
🤵?��? ������ҳ: @�����ħ��ʦ
👨?💻 �����:CSDN���ݺϻ���,ȫջ�������ʴ����ߡ�
��������¼ר��
?�� ����ѧϰ ��?
������ѧϰ��logistics����
һ�����Իع������ڷ�����?
l o g i s t i c logistic logistic(������)�ع��㷨(Ԥ����ɢֵ y y y �� �dz����õ�ѧϰ�㷨
���������µİ˸���( y = 1 �� 0 ) y=1 �� 0) y=1��0),������Ҫ����һ��ģ�͵õ�ȷ���ж�,��ôӦ�����ʵ����
- ���dz���ʹ��֮ǰ������ѧ�����Իع� h �� ( x ) = �� T ? x h_\theta(x) = \theta^T*x h��?(x)=��T?x ���������( �� \theta ���Dz���������,ע������� x x x�ǹ��� x i x_i xi?������,���� x 0 = 1 , �� x 0 ? �� 0 = ������ x_0=1, �� x_0*\theta_0 = ������ x0?=1,��x0??��0?=������),����0~1����һ����ֵ y = 0.5 ����Ӧ�� x 0.5 ֵ y = 0.5 ����Ӧ�� x_{0.5} ֵ y=0.5����Ӧ��x0.5?ֵ, x x x ���� x 0.5 x_{0.5} x0.5? �ĵ���Ϊ1,����Ϊ0,Ԥ���õ�������˿ֱ��,
��һƪ����: ������ѧϰ��dz̸���淽�̷�&�ݶ��½�
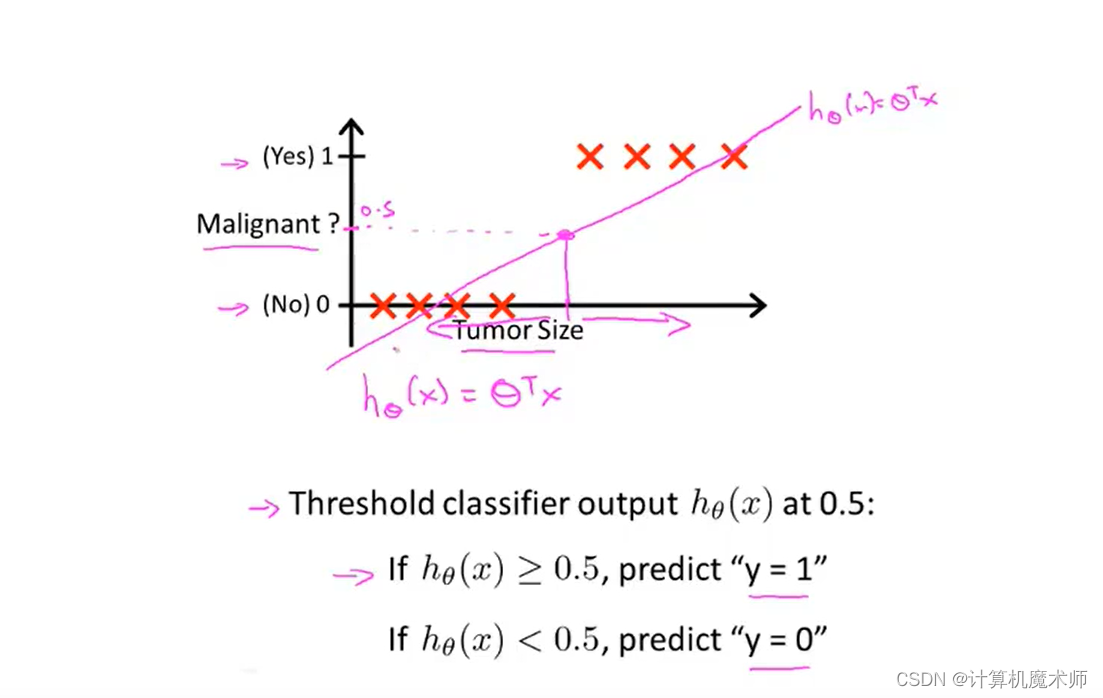
��������������һ�����ݵ�,����ͼ�ҷ�,���������㷨��Ӧ�����ֱ��
h
��
(
x
)
h_\theta(x)
h��?(x)��������ɫֱ��,��ʱ�õ������Ԥ�� (���ڽ��Ϊ1ҲС��
x
0.5
x_{0.5}
x0.5?)
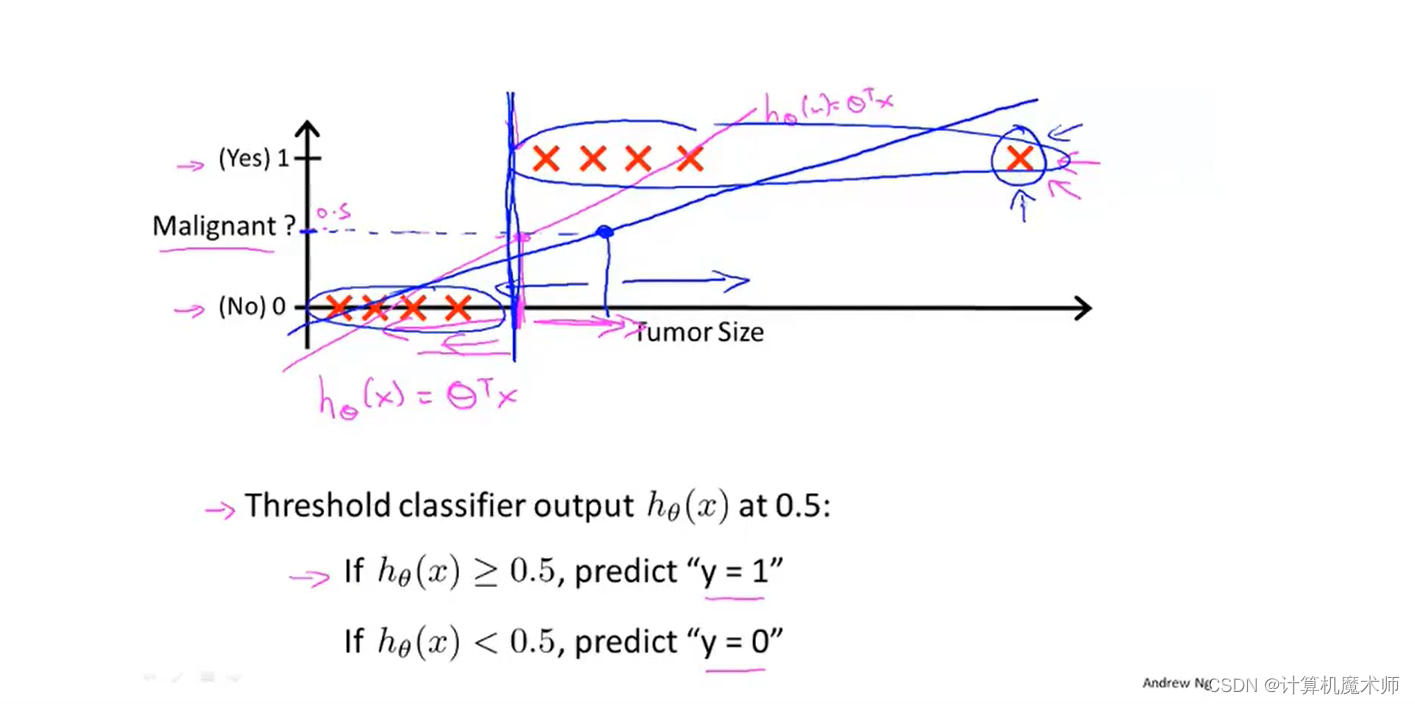
������������,�����Իع������ڷ�������ͨ������һ��������,�������Իع��ֵ��ԶԶƫ��0��1,����ʾ��̫������
�����ݶ��½��㷨������ logistic regression �㷨
������Ԫ����
2.1���躯��
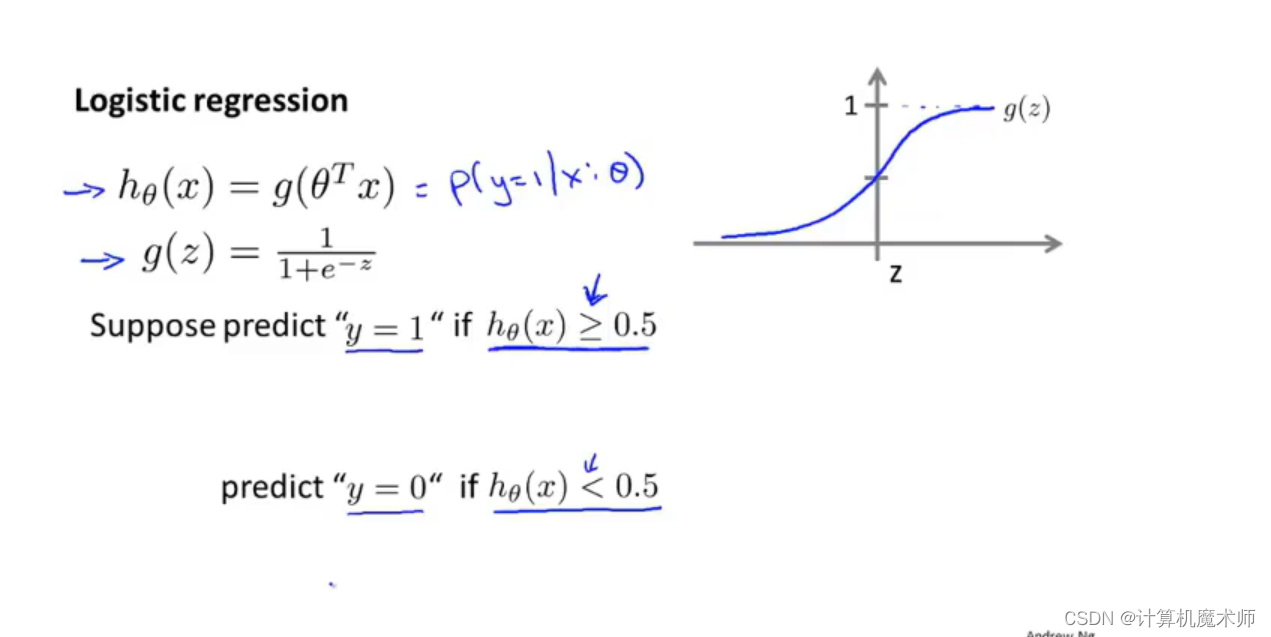
����ϣ���ܰ� h �� ( x ) = �� T ? x h_\theta(x) = \theta^T*x h��?(x)=��T?x ����� 0 ~ 1 ֮��,
�������� s i g m o i d sigmoid sigmoid ���� (Ҳ���� l o g i s t i c logistic logistic ����) ���� g ( x ) = 1 1 + e ? x g(x) = \frac{1}{1 + e ^{-x}} g(x)=1+e?x1?
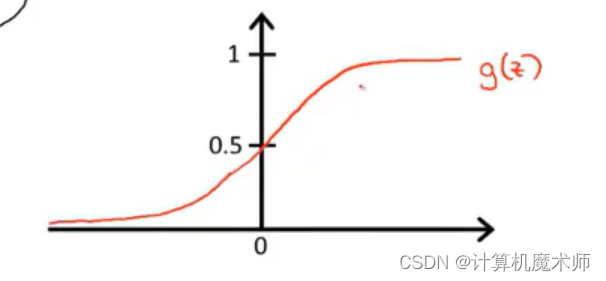
s i g m o i d sigmoid sigmoid����ͼ����һ�������� 0 ~ 1��S�ͺ���, x ? �� x \Rightarrow\infty x?���� y ? 1 y\Rightarrow1 y?1, x ? ? �� x \Rightarrow-\infty x??���� y ? 0 y\Rightarrow0 y?0
- ��
h
��
(
x
)
=
g
(
��
T
?
x
)
=
1
1
+
e
?
��
T
?
x
h_\theta(x) =g( \theta^T*x) = \frac{1}{1 + e ^{- \theta^T*x}}
h��?(x)=g(��T?x)=1+e?��T?x1?
��ô���ǵĺ����������ͻ���0 ~ 1 ֮��
������������Ҫ���ı�����Ҫ��ò��� �� \theta �� ���ģ��
����ͼ,������������,���� x x xΪһ������ ͬ��������������ʾ x x x�IJ���,��ô����һtumorSize���������Ĵ�С,��ô���ǿ��Լ���������Ϊ 0.7 ,��˼����ҽ�������������˺ܲ���,���кܴ�(70%)�ĸ��ʵõ�������
- ��ô��ʽ���Ա�ʾΪ h �� ( x ) = P ( y = 1 �O x ; �� ) h_\theta(x) = P(y=1|x;\theta) h��?(x)=P(y=1�Ox;��)
- ���� x x x�������� ����� y y y (���ʲ���Ϊ �� \theta ��)�ĸ���

��ô��
y
y
yֻ�� 0 �� 1 �������,�����¹�ʽ (����Ϊ�����¼�,����ȫ���ʹ�ʽ)
- P ( y = 1 �O x ; �� ) + P ( y = 0 �O x ; �� ) = 1 P(y=1|x;\theta)+ P(y=0 |x;\theta)= 1 P(y=1�Ox;��)+P(y=0�Ox;��)=1
- 1 ? P ( y = 0 �O x ; �� ) = P ( y = 1 �O x ; �� ) 1 - P(y=0 |x;\theta)= P(y=1|x;\theta) 1?P(y=0�Ox;��)=P(y=1�Ox;��)
���ʽ��ֻ��0 ~ 1��
- ��������
��ô��ʱ���ǿ���������ֵ g ( z ) g(z) g(z) = 0.5,���� 0.5 �ĵ���Ϊ1,����Ϊ0
���� z < 0 z<0 z<0(�� �� T ? x \theta^T*x ��T?x)�� g ( z ) g(z) g(z)< 0.5, ��ʱԤ��Ϊ0,�� z > 0 z>0 z>0(�� �� T ? x \theta^T*x ��T?x) ʱ, g ( z ) > 0 g(z)>0 g(z)>0 Ԥ��ֵΪ1
2.1.1 ����һ
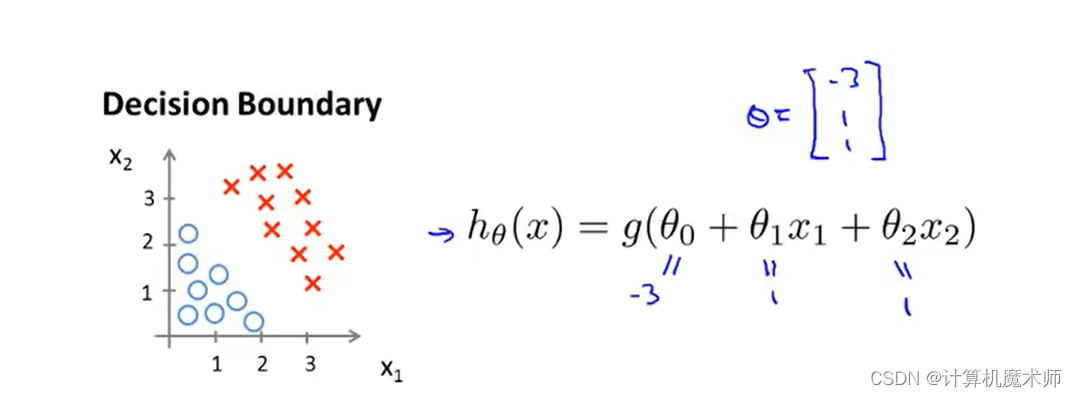
���Ǽ������ĸ���
��
\theta
�� ������������Ϊ-3,1,1
��ʱ�������
g
(
z
)
g(z)
g(z)> 0.5 , Ҳ���Ǻ�����
z
z
z(�����
z
z
z �Ƕ�Ӧ���Է���) ������,Ԥ�� y Ϊ 1 ����������:
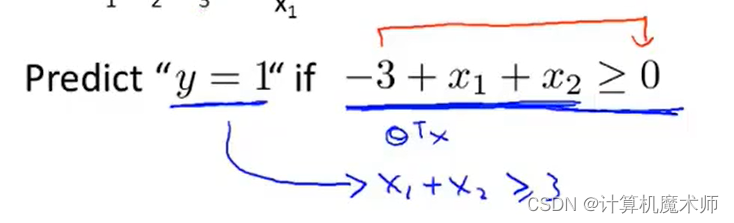
��������
x
1
+
x
2
>
=
3
x_1 + x_2 >=3
x1?+x2?>=3 , �����������Ӧ�ļ�������:
��һ���и��ߵ��Ҳ�,��ʱ
s
i
g
o
m
i
d
������
z
����
>
0
sigomid������z����>0
sigomid������z����>0 , yֵ ����0.5
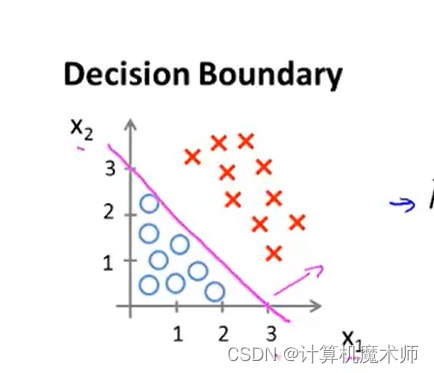
��ʱ���и��߷ָ������������,�ֱ���
y
=
0
��
y
=
1
y=0 �� y=1
y=0��y=1�� ���,���ǰ������߽�,��Ϊ���߽߱�,��Щ���ǹ��ڼ��躯��������,�����������,�����ݼ�������

2.1.2���Ӷ�
�����ݼ�����:
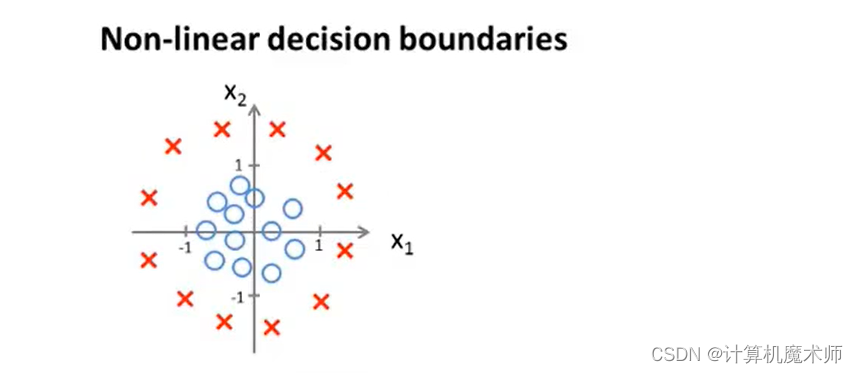
���Ǽ��躯��Ϊ����ʽ�߽���,������������踳ֵ���¡�
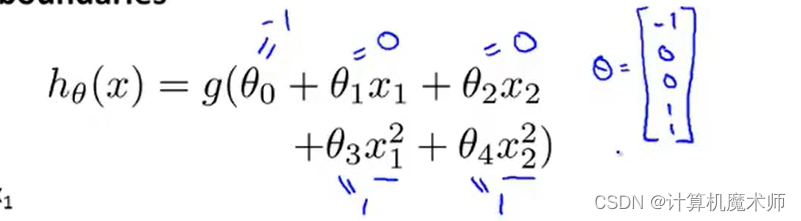
�����ǵ�Ԥ��y=1ʱ,
s
i
g
o
m
i
d
sigomid
sigomid������
z
z
z��������Ϊ
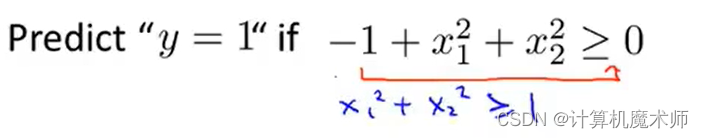
���Եõ������߽߱�decision boundory ����
x
1
2
+
x
2
2
=
1
x_1^2+x_2^2 =1
x12?+x22?=1
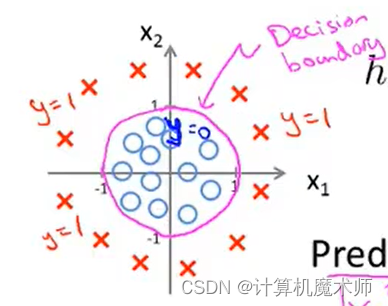
- ǿ��: ���߽߱粢�������ݼ�������,�������躯���Լ������������,���ݼ�����������ϲ���
��
\theta
��
��ͬ�ĸ߽���ʽ ��õ���һ���ľ��߽߱�
��:
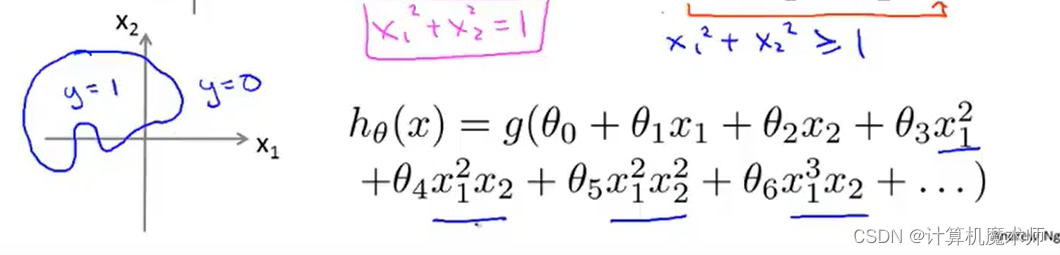
2.2 ���logistic�ع���� �� i \theta_i ��i?
- ���ۺ���
���Ǹ��������ݼ�
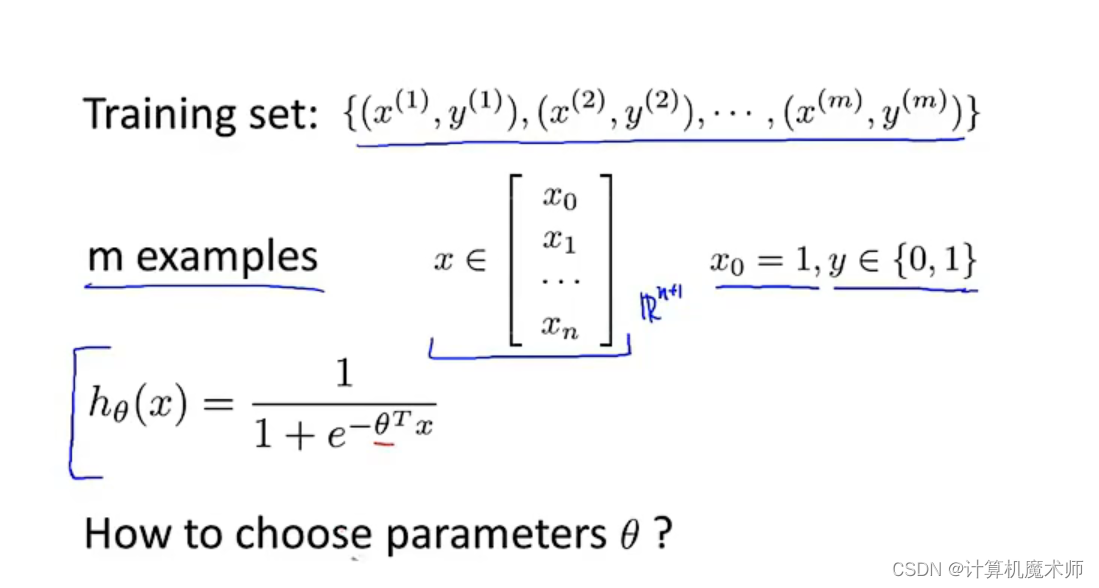
��
m
m
m������,ͬ����ÿһ��
x
x
x��
n
+
1
n+1
n+1ά������ʾ(����ÿ��Ԫ�ؼ�����,����
x
0
Ϊ
1
x0Ϊ1
x0Ϊ1 ) �����ǩ
y
y
yֻ�� 0,1���
- ��ô�������ѡ����� �� \theta ����?
����ƪ�������������Իع����������ۺ������Ա仯����:

����,����ʡ���ϱ�
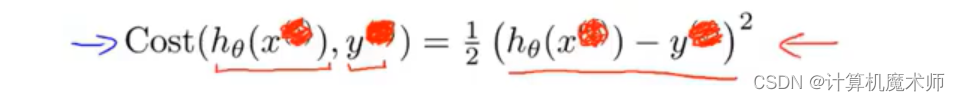
��Ϊ
s
i
g
o
m
i
d
sigomid
sigomid �Ǹ��ӵķ����Ժ���,���ֱ���Ժ�����Ϊ���ۺ���,��ô����ģ�Ͷ�Ӧ���ۺ���Ϊ�ǰ�����,���зdz�����ֲ�����,����ͼ
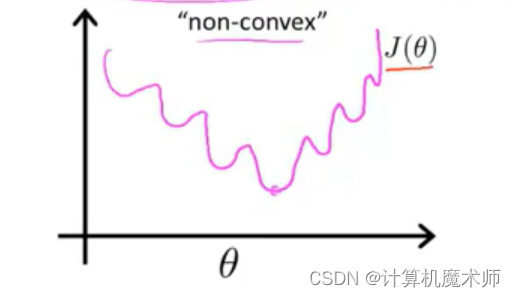
���Dz��ܱ�֤������½�����������
��������ϣ���ҵ����µİ��ʹ��ۺ���,�Կ����ҵ��������š�
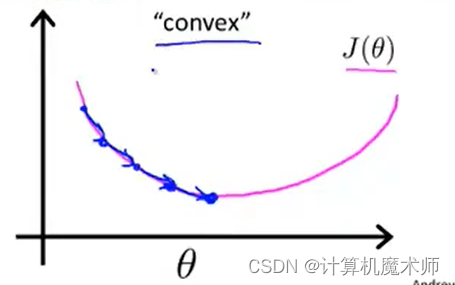
��������Ҫ�ҵ�����Ĵ��ۺ�����֤���ǿ����ҵ�ȫ����Сֵ
����logistic���ۺ���

3.1 �� y = 1 y=1 y=1���ۺ���ͼ��
�Ը����ۺ���,���ǿ��Ի�����
y
=
1
y=1
y=1ʱ��ͼ��(����
s
i
g
o
m
i
d
sigomid
sigomid ����ֵ����0~1,��Ӧ���ۺ���������Ϊ0 ~1)
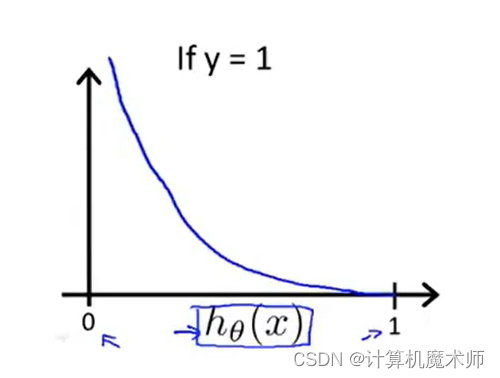
Ϊ�˷����������ǿ��Ի���,����������ͼ��
l
o
g
(
z
)
log(z)
log(z) (
z
=
h
��
(
x
)
)
z = h_\theta(x))
z=h��?(x)) )
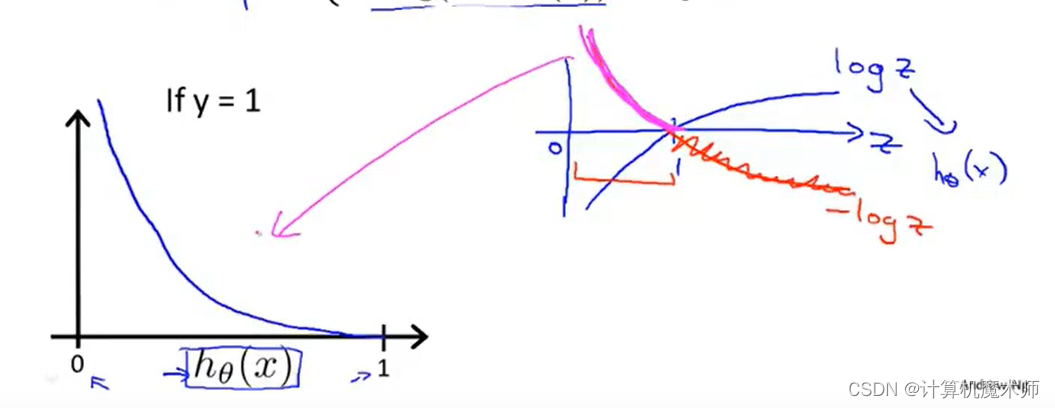
- ��ͼ������Ҳ���Կ�����Ϊ���ۺ��� �ܺõ�����
-
�� C o s t ? 0 Cost \Rightarrow 0 Cost?0ʱ,�����ۺ���Ϊ0,��ʱ�� h �� ( x ) ? 1 h_\theta(x)\Rightarrow1 h��?(x)?1 ��ģ���������
-
�� C o s t ? �� Cost \Rightarrow\infty Cost?��ʱ,�����ۺ��� ? �� \Rightarrow\infty ?��,��ʱ h �� ( x ) ? 0 h_\theta(x) \Rightarrow 0 h��?(x)?0��Ϊ ����ʱ˵��ģ����Ϸdz���
��Ȼ�� y = 1 y=1 y=1 ʱ ������ۺ����������ǵ�Ҫ��

3.2 �� y = 0 y=0 y=0���ۺ���ͼ��
��Ӧ
y
=
0
y=0
y=0�������:
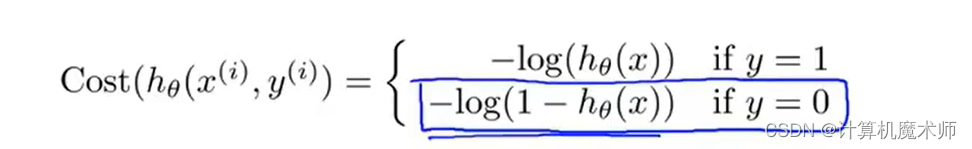
- ����ͼ
-
�� C o s t ? 0 Cost \Rightarrow 0 Cost?0ʱ,�����ۺ���Ϊ ? 0 \Rightarrow0 ?0,��ʱ�� h �� ( x ) ? 0 h_\theta(x)\Rightarrow0 h��?(x)?0 ��ģ���������
-
�� C o s t ? �� Cost \Rightarrow\infty Cost?��ʱ,�����ۺ��� ? �� \Rightarrow\infty ?��,��ʱ h �� ( x ) ? 1 h_\theta(x) \Rightarrow 1 h��?(x)?1��Ϊ �������ͷ��ܴ�
ͬ���ķ��ϴ��ۺ�������
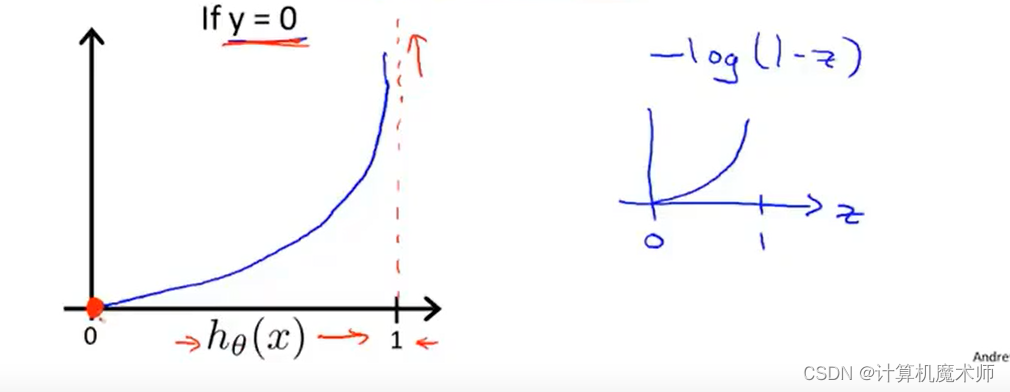
����,���Ƕ����˹��ڵ��������������ķ������ۺ���,������ѡ������ۺ�������Ϊ���ǽ�����ۺ���Ϊ�ǰ������������Լ�����������,����������ʹ���ݶ��½��㷨����� l o g i s t i c logistic logistic �㷨
�ġ� ���ۺ������ݶ��½�
Ϊ�˱����ô��ۺ�����Ϊ y = 1 , y = 0 y = 1,y= 0 y=1,y=0������� ,����Ҫ��һ����������������ʽ�Ӻϲ���һ����ʽ,�Ա����д�����ۺ���,���Ƶ����ݶ��½���
��ʽ����ͼ��ɫ���幫ʽ:

���� y ֻ��������� 0,1 ,���ø����� ��y = 1 ʱ,y=0����Ķ���ʽ��ȥ,y = 0 ʱͬ��,�����ͳɹ����������ֲ�ͬ����ĺ���
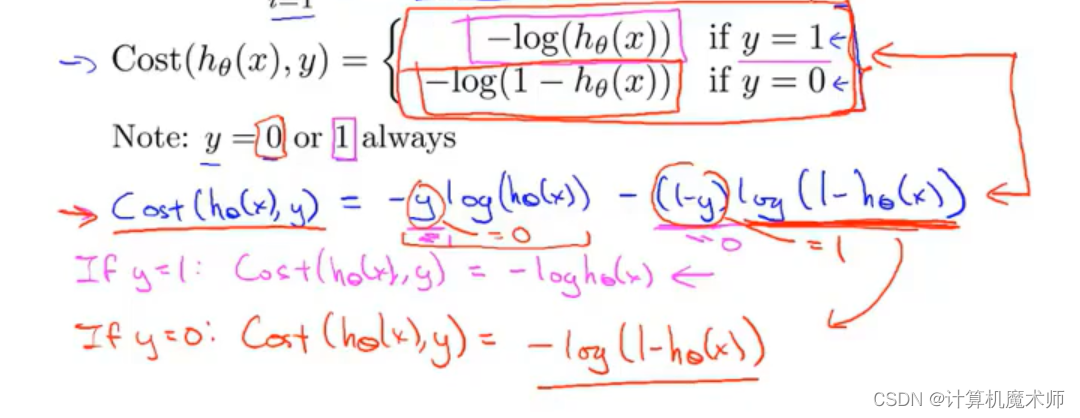
- ͨ����ʽ�Ӻϲ�Ϊһ����ʽ,���ۺ���(cost function) �仯Ϊ����(�ο�:ͳ��ѧ��������Ȼ��:
Ϊ��ͬģ����֪����Ѱ�Ҳ����ķ���,��ѡȡ�������IJ���)
�����Ȼ�����ο�����

ͬ��,����Ϊ������С�����ۺ�������ϲ���
��
\theta
��,ʹ���ݶ��½�

- ͬ��,����������ƫ��

- ���ô˹�ʽ����ÿ������ (ע����:ͬ������)

4.1 ���Իع���logistic�ع���ݶ��½�����
���ǿ��Ծ���ķ������Ϲ�ʽ�����Իع�ʱ�������ݶ��½��ķ���һ��
��ô���Իع��logistic�ع���ͬһ���㷨��?
���Իع��logistic���ݶ��½����µĺ�����������: h �� ( x i ) h_\theta(x^i) h��?(xi)
- �������Իع� : h �� ( x ) = �� T ? x h_\theta(x) = \theta^T*x h��?(x)=��T?x
- ����logistic�ع�: h �� ( x ) = 1 1 + e ? �� T ? x h_\theta(x) = \frac{1}{1 + e ^{- \theta^T*x}} h��?(x)=1+e?��T?x1?
��Ȼ���ݶ��½��㷨������������ͬ,������Ķ��巢���˱仯,�����ݶ��½���logistic�ع�����ȫ��һ�����㷨
- �����ô��㷨���¸�������,����ͨ��for����ʵ��,Ҳ����ͨ������������ʵ�֡�
����������,���Բο����� ������ѧϰ������������ �C ����ѧϰ·�ϱؾ�·

ͬ����,�ڶ������Իع���ݶ��½���,����ʹ�õ��������������ݱ���,ͬ����,�����
l
o
g
i
s
t
i
c
logistic
logistic �ع��㷨ͬ�����á�
���ݱ����ɲο�����: ������ѧϰ���ݶ��½�֮���ݱ���
�塢���Ż��㷨
���Ż��㷨,���ݶ��½�����ܹ�������
l
o
g
i
s
t
i
c
logistic
logistic �ع��ٶ�,Ҳʹ���㷨�����ʺϴ������ݼ�����ѧϰ���⡣
����ʹ���ݶ��½��㷨,������������㷨

�ŵ�����
- ����Ҫѡ��ѧϰ�� �� \alpha �� ( ����������ѭ��,����ѡ����ѵ�ѧϰ�� �� \alpha ��
- �½����ʿ�ö�
ȱ��
- ̫���ڸ�����
��ʵ�ʽ��������,���Ǻ���ͨ���Լ���д������ƽ���������������,������������ʹ�ñ���д�ĺõ����ݿ�ѧ��,��numpy
����������(����������)

���ǿ���ͨ���ݶ��½�����ò���,������ƫ��:

octave����ʵ������;
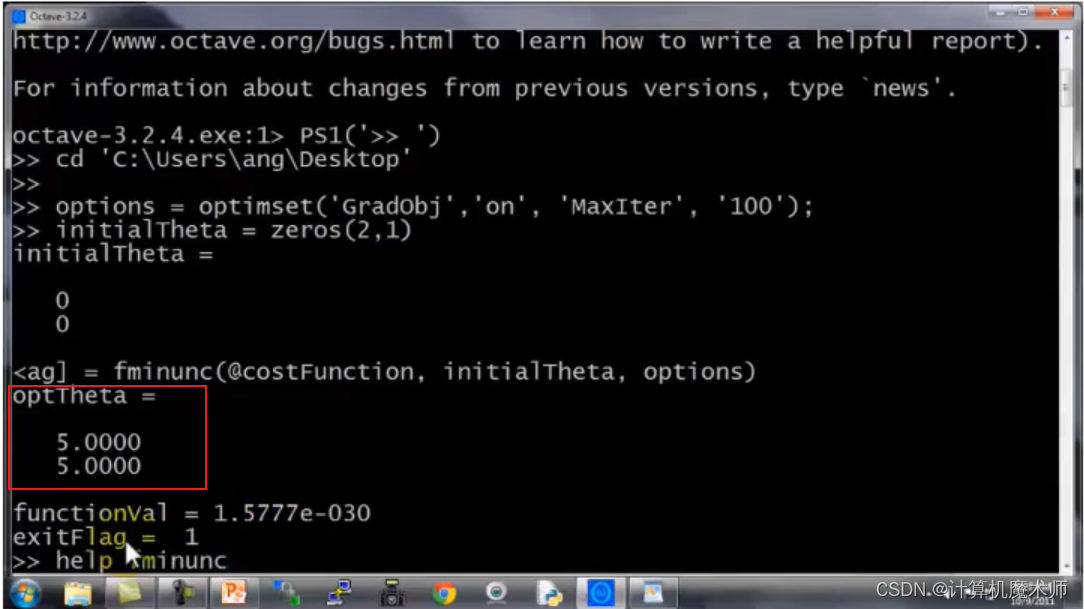
����һ���Ķ��δ��ۺ���,����������ν�������logistic�ع��㷨����?
��logistic�ع���,����ʹ�����µ�
��
\theta
���������� (ʹ�ò���������)

������ʵ����Щ���㷨,��ʵ��ʹ�ò�ͬ�ĸ��⺯��,��Ȼ��Щ�㷨�ڵ��Թ�����,�����鷳,�������ٶ�ԶԶ�����ݶ��½�,������Ի���ѧϰ������,����ʹ����Щ�㷨��
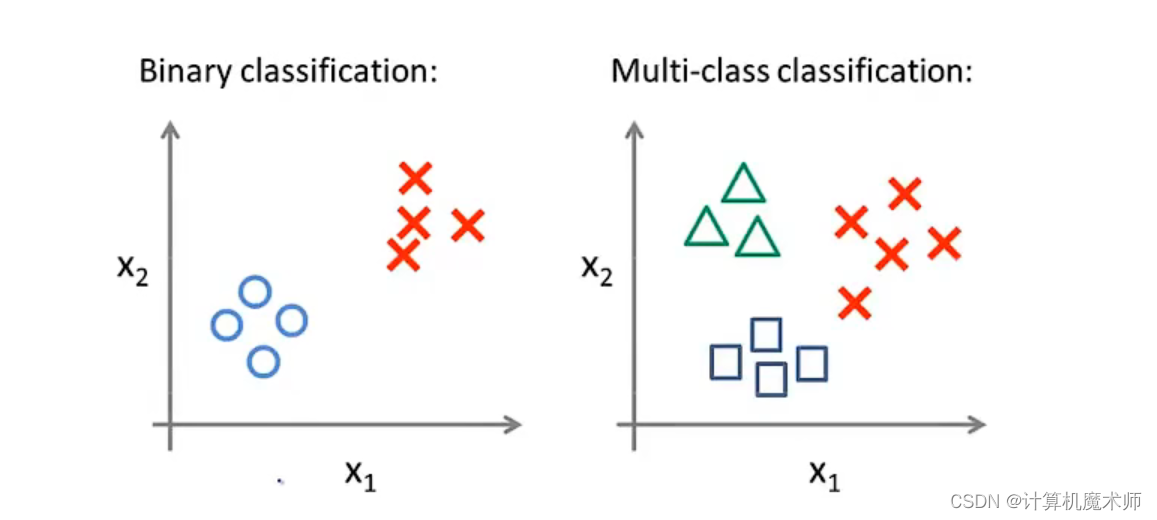
������Ԫ����:һ�Զ�
���罫�ʼ���Ϊ����,����,ͬ�¡����罫��������,����,����ȡ����ǿ��Խ���Щ������0,1,2����,������Щ������������
�������ͼ��ͬ(��ͼ)
����,���ǽ������ݼ�����Ϊ����
����Ҫ���ľ��ǽ������ݼ�ת��Ϊ���������Ķ�Ԫ��������, ���ǽ�����һ���µ�**��α��ѵ����**,�����ڶ��������Ϊ����,��һ��Ϊ����(����ͼ�Ҳ�)
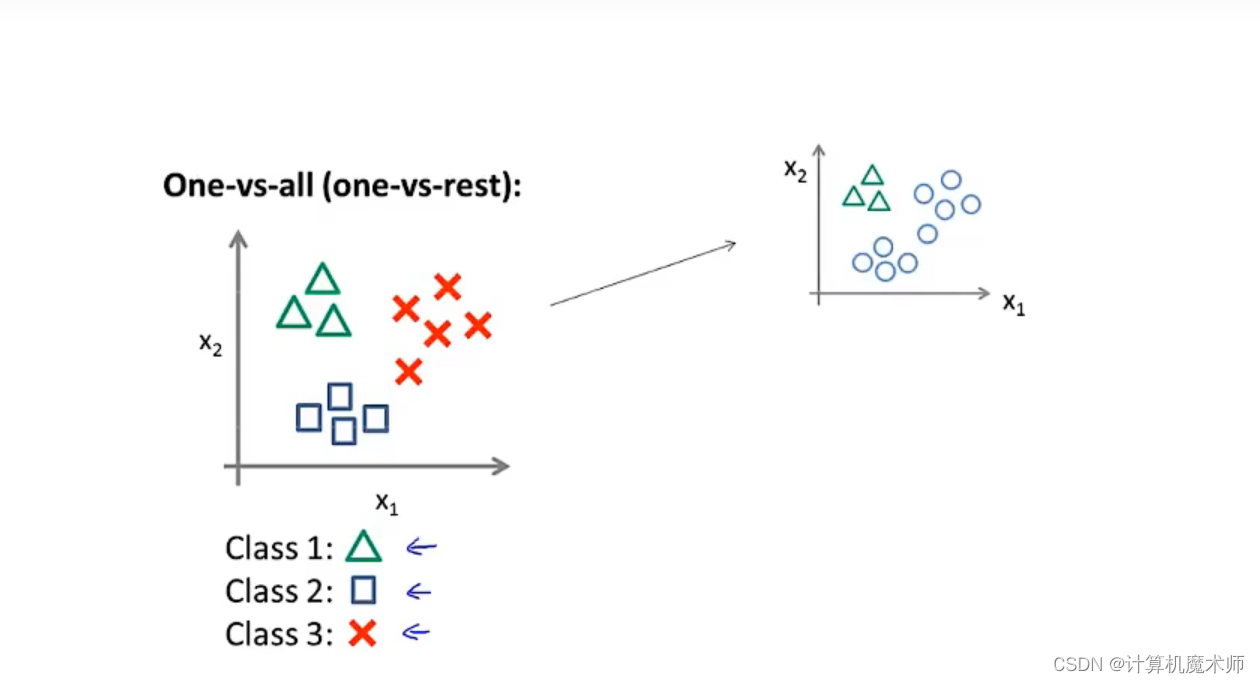
�����һ��������
h
��
1
(
x
)
h_\theta^1(x)
h��1?(x),������������ʵ��һ���������ع������,ͨ��ѵ��,���ǿ��Եõ�һ�����߽߱�
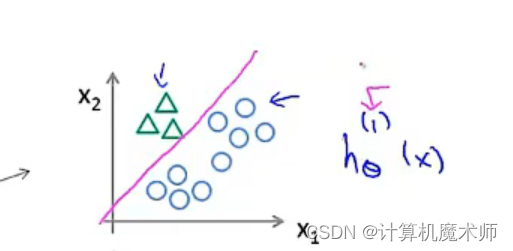
- ͬ��,����������������������
α���ݼ�,�Լ���Ӧ����Ϸ�����,����һ���������ع������,�õ���Ӧ�߽�

�ܶ���֮,������ϳ�������������
h �� i ( x ) = P ( y = i �O x ; �� ) ( i = 1 , 2 , 3 ) h_\theta^i(x) = P(y=i|x;\theta) (i=1,2,3) h��i?(x)=P(y=i�Ox;��)(i=1,2,3)
ÿ������������Ӧ��֮�����ѵ��,y = 1, 2, 3 �����
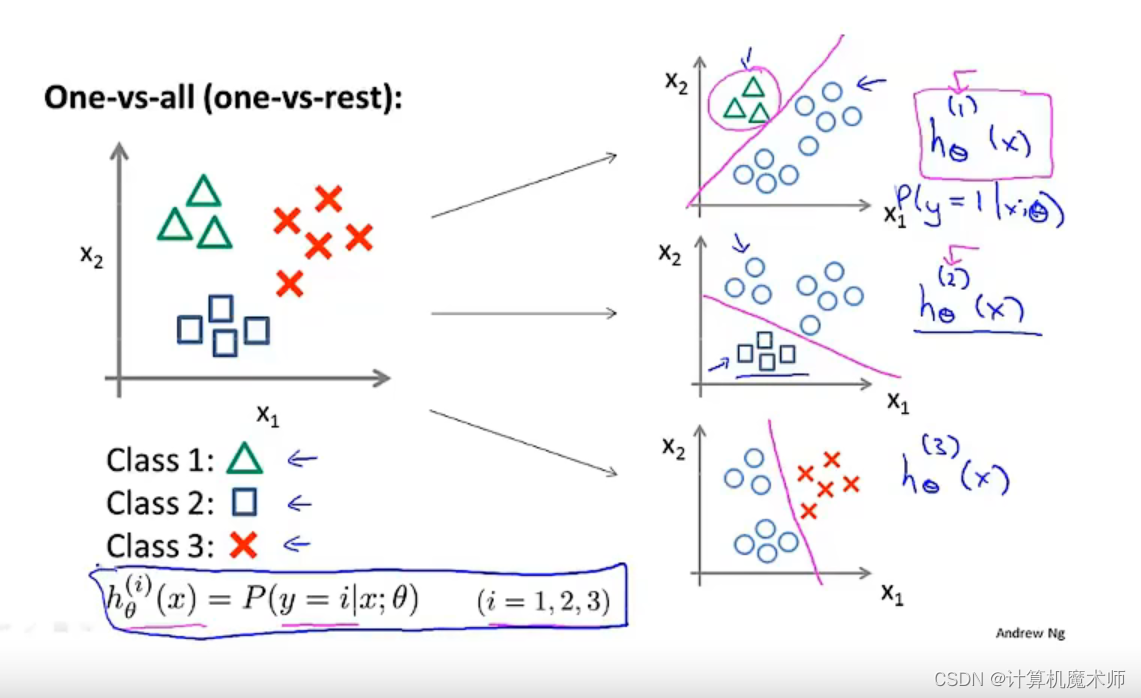
����ѵ�������ع������ h �� i ( x ) = P ( y = i �O x ; �� ) ( i = 1 , 2 , 3 ) h_\theta^i(x) = P(y=i|x;\theta) (i=1,2,3) h��i?(x)=P(y=i�Ox;��)(i=1,2,3),����Ԥ�� y = i y= i y=i �ĸ���,Ϊ������Ԥ��,���������������һ�� x x x,�������Ԥ��,������Ҫ���������ع���������������� x x x,ѡ������и�������һ��(�����)���Ǹ�������,��������Ҫ�����