3.6. softmax�ع�Ĵ��㿪ʼʵ��
ʹ��Fashion-MNIST���ݼ�,�������ݵ�������������СΪ256��
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
��ʼ��ģ�Ͳ���
?��28x28��ͼ��ת��Ϊlen=784��������ʾ
?ÿ������XΪ1
��
\times
�� 784; WΪ784
��
\times
�� 10;bΪ1
��
\times
�� 10;���
y
^
\hat{y}
y^?Ϊ1
��
\times
�� 10 ( ?ע��:b��
y
^
\hat{y}
y^?����������,�������Ĺ淶����ʱ��,�Ƕ��������sum(1))
- �����Իع�һ��,���ǽ�ʹ����̬�ֲ���ʼ��Ȩ��W,ƫ��b��ʼ��Ϊ0��
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
����softmax����
ʵ��softmax�������������:
- ��ÿ��������(ʹ��exp);
- ��ÿһ�����(С������ÿ��������һ��),�õ�ÿ�������Ĺ淶������;
- ��ÿһ�г�����淶������,ȷ������ĺ�Ϊ1��
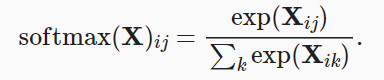
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # ����Ӧ���˹㲥����
����softmax�ع�ģ��
? ע��,�����ݴ��ݵ�ģ��֮ǰ,����ʹ��reshape������ÿ��ԭʼͼ��չƽΪ������
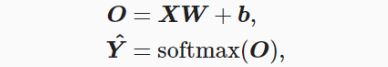
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
������ʧ����
y = torch.tensor([0, 2])
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y_hat[[0, 1], y]

- ����һ����������y_hat,���а���2��������3������Ԥ�����, �Լ����Ƕ�Ӧ�ı�ǩy��
- ��y����֪��,��һ��������ʵ����ǵ�һ��; ���ڶ���������ʵ����ǵ����ࡣ
- Ȼ��ʹ��y��Ϊy_hat�и��ʵ�����,�õ���Ԥ������,ѡ���һ�������е�һ����ĸ��ʺ�ѡ��ڶ��������е�������ĸ��ʡ�

����ֻ��һ����ǩ,���Կ�������ͼ�л������Ĺ�ʽ���м���,��һ��-log�������ɵõ��������������ԵĽ�����:
def cross_entropy(y_hat, y):
return - torch.log(y_hat[range(len(y_hat)), y])
'''range(len(y_hat))��������y_hat��ÿһ��,��ÿһ������;����y_hat[range(len(y_hat)), y]�õ�����ÿһ����������ʵ����Ӧ��һ������'''
cross_entropy(y_hat, y)

?? ��??������ͽ�������?��������������,���ǻ������ƽ��ֵ��??

��ʵ,��������ͻ�����,������ֵ�Ĺ��̱��ںϵ��˺�������ѵ����!
����ȷ��(���ྫ��)
- ��Ԥ�����ǩ����yһ��ʱ,������ȷ�ġ� ���ྫ�ȼ���ȷԤ����������Ԥ������֮�ȡ�
�ȼ�����ȷԤ������
- ����y_hat��ÿһ�ж�Ӧһ������,���ж�Ӧ��������Ԥ�������
- ��ʹ��argmax���ÿ�������Ԫ�������������Ԥ����� Ȼ��Ԥ���������ʵyԪ�ؽ���"=="�Ƚ�(������ͳһ������������)��cmp�����һ������0(��)��1(��)��������
- ���,������cmp�����õ���ȷԤ���������
def accuracy(y_hat, y): #@save
"""����Ԥ����ȷ������"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
�ټ����������ݼ��ϵ�Ԥ��ȷ��
��������ģ��net,�������ݼ�data_iter:
def evaluate_accuracy(net, data_iter): #@save
"""������ָ�����ݼ���ģ�͵ľ���"""
if isinstance(net, torch.nn.Module): #isinstance()�ж��Ƿ�Ϊij����, ����type()
net.eval() # ����Ϊ����״̬
metric = Accumulator(2) #ʵ������������
with torch.no_grad(): #���¼��㲻�����ݶ�
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
#accuracy(net(X), y)����ȷԤ����, y,numel()������y�����Ԫ�ظ���,������
return metric[0] / metric[1]
���� �ؼ�������ʵ����������:
for X, y in data_iter: metric.add(accuracy(net(X), y), y.numel()) return metric[0] / metric[1]
- ��data_iter����������Xi,yi ����Ԥ����ȷ�����ۼӺ� metric[0],������Ԥ���ȫ������ metric[1]
- Ȼ�������ı�ֵ,��ȷ��
����Accumulator()��Ϊ�˷���,�����һ���Ķ��������͵ĺ���:
class Accumulator: #@save
"""��n���������ۼ�"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
��һ��
�����ĸն����softmaxģ��net()���Կ�,��ʱ��û�о���ѵ��,���в���W��b��������ɵ�,���Ծ�ä��Ϲ����һ������,���Ծ�ȷ��Ӧ����Լ���� 1 10 \frac {1} {10} 101? (��Ϊ������һ��10�����)
evaluate_accuracy(net, test_iter)

ѵ��:
- ������,�����ع�ѵ�����̵�ʵ����ʹ����ظ�ʹ���� ����,���Ƕ���һ��������ѵ��һ���������ڡ�
- ��ע��,updater�Ǹ���ģ�Ͳ����ij��ú���,������������С��Ϊ������ ��������d2l.sgd����,Ҳ�����ǿ�ܵ������Ż�������
ѵ��ģ�͵�һ��epoch
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""ѵ��ģ��һ����������(�������3��)"""
# ��ģ������Ϊѵ��ģʽ
if isinstance(net, torch.nn.Module):
net.train()
# ѵ����ʧ�ܺ͡�ѵ��ȷ���ܺ͡�������
metric = Accumulator(3)
for X, y in train_iter:
# �����ݶȲ����²���
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# ʹ��PyTorch���õ��Ż�������ʧ����
updater.zero_grad()
l.mean().backward()
updater.step()
else:
#ʹ���Զ��Ƶ��Ż�������ʧ����:���������Լ�д���Ǹ�sgd
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# ����ѵ����ʧ��ѵ������
return metric[0] / metric[2], metric[1] / metric[2]
����epoch������ѵ��
- ���ѵ������train_ch3(), ����train_iter���ʵ���ѵ�����ݼ���ѵ��һ��ģ��net����ѵ�������������ж����������(��num_epochsָ��)��
- ��ÿ���������ڽ���ʱ,����test_iter���ʵ��IJ������ݼ���ģ�ͽ���������
- ���ǽ�����Animator�������ӻ�ѵ�����ȡ�
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""ѵ��ģ��(�������3��)"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
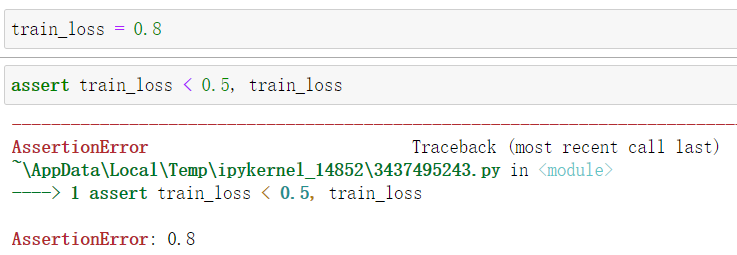
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
����һ����ͼ����-���ڽ�����ӻ�:
����һ���ڶ����л������ݵ�ʵ�ó�����Animator, ���ܹ��������ಿ�ֵĴ��롣
class Animator: #@save
"""�ڶ����л�������"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# �����ػ��ƶ�����
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# ʹ��lambda�����������
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# ��ͼ�������Ӷ�����ݵ�
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
���Կ�
ʹ��֮ǰ����3.2����Լ�������Ż�����:С��������ݶ��½����Ż�ģ�͵���ʧ����,����ѧϰ��Ϊ0.1��
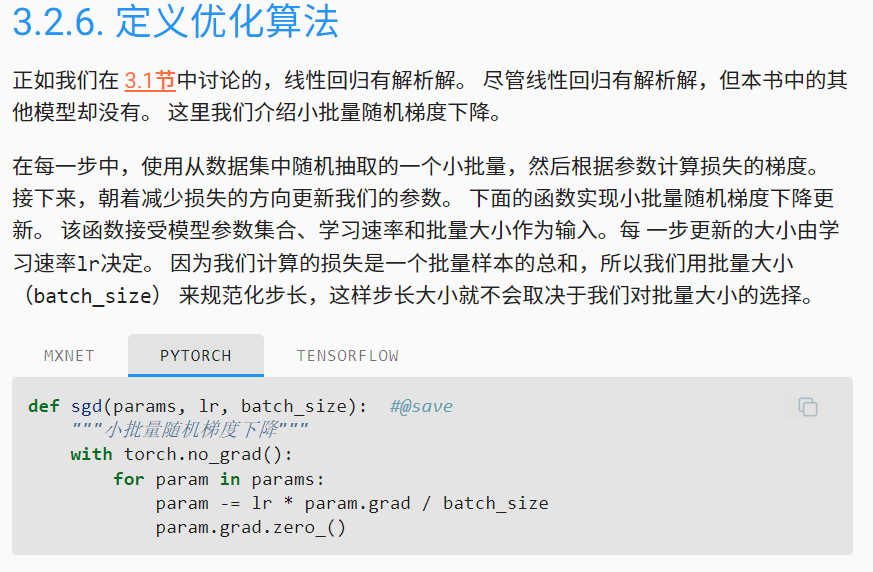
lr = 0.1
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
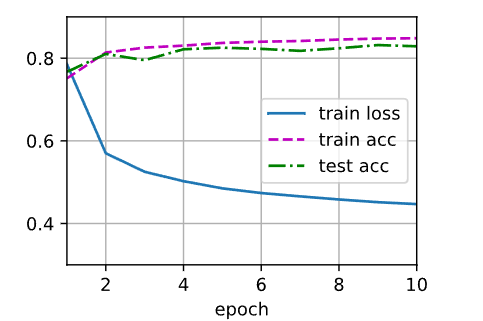
����,����ѵ��ģ��10���������ڡ���������num_epochs��ѧϰ��lr���ǿɵ��ڵij������� ͨ���������ǵ�ֵ,�������ģ�͵ķ��ྫ�ȡ�
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
��!!!�����������,���Ƕ�̬��ͼ��~~~~
Ԥ��
����ѵ���Ѿ����,���������з���Ԥ�⡣ ����һϵ��ͼ��,���ǽ��Ƚ����ǵ�ʵ�ʱ�ǩ(�ı�����ĵ�һ��)��ģ��Ԥ��(�ı�����ĵڶ���)��
def predict_ch3(net, test_iter, n=6): #@save
"""Ԥ���ǩ(�������3��)"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
predict_ch3(net, test_iter)

python�����
eval() ����
- ����ִ��һ���ַ�������ʽ,�����ر���ʽ��ֵ��
- eval(expression[, globals[, locals]])
- ����:expression �C ����ʽ; globals �C ����ȫ��������,������һ���ֵ����
locals �C �����ֲ�������,�������κ�ӳ����� - ���ر���ʽ�ļ�����
��pytorchϵ�С�model.train(), model.eval()�÷����
ģ������BatchNormalization��Dropout,����ʱʹ��model.eval() ��Ὣ��ر�����Ӱ��Ԥ������
ʲô��˼��??(�ο�����model.eval()������)
������Ҫ������ѵ�����̺Ͳ��Թ��̡�
- ѵ��������BN������: ������һֱ�ڱ�������,��ʱ��BN��ϵļ�����ۻ���ֵ�ͷ���,ѵ��������õ����յľ�ֵ�ͷ���,�ڴ˴������Ϊmean_train,variance_train��
- ���Թ�����BN:
- �����ʹ��model.eval(),��ôBN���������������Ԥ������,�����ۻ���ֵ�ͷ���,��������һ��Ԥ�����ݺ�,BN�����õ����ֵ�ͷ���ֱ�Ϊmean_test,variance_test,��ʱBN��ľ�ֵ�ͷ���������(mean_train+mean_test),(variance_train+variance_test),�����ѵ�������еľ�ֵ�ͷ�����˱仯��˻ᵼ��Ԥ���������仯��
- ���ʹ��model.eval(),��BN��Ͳ����ټ���Ԥ�����ݵľ�ֵ�ͷ���,����Ԥ�������BN��ľ�ֵ�ͷ������ѵ�����̵õ��ľ�ֵ�ͷ���mean_train,variance_train,��ʱԤ�����Ͳ����ٷ����仯��
- ѵ��������Dropout:
ѵ���������������õ�dropout������ʹһ���ֵ��������Ӳ����м��㡣 - ���Թ�����Dropout:
- Ԥ������������ʹ��model.eval()�Ļ�,��Ȼ��ʹһ���ֵ��������Ӳ����м���,
- ��ʹ��model.eval()��������е��������Ӿ����м��㡣
numel()����:
- numel()����:����������Ԫ�صĸ���
- net.parameters():��Pytorch�÷�,��������net�����еIJ���
assert ����:
�����ж�һ������ʽ,�ڱ���ʽ����Ϊ false ��ʱ���쳣,��ָ�����������쳣���شʡ�
assert expression [, arguments]
��: