��˹̹����ѧ������CS224W����ͼ����ѧϰ���ġ���Ϣ���ݺͽڵ����
����Ŀ¼
���ǵ�������: ��֪ͼ��һ���ֽڵ�ı�ǩ,��ͼ�нڵ�֮��Ĺ�ϵ������ǩ���䵽���нڵ��������ڰ�ලѧϰ����
���ڿ�����ѧϰmessage passing�����������һ����ijһ�ڵ�ı�ǩ����Ԥ��,��Ҫ�䱾���������ھӵı�ǩ��������
message passing�ļ�����ͼ�����ƵĽڵ�֮����������,Ҳ�������ڽڵ��б�ǩ��ͬ�������������������homophily(���ƽڵ������ھۼ�)��influence(��ϵ��Ӱ��ڵ���Ϊ)��confounding(����Ӱ����Ϊ��ϵ)�����͡�
collective classification�����нڵ�ͬʱԤ���ǩ�ĸ��ʷֲ�,���������Ʒ����(ijһ���ǩ��ȡ�������ھӵı�ǩ)��
local classifier(�ýڵ�����Ԥ���ǩ)�� relational classifier(���ھӱ�ǩ ��/�� ����,Ԥ��ڵ��ǩ)�� collective inference(��������)
���ڿν���������collective classification��ʵ�ּ���:
- relational classification:���ھӱ�ǩ���ʵļ�Ȩƽ��ֵ�������ڵ��ǩ����,ѭ���������
- iterative classification:��ѵ������ѵ���� (�ڵ�����) �� (�ڵ�����,�ھӱ�ǩsummary z zz) �����Ա���Ԥ���ǩ�ķ����� ? 1�� ? 2 ,�ڲ��Լ����� ? 1 �����ʼ��ǩ,ѭ��������� z ? �� ? 2 ����Ԥ���ǩ
- belief propagation:�ڱ��ϴ��ݽڵ���ھӵı�ǩ���ʵ����Ŷ�(belief)��message/estimate,����������ϵ�message,���յõ��ڵ��belief���л�ʱ���ܳ������⡣
1. Message Passing and Node Classification
������Ҫ����:���������в��ֽڵ�ı�ǩ,������������������������нڵ�ı�ǩ?(����:��֪��������һЩթƭ��ҳ,��һЩ������ҳ,����ҵ�����թƭ�Ϳ��ŵ���ҳ�ڵ�?)
ѵ��������һ�����б�ǩ,ʣ�µ�û��ǩ,���־��ǰ�ලѧϰ1
����������һ�ֽ����ʽ:node embeddings2
�������ǽ���һ�������������ķ���3:message passing
ʹ��message passing���ڡ������д��ڹ�ϵcorrelations����һֱ��,�༴���ƽڵ��������ӡ�
message passing��ͨ�����Ӵ��ݽڵ����Ϣ,�о��ϻ�Ƚ������� PageRank4 ���ڵ��voteͨ�����Ӵ��ݵ���һ�ڵ�,�������������Ǹ��µIJ�������Ҫ�Եķ���,���ǶԽڵ��ǩԤ��ĸ��ʡ�
���ĸ��� collective classification:ͬʱ����ǩ���䵽�����е����нڵ��ϡ�
���½���������ʵ�ּ���:
- relational classification
- iterative classification
- belief propagation
�����д��ڹ�ϵcorrelations:
���Ƶ���Ϊ�������лụ�������
correlation:����Ľڵ�������ͬ��ǩ
����correlation�����ֽ���:
homophily(ͬ����,��ͬ��,ͬ������ԭ��):��������Ӱ���罻����
influence:�罻����Ӱ���������
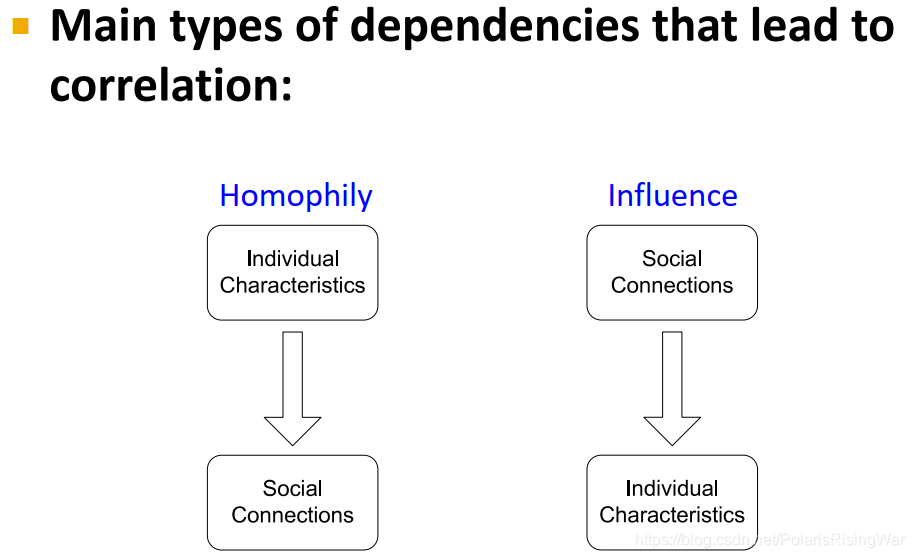
homophily:���ƽڵ�������ڽ���������(�������,����Ⱥ��)
�������о��еõ��˴����۲�
����:ͬ������о��߸���������ϵ,��Ϊ���Dzμ���ͬ�Ļ��顢ѧ���ݽ������Ȼ
influence:�罻���ӻ�Ӱ�������Ϊ��
����:�û���ϲ���������Ƽ������ѡ�
��������������:
������֪���ƽڵ���������и��ӿ���,����ֱ��������
��˸��ݹ����ƶ�guilt-by-association:���������б�ǩX�Ľڵ�����,��ô��Ҳ�ܿ��ܾ��б�ǩX(���������Ʒ����6)
����:�������еĶ���/������ҳ:������ҳ�����ụ�����,�������ع�,ʹ�俴�������ɿ�,�����������������������
Ԥ��ڵ� v vv �ı�ǩ��Ҫ:
- v ������
- v �ھӵı�ǩ
- v �ھӵ�����
1.1 collective classification����
ֱ��:ʹ�������еĹ�ϵͬʱ�������ڵ���з���
���ʿ��propabilistic framework
�����Ʒ����:�ڵ� v �ı�ǩ Y_vȡ�������ھ�N_v�ı�ǩ:P ( Y v ) = P ( Y v �O N v )
collective classification�ֳ�����:
- local classifier:����ڵ�ij�ʼ��ǩ(���ڽڵ���������������,��ʹ������ṹ��Ϣ)

- relational classifier:�����ϵ(�����ھӽڵ�ı�ǩ �� ����,����Ԥ��ڵ��ǩ�ķ�����ģ��)(Ӧ��������ṹ��Ϣ)

- collective inference:������ϵ(��ÿ���ڵ��ϵ���relational classifier,ֱ���ھӼ��ǩ�IJ�һ����С��������ṹӰ������Ԥ����)

2. Relational Classification / Probabilistic Relational Classifier


3. Iterative Classification
relational classifiersû��ʹ�ýڵ�������Ϣ,��������ʹ���·���iterative classification��
iterative classification��˼·:���ڽڵ��������ھӽڵ��ǩ�Խڵ���з���
iterative classifier�Ľṹ
-
��һ��:���ڽڵ���������������
��ѵ������ѵ�����·�����(���������Է���������������㷨):- ? 1 ( f v ) ���� f_vԤ��Y_v
- ? 2 ( f v , z v ) ���� f_v�� z_v(v �ھӱ�ǩ��summary)Ԥ��Y_v
-
�ڶ���:����������
�ڲ��Լ���,�� ? 1Ԥ���ǩ,���� ? 1������ı�ǩ����z_v���� ? 2 Ԥ���ǩ��ÿ���ڵ��ظ���������z_v���� ? 2 Ԥ���ǩ�������,ֱ������������������(10, 50, 100��������,����̫��10)
ע��:ģ�Ͳ�һ��������
4. Loopy Belief Propagation
���ֽ�loopy����Ϊloopy BP������Ӧ�����кܶ������¡�
belief propagation��һ�ֶ�̬�滮����,���ڻش�ͼ�еĸ�������(����ڵ�����ij��ĸ���)��
�ھӽڵ�֮�����������Ϣpass message(�紫�����ŶԷ�����ijһ��ĸ���),ֱ����ɹ�ʶ(��Ҷ���ô����),�����������Ŷ�(Ҳ�з���Ϊ�����)belief��
�ο�6:�����нڵ��״̬����ȡ���ڽڵ㱾����belief,��ȡ�����ھӽڵ��belief��
4.1 message passing
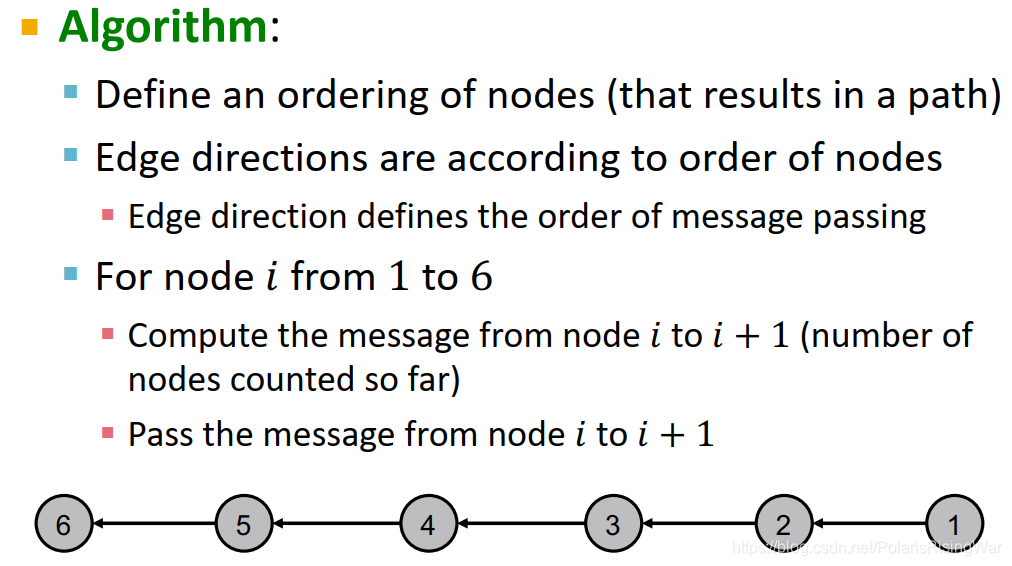
�㷨
- ����ڵ�˳��(����һ��·��)
- ���ڽڵ�˳�����ɱ߷���,�Ӷ�����message passing��˳��
- ���ڵ�˳��,���������һ�ڵ����Ϣ(���������Ľڵ���),������Ϣ���ݵ���һ�ڵ�
4.2 Loopy BP Algorithm
�� i ���ݸ� j ����Ϣ,ȡ���� i ���ھӴ����յ���Ϣ��ÿ���ھӸ� i ����״̬�����Ŷȵ���Ϣ��

