0. ЧАбд
ЩюЖШбЇЯАЗжВМЪНбЕСЗШЮЮё,ОЭЪЧгЩЖрИіНјГЬвЛЦ№азїЭъГЩФГИіФЃаЭЕФбЕСЗ,етаЉНјГЬПЩвддЫаадкЕЅИіЛњЦїЩЯ,вВПЩвддЫаадкЖрИіЛњЦїЩЯ;ПЩвддЫаадк CPU Device(ЩшБИ)ЩЯ,вВПЩвддЫаадк GPUЁЂNPU(ЛЊЮЊNЬк)ЁЂXPU(АйЖШРЅТи) Device ЩЯ;ПЩвддЫаадк Host(ЮяРэЛњ) ЩЯ,вВПЩвддЫаадк Container(ШнЦї)ЁЂVM(ащФтЛњ)ЩЯЁЃФЧУД,ЯрБШгкЕЅЬхбЕСЗ,ЗжВМЪНбЕСЗФмДјРДФФаЉКУДІФи?ЗжВМЪННјГЬЪЧШчКЮЦєЖЏЕФФи?етаЉНјГЬжЎМфашвЊНЛЛЅТ№?ШчКЮИјУПИіНјГЬЗжХфбЕСЗШЮЮё?БОЮФНЋДјФуРДвЛЦ№бАеветаЉЮЪЬтЕФД№АИЁЃ
1. ЩюЖШбЇЯАШчКЮбЁдёЗжВМЪНбЕСЗПђМм?
ДѓФЃаЭДјРДЕФЬєеНжївЊгаСНЕу:КЃСПбљБОЁЂВЮЪ§(ЭђвкМЖБ№)КЭНЯГЄЕФЪеСВЪБМфЁЃвЛАуРДЫЕ,ЕЅеХ GPU A100 ЯдДцДѓаЁ 40GЁЂЕЅЬЈЛЊЮЊ 2288H V5 ЕФФкДцДѓаЁФмДяЕНЩЯАй G,ЫљвдДѓФЃаЭЕФбЕСЗЕУНшжњЖрЛњЖрПЈ,ЕЋЪЧЫцзХЛњЦїЪ§ЕФдіМг,ЪевцШДВЛФмДјРДЯпГЬдіГЄ,етжївЊЪЧЛњЦїМфЭЈаХПЊЯњжИЪ§діМг,ЗжВМЪНбЕСЗЛЙЕУБЃжЄвЛЖЈЕФЖрПЈМгЫйБШЁЃ
ДѓФЃаЭжївЊЗжЮЊСНРр:вЛЪЧЫбЫїЁЂЭЦМіЁЂЙуИцРрШЮЮё,ЫќЕФЬиЕуЪЧКЃСПбљБОМАДѓЙцФЃЯЁЪшВЮЪ§(sparse embeddings),ЪЪКЯЪЙгУ CPU/GPU ВЮЪ§ЗўЮёЦїФЃЪН(PS);СэвЛжжЪЧ CVЁЂNLP ШЮЮё,ЫќЕФЬиЕуЪЧГЃЙцбљБОЪ§ОнМАДѓЙцФЃГэУмВЮЪ§,ЫќЪЪКЯгУДП GPU МЏКЯЭЈаХФЃЪН(Collective)ЁЃВЮЪ§ЗўЮёЦїФЃЪНДгЕквЛДњ Alex Smola дк 2010 ФъЬсГіЕФ LDA(ЮФБОЭкОђСьгђЕФвўЕвРћПЫРзЗжХфФЃаЭ),ЕНЕкЖўДњ Jeff Dean ЬсГіЕФ DistBelief,НгзХЕНЕкШ§ДњРюухЬсГіЕФЯрЖдГЩЪьЕФЯжДњ Parameter Server МмЙЙ,дйЕНКѓРДЕФАйЛЈЦыЗХ:Uber ЕФ Horvod,АЂРяЕФ XDLЁЂPAI,Meta ЕФ DLRM,зжНкЕФ BytePsЁЂУРЭХЛљгк Tensorlow зіЕФИїжжЪЪХфЕШЕШЁЃВЮЪ§ЗўЮёЦїЕФЙІФмШеЧїЭъЩЦ,адФмвВдНРДдНЧП,гаДП CPUЁЂДП GPU,вВгавьЙЙФЃЪНЁЃСэвЛЗНУц,ЛљгкДП GPU ЕФМЏКЯЭЈаХФЃЪНЕФЗжВМЪНбЕСЗПђМм,АщЫцзХ Nvidia ЕФММЪѕЕќДњ,ЬиБ№ЪЧ GPU ЭЈаХММЪѕ(GPU Direct RDMA)ЕФНјВН,адФмвВБфЕУгњРДгњЧПЁЃ
AI ФЃаЭбЕСЗШЮЮёСїГЬ:ГѕЪМЛЏФЃаЭВЮЪ§ -> ж№ЬѕЖСШЁбЕСЗбљБО -> ЧАЯђЁЂЗДЯђЁЂВЮЪ§ИќаТ -> ЖСШЁЯТвЛЬѕбљБО -> ЧАЯђЁЂЗДЯђЁЂВЮЪ§ИќаТ -> Ё бЛЗ,жБжСЪеСВЁЃ
дкШэМўВуУцЕФЬхЯжОЭЪЧМЦЫуЛњАДЫГађдЫаавЛИіИі OP(МЦЫуЕЅдЊ,ПЩвдРэНтЮЊКЏЪ§)ЁЃМйШчвЛИіДѓФЃаЭЕФ OP змЪ§ЮЊn,Ек iИі OP ЕФЪфШыЁЂЪфГіБфСПЁЂВЮЪ§ЁЂгХЛЏЦїжаМфзДЬЌБфСПИіЪ§змЙВЮЊmi ,бЕСЗЕЅЬѕбљБОашвЊЕФЫуСІЮЊ ci Flops(ИЁЕудЫЫуДЮЪ§),ФЧУДашвЊДцДЂЕФРлМЦБфСПИіЪ§ЮЊ 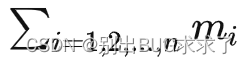
,ЫљашзмЫуСІЮЊ 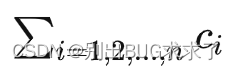
,ЭЌЪБПМТЧЕНВЛЭЌ OP жЎМфЕФДцДЂЁЂЫуСІашЧѓВювьКмДѓ,БШШчгаЕФ OP ашвЊЯћКФОоДѓЕФДцДЂФмСІ,ШДжЛвЊКмЩйЕФЫуСІ,ЖјгаЕФ OP ашвЊОоДѓЕФЫуСІ,ШДЖдДцДЂЕФвЊЧѓКмЕЭЁЃЕкiИі OP КЭЕкj ИіOP жЎМфЕФЭЈаХПЊЯњ(ДјПэКЭЪБбг)БъЪЖЮЊk_i,j . ДгЪ§бЇЩЯПД,ШчЙћИјЖЈЙЬЖЈЪ§СПЕФ CPUЁЂGPU ЛњЦїПЈЪ§,ФЧУДдкДцДЂзЪдДРћгУТЪІЫЁЂЫуСІзЪдДРћгУТЪІЧ ЁЂзюЖЬбЕСЗЪБМфІУЕШжИБъЩЯЭЈЙ§ЭЙгХЛЏРэТлПЩвдШЁЕУ(НќЫЦ)зюгХНтЁЃ
ШЛЖј,МДЪЙДгЪ§бЇдРэЩЯЧѓГіСЫзюгХЕФВЮЪ§КЭ OP ЗХжУВпТд,ДгЙЄГЬЪЕМљЩЯПД,ЪЕЯжИДдгЖШЗЧГЃИпЧвМИКѕЮоЗЈИДгУ(ЖдгквЛИіаТРДЕФДѓФЃаЭ),етЪЧгЩЩюЖШбЇЯАПђМмЕФЪЕЯждРэОіЖЈЕФЁЃЮвУЧдйРДПДПДЪаУцЩЯвбгаЕФЗжВМЪНВпТд,БШШч:
- Ъ§ОнВЂаа:зюШнвзРэНт,КЃСПбЕСЗбљБОЧаЗжЕНВЛЭЌЛњЦїЩЯ,ДЋЭГЕФВЮЪ§ЗўЮёЦїФЃЪНЪЧЕфаЭДњБэ
- ФЃаЭВЂаа:АбФЃаЭБОЩэНјааЧаЗж,ЪЙЕУУПЬЈЛњЦї(ЯдПЈ)ЩЯжЛашвЊДцФЃаЭЕФвЛВПЗж,ЪЕЯжЗНЪНЖржжЖрбљ:
- жЛЧаЗжФЃаЭВЮЪ§
- жЛзіФЃаЭЕФМђЕЅКсЯђЧаЗж,вЛИі Layer ЧаГЩЖрИі Partition
- ЖдвЛИіЫузгНјааВ№Зж,БШШч FC(ШЋСЌНгВу),АбВЮЪ§КЭМЦЫуЕФЧаЗжЕНЖрИіGPUЩЯ,ЭЈЙ§ЭЈаХЭъГЩетИідзгМЦЫу
- СїЫЎЯпВЂаа:РЯЩњГЃЬИСЫ,ЭЈЙ§ЛЎЗж micro batch ШУМЦЫуЛњдкЭЈаХЕФЪБКђВЛвЊЭЃжЙМЦЫу
- Sharding:ПЩвдРэНтЮЊЪЧБШНЯвзгУЕФФЃаЭВЂаа,жївЊЪЧВЮЪ§ЁЂЬнЖШЁЂгХЛЏЦїзДЬЌЧаЗжЕНВЛЭЌЛњЦї(ЯдПЈ)
- Offload:ОоСПЯЁЪшВЮЪ§аЖдиЕН SSDЁЂHost ФкДцЁЂHBM(ЯдДц)ЕШ,ВЩгУЖрМЖДцДЂМмЙЙ;ЖјЖдгкГэУмВЮЪ§,дђашвЊНшгУЛьКЯОЋЖС
- Recompute:гУЪБМфЛЛПеМфЕФЫМЯы,МДдкЧАЯђЪБжЛБЃДцВПЗжжаМфНсЙћ,дкЗДЯђЪБжиаТМЦЫуУЛБЃДцЕФВПЗж
ЛьКЯВЂаа:ЩЯЪіФмгУЕФВЂааВпТдШЋгУЩЯ
ЩЯЪіетаЉВЂааВпТдгаФФаЉЬиЕуФи?БШНЯШнвзЯыЕН,ЕЋЪЧЪЕЪЉЦ№РД,гавЛЖЈПЊЗЂСПЧвФбвдИДгУЁЃетРя,ЮвдйВЙГфвЛЬѕ,ОЭЪЧ C++ ШэМўВуУцБОЩэЕФадФмгХЛЏ,ЩцМАЕНДњТыгХЛЏЁЂжДааСїГЬгХЛЏЁЂiCacheЁЂiTableЁЂPGO ЕШгХЛЏ,дЄМЦдкбЕСЗЫйЖШЩЯжСЩйга 10% ЕФЬсЩ§,ЖјЧвЖдУПИіФЃаЭЛљБОЖМгааЇЁЃЕЋЪЧ,КмЩйПДЕНгаШЫетбљИЩЙ§ЁЃвЛЗНУцдвђЪЧЯрБШгкКъЙлВуУцЕФВЂааВпТдФмДјРДОоДѓЕФадФмЬсЩ§,етВПЗжЕФадФмЬсЩ§ЕуЯдЕУКмаЁ;СэвЛЗНУцдвђ,вВПЩФмЪЧФмЙЛзіЕНШэМўадФмМЋжТгХЛЏ(НсКЯВйзїЯЕЭГКЭБрвыЦї)ЕФзЈвЕШЫВХдк AI СьгђЪЧЯЁШБЕФЁЃ
ДгИіШЫОбщРДПД,ШчЙћАДЪ§бЇЩЯзюгХЕФВпТдРДжДааЗжВМЪНбЕСЗШЮЮё,ФмДјРДДѓдМ 30% ЕФГЩБОНЕЕЭКЭЬМХХЗХ(ЖдгІЕФОјЖдГЩБОНЕЕЭПЩДѓСЫШЅСЫ),ФмНкЪЁОоДѓЕФШЫСІПЊЗЂГЩБО,ЖјЧвЪЙЕУФЃаЭФмЙЛПьЫйЪеСВЁЂЩЯЯпВЂПьЫйЕќДњЁЃЯывЊДяГЩетвЛФПБъ,ЮвУЧвЊДгФФаЉЗНЯђзХЪжФи?етРяЯШТєИіЙизг,ЯШПДПДЯжгаЕФЗжВМЪНбЕСЗПђМмЕФдЫааЛњжЦЁЃ
2. ЩюЖШбЇЯАЗжВМЪНбЕСЗПђМмЕФдЫааЛњжЦ
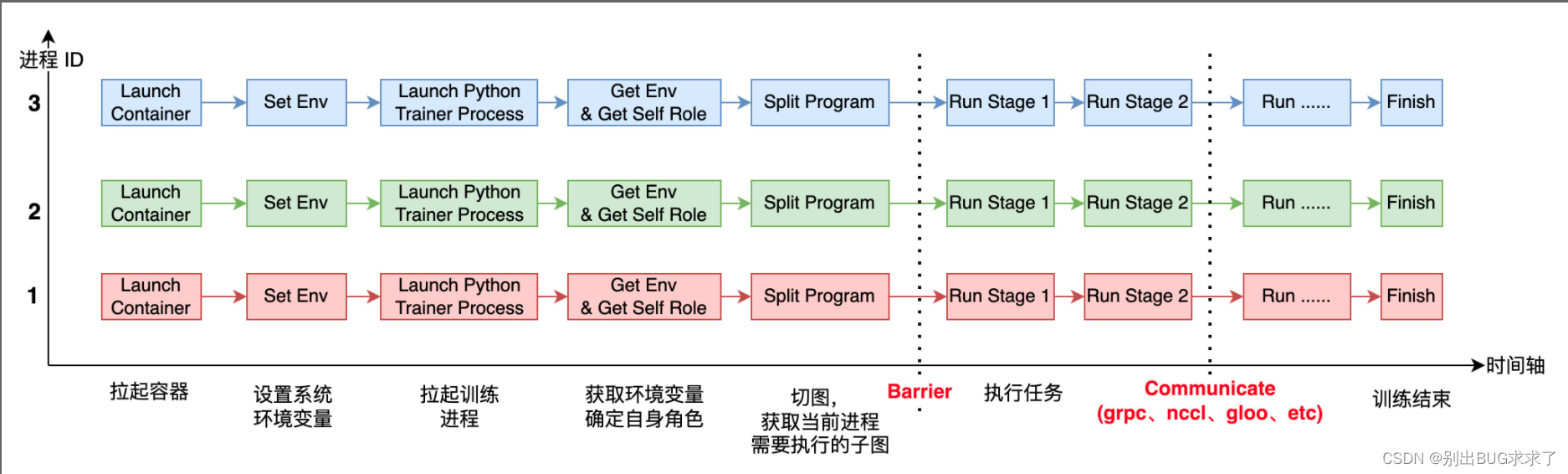
ЩЯЭМБэЪОЕФЪЧ 3 ИіНјГЬ(дЫаадкШнЦїРя)вЛЦ№азїРДЭъГЩ AI ФЃаЭЕФЗжВМЪНбЕСЗЁЃ
УПИіНјГЬЦєЖЏКѓ,ЫќашвЊИажЊздМКШЋОжЕФНјГЬЪ§( world_size)МАздЩэЕФНјГЬ ID(Лђеп rank_id),гЩгкУПИіНјГЬЩЯдЫааЕФЖМЪЧЭЌвЛЗнбЕСЗНХБО,ЫљвдЕУЪТЯШдкУПИіНјГЬЫљдкЕФЯЕЭГЩЯЩшжУВЛЭЌЕФЛЗОГБфСП,НјГЬдЫааЦ№РДжЎКѓ,ОЭПЩвдЛёШЁЛЗОГБфСП,ДгЖјШЗЖЈздМКЕФНЧЩЋ(WorkerЁЂPServerЁЂCoordinator ЕШ)МАrank_idЁЂworld_size ЕШаХЯЂЁЃ
дкдЫааЙ§ГЬжа,ЛЙгаСНИіживЊЕФЛЗНкЪЧ Barrier КЭ Communicate. Barrier ЕФФПЕФЪЧЮЊСЫЪЕЯжНјГЬМфЭЌВН,БШНЯГЩЪьЕФПЊдДЯюФПга glooЁЂmpi ЕШЁЃCommunicate ВйзїОЭЪЧЪЕЯжЭЈаХ,ТњзуНјГЬМфЪ§ОнНЛЛЛашЧѓЁЃЭЈаХПЩвддкЭЌРраЭгВМўжЎМфЗЂЩњ,БШШч CPU ЕН CPUЁЂGPU ЕН GPU,вВПЩвдЗЂЩњдкВЛЭЌгВМўжЎМф,БШШч GPU ЕН CPU,ЭЈаХКѓЖЫвВгаЖржжаЮЪН,БШШч grpcЁЂncclЁЂsocket ЕШЁЃ
3. ЩюЖШбЇЯАЗжВМЪНбЕСЗПђМмЕФРэЯыаЮЬЌ
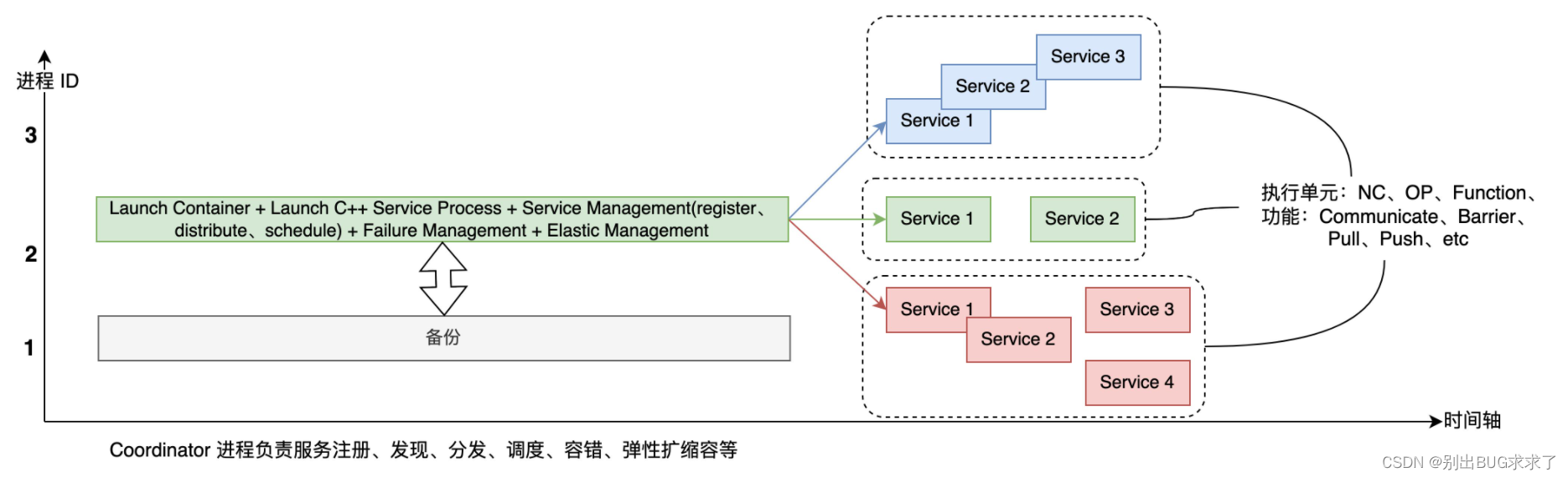
ЩЯвЛНкжаЬсЕНЕФЩюЖШбЇЯАЗжВМЪНПђМмЪЧЕБЧАжїСїЕФЪЕЯж,Шч TesorflowЁЂPytorchЁЂPaddle ЕШ,ЫќЕФвЛДѓгХЕуЪЧПЊЗЂЦ№РДБШНЯШнвз,ФмПьЫйВПЪ№ЁЃШЛЖј,ЫќЕФРЉеЙадНЯВю,вВЮоЗЈТњзузюгХЕФЕїЖШВПЪ№вЊЧѓЁЃгкЪЧ,ВЮПМдЦдЩњЕФМмЙЙ,етРяЮвЬсГіСЫЗжВМЪНбЕСЗПђМмЕФвЛжжРэЯыаЮЬЌ(ЩЯЭМ)ЁЃЭЌвЛжжбеЩЋЕФЗўЮёдЫаадкЭЌвЛИіНјГЬРя,ЫќУЧПЩвдЪЧЫГађжДаа,вВПЩвдЪЧВЂаажДааЕФ,ПЩвддЫаадкаГЬЩЯ,вВПЩвддЫаадкЯпГЬРя,ПЩвдВЩгУ"ШЅжааФЛЏ"ЛђепЪЧ"гажааФЛЏ"ЕФЛљгкЪТМўЕФЕїЖШВпТдЁЃ
ЪзЯШ,гавЛИіМЏжаЕФЧаЭМЁЂЕїЖШжааФЁЂЗўЮёЙмРэФЃПщ,гУЛЇПЩвдздЖЈвхИїжжЧаЭМВпТдЁЂЕїЖШЫуЗЈМАЗўЮёЙмРэВпТдЁЃЦфДЮ,бЕСЗШЮЮёЭъШЋЮЂЗўЮёЛЏ(Service),ДгжДааЕЅдЊЩЯРДПД,етРяЕФ Service ПЩвдЪЧ Nerual Cell(OP жЎЩЯЕФИХФю,БШШчвЛИі EncoderЁЂDecoder ФЃПщ),вВПЩвдЪЧ OP,ЛЙПЩвдЪЧЦфЫћ Function(КЏЪ§);ДгЙІФмЩЯРДЫЕ,етаЉ Service ПЩвдЪЧЭЈаХЯрЙиЁЂBarrier ЯрЙиЁЂвВПЩвдЪЧ PushЁЂPull ЯрЙиЁЃФЧУДДгЕБЧАЕФЩюЖШбЇЯАЗжВМЪНбЕСЗПђМмбнНјЕНЯТвЛДњ,ашвЊзіФФаЉЙЄзїФи?
- ПђМмЕФдЫааДѓФд - Coordinator
- здЖЏЧаЭМВпТд,етРяАќРЈвЛаЉОпЬхЕФгХЛЏЫуЗЈ,Шч allreduce fuse ЕШ
- C++ КѓЖЫДњТыЗўЮёЛЏ,ШЅёюКЯ,ЮозДЬЌИФдь
- ЭГвЛЕФЭЈаХЧАЖЫНгПк,жЇГжЖрбљЕФКѓЖЫ
гУЛЇдкЬсНЛДѓФЃаЭЕФбЕСЗШЮЮёЪБ,жЛашвЊЬсЙЉвЛИіПЩгУзЪдДЙцИёСаБэЁЂбЕСЗбљБОМАФЃаЭзщЭјЭМ,ЪЃЯТЕФЪТОЭПЩвдШЋНЛИјПђМмСЫЁЃаТвЛДњЕФЗжВМЪНЩюЖШбЇЯАбЕСЗПђМмДјРДЕФКУДІЪЧЯдЖјвзМћЕФ:
- ЮЊжДааРэТлзюгХЕФЕїЖШВпТдЬсЙЉСЫПђМмжЇГж,ДгЖјзюДѓЛЏОМУаЇвц
- ВЮЪ§ЗўЮёЦїФЃЪНКЭМЏКЯЭЈаХФЃЪНДѓвЛЭГ
- гУЛЇЩЯЪжГЩБОИќЕЭЁЂБугкЖўДЮПЊЗЂ
- СуГЩБОЧЈвЦдЦЩЯВПЪ№
- гУЛЇзщЭјЪБ,ВЛашвЊвЛаавЛаааД OP,вВПЩвджБНгзщзА Service(Python ЖЫБэЪО),ФмжЇГжДѓвЛЭГжЎКѓЕФЩёОЭјТчМмЙЙ