CSDN话题挑战赛第2期
参赛话题:学习笔记
摘要
循环神经网络(RNN)是一种强大的序列数据模型。端到端的训练方法,如连接主义时间分类,使得训练RNN有可能用于输入-输出排列未知的序列标记问题。这些方法与长短时记忆RNN架构的结合被证明是特别有成效的,在手写识别中提供了最先进的结果。然而,到目前为止,RNN在语音识别中的表现令人失望,深度前馈网络的结果更好。本文研究了深层循环神经网络,它结合了深层网络中已被证明非常有效的多层次表示,以及灵活使用赋予RNN的长范围背景。当用适当的正则化进行端到端训练时,我们发现深层长短期记忆RNN在TIMIT音素识别基准上的测试集误差为17.7%,就我们所知,这是最好的记录。
一、背景介绍
神经网络在语音识别方面有很长的历史,通常与隐马尔可夫模型(HMM)相结合。近年来,随着深度前馈网络在声学建模方面的巨大改进,它们获得了关注。鉴于语音是一个固有的动态过程,考虑将循环神经网络(RNN)作为一种替代模型似乎是很自然的。HMM-RNN系统最近也出现了复兴,但目前的表现还不如深度网络好。
与其将RNN与HMMs结合起来,不如 "端到端 "地训练RNN用于语音识别。这种方法利用了RNNs与HMMs相比更大的状态空间和更丰富的动态,并避免了使用可能不正确的排列组合作为训练目标的问题。长短期记忆(LSTM),一种具有改进记忆的RNN结构,与端到端训练的结合,已被证明对手写识别特别有效。然而,到目前为止,它对语音识别的影响很小。
RNNs从根本上来说在时间上比较擅长,因为它们的隐藏状态是之前所有隐藏状态的函数。激发本文的问题是,RNN是否也能从空间深度中获益;也就是说,通过将多个递归隐藏层堆叠在一起,就像传统深度网络中的前馈层堆叠那样。为了回答这个问题,我们介绍了深度长短时记忆RNN,并评估了它们在语音识别方面的潜力。我们还介绍了对最近引入的端到端学习方法的改进,该方法联合训练两个独立的RNN作为声学和语言学模型。第2节和第3节描述了网络结构和训练方法,第4节提供了实验结果,第5节给出了结论性意见。
二、循环神经网络RNNs
给定一个输入序列x=(x1,…,xT),一个标准的循环神经网络(RNN)通过从t=1到T的迭代,计算出隐藏向量序列h=(h1,…,hT)和输出向量序列y=(y1,…,yT)。
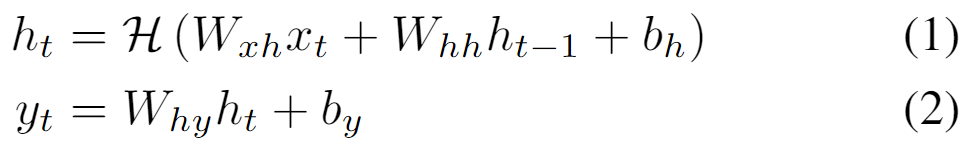
其中W项表示权重矩阵(如Wxh是输入-隐藏的权重矩阵),b项表示偏置向量(如bh是隐藏偏置向量),H是隐藏层函数。
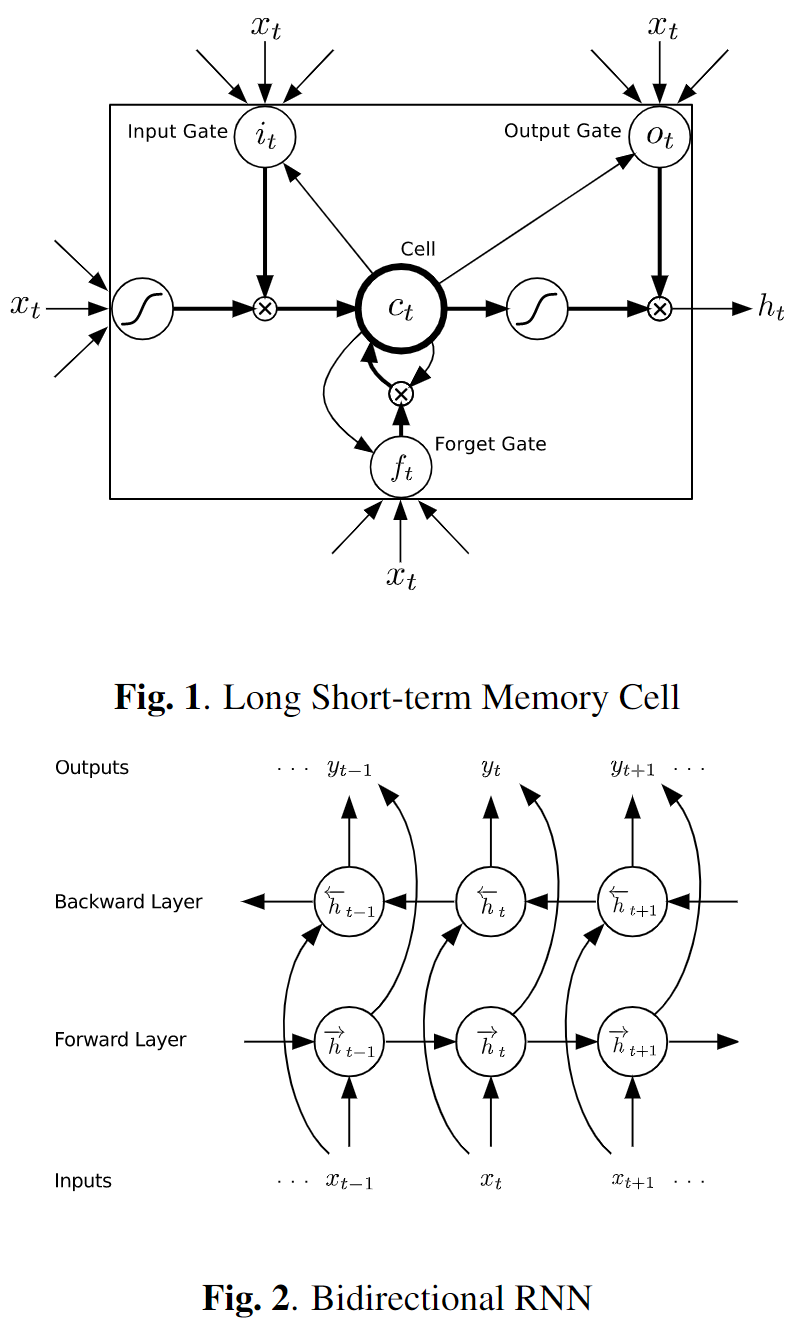
H通常是一个sigmoid函数的元素应用。然而,我们发现,长短期记忆(LSTM)架构,使用特制的记忆单元来存储信息,在寻找和利用长距离背景方面更有优势。图1展示了一个单一的LSTM存储单元。对于本文使用的LSTM版本,H由以下复合函数实现:
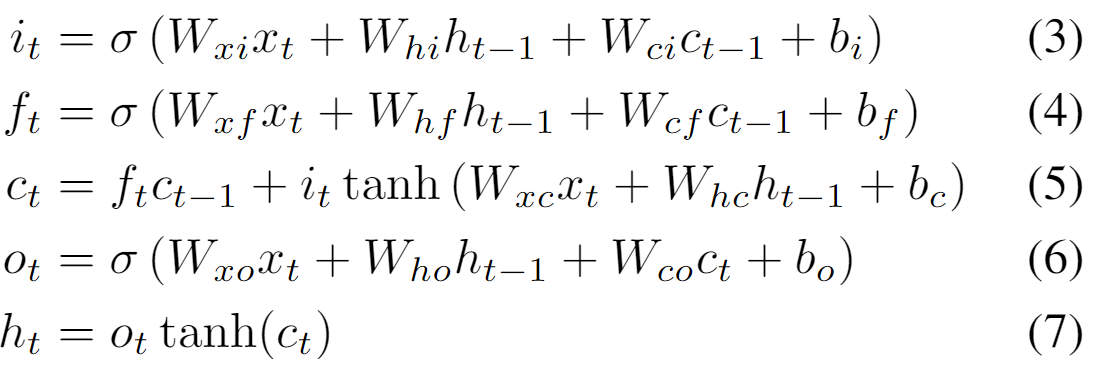
其中σ是Logistic sigmoid函数,i、f、o和c分别是输入门、遗忘门、输出门和激活门向量,它们的大小都与隐藏向量h相同。 从单元到门向量的权重矩阵(如Wsi)是对角线的,因此每个门向量中的元素m只接受来自单元向量中元素m的输入。
传统的RNNs的一个缺点是,它们只能利用以前的上下文。在语音识别中,整个语料被一次性转录,没有理由不利用未来的上下文。双向RNNs(BRNNs)通过用两个独立的隐藏层来处理两个方向的数据,然后将这些数据前馈到同一个输出层来实现这一点。如图2所示,BRNN通过迭代后向层从t=T到1,前向层从t=1到T,然后更新输出层来计算前向隐藏序列→h,后向隐藏序列←h和输出序列y。
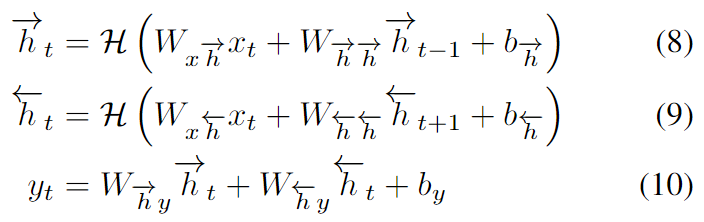
将BRNN与LSTM结合起来,可以得到双向LSTM,它可以在两个输入方向上获取长距离的上下文。
混合HMM神经网络系统最近成功的一个关键因素是使用了深度架构,它能够逐步建立起更高层次的声学数据表征。深度RNNs可以通过将多个RNN隐藏层堆叠在一起来创建,一个层的输出序列形成下一个层的输入序列。假设在堆叠的所有N层中使用相同的隐藏层函数,隐藏向量序列hn从n=1到N和t=1到T中反复计算。
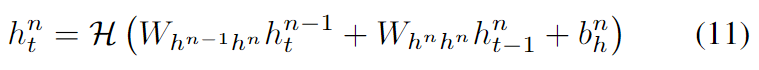
其中我们定义h0=x,网络输出yt为
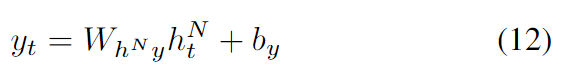
深度双向RNN可以通过用前向和后向序列→h n和←h n替换每个隐藏序列hn来实现,并确保每个隐藏层都能收到来自下面一层的前向和后向层的输入。如果隐藏层使用LSTM,我们就会得到深层双向LSTM,也就是本文中使用的主要架构。据我们所知,这是第一次将深度LSTM应用于语音识别,我们发现它比单层LSTM产生了巨大的改进。
三、网络训练
我们专注于端到端的训练,RNN学会直接从声学序列映射到语音序列。这种方法的一个优点是,它消除了创建训练目标的预定义(和容易出错的)对齐的需要。第一步是利用网络输出对所有可能的语音输出序列y进行参数化可微分布Pr(y|x),给定一个声学输入序列x,然后目标输出序列z的对数概率log Pr(z|x)可以通过时间的反向传播,相对于网络权重进行区分,整个系统可以通过梯度下降进行优化。我们现在描述两种方法来定义输出分布,从而训练网络。我们把x的长度称为T,把z的长度称为U,把可能的音素数量称为K。
3.1. 连接主义时态分类
第一种方法被称为连接主义时间分类法(Connectionist Temporal Classi-fication,CTC),它使用一个softmax层来定义输入序列中每一步的分离率输出分布Pr(k|t)。 这个分布涵盖了K个音素和一个额外的空白符号?,它代表一个非输出(因此softmax层的大小是K+1)。 直观地说,网络工作在每个时间步骤中决定是否发出任何标签,或不发出任何标签。 这些决定共同定义了输入序列和目标序列之间的排列组合。CTC然后使用前向-后向算法对所有可能的排列组合进行求和,并确定给定输入序列的目标序列的归一化概率Pr(z|x)。类似的程序已被用于语音和手写识别的其他地方,以整合可能的分割;然而CTC的不同之处在于它完全忽略了分割,而是对单一时间段的标签决定进行求和。
用CTC训练的RNN通常是双向的,以确保每个Pr(k|t)都取决于整个输入序列,而不仅仅是截至t的输入。在这项工作中,我们专注于深度双向网络,Pr(k|t)定义如下:
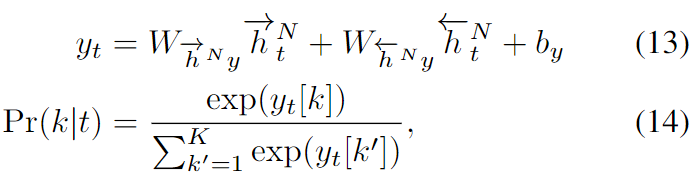
其中yt[k]是长度为K+1的非正则输出向量yt的第k个元素,N是双向层的数量。
3.2. RNN变换器
CTC定义了一个只依赖于声学输入序列x的音素序列的分布。 因此,它是一个纯声学的模型。最近的一个扩展,被称为RNN变换器,它将类似CTC的网络与一个独立的RNN结合在一起,RNN可以根据之前的音素预测每个音素,从而产生一个联合训练的声学和语言模型。 在过去,联合的LM-声学训练已被证明有利于语音识别。
CTC在每个输入时间点上确定一个输出分布,而RNN转换器为每个输入时间点和输出时间点的组合确定一个单独的分布Pr(k|t,u)。 与CTC一样,每个分布涵盖了K个音素加?。 直观地说,网络根据它在输入序列中的位置和它已经发出的输出来 "决定 "要输出什么。 对于长度为U的目标序列z,完整的TU决定集共同决定了x和z之间所有可能的排列组合的分布,然后可以用前向-后向算法整合出来,以确定Log Pr(z|x)。
在最初的表述中,Pr(k|t,u)是通过从CTC网络中获取 "声学 "分布Pr(k|t),从预测网络工作中获取 "语言学 "分布Pr(k|u),然后将两者相乘并重新归一来定义的。本文引入的一项改进是将两个网络的隐藏激活输入一个单独的前馈输出网络,然后用一个softmax函数将其输出归一化来产生Pr(k|t,u)。 这允许更大的可能性来结合语言和声音信息,并似乎导致更好的泛化。特别是我们发现在解码过程中遇到的删除错误的数量减少了。
用-→hN和←-hN表示CTC网络的最上层前向和后向隐藏序列,用p表示预测网络的隐藏序列。 在每一个地方,输出网络都是通过将→hN和←-hN送入一个线性层来产生向量lt,然后将lt和pu送入一个隐藏层来产生ht,u,最后将ht,u送入一个大小为K+1的softmax层来确定Pr(k|t,u)。
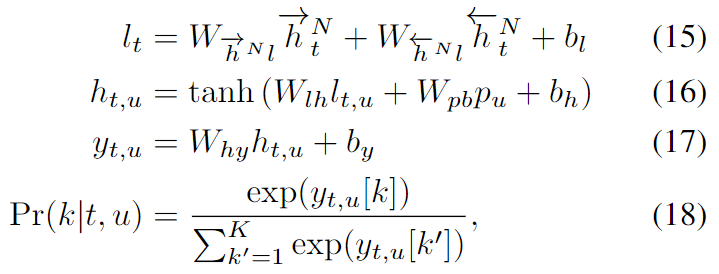
其中yt,u[k]是长度为K+1的非正常化输出向量的第k个元素。为了简单起见,我们将所有的非输出层约束为相同的大小(|- →h nt | = |←- h nt | = |pu| = |lt| = |ht,u|);但是它们可以独立变化。
RNN传感器可以从随机初始权重开始训练。然而,当用预训练的CTC网络和预训练的下一步预测网络的权重进行初始化时,它们似乎效果更好(因此,只有输出网络从随机权重开始)。网络在预训练时使用的输出层(和所有相关的权重)在再训练时被删除。在这项工作中,我们在音频训练数据的语音转录上对预测网络进行预训练;但是对于大规模的应用来说,在单独的文本语料库上进行预训练会更有意义。
3.3. 解码
RNN传感器可以通过波束搜索进行解码,产生一个n-best候选转录列表。在过去,CTC网络的解码是使用一种被称为前缀搜索的最佳优先解码形式,或者简单地在每个时间步长中获取最活跃的输出。然而,在这项工作中,我们利用了与转换器相同的波束搜索,并修改了输出标签概率Pr(k|t, u)不依赖于先前的输出(因此Pr(k|t, u) = Pr(k|t))。我们发现波束搜索比CTC的前缀搜索更快、更有效。请注意,来自转换器的n-best列表最初是按长度归一化的对数概率log Pr(y)/|y|排序的;在目前的工作中,我们放弃了归一化(只有在删除比插入多的情况下才有帮助),而是按Pr(y)排序。
3.4. 正则化
正则化对于RNN的良好表现至关重要,因为它们的灵活性使它们容易出现过拟合。本文使用了两种正则化方法:早期停止和权重噪声(在训练期间向网络权重添加高斯噪声)。每个训练序列添加一次权重噪声,而不是在每个时间段添加。权重噪声倾向于 "简化 "神经网络,即减少传输参数器所需的信息量,从而提高泛化能力。
四、 实验
在TIMIT语料库上进行了音素识别实验。标准的462个说话人集,去掉了所有的SA记录,用于训练,另外一个50个说话人的开发集用于早期停止。报告了24个说话人的核心测试集的结果。音频数据使用基于傅里叶变换的滤波器库进行编码,其中有40个系数(加上能量)分布在美尔尺度上,同时还有它们的第一和第二时间导数。因此,每个输入向量的大小为123。数据经过归一化处理,使输入向量的每个元素在训练集上的平均值为零,方差为单位。在训练和解码过程中使用了所有61个音素标签(所以K=61),然后映射到39个类别进行评分。请注意,所有的实验都只运行一次,所以随机权重初始化和权重噪声导致的方差是未知的。
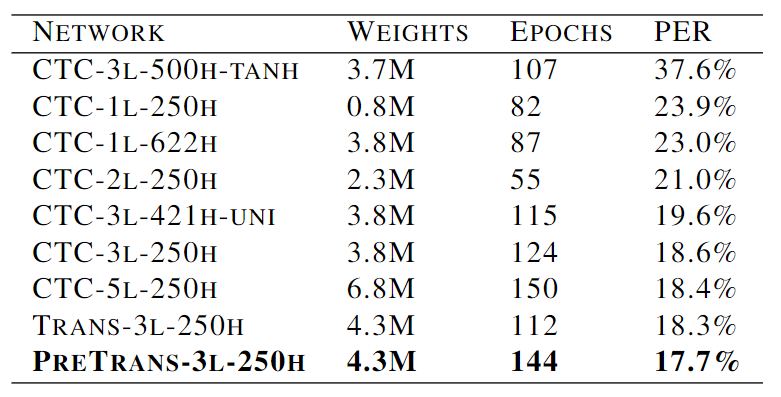
表1:TIMIT音素识别结果。 Epochs 是指在收敛之前通过训练集的次数。PER是核心测试集上的音素错误率。
如表1所示,对九个RNN进行了评估,主要有三个方面的变化:使用的训练方法(CTC,Transducer或预训练Transducer),隐藏层的数量(1-5),以及每个隐藏层中LSTM单元的数量。除了CTC-3l-500h-tanh(TANH单元代替了LSTM单元)和CTC-3l-421h-uni(LSTM层是单向的)外,所有网络都使用了双向LSTM。所有的网络都是用随机梯度下降法训练的,学习率为10-4,动量为0.9,随机初始权重从[-0.1, 0.1]中均匀抽取。除了CTC-3l-500h-tanh和PreTrans-3l-250h之外,所有的网络首先在没有噪音的情况下进行训练,然后从开发集上的最高对数概率点开始,用高斯权重噪音(σ=0.075)重新训练,直到开发集上的最低音素错误率点。PreTrans-3l-250h是用CTC3l-250h的权重和一个音素预测网络(它也有一个由250个LSTM单元组成的隐藏层)的权重初始化的,这两个网络都是在没有噪声的情况下训练的,用噪声重新训练,并在最高对数概率点停止。PreTrans-3l250h从这个点开始训练,并加入了噪声。CTC-3l500h-tanh完全在没有权重噪声的情况下进行训练,因为它在加入噪声的情况下未能学习。所有网络都使用了波束搜索解码,波束宽度为100。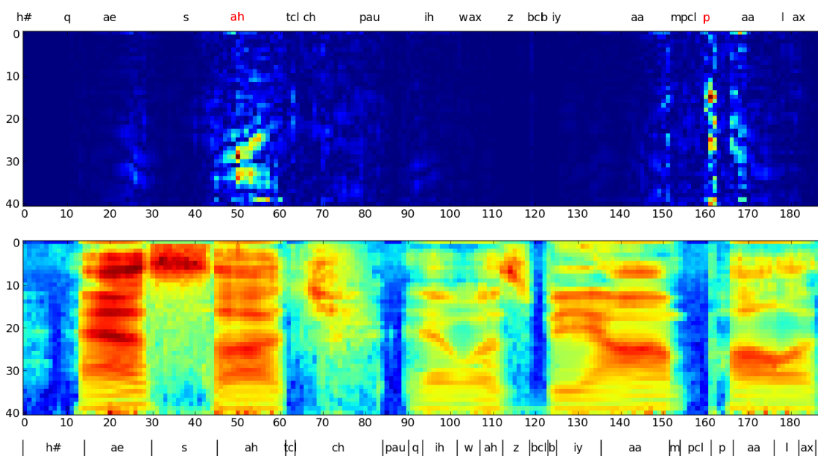
图3:深度CTC RNN的输入敏感度。热图(顶部)显示了 "ah "和 "p "的输出相对于滤波器库输入(底部)的红色导数。下面显示了TIMIT的地面真实分割。请注意,敏感性延伸到周围的片段;这可能是因为CTC(缺乏明确的语言模型)试图从声音数据中学习语言依赖性。
随着隐藏层数从1到5的增加,深度网络的优势立即显现出来,CTC的错误率从23.9%下降到18.4%。CTC-3l-500h-tanh、CTC-1l-622h、CTC3l-421h-uni和CTC-3l-250h这四个网络的权重数量都大致相同,但得到的结果却截然不同。我们可以从中得出的三个主要结论是:
- 在这个任务中,LSTM比tanh好用得多;
- 双向LSTM比单向LSTM略有优势;
- 深度比层的大小更重要。尽管当权重被随机初始化时,转换器的优势是轻微的,但当使用预训练时,它变得更加可观。
五、结论和未来的工作
我们已经表明,深度、双向长短期记忆RNNs与端到端训练和权重噪声的结合在TIMIT数据库的音素识别中给出了最先进的结果。一个明显的下一步是将该系统扩展到大词汇量的语音识别。另一个有趣的方向是将频域卷积神经网络与深度LSTM相结合。