШыЕН Transformer НтТыЦїЕФЕк i ВуЕФЪБМфЕїжЦЬиеїСПЁЃ q i \mathbf{q}_{i} qi?ЪЧж№ВНЯИЛЏЕФВщбЏtoken, q 0 \mathbf{q}_{0} q0? зїЮЊПЩбЇЯАВЮЪ§, p \mathbf{p} p ЪЧзюжедЄВтЁЃNЁЂM ЗжБ№БэЪОжїИЩЭМЯёБрТыЦїКЭЪБПеНтТыЦїжаЕФПщЪ§ЁЃ MHAДњБэmulti-head attention,Ш§ИіВЮЪ§ЗжБ№ЪЧqueryЁЂkeyКЭvalueЁЃ Temp ЪЧЪБМфНЈФЃ,ЫќВњЩњгЩИќЯИСЃЖШЕФЪБМфаХЯЂЕїжЦЕФЬиеїtokenЁЃ
3.2 Learning Temporal Cues from Spatial Features
ЫфШЛ CLIP ФЃаЭЩњГЩЧПДѓЕФПеМфЬиеї,ЕЋЫќУЧЭъШЋШБЗІЪБМфаХЯЂЁЃОЁЙм Transformer НтТыЦїФмЙЛНјааМгШЈЬиеїОлКЯ,етЪЧвЛжжШЋОжЪБМфаХЯЂЕФаЮЪН,ЕЋЯИСЃЖШКЭОжВПЪБМфаХКХвВПЩФмЖдЪгЦЕЪЖБ№гаМлжЕЁЃвђДЫ,зїепв§ШыСЫвдЯТЪБМфФЃПщРДЖдетаЉаХЯЂНјааБрТы,ШЛКѓдйНЋЬиеїЪфШыЕН Transformer НтТыЦїжаЁЃ
Temporal Convolution
ЪБМфЩюЖШОэЛ§ФмЙЛВЖЛёбиЪБМфЮЌЖШЕФОжВПЬиеїБфЛЏ,ВЂЧввбжЊЪЧИпаЇКЭгааЇЕФЁЃаЮЪНЩЯ,етИіОэЛ§БрТыЕФЬиеїаДГЩ Y conv? \mathbf{Y}_{\text {conv }} Yconv??,ВЂЧв
Y c o n v ( t , h , w , c ) = ЁЦ ІЄ t ЁЪ { ? 1 , 0 , 1 } W c o n v ( ІЄ t , c ) X ( t + ІЄ t , h , w , c ) + b conv? ( c ) \mathbf{Y}_{\mathrm{conv}}(t, h, w, c)=\sum_{\Delta t \in\{-1,0,1\}} \mathbf{W}_{\mathrm{conv}}(\Delta t, c) \mathbf{X}(t+\Delta t, h, w, c)+\mathbf{b}_{\text {conv }}(c) Yconv?(t,h,w,c)=ІЄtЁЪ{?1,0,1}ЁЦ?Wconv?(ІЄt,c)X(t+ІЄt,h,w,c)+bconv??(c)
Temporal Positional Embeddings
зїепбЇЯАСЫвЛзщЮЌЖШЮЊ C ЕФ T ИіЯђСП,БэЪОЮЊ P ЁЪ R T ЁС C \mathbf{P} \in \mathbb{R}^{T \times C} PЁЪRTЁСC,зїЮЊЪБМфЮЛжУЧЖШыЁЃЭМЯёЬиеїИљОнЫќУЧЕФЪБМфЮЛжУ t гыЯђСПжЎвЛЯрМг,БэЪОЮЊ:
Y pos ? ( t , h , w , c ) = P ( t , c ) \mathbf{Y}_{\operatorname{pos}}(t, h, w, c)=\mathbf{P}(t, c) Ypos?(t,h,w,c)=P(t,c)
ЫфШЛЪБМфОэЛ§вВПЩвдвўЪНВЖЛёЪБМфЮЛжУаХЯЂ,ЕЋЭЈЙ§ЪЙВЛЭЌЪБМфЕФЯрЫЦЬиеїПЩЧјЗж,ЮЛжУЧЖШыИќМгУїШЗЁЃЮЛжУЧЖШыЖдгкдЖГЬЪБМфНЈФЃвВИќЧПДѓ,ЮЊДЫБиаыЖбЕўЖрИіОэЛ§ПщвдЪЕЯжДѓЕФИаЪмвАЁЃ
Temporal Cross Attention.
СэвЛИігаШЄЕЋОГЃБЛКіЪгЕФЪБМфаХЯЂРДдДЪЧзЂвтСІЭМЁЃгЩгкзЂвтСІЭМЗДгГСЫЬиеїЖдгІЙиЯЕ,МЦЫуСНжЁжЎМфЕФзЂвтСІЭМздШЛЛсНвЪОЖдЯѓдЫЖЏаХЯЂЁЃИќОпЬхЕиЫЕ,зїепЪзЯШЪЙгУ CLIP жаЕФдЪМВщбЏКЭЙиМќЭЖгАЙЙНЈЯрСкжЁжЎМфЕФзЂвтСІЭМ:
A prev? ( t ) = Softmax ? ( ( Q X ( t ) ) T ( K X ( t ? 1 ) ) ) A next? ( t ) = Softmax ? ( ( Q X ( t ) ) T ( K X ( t + 1 ) ) ) \mathbf{A}_{\text {prev }}(t)=\operatorname{Softmax}\left((\mathbf{Q X}(t))^{T}(\mathbf{K X}(t-1))\right)\\\mathbf{A}_{\text {next }}(t)=\operatorname{Softmax}\left((\mathbf{Q X}(t))^{T}(\mathbf{K X}(t+1))\right) Aprev??(t)=Softmax((QX(t))T(KX(t?1)))Anext??(t)=Softmax((QX(t))T(KX(t+1)))
ЮЊМђЕЅЦ№Мћ,зїепЪЁТдСЫзЂвтСІЭЗ,ВЂдкБОЮФЕФЪЕЯжжаЖдЫљгаЭЗНјааСЫЦНОљЁЃШЛКѓНЋЦфЯпадЭЖгАЕНЬиеїЮЌЖШ:
Y attn ? ( t , h , w , c ) = ЁЦ h Ёф = 1 H ЁЦ w Ёф = 1 W W prev? ( h ? h Ёф , w ? w Ёф , c ) A prev? ( t , h Ёф , w Ёф ) + W next? ( h ? h Ёф , w ? w Ёф , c ) A next? ( t , h Ёф , w Ёф ) . \mathbf{Y}_{\operatorname{attn}}(t, h, w, c)=\sum_{h^{\prime}=1}^{H} \sum_{w^{\prime}=1}^{W} \mathbf{W}_{\text {prev }}\left(h-h^{\prime}, w-w^{\prime}, c\right) \mathbf{A}_{\text {prev }}\left(t, h^{\prime}, w^{\prime}\right)+\\\mathbf{W}_{\text {next }}\left(h-h^{\prime}, w-w^{\prime}, c\right) \mathbf{A}_{\text {next }}\left(t, h^{\prime}, w^{\prime}\right) . Yattn?(t,h,w,c)=hЁф=1ЁЦH?wЁф=1ЁЦW?Wprev??(h?hЁф,w?wЁф,c)Aprev??(t,hЁф,wЁф)+Wnext??(h?hЁф,w?wЁф,c)Anext??(t,hЁф,wЁф).
ЪЕбщБэУї,ОЁЙмВщбЏЁЂЙиМќКЭЪфШыЬиеїЖМЪЧДгДП 2D ЭМЯёЪ§ОнжабЇЯАЕФ,ЕЋетжжзЂвтСІЭМШдШЛЬсЙЉгагУЕФаХКХЁЃ
зюжеЕФЕїжЦЬиеїЪЧЭЈЙ§НЋЪБМфЬиеїгыдЪМПеМфЬиеївдВаВюЗНЪНЛьКЯЕУЕНЕФ,МД
Y
=
X
+
Y
c
o
n
v
+
Y
pos?
+
Y
a
t
t
n
\mathbf{Y}=\mathbf{X}+\mathbf{Y}_{\mathrm{conv}}+\mathbf{Y}_{\text {pos }}+\mathbf{Y}_{\mathrm{attn}}
Y=X+Yconv?+Ypos??+Yattn?ЁЃ
3.3 Complexity Analysis
Inference
ПМТЧЕНжЛЪЙгУвЛИіВщбЏtoken,ЖюЭтЕФ Transformer НтТыЦїжЛв§ШыСЫПЩКіТдЕФМЦЫуПЊЯњЁЃЮЊСЫжЄУїетвЛЕу,зїепНЋ ViT-B/16 ЪгЮЊБОЮФЕФЭМЯёжїИЩ,ВЂЮЊ Transformer ПщаДГі FLOPS,ШчЯТЫљЪО:
F L O P S = 2 q C 2 + 2 k C 2 + 2 q k C + 2 ІС q C 2 \mathrm{FLOPS}=2 q C^{2}+2 k C^{2}+2 q k C+2 \alpha q C^{2} FLOPS=2qC2+2kC2+2qkC+2ІСqC2
етРя,qЁЂkЁЂCЁЂІС ДњБэВщбЏtokenЕФЪ§СПЁЂМќ(жЕ)tokenЕФЪ§СПЁЂЧЖШыЮЌЖШЕФЪ§СПКЭ MLP РЉеЙвђзгЁЃЭЈЙ§етИіЙЋЪН,ПЩвдДжТдЕиБШНЯвЛИіБрТыЦїПщКЭНтТыЦїПщЕФ FLOPS(h,w,t ЪЧбиИпЖШЁЂПэЖШЁЂЪБМфЮЌЖШЕФЬиеїДѓаЁ,ВЩгУГЃМћЕФбЁдё ІС = 4,h = w = 14,C = 768 гУгкЙРМЦ):
?FLOPS? d e c F L O P S e n c Ёж 2 h w t C 2 t ( 12 h w C 2 + 2 h 2 w 2 C ) Ёж 1 6 \frac{\text { FLOPS }_{\mathrm{dec}}}{\mathrm{FLOPS}_{\mathrm{enc}}} \approx \frac{2 h w t C^{2}}{t\left(12 h w C^{2}+2 h^{2} w^{2} C\right)} \approx \frac{1}{6} FLOPSenc??FLOPS?dec??Ёжt(12hwC2+2h2w2C)2hwtC2?Ёж61?
гЩДЫ,ПЩвдПДЕН,гыБрТыЦїПщЯрБШ,НтТыЦїПщИќЧсСПМЖЁЃМДЪЙЪЙгУЭъећХфжУ(УПИіБрТыЦїЪфГіЩЯЖМгавЛИіНтТыЦїПщ,ВЛМѕЩйЭЈЕРВЂЧвЦєгУЫљгаЪБМфФЃПщ),FLOPS ЕФдіМгвВдкжїИЩЕФ 20% вдФкЁЃ
Training
гЩгкЪЙгУЙЬЖЈЙЧИЩЭјКЭЗЧЧжШыЪН Transformer НтТыЦїЭЗ(МД,ВхШыЕФФЃПщВЛЛсИФБфШЮКЮЙЧИЩЭјВуЕФЪфШы),ПЩвдЭъШЋБмУтЭЈЙ§ЙЧИЩЭјНјааЗДЯђДЋВЅЁЃетДѓДѓМѕЩйСЫФкДцЯћКФКЭУПДЮбЕСЗЕќДњЕФЪБМфЁЃ
4.ЪЕбщ
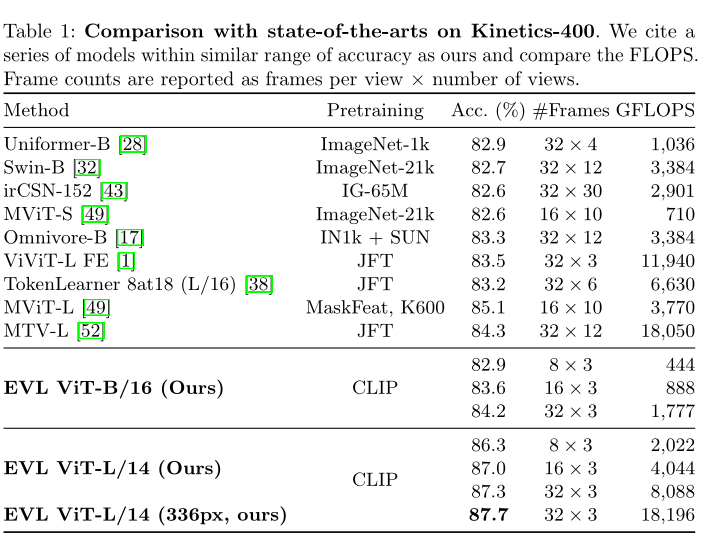
Kinetics-400Ъ§ОнМЏЩЯБОЮФЗНЗЈКЭЦфЫћSOTAЗНЗЈЕФЖдБШЁЃ
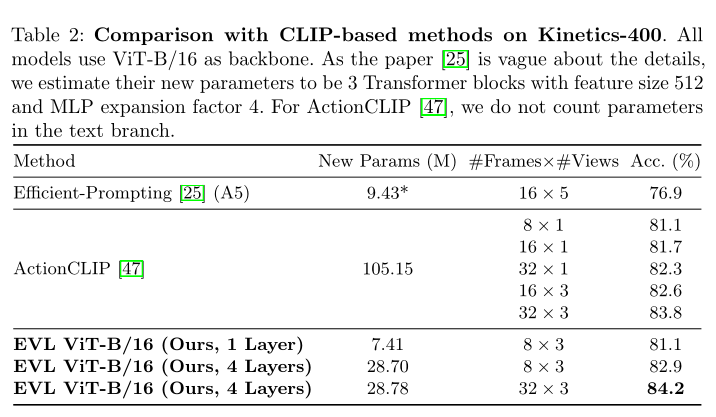
ЩЯБэеЙЪОСЫБОЮФЗНЗЈЕФЛљгкCLIPЗНЗЈЕФЖдБШНсЙћЁЃ
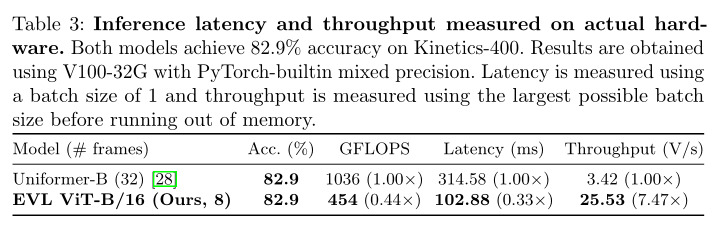
дкЪЕМЪгВМўЩЯВтСПЕФЭЦРэбгГйКЭЭЬЭТСПЁЃ
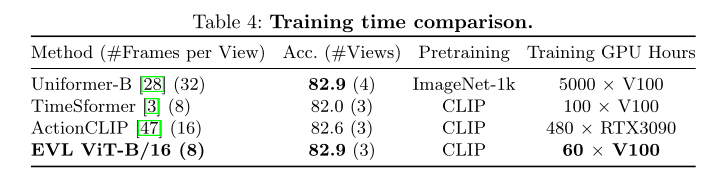
бЕСЗЪБМфБШНЯЁЃ

зїепдкЩЯБэжаБШНЯСЫРэЯыЩшжУжаЕФбЕСЗЪБМфЁЃ
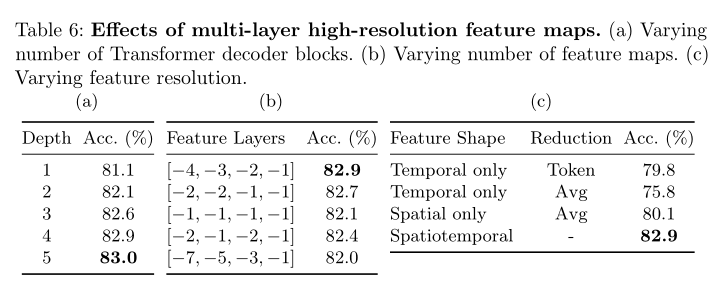
ЖрВуИпЗжБцТЪЬиеїЭМЕФаЇЙћЁЃ
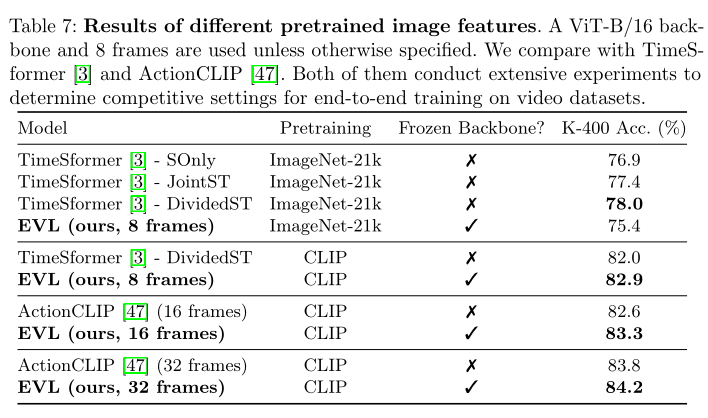
ВЛЭЌдЄбЕСЗЭМЯёЬиеїЕФНсЙћЁЃ
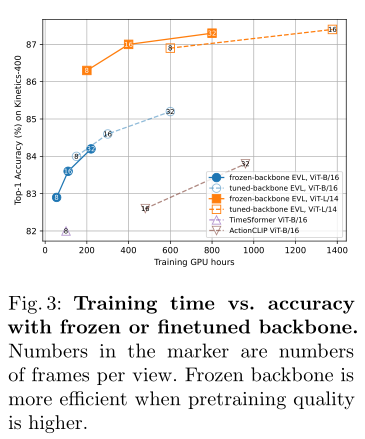
ЩЯЭМеЙЪОСЫбЕСЗЪБМфгыЖГНсЛђЮЂЕїжїИЩЕФзМШЗадЁЃ
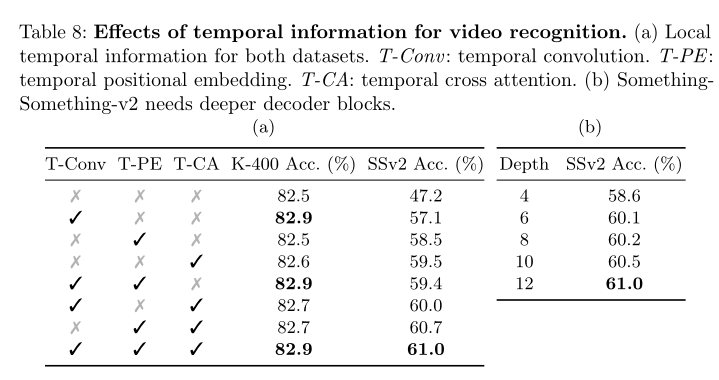
ЪБМфаХЯЂЖдЪгЦЕЪЖБ№ЕФгАЯьЁЃ

Something-Something-v2 ЕФжївЊНсЙћЁЃ
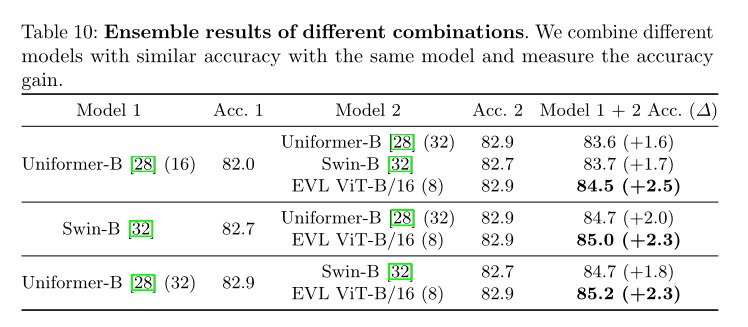
ВЛЭЌзщКЯЕФМЏГЩНсЙћЁЃ

дкSomething-Something-v2 ЩЯМЏГЩНсЙћЁЃ
5. змНс
зїепЬсГіСЫвЛжжаТЕФЪгЦЕЖЏзїЪЖБ№pipelineаЮЪН:дкЙЬЖЈЕФПЩЧЈвЦЭМЯёЬиеїжЎЩЯбЇЯАвЛИігааЇЕФЧЈвЦбЇЯАЭЗЁЃЭЈЙ§ЖГНсЭМЯёжїИЩ,бЕСЗЪБМфДѓДѓМѕЩйЁЃДЫЭт,ЭЈЙ§РћгУРДзджїИЩЕФЖрВуИпЗжБцТЪжаМфЬиеїЭМ,ПЩвддкКмДѓГЬЖШЩЯВЙГЅгЩгкЖГНсжїИЩдьГЩЕФОЋЖШЫ№ЪЇЁЃвђДЫ,БОЮФЕФЗНЗЈгааЇЕиРћгУСЫЧПДѓЕФЭМЯёЬиеїНјааЪгЦЕЪЖБ№,ЭЌЪББмУтСЫЖдЗЧГЃДѓЕФЭМЯёФЃаЭНјааЗБжиЛђСюШЫЭћЖјШДВНЕФШЋУцЮЂЕїЁЃзїепНјвЛВНБэУї,дкПЊЗХЪРНчЛЗОГжабЇЯАЕФПЩзЊвЦЭМЯёЬиеїАќКЌгыБъМЧЪ§ОнМЏИпЖШЛЅВЙЕФжЊЪЖ,етПЩФмЛсМЄЗЂИќгааЇЕФЗНЗЈРДЙЙНЈзюЯШНјЕФЪгЦЕФЃаЭЁЃзїепШЯЮЊБОЮФЕФЙлВьгаПЩФмЪЙИќЙуЗКЕФЩчЧјПЩвдЗУЮЪЪгЦЕЪЖБ№,ВЂвдИќгааЇЕФЗНЪННЋЪгЦЕФЃаЭЭЦЯђаТЕФзюЯШНјЫЎЦНЁЃ
ЁОЯюФПЭЦМіЁП
УцЯђаЁАзЕФЖЅЛсТлЮФКЫаФДњТыПт:https://github.com/xmu-xiaoma666/External-Attention-pytorch
УцЯђаЁАзЕФYOLOФПБъМьВтПт:https://github.com/iscyy/yoloair
УцЯђаЁАзЕФЖЅПЏЖЅЛсЕФТлЮФНтЮі:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading

ЁАЕуИідкПД,дТаНЪЎЭђ!ЁБ
ЁАбЇЛсЕудо,ЩэМлЧЇЭђ!ЁБ