目标检测模型的数据准备、训练和预测过程开发文档
开发步骤:
一:数据采集与数据标注
二:训练模型
三:测试模型
代码文件:
yolo4_tiny.py,CSPdarknet53_tiny.py定义了一个轻量级模型
loss.py用于计算预测框与真实框的iou以及loss值等
ious.py用于求出预测框以及真实框的位置
utils.py文件中设置了输入进来的图片以及预测框的处理以及训练学习率的调用设置
一:数据采集与数据标注
1:数据集结构:
JPEGImages文件夹:
原始图像格式必须为jpg格式,避免出错
Annotations文件夹:
该文件夹中存放图像标注的xml文件
ImageSets文件夹:
该文件夹中存放标注类别的每个文件列表信息
train.txt表示训练数据集合
val.txt表示验证数据集合
trainval.txt表示验证跟训练数据集合
test.txt表示测试数据集合
2:数据采集
选择需要检测的目标,按目标采集图片
此处选择目标类别为:人头(head),眼镜(glass),帽子(cap),行人(pedestrian),口罩(mask)
3:数据标注
使用labelImg工具标注图片
4:数据集制作
运行voc2yolo4.py文件会生成四个txt文件
5:生成图片及标注框位置
运行voc_annotation.py文件会生成三个txt文件

2007_train.txt中每一行对应图片路径及标注框位置
二:训练模型
训练前在model_data文件夹下创建voc_classes.txt文件,存放需要分类的类别
train.py文件中获得类和先验框
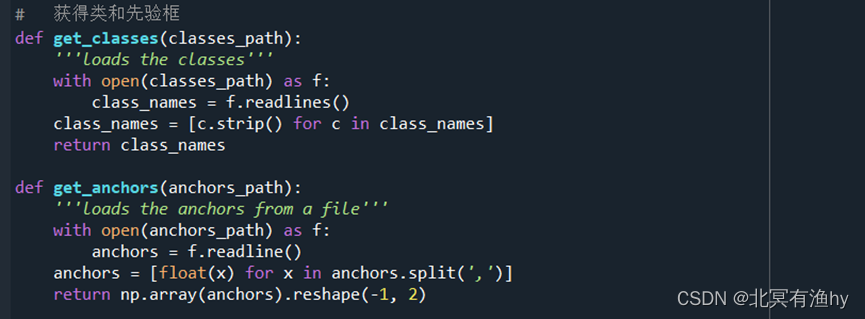
设置训练数据生成器后读入xml文件,获得框属性
创建yolo模型

训练文件中可选择是否加载预训练权重

训练参数的设置
logging表示tensorboard的保存地址
checkpoint用于设置权值保存的细节,period用于修改多少epoch保存一次
reduce_lr用于设置学习率下降的方式
early_stopping用于设定早停,val_loss多次不下降自动结束训练,表示模型基本收敛
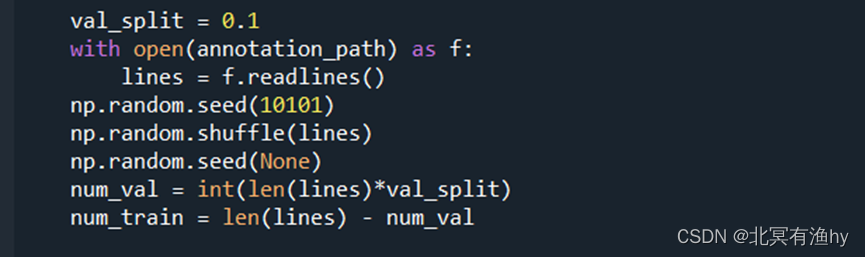
划分验证集和训练集比例为1:9

开始训练,先冻结后训练,再解冻训练,冻结后训练可以加快训练速度,也可以在训练初期防止权值被破坏

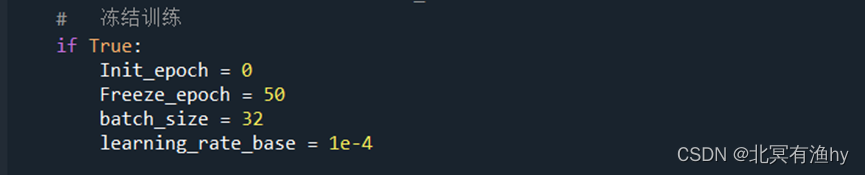
Init_epoch为训练起始
Freeze_epoch为冻结训练的次数
Epoch为总训练次数
batch_size为一次训练中每次数据读取个数
这些数据可视个人情况设定
运行train.py文件开始训练

三:测试模型
在yolo.py文件中设置模型路径以及预测框的分数score、交并比iou等
如检测不出目标可适当降低score值
需注意当模型损失率在20左右时可能检测不到目标,应多进行几次训练尽量降低损失率。
运行predict.py文件
在终端中输入:
python predict.py
输入图片名称可测试图片,并将图片保存


运行video.py可调用摄像头检测
在终端中输入
python video.py
如果要调用视频测试可将
capture=cv2.VideoCapture(0)
改为
capture=cv2.VideoCapture(“视频路径”)