目录
2021视觉文本多模态任务,极其简单的多模态结构。模态的特征抽取做到了极小化,主要的计算量放在后边的模态融合上,提高了推理速度。多模态领域里程碑式工作。将区域特征,region 从多模态框架中移除。
为了加强理解ViLT把模型简化到什么程度如下图。对文本来说,只需一个词嵌入Liner Embedding就够了。而图像这边,ViLBERT需要经过CNN Backbone,和一个Region操作,其实就是一个目标检测任务。
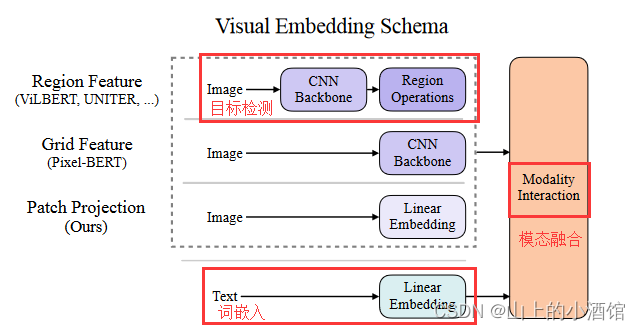
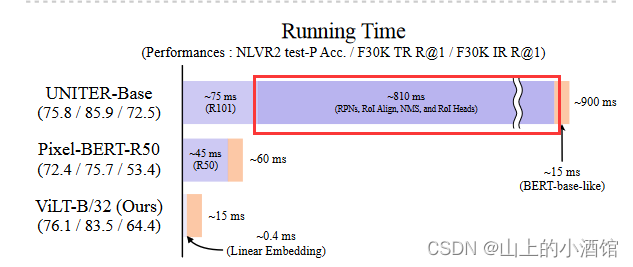
目标检测这就耗费了大量的时候。例如下图UNITER整个运行时间900ms,处理文本只需15ms,大部分时间都用在了处理目标检测任务上,达到了810ms。
0.摘要
Vision and Language Pre-training(VLP)已经已经在视觉语言的多模态下游任务中发展的很好。然而,当前VLP的工作主要集中在图像特征抽取上,一般来讲,图像特征抽取的越好,下游任务中的表现就越好。但是,现在主要有两个问题,一是效率太低,速度太慢,抽取图像特征花费大量时间,比多模态融合都多。我们应该花费更多时间在融合上。第二个是,你用一个预训练好的模型去抽取特征,表达能力受限。目标检测数据集不够大,规模不够大。如果模型不是端到端学习,只是从预训练模型抽取特征,大概率来说不是最优解。
1.引言
主要的目标函数:
1.image text matching? 2.mask language modeling
如何把图像的像素变成带有语义性的、离散的特征,再与text特征匹配。早起的多模态工作都是基于目标检测,因为目标检测框内的特征,即含有明确的类别信息,又是区域内的,小的bound box相对于整个图像是离散的,可以当做序列来处理。之前的VLP模型都是基于Visual Genome数据集上训练有1600各类别和400个属性,类别属性信息比较丰富。
但是呢,用目标检测去做模态融合确实太贵,也有一些工作尝试把工作量降下来。piexlBERT,使用ResNet去抽去图像特征,然后将抽取好的特征当做离散的序列。也可以理解为先用CNN抽取特征,得到的高维特征对应较短的序列长度,此时就可以应用Transformer去处理。这样就不需要目标检测那些操作,例如ROI(映射)和nms(非极大值抑制),速度可以提高不少。

当前,大多是VLP任务主要聚焦在通过改善视觉编码器来提高其性能。然而,现实世界中数据都是每时每秒实时生成的,这时候去做推理的时候,视觉编码器效率低的问题就显露出来了。
因此作者受ViT启发,将ViT应用到了多模态领域。ViT可以将图像打成patch,得到一个有语义信息的离散的序列。
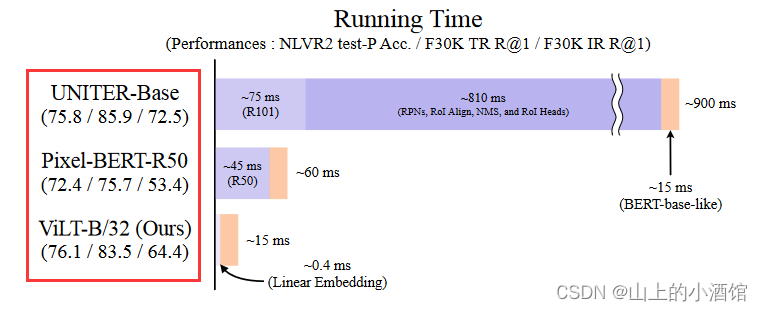
ViLT相对于使用目标检测或只用Backbone抽取特征的方法,速度快是毋庸置疑的,性能上也不差。例如在NLVR2 test-P 上准确率达到了76.1,是最高的。
? ViLT is the simplest architecture by far for a visionand-language model as it commissions the transformer module to extract and process visual features in place of a separate deep visual embedder. This design inherently leads to significant runtime and parameter efficiency.
? For the first time, we achieve competent performance on vision-and-language tasks without using region features or deep convolutional visual embedders in general.
? Also, for the first time, we empirically show that whole word masking and image augmentations that were unprecedented in VLP training schemes further drive downstream performance.
ViLT的三大贡献。一是最简单的架构,大部分精力都在多模态融合上,这种设计带来了运行时间和参数上显著的减少。二是,在减少计算复杂度的同时,保持性能很好,与使用区域特征(目标检测)和卷积网络达到相同的效果。三是首次使用了数据增强的方式whole word masking and image augmentations。多模态学习要考虑图像文本匹配的问题,数据增强可能会改变图像语义,因此前边的研究没有使用,但是本文发现使用了数据增强后效果不错。
2.背景知识
2.1VLP 的分类

作者根据两点对现在VLP的模型进行了分类,第一点看图像和文本的表达力度是否平衡,表达力度根据参数量和计算量来评价。二者都是很重要的模态,但是现在大多数方法更关注图像特征的抽取。第二点是讲如何将两个模态融合。具体分类如图二。
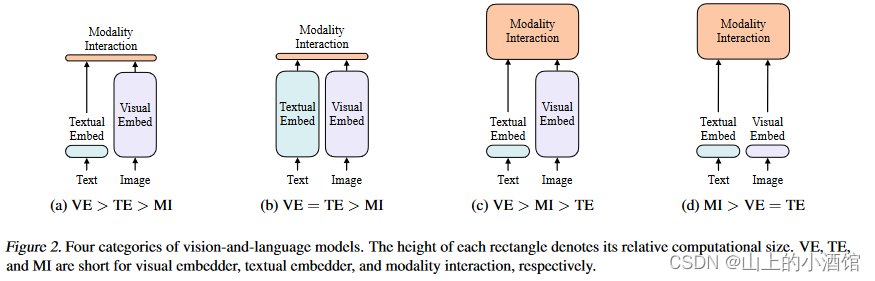
VE:Vision Embed??? TE:Text Embed?? MI:Modalities interact
第一类,如图a,代表作VSE,文本端较为简单,图像比较贵,融合端也是简单的神经网络。图b,CLIP为代表作,图像和文本的计算力度等价,融合的时候将两种特征直接点乘,非常轻量。图c,如ViLBERT、UNITER占据了大部分工作,文本端非常轻量。图像端使用目标检测的系统,非常贵。另外,融合端也使用了Transformer,相当于两个大模型。总结了前人工作,作者认为模态融合部分一定要做得比较大,融合做好了,最后的效果才能好。于是就直接基于ViT把patch embedding拿过来,视觉端抽特征也非常轻量。
2.2模态融合

主要有两点,一是signal-stream approaches。将两种特征拼接起来,用一个模型处理两个输入。
二是dual-stream approach。两个模型分别对两种模态信息进行处理,充分挖掘每种模态包含的信息,然后再融合。
两种模型表现差不多,但是dual-stream approach参数多一些,作者采用signal-stream approaches。
2.3视觉嵌入端
文本端都是用预训练的BERT里的tokenizer,而视觉端抽特征主要有三步:


?
主要看图像端,先经过一个Backbone抽取特征,然后经过RPN网络生成proposal,经过非极大值抑制nms筛选边界框,最后经过ROI head得到图像序列。结果就是把一张图像变成了离散的boundbox,每个边界框内都含有明确的类别语义信息。
再一种就是仅基于Backbone,但是这样的效果并不好。作者就基于ViT提出了自己的想法。直接将图像打成patch,然后根据patch得到图像序列,也含有语义信息。
3.方法部分
3.1模型架构
模型就是一个Transformer,比较简单
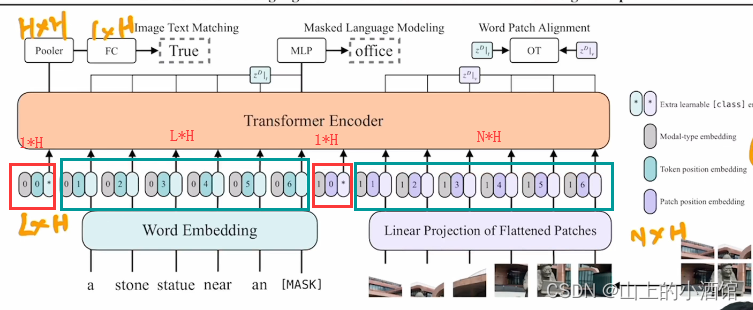
假设文本端有L个长为H 的序列,L为一个句子中单词数量,H为序列长度。图像端图像被打成N个patch,每个patch也对应长为H的序列。其中还加入了Modal-type embedding模态信息(文本为0,图像为1),Token position embedding文本位置信息,Patch position embedding图像位置信息。因此,Transformer Encoder的输入为(N+L+2)×H的矩阵。*代表[CLS] token,(N+L+2)×H 中2代表两种模态的[CLS]。位置嵌入和类别嵌入式拼接的。
文章使用了两个loss,分别是Image Text Matching和Mask Laguage Modeling。
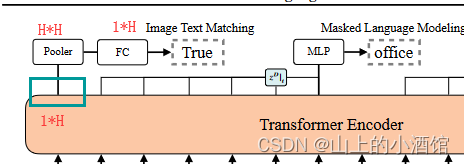
Transformer 的输出为[CLS]1*H的矩阵,经过H*H的pooler得到仍是1*H的矩阵,最后经过一个FC层进行二分类任务(文本与图像是否匹配)。
3.2技巧
Whole word masking。例如giraffe长颈鹿这个单词,由三个wordpiece组成,分别是gi,raf,fe,如果mask 的时候mask “raf”这个token。由于开头为gi结尾为fe的单词不多,模型就记住了中间一定是raf,就相当于模型学到了shortcut,这样泛化性就不好。因此作者直接mask“giraffe”整个单词。这样就需要借助图像信息,因此就加强了图像文本的联系。
Image Augmentation。之前的工作都是使用预训练模型,无法进行数据增强。此处的图像增强不适用color inversion和cutout避免与文本信息不匹配。
4.实验
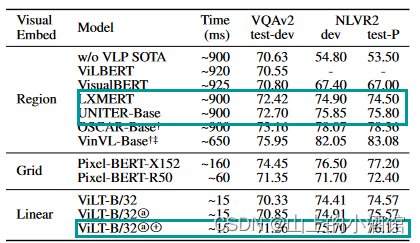
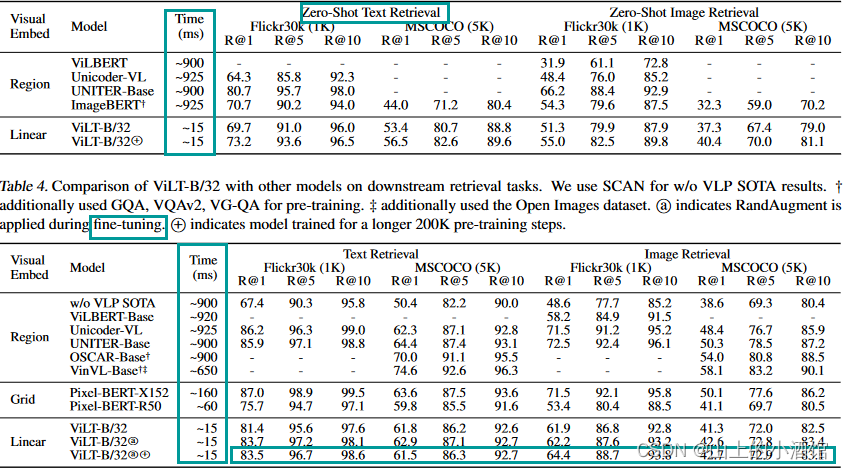
总结一下就是速度非常快,精度也不差。
5.结论
作者这里主要说使用了一个轻量的文本图像特征提取模型,就可以达到不错的效果。有三点可以提升性能:一是将模型规模做大,一般来说,Transformer规模越大效果越好。二是MAE的思想,在图像这边使用“完形填空”的形式。三是数据增强。
文章链接:http://arxiv.org/abs/2102.03334
参考:
ViLT 论文精读【论文精读】_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV14r4y1j74y?spm_id_from=333.999.0.0
https://www.bilibili.com/video/BV14r4y1j74y?spm_id_from=333.999.0.0