Transformer简介
自从Transformer模型问世后,基于Transformer的深度学习模型也在NLP领域中大放异彩。本文主要是介绍Transformer模型自注意力机制的基本原理,以方便大家在NLP中了解和使用Transformer。
Self-Attention(自注意力机制)
自注意力机制最初是就是出现在自然语言处理领域的,自注意力模型可以认为在学习一种关系,在Transformer的整体结构中处于下图红框的位置中。
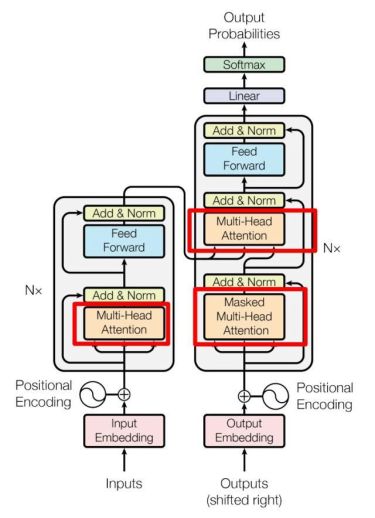
Multi-Head Attention的位置:这是论文中 Transformer 的内部结构图,左侧为编码块(Encoder block),右侧为解码块(Decoder block)。红框中的部分为多头注意力模块(Multi-Head Attention),是由多个自注意力(Self-Attention)组成的,可以看到Encoder block包含一个Multi-Head Attention,而 Decoder block包含两个Multi-Head Attention。Multi-Head Attention上方还包括一个Add&Norm层,Add表示残差连接(Residual Connection)用于防止网络退化,Norm表示Layer Normalization,用于对每一层的激活值进行归一化。
Self-Attention 结构:通过上面介绍我们可以发现Self-Attention是构成多注意力机制的基本单元,所以下面解析下Self-Attention的结构和内部的计算。
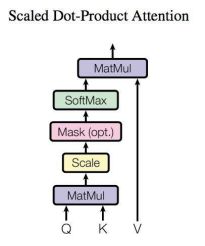
上图是 Self-Attention 的结构,在计算的时候需要用到矩阵Q(Query)、K(Key)和V(Value)向量。对于输入的单词,会首先经过Embedding将单词编码成词向量X,对每个词向量Xi,再计算该词向量对应的Q、K、V。
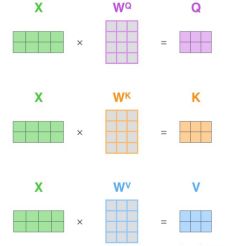
Self-Attention 的输入用矩阵X进行表示,通过对应的输入向量X乘以对应的权重矩阵W,计算如下图所示,X、Q、K、V的每一行都表示一个词。
计算自注意力分数:对于一个词向量,用该向量对应的q与整个序列中所有k进行点乘,并得到对应分数,这里将这个分数命名“自注意力分数”。例如某一词向量Xi,用它的q1分别与该序列的k1、k2、...、kn相乘,会得到n个分数标量,分数值越大的,就表述这两个词向量的关联越大。
自主注意力分数值得调整 :在计算完自注意力分数后,我们看到后面还有一个softmax计算,考虑到softmax的图形,在值越大的地方梯度会越小,所以如果上一步计算出的分数值越大,那样就会出现梯度小时的情况,此时就需要进行分数值的调整。常用的计算方法是用分数值除以dk的开方,这里的dk表示向量k的维度。

Softmax的计算:经过softmax之后的分数与对应的Value(v)相乘。 这一步计算的目的是希望通过自注意力分数值来保持序列中相关单词的权重,同时降低不相关单词的权重。
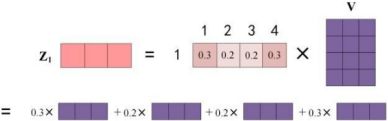
计算最终的输出Z值:最终词1的输出等于所有单词i的值根据自注意力系数的比例加在一起得到,如下图所示。
Multi-Head?Attention(多头注意力)
在上一步,我们已经知道怎么通过Self-Attention计算得到输出矩阵Z,而Multi-Head Attention是由多个Self-Attention组合形成的,所以整体也叫多头注意力机制。下图是论文中Multi-Head Attention的结构图。

Multi-Head Attention
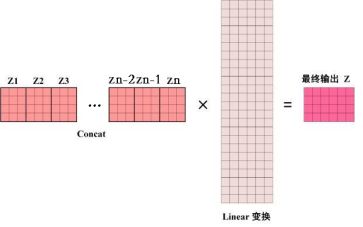
从上图可以看出Multi-Head Attention由多个Self-Attention层,首先将输入X分别传递到h个不同的Self-Attention中,计算得到h个输出矩阵Z。Multi-Head Attention 将h个矩阵Z拼接在一起,然后传入一个Linear层,得到Multi-Head Attention最终的输出Z。
总结
通过本文自注意力机制self-attention的过程解析,首先通过输入词的query和key相乘计算出一个关系权重,再用这个关系权重对value进行加权求和,以提升一个序列中相关向量的权重,降低不相关元素的权重。Multi-Head Attention则是将多层self-attention的结果进行拼接计算,从而实现自注意力的目的。
谢谢浏览,如有不正确的地方欢迎留言指正~