论文名称:
AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
论文下载:https://arxiv.org/abs/2010.11929
原论文对应源码:https://github.com/google-research/vision_transformer
Pytorch实现代码: pytorch_classification/vision_transformer
Tensorflow2实现代码:tensorflow_classification/vision_transformer
在bilibili上的视频讲解:https://www.bilibili.com/video/BV1Jh411Y7WQ
相关工作
受NLP中Transformer可扩展性的成功的启发,本文尝试将标准Transformer直接应用于CV领域,并进行尽可能少的修改。为此,我们将图像分割为多个补丁,并提供这些补丁的线性嵌入序列作为Transformer的输入。图像补丁在NLP应用程序中的处理方式与令牌(词)相同。我们对模型进行了有监督的图像分类训练。
方法-ViT
尽可能遵循原始的Transformer:
可伸缩的NLP Transformer体系结构――及其高效的实现――几乎可以开箱即用。
整体结构
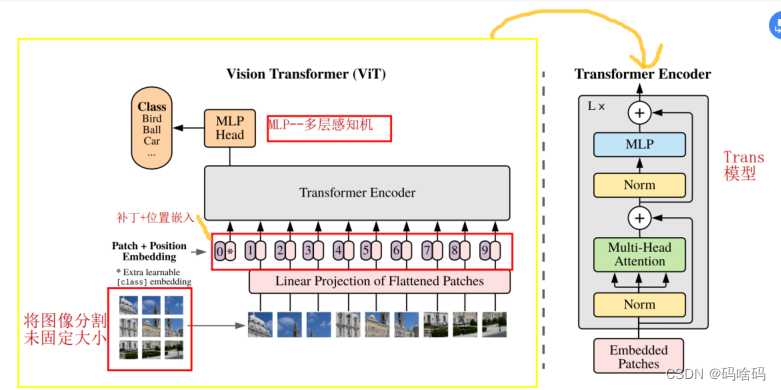
模型概述。ViT将一个图像分割成固定大小的patch(16x16), 线性嵌入每个patch,添加位置嵌入,并将得到的向量序列提供给一个标准的变压器编码器。为了进行分类,我们使用在序列中添加额外可学习“分类标记”的标准方法
原论文中给出的关于Vision Transformer(ViT)的模型框架。模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层)
- Transformer Encoder(图右侧有给出更加详细的结构)
- MLP Head(最终用于分类的层结构)
ViT 算法结构扩展图
图源,此图是以ViT-B/16为例的
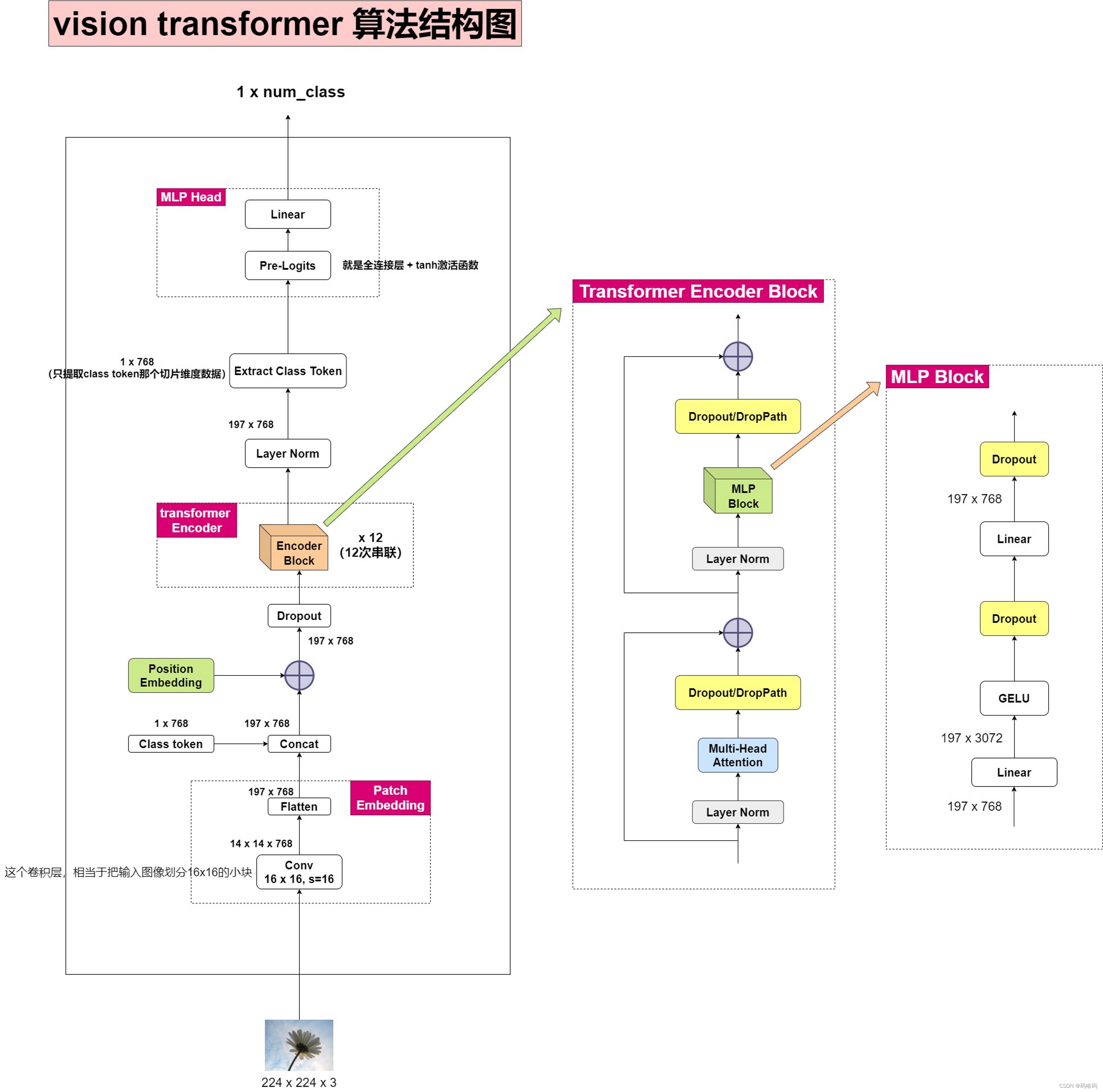
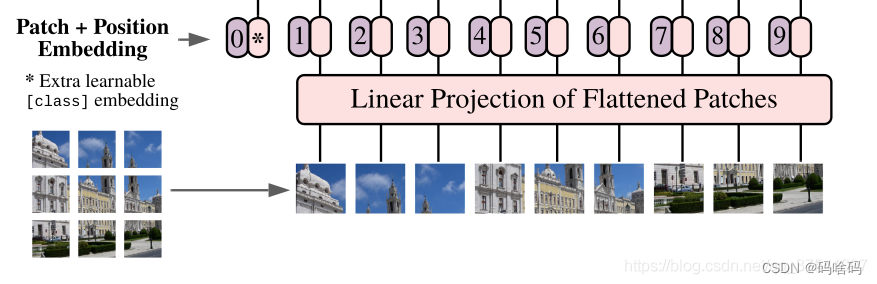
Embedding层
标准 Transformer ,要求输入是token(向量)序列,即二维矩阵[num_token,token_dim]。为处理 2D 图像,我们将图像 x ∈ R H × W × C x \in R ^{H \times W \times C} x∈RH×W×C 为一个展平 (flatten) 的 2D 块序列 x p ∈ R N × ( P 2 ? C ) x_p \in \mathbb{R}^{N \times (P^2 \cdot C) } xp?∈RN×(P2?C),其中 ( H , W ) (H, W) (H,W)是原始图像的分辨率,C 是通道数 (RGB 图像 C = 3 C = 3 C=3), ( P , P ) (P, P) (P,P)是每个图像块的分辨率, N = H W / P 2 N = HW / P^2 N=HW/P2 是产生的图像块数,即 Transformer 的有效输入序列长度。Transformer 在其所有层中使用恒定的隐向量 (latent vector) 大小 ,因此我们将图像块展平,并使用可训练的线性投影 (FC 层) 将维度 p 2 ? C p{^2・C} p2?C映射为 D维,同时保持图像块数 N不变 (等式 1)。此投影输出称为 图像块嵌入 (Patch Embeddings) (本质就是对每一个展平后的 patch vector 做一个线性变换 / 全连接层 ,由 p 2 ? C p{^2・C} p2?C维降维至 D维,得到 ),这好比于 NLP 中的词嵌入 (Word Embeddings)。
-
patch embedding:以ViT-B/16(patch的shape为16x16x3)为例,如输入图片大小为224x224,将图片分为固定大小的patch,则每张图像会生成224x224/16x16=196个patches,即输入序列长度为196,每个patch维度16x16x3=768,线性投射层的维度为768xN (N=768),因此输入通过线性投射层之后的维度依然为196x768,即一共有196个token,每个token的维度是768。这里还需要加上一个特殊字符cls,因此最终的维度是197x768。到目前为止,已经通过patch embedding将一个视觉问题转化为了一个seq2seq问题。
-
在Transformer Encoder之前要加上[class]token,参考BERT,在刚刚得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,
Cat([1, 768], [196, 768]) -> [197, 768]。 -
positional encoding(standard learnable 1D position embeddings) :ViT同样需要加入位置编码,位置编码可以理解为一张表,表一共有N行,N的大小和输入序列长度相同,每一行代表一个向量,向量的维度和输入序列embedding的维度相同。注意位置编码的操作是直接叠加在tokens上(add)。所以加入位置编码信息之后,维度依然是197x768。
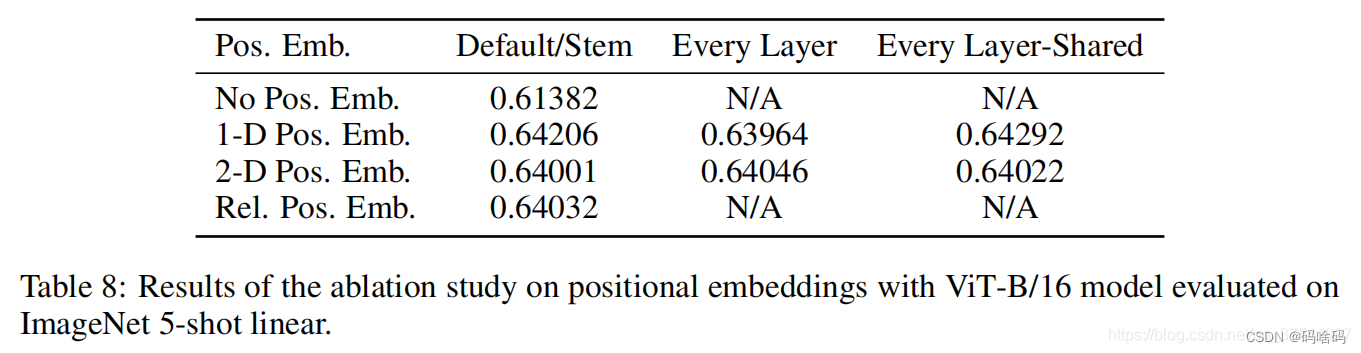
实验对比,默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了大概3个点,和2D Pos. Emb.比起来没太大差别。
Transformer层
Transformer Encoder其实就是重复堆叠Encoder Block L次。
- Layer Norm:LN这里是对每个token进行Norm处理,LN输出维度依然是197x768。
- LN/multi-head attention/LN:多头自注意力时,先将输入映射到 q , k , v q,k,v q,k,v,如果只有一个头, q k v q k v qkv的维度都是197x768,如果有12个头(768/12=64),则 q k v qkv qkv的维度是197x64,一共有12组 q k v qkv qkv,最后再将12组 q k v qkv qkv的输出拼接起来,输出维度是197x768,然后在过一层LN,维度依然是197x768
- Dropout/DropPath:Dropot/DropPath,在原论文的代码中是直接使用的Dropout层,在但rwightman实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。
- MLP:如下图所示,就是全连接+GELU激活函数+Dropout组成也非常简单,在第一个全年连接层将维度放大4倍
197x768-->197x3072,第二个全连接层再缩小回原节点个数197x3072-->197x768。
MLP Head
这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
实验
ViT 并不像 CNN 那样具有归纳偏置(Inductive Bias),若直接在 ImageNet 上训练,同 level 的 ViT 效果不如 ResNet。但若先在较大的数据集上预训练,然后再对特定的较小数据集进行微调,则效果优于 ResNet。比如 ViT 在Google 私有的 300M JFT 数据集上预训练后,在 ImageNet 上的最好的 Top-1 ACC 可达 88.55%,这在当时已和 ImageNet上的 SOTA 相当了 (Noisy Student EfficientNet-L2 效果为 88.5%,Google 最新的 SOTA 是 Meta Pseudo Labels,效果可达 90.2%)
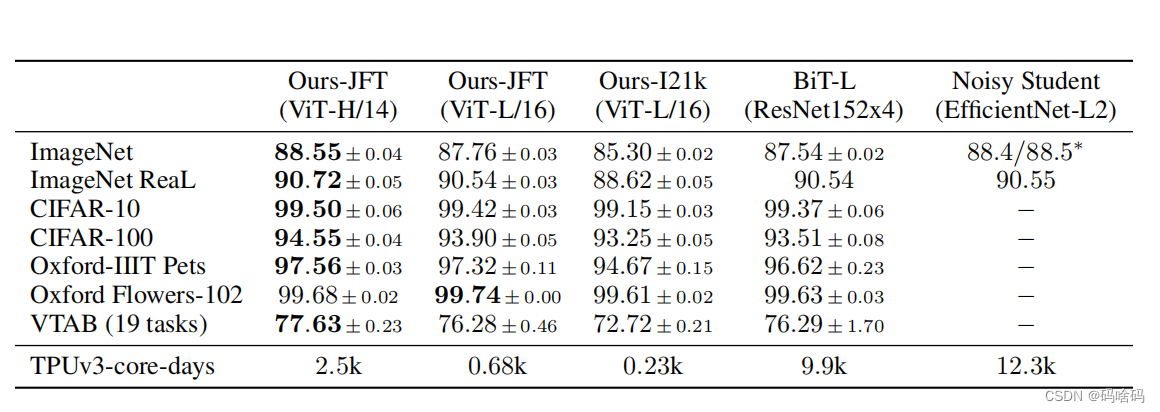
那么 ViT 至少需要多大的数据量才能比肩 CNN 呢?结果如下图所示。可见预训练的数据量须达到 100M 时才能凸显 ViT 的优势。Transformer 的一个特色其 Scalability:当模型和数据量提升时,性能持续提升。在大数据下,ViT 可能会发挥更大的优势。
但实际上resnet的性能是相当好的,在图中可明显看出100M以后ViT-B/16相较于Resnet152x2并没有显著的提升
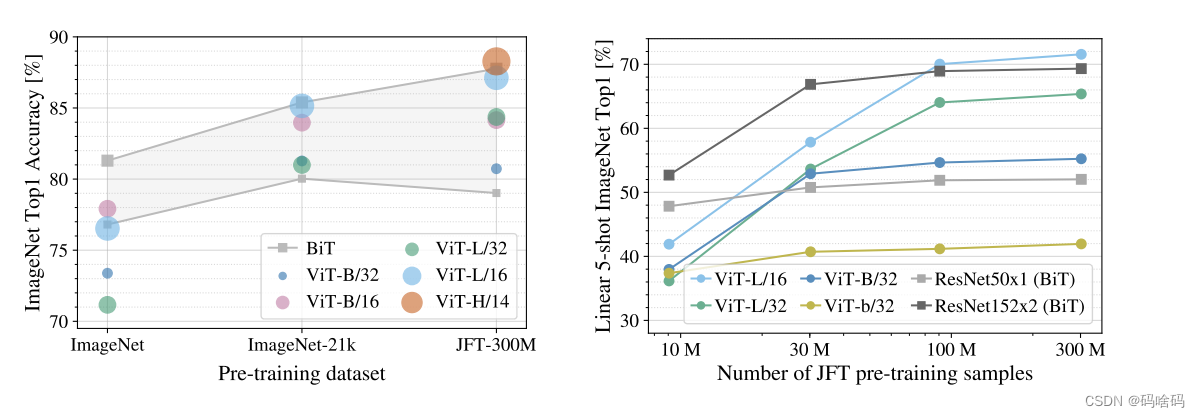
再由下图可以看出在Transformer、Hybrid和Resnet三个不同架构的性能与训练前计算相比:ViT、ResNets和Hybrid。在相同的计算预算下,ViT通常优于ResNets。Hybrid对于较小的模型尺寸,改进了纯Transformer,但对于较大的模型,差距消失了。
而且图中仅仅只能看出Hybrid的性能饱和,ViT和Resnet性能都未饱和,文中作者给出的解释是:
总结
本文探索了Transformer在图像识别中的直接应用。与之前在计算机视觉中使用自我注意的工作不同,除了初始的补丁提取步骤外,没有将图像特定的归纳偏差引入到体系结构中。相反,文中将图像解释为一系列补丁,并使用NLP中使用的标准Transformer编码器对其进行处理。这种简单但可扩展的策略在与大型数据集的预训练相结合时工作得非常好。因此,Vision Transformer在许多图像分类数据集上达到或超过了最先进的水平,同时预训练成本相对较低。
虽然这些初步成果令人鼓舞,但仍存在许多挑战。一是将ViT应用于其他计算机视觉任务,如检测和分割。本文的研究结果以及Carion等人(2020)的研究结果表明了这种方法的前景。另一个挑战是继续探索自我监督的训练前方法。我们的初步实验表明,自我监督预训练比自我监督预训练有一定的提高,但与大规模监督预训练相比,自我监督预训练仍有较大的差距。最后,ViT的进一步扩展可能会提高性能。