一:硬件环境
深度学习模块训练运算量较大,依赖GPU进行加速,硬件需独立显卡支撑,目前训练只支持英伟达核心显卡。显卡硬件配置越高,训练及预测耗时越短。
1,模型训练:
? 本地训练
a) 6G及以上显存 DL单字符识别训练实现显存自适应,能根据硬件配置自动分配训练
显存,从耗时等综合因素考虑推荐采用6G及以上显存显卡训练,如GTX 1660Super,RTX 2080,RTX 3070等
b) 需去英伟达显卡驱动官网(https://www.nvidia.cn/geforce/drivers/),根
据电脑显卡型号下载451.22版本以上驱动
c) VisionTrain1.4(VM4.0)版本已支持30系列显卡训练(预测),以前版本不支持
d) 支持萤石云服务器训练
e) 支持本地云服务器训练
2,模型检测: ? 支持GPU版本检测 (需2G及以上显存。单DL模块2G显存可以满足,多DL流程或单流程多 DL模块需更大的显存)
? 支持CPU版本检测 (效果与GPU版本一致,检测耗时会比GPU版本长)
? 操作系统要求为Windows7或Windows10 (系统需要安装完整版,不能装裁切版)
? 图片的水平或垂直分辨率应大于32像素,小于20000像素
若显卡配置符合条件,发现无法进行训练或预测,则需检查显卡驱动,要求安装451.22版本以上显卡驱动(显卡驱动的要求和显卡本身以及VM的版本有关)
二:适用场景
DL目标检测是一种基于目标几何和统计特征的图像分割,它将目标的分割和识别合二为一,具备准确 性和实时性。尤其是在复杂场景中,可对多个目标进行实时处理,自动提取和识别目标,适用于物体的 识别、定位、分类等。目标检测要求目标最小像素占比在 2.5%以上,例:图片宽度为1280,则最小 目标要求占比≥32(1280*2.5%)像素。
三:DL 目标检测训练和测试
一)深度学习目标检测-模型训练:
1)打开 VisionTrain1.4.0训练工具

2)PC端:选择目标平台->VM平台(VM 平台训练的模型用于VM4.0.0 软件,SC 平台训练的模型用 于 SC 系列智能相机),选择训练类型->目标检测,点击下一步。
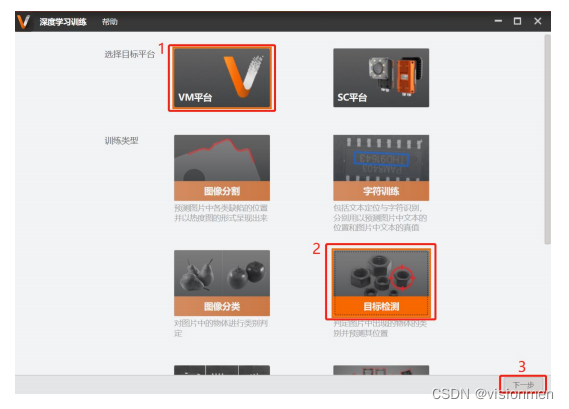
3)点击“新建训练集”,创建或选择训练样本,训练样本的绝对路径应当不包含空格(・注:将样本图
片放在一个文件夹中,便于后期增加样本以丰富训练集,训练集图片数量不能少于11张。)。
其中标定保存是在标定过程中,保存标定文件,建议经常性使用。而预标定通常是模型已经生成,在加
入新样本的时,通过先前的模型预测样本标签,提升打标的速度。
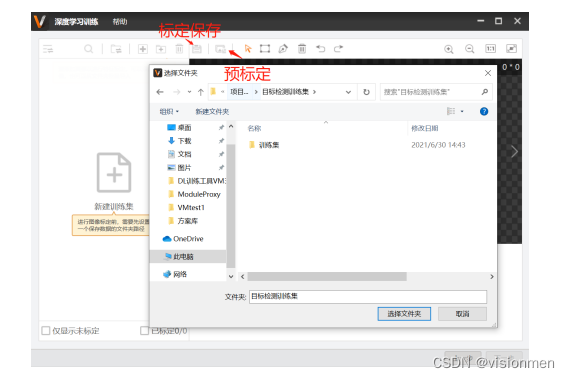
4)进入标定界面
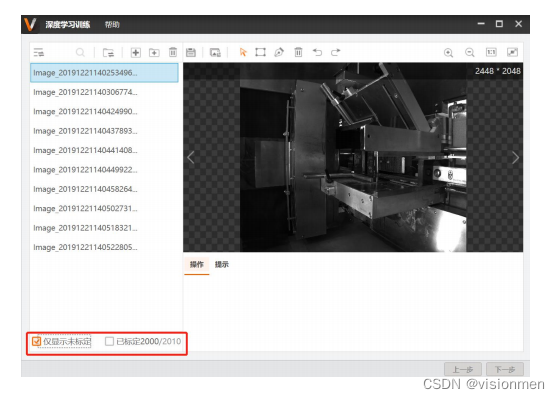
①左边到特定场景的图像时,在右边图像标签值中输入对应的标签,完成一张的标定后进入下一张。
②标注样本的数量根据实际项目需求与场景复杂度而定。若较为简单的场景可以先标注50张样本进行
测试。样本最好能有代表性,覆盖目标会出现的大部分情况。
③若目标为规则物体,则使用矩形标定工具,框住需要识别的目标,要求标注最小外接矩形框,紧贴目
标边缘标注,包围整个目标。若目标为不规则物体,则使用多边形标定工具。
④要求最少标定11张,否则无法点击下一步进行保存,标注过程中应经常性的点击标定保存,防止标
定数据消失。其中预标定功能通常是模型已经生成,在加入新样本的时,通过先前的模型预测样本标签,
提升打标的速度。
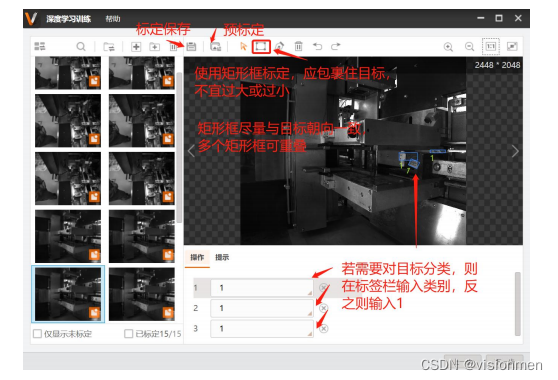
以药盒为例,以下举例了一些标注正确与错误的示范:
1.标签需包含目标整个部分,不能将部分特征遗漏。

2.标签需紧贴目标边缘,若为不规则物体,可以使用多边形标定工具。
3.标签可以标出图片外,训练时只训练在图片里面那部分。

4.肉眼难观察的样本,一定不能漏标注,最终模型性能主要体现在这种类型目标的检测效果上,漏标 会严重影响模型性能。

1)配置训练参数和训练
? 选择类型:本地训练-依赖本机显卡训练;云服务器训练-使用萤石云进行训练;本地服务器训练- 在本地架设的服务器上训练。
? 迭代轮次:算法内部称为Epoch,一轮就是将所有训练样本训练一次的过程。增大迭代伦次可以增
加训练的迭代次数。参数根据图片数量设置。30张设置700轮。100张设置500轮。500张设置
200轮。1000张设置150轮。5000张设置100轮。10000张设置60轮。100000张设置50轮。若
训练过程中曲线任有明显的下降趋势,可以暂停训练增大迭代轮次。
? 基础学习率:更新参数时前进的步长。一般按默认值1设置,不需改动。
? Patch大小:训练过程中,输入神经网络的图像尺寸。有大中小可供选择,对应的缩放分辨率为 608,416,288。目标占图片比例小则推荐选择大patch,占比大则可选择中或小patch。为了 保证效果建议选择大Patch。
? 模型能力:处理复杂图片的能力,有普通和高精度两种模式选择。普通训练、检测速度更快,消耗 的显存资源更小。高精度检测效果更加精确, 但资源消耗大。小目标、精度要求高推荐使用高精 度模式,大目标、精度要求较低推荐使用普通模式。 为了保证效果建议选择高精度。
? 角度能力:开启后可预测目标是否发生倾斜,检测框会随着目标角度而旋转。若不开启检测框呈0° 的矩形框。
? 版本:目前提供VM320、VM330、VM340、VM400四个版本模型训练。VM340版本模型能在VM3.4 及更高的VM版本如VM4.0上使用,VM400版本模型只能在VM4.0及更高的VM版本使用。
? 是否剪枝:开启剪枝使能后,能设置剪枝比例。根据设置的比例减小模型大小,缩短检测耗时,同 时也会损失一定的检测精度与增加训练耗时。若节拍满足不建议开启。
? 是否增强:开启增强使能后,可设置数据增强参数。可进行HSV空间变换、镜像、画布扩大、裁剪、 仿射变换、噪声这六类数据增强的操作。具体设置见“数据增强白皮书”。
模型生成位置:模型默认保存在VisionTrain1.4.0\Applications\DeepLearningModel里,
建议修改路径
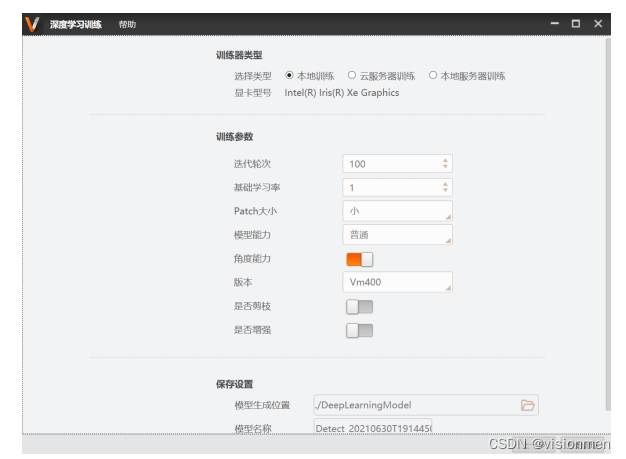
Patch设置、模型能力设置参考:

2)训练过程
参数设置完成后点击开始训练进行训练模型。
6.1 本地训练过程
依赖本地电脑显卡进行训练,若在测试中发现会出现误识别、漏识别与多识别的情况,可以尝试增
加训练样本、增大迭代轮次。
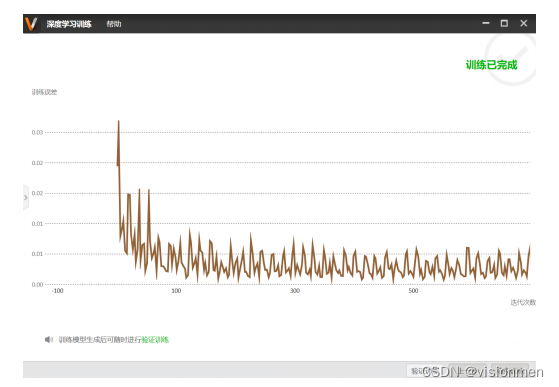
默认保存位置为:\VisionTrain1.4.0\Applications\DeepLearningMode 。确定好模型名
称后点击开始训练,随着迭代次数的增加,训练误差会越来越小,最后趋于平缓。当训练完成后点击结束 训练,在指定的文件夹位置会生成一个.bin 文件,该文件则是深度学习网络训练后得到的模型文件。
6.2 云服务器训练过程
暂不支持VM4.0.0版本的云服务训练,需切换为VM3.4.0。参数设置完成后点击开始训练,会显示 “训练集上传中”,在桌面生成一个训练集压缩包,上传完成后进行云训练,在提示时间内完成训练后会 在对应位置生成模型。
6.3 本地服务器训练过程
由我司专业人员通过组装性能极强的硬件设备,安装ubuntu系统、GPU训练所需驱动以及nvidia docker,并部署其他必须组件,帮助客户完成本地服务器的搭建。选择训练类型为本地服务器训练,训练流程与6.2相同。
二)深度学习目标检测-模型测试
(1)打开VisionMaster4.0.0,使用深度学习目标检测模块进行模型效果测试,将推演预测错误的图
片统一保存至训练集中,使用VisionTrain1.4.0重新标注之后,重新进行模型训练,此方法增加了样12
本容量,也是模型优化最直接有效的方式。・注:若效果不满足预期,可联系对应销售或技术进行技术指
导,优化模型。
在VisionMaster4.0.0中拉出一个图像源模块,点击右下角的将需要测试图片放入模块中。
(2)模块参数说明
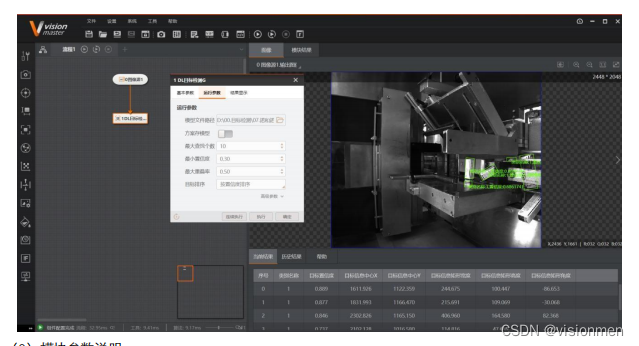
? DL目标检测G/C:其后缀的G/C代表以GPU或CPU进行预测。13
? 模型文件路径 :选择之前VisionTrain1.4.0训练生成的模型文件
? 方案存模型:在进行方案保存时是否保存当前加载的模型,默认关闭,打开后保存的方案文件 2.
大小变大,包含模型文件。
? 最大查找个数 :目标检测的最大查找目标个数
? 最小置信度 :定位框的最小得分
? 最大重叠率:目标图像允许被遮挡的最大比例
? 目标排序: 有按中心点 X/Y 坐标排序、按置信度排序
? 边缘过滤使能:
- 开启使能可设置最小边缘分数,若查找目标在边缘内的部分占整体的比例小于最小边缘分数,
则舍去该查找目标,界面端不做显示,如图一所示; - 关闭使能后位于边缘处的目标均可被显示,如图二所示;
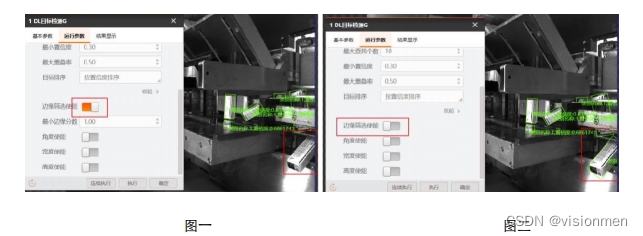
? 角度使能 : 设置目标的相对角度范围忍值,若要搜索有旋转变化的目标则需要对应设置,默认范 围-180°~180°。
? 宽度/高度使能 :宽度/高度在该范围内的目标才可能被检测到
四:系统运行过程中继续添加样本的方法
在系统运行过程中,通常训练的模型不能一次到位,适用于所有的场景,需要在运行过程中不断添
加样本,增强模型的鲁棒性。方法是: - 之前训练集(包括原图和DetectTrainData.txt文件)不能删除,新采集或模型误检的原图
样本应放到之前的样本中去。
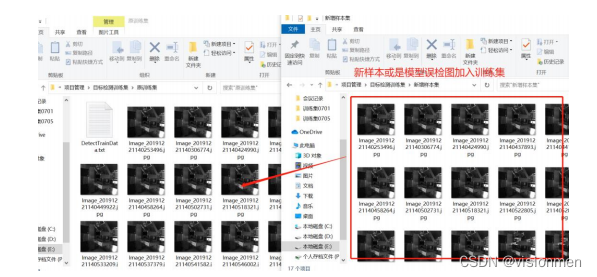
- 对增加样本后的新训练集做二次标定。之前标定的数据还保存在样本的文件夹中,把新采集的
样本再标定好,重新训练模型。训练参数参考以上说明。