文章目录
前言
这篇文章发表于ACL 2019。
原文链接:https://arxiv.org/pdf/1908.05391.pdf
代码链接:https://github.com/THUDM/KBRD
什么是end-to-end端到端框架
输入数据为原始数据,结果输出为最终的输出,从输入端到输出端,中间的神经网络自成一体,为端到端的框架。
而对于非端到端的框架,每个部分都是由独立的模块组成,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果,这是非端到端的。
参考博客https://blog.csdn.net/ViatorSun/article/details/81880679
什么是自动编码器auto-encoder
一、原文摘要
在本文中,我们提出了一个全新的端到端框架KBRD,即基于知识的对话推荐系统。它集成了推荐系统和对话生成系统。对话系统通过引入基于知识的用户偏好信息来提高推荐系统的性能,推荐系统通过提供推荐感知词汇偏差来提高对话生成系统的性能。实验结果表明,我们提出的模型在评价对话生成和推荐方面都比基准模型有明显的优势。一系列的分析表明,这两种系统可以相互促进,引入的知识对两种系统的性能都有促进作用。
二、为什么要提出KBRD
- 传统推荐高度依赖于用户的此前操作:点赞、收藏等。但这种反馈的隐含性,只能反映用户的一部分兴趣,导致推荐不准确。
- 获得推荐信息的另一个信息源是用户和系统之间的对话,往往会提供更多的用户偏好信息。
- 对话推荐系统可以看作是推荐系统和对话系统的结合。对话系统应用信息丰富的自然语言来响应用户的话语,推荐系统根据用户的话语内容提供高质量的推荐。
- 外部知识的引入可以加强系统之间的联系,提高系统的性能。因此,在这些动机的驱动下,我们提出了一个全新的端到端框架来集成这两个系统。我们将其命名为KBRD,即基于知识的对话推荐系统。
- 动机原理:具体来说,对话生成系统向推荐系统提供关于项目的上下文信息。例如,对于电影推荐系统,上下文信息可以是导演、演员和类型。因此,即使对话框中没有提到任何项目,推荐系统仍然可以根据上下文信息进行高质量的推荐。反过来,推荐系统提供推荐信息以促进对话,如带推荐信息的词汇。此外,我们将外部知识纳入到我们的框架中。知识图有助于弥合系统之间的差距,并提高它们的性能。
三、相关工作
作者提到了REDIAL那篇文章的模型,其中用到了开创性的词眼(可见很重要啊!)
2016年所提出的一个转换机制,决定解码器到底是输出推荐结果还是继续引导话题
(待填坑)
四、KBRD模型
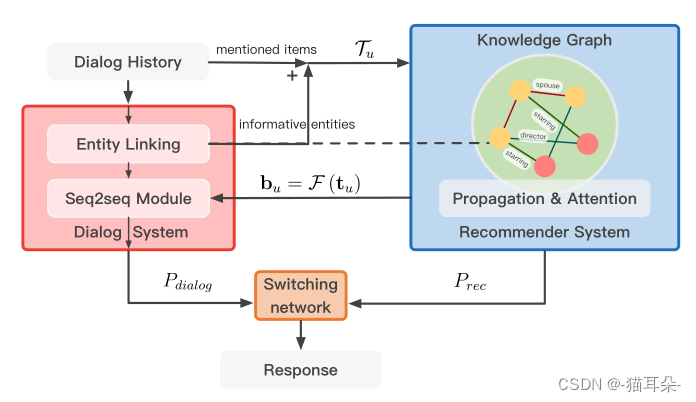
- 对话感知的知识推荐
充分利用系统与用户的对话信息,一共包含项目信息和非项目信息(表明用户偏好的上下文信息)。
为充分探索用户的偏好,对那些非项目信息引入知识图谱DBpedia。 - 合并对话内容
知识图谱表示为三元组 G = ( h , r , t ) G=(h,r,t) G=(h,r,t),其中 h , t ∈ h,t∈ h,t∈ ? \epsilon ?,即 h , t h,t h,t均表示实体, ? \epsilon ?为实体集; r r r表示 h , t h,t h,t相互之间的关系。
做法:首先将用户提到的项目名在实体集E中进行匹配,再采用实体链接Entity Linking将对话中的信息性非项目实体与匹配到实体集 ? \epsilon ?中,用Tu={e1,e2,e3,…,e|Tu|}该集合表示用户所提到的项目与非项目,以便连接至知识图谱。 - 关系图传播
由于在知识图谱中,相邻节点可能有相似的特征,所以文中采用了R-GCN将知识图谱中的结构与关系信息编码为实体隐藏表示。比如说用户给系统谈及了一位演员,系统就会推荐这位演员有密切联系的电影。鉴于R-GCN,对于不同类的邻居节点会分别进行建模。
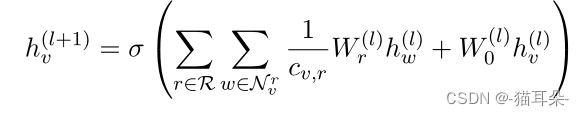
上面就是R-GCN的公式, v v v是第 l l l层的某个实体节点, W W W是可学习的嵌入矩阵, h h hl为某个节点第 l l l层的隐藏嵌入表示…(公式没咋看懂,参考b站小淡鸡的R-GCN视频吧带你快速理解R-GCN(relational-GCN)
大概的意思就是,对于不同的邻居,我有不同的学习方式来更新我的嵌入表示。。。
那么经过了R-GCN之后,对于每个实体 v v v,都有一个知识增强隐藏表示矩阵 H H H。 - 实体注意力
下一步就是根据知识增强后的矩阵 H H H向用户推荐项目,这里是采用了自注意力机制,给对话中的项目进行打分,得到最终推荐的概率Prec
-
推荐感知的对话
在对话方面,本文是基于Transformer来做的,实验中的效果也比较好。而此前的ReDial那篇的模型是基于HRED双层循环编码器做的。那么Transformer也是一个端到端的seq2seq模型。它的编码器由一个嵌入层和多个编码器层组成。每个编码器层都有一个自注意力模块和一个Point-Wise Feed-Forward Network(FFN)。
然而原来的Transformer完全依赖于对话内容,通过更进一步在推荐系统中引入信息增强后的项目信息后,模型可以引导对话系统生成更契合用户偏好的回答。具体做法就是在最高层的解码器引入一个
vocabulary bias bu,它是根据推荐系统对用户的隐藏嵌入所计算出来的。最后解码器顶层的概率计算公式就是这样。
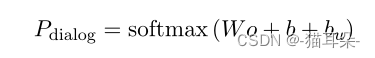
-
与基准模型相比
1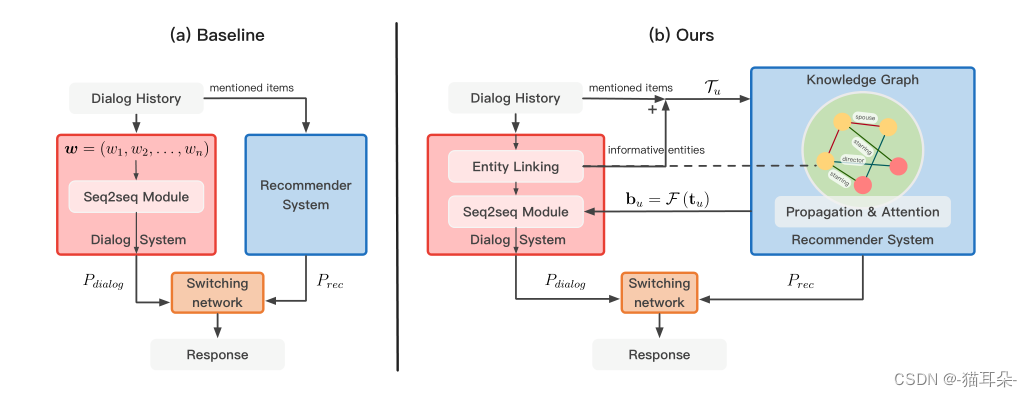
-
基线框架中推荐系统与对话系统之间的连接较弱。对话系统将对话历史的纯文本作为输入,推荐器只考虑对话中提到的项目。
-
KBRD使两个系统之间的交互更强。首先,项目通过实体链接,链接到了知识图谱,并且其相关信息也告知了推荐系统。它们通过R-GCN在知识图谱上传播,丰富了用户的兴趣向量。然后,将知识增强后的用户嵌入表示以bu的形式发送给对话系统,进而生成与用户兴趣一致的回答。
五、实验
实验在ReDial数据集上运行,并且引入了DBpedia知识图谱。
所采用的基准模型为ReDIAL和Transformer
- 对话推荐效果的实验
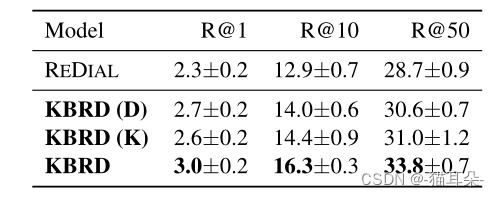
这里的指标用的是Recall@K,意思是推荐系统选择的前K项是否包含ground truth。KBRD(D)表示不引入外部知识图谱,推荐信息只包含对话内容。KBRD(K)表示只包含外部知识。
文章在与ReDIAL对比的同时,还加了消融实验,以讨论对话系统和引入的外部知识是否有贡献。
那么最后的结果就是,与基准模型相比,KBRD确实提升了,并且,对话内容、外部知识都有贡献,并且两两组合带来的优势甚至大于仅包含一个部分的结果之和,充分证明了模型的有效性。 - 对话系统的实验
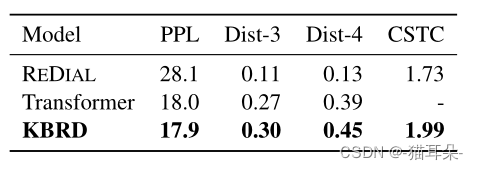
PPL为perplexity疑惑度,越低越好;Dist-n表示n元模型,越高越好,CSTC表示consistency一致性,由人来判断生成的话语与对话历史的一致性。
从结果来看,与两个基准模型对比,KBRD是表现最好的。
六、讨论KBRD为什么work
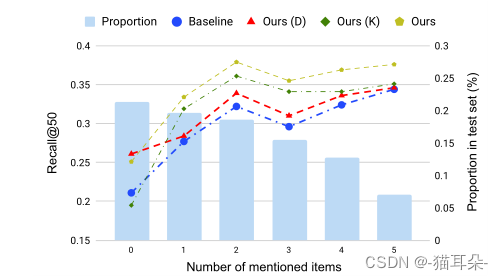
对话有助于推荐
- 从图中的直方图可以看出,大部分对话都只提到了0~2部电影,所以通过尽可能少的交互轮次来进行高质量推荐是很重要的,这也对应于经典的cold start冷启动问题。
- 观察折线图,
当对话中用户没有提到任何项目时,基准模型和只通过对话内容来推荐的模型效果表现是最差的,而另外两个注意了非项目信息的模型表现效果很好,这就说明对话中的上下文包含了许多有价值的非项目信息。而随着对话中所提到的项目数增加,知识的贡献度比对话内容更加重要。同时拥有两个信息源的系统性能最好。对话引入了上下文信息,知识引入电影特征和与其他电影的结构联系。
推荐助于对话
与推荐系统交互确实可以提高对话系统在自动评价和人工评价方面的性能。KBRD更关注于对话中提到的实体的外部信息,比如说用户表示,词汇bias。
为了进一步研究推荐系统对对话生成的影响,本文展示了生成的排名靠前的具有biased的词汇。

这些biased的词汇确实很符合电影的主题,可以认为推荐系统以词汇偏差的形式向对话系统传递了重要信息。此外,这些带有偏见的词汇也可以作为对推荐结果的明确解释。
七、结论
本文提出了一个全新的端到端框架KBRD,该框架通过知识传播来搭建推荐系统和对话系统之间的桥梁,使得二者的交互性更强。