Bi-LSTM(Attention)
文章目录
1.理论
1.1 文本分类和预测(翻译)
文本分类的输入处理和预测(翻译)不同:
- 预测(翻译)通常用eye()把每个输入向量转换为one-hot向量,
- 但文本分类模型通常用Embedding初始化一个嵌入矩阵用来训练,不需要one-hot向量
1.2 注意力模型
1.2.1 Attention模型
注意力机制(Attention Mechanism)的本质是对于给定目标,通过生成一个权重系数对输入进行加权求和,来识别输入中哪些特征对于目标是重要的,哪些特征是不重要的;
为了实现注意力机制,我们将输入的原始数据看作<Key,Value>键值对的形式,根据给定的任务目标中的查询值Query计算Key与Query之间的相似系数,可以得到Value值对应的权重系数,即注意力权重,之后再用权重系数对Value值进行加权求和,即可得到输出.我们使用Q,K,V分别表示Query,Key和Value.
注意力机制在深度学习各个领域都有很多的应用.不过需要注意的是,注意力并不是一个统一的模型,它只是一个机制,在不同的应用领域有不同的实现方法。
- 注意力权重系数W的公式如下: W = s o f t m a x ? ( Q K T ) W=softmax?(QK^T) W=softmax?(QKT)
- 注意力权重系数W与Value做点积操作(加权求和)得到融合了注意力的输出:
A t t e n t i o n ( Q , K , V ) = W ? V = s o f t m a x ? ( Q K T ) ? V Attention(Q,K,V)=W?V=softmax?(QK^T)?V Attention(Q,K,V)=W?V=softmax?(QKT)?V
注意力模型的详细结构如下图所示:
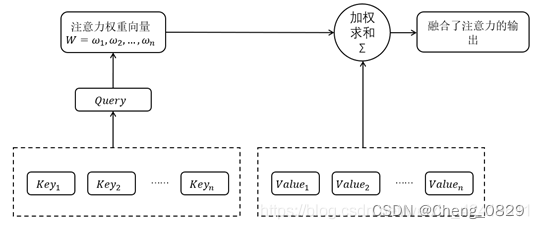
在本实验中,Query是指final_hidden_state,Key和Value都是指lstm_output,注意力权重W是指attn_weights
- 两个输入值用bmm()进行加权求和得到注意力权重attn_weights(由于final_hidden_state是一维的,所以不需要像seq2seq2中一样遍历时间步)
- 然后注意力权重attn_weights和lstm_output再进行用bmm()进行加权求和,得到context,即融合了注意力的输出(不同任务处理方式不同,Bi-LSTM文本分类不需要和Seq2Seq任务一样把context再和decoder_output进行combine和fc)
1.2.2 Bi-LSTM(Attention)模型结构
文本分类中的Attention结构:

2.实验
2.1 实验步骤
- 数据预处理,得到字典、样本数等基本数据
- 构建Bi-LSTM(Attention)模型,分别设置模型的输入
- 训练
- 代入数据
- 得到模型输出值,取其中最大值的索引,找到字典中对应的字母,即为模型预测的下一个字母.
- 把模型输出值和真实值相比,求得误差损失函数,运用Adam动量法梯度下降
- 预测
- 可视化注意力权重矩阵
2.2 算法模型
