目录
4.2.1 Masked Multi-Head Attention
先写一下理解Transformer会用到的知识点,再写Transformer内部详解。
一、Self-Attention
Transformer整个网络结构完全由Attention机制以及前馈神经网络组成,Self-Attention是Transformer很重要的一部分,理解了Self-Attention可以说就理解了一大半Transformer。
关于Self-Attention的介绍之前已经写过了,在下面这篇博客中:
自注意力机制(Self-Attention)_Michael_Lzy的博客-CSDN博客
二、Mask Self-Attention
Mask Self-Attention在Transformer的encoder和decoder里面都有用到。
在encoder中,主要是用来把padding给mask掉,如果一句话的长度小于指定长度,为了让长度一致往往用0填充,此时需要用Mask Self-Attention来计算注意力分布。
在decoder中,输入有顺序关系,t时刻的输出只与t时刻的输入有关,用mask遮掩住后面的信息。
2.1 什么是Mask Self-Attention
先看Self-Attention,对于Self-Attention,的输出考虑了a1-a4全部输入的信息。

而对于Mask Self-Attention,输出只考虑了已知部分的输入信息,比如b1只和a1有关,b2只和a1、a2有关。?

2.2 为什么要用Mask Self-Attention
在翻译任务中,往往是按顺序翻译,翻译完第i个单词,才根据前i个单词翻译第i+1个单词。但是Transformer结构中输入往往是同时一起输入,所以需要通过masked操作防止第i个单词知道第i+1个单词之后的信息。
在用一句话中的前 N-1 个词去预测第N个词时,第N个及以后的词都要masked掉。比如我们假设预测序列为’i like this apple’:
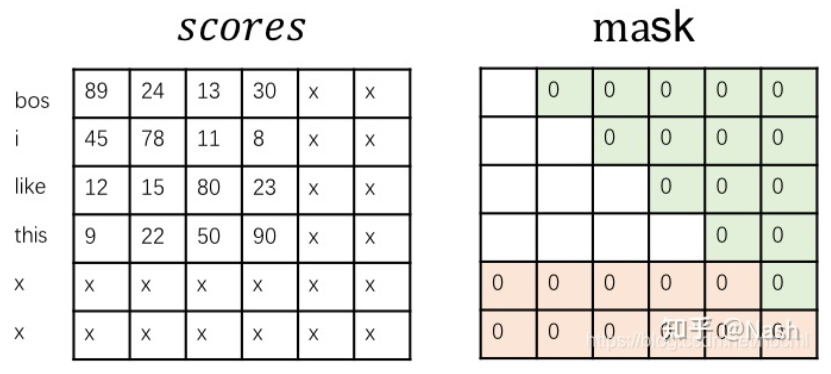
绿色的部分就是为了不泄露未来的词而进行的Masked,粉色的0是encoder中解决padding做的Masked。
三、Positional Encoding
Transformer 是采用 Attention 来取代了RNN。RNN作为序列模型,天生就包含了词在序列中的位置信息,而Attention是没有位置的概念的。这使得模型没有办法知道每个词在句子中的相对和绝对位置信息。Positional Encoding (位置编码)就是用来解决这个问题的。
下图是位置编码很形象的展示,位置编码矩阵中的每一行都对应序列中的一个词,且每个位置编码都是独一无二的

Transfomer中的Positional Encoding下面会提到。
四、Transformer的输入
Transformer 中单词的输入表示?x由单词 Embedding?和位置 Embedding?(Positional Encoding)相加得到。

4.1 单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
4.2?位置 Embedding
位置 Embedding 用?PE表示,PE?的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中使用某种公式计算,计算公式如下:
?
pos:单词的位置,比如I am a Robot 中,I 的位置就是0
d:单词的维度
n:用户设置的值。论文中设置的是10000
PE(pos, j):是一个位置函数,将输入序列中的position映射到位置矩阵的索引(k,j)中
i:取值范围是[0,d/2),每一个i会匹配sin和cos
案例说明
输入序列是 I am a Robot,n = 100,d = 4

五、Transformer详解
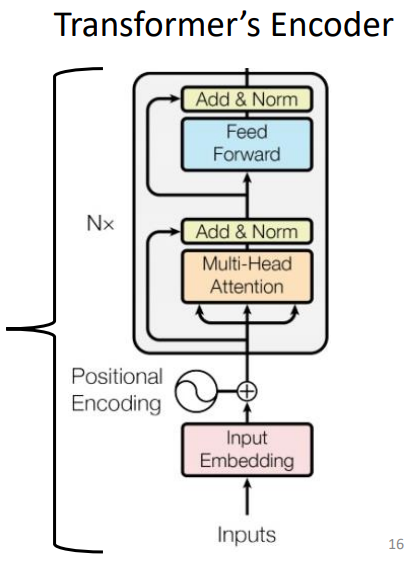
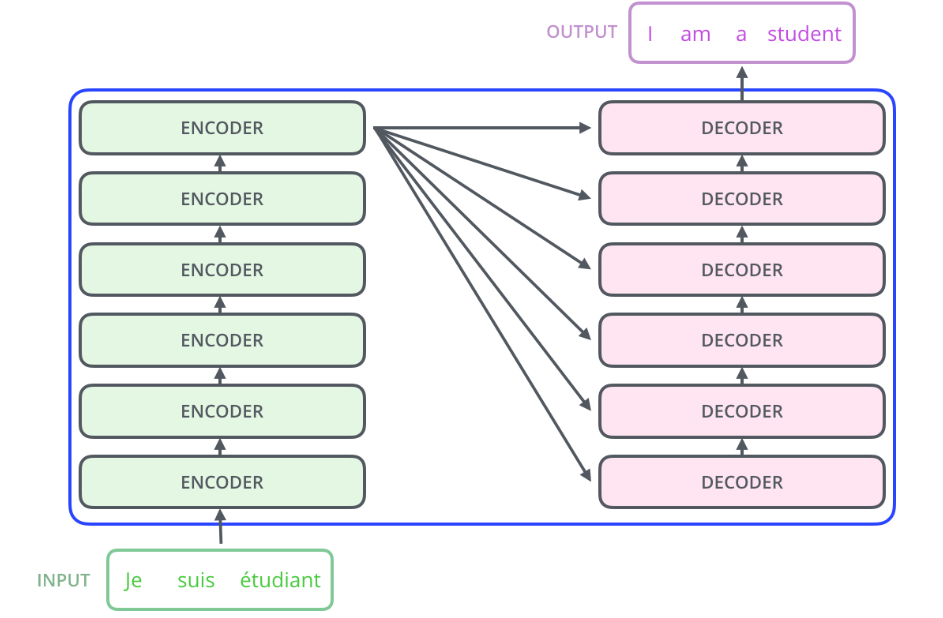
下图为完整的Transformer结构,拆解为Encoder和Decoer两部分分析。

4.1 Encoders
单独把Ecoder拿出来看,里面的工作如下图所示:
?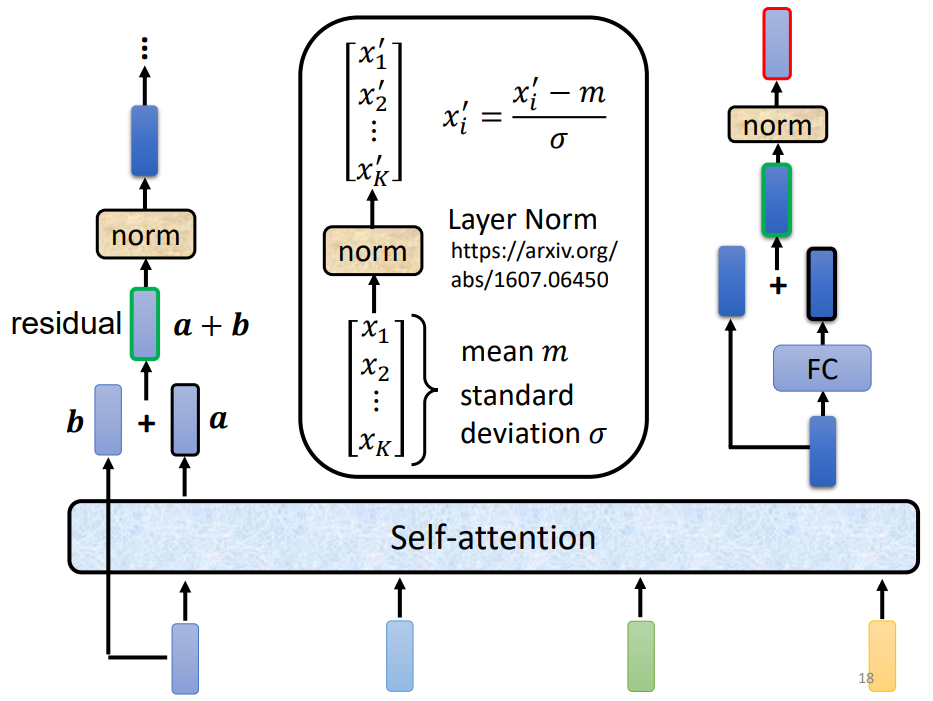
Step 1:输入4个向量(词向量+位置向量之后的向量),然后进行Self-attention,得到输出a
Step 2:对a和b做residual connection(残差连接),即将输出a与输入b相加。通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分。
Step 3:将resudual connection的结果进行layer normalization
这里layer normalization就是层标准化,方式为先算出各层均值和标准差,再代入公式:
?Step 2和Step 3就是下图中黄色模块的Add&Norm
Step 4:??将layer normalization的结果输入到Feed Forward层
Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数,对应的公式如下:
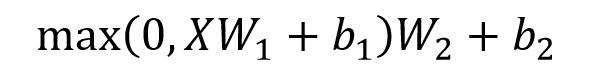
X是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
Step 5:?Feed Forward层的输出再做一个residual connection和layer normalization,最终得到encoder的输出
通过上面的步骤就可以构造出一个 Encoder block,Encoder block 接收输入矩阵?X(n×d)?,并输出一个矩阵?O(n×d)?。通过多个 Encoder block 叠加就可以组成 Encoders。
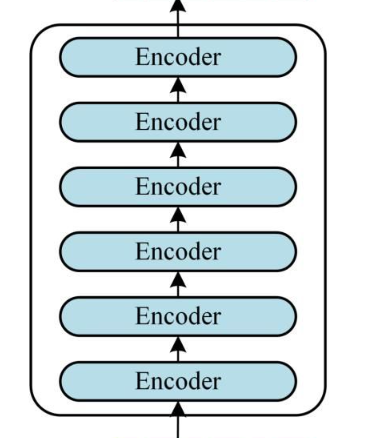
?真正的Transformer一般由多个Encoder block组成。
4.2 Decoders

4.2.1 Masked Multi-Head Attention
Mask Self-Attention在上面已经介绍了,下面介绍一下这个模块的具体步骤:
Step 1:先明确输入矩阵、Mask矩阵
输入矩阵如果包含n个单词的表示向量,Mask?是一个 n×n 的矩阵。
例如:输入为?"<Begin> I have a cat" (0, 1, 2, 3, 4) 五个单词,Mask?是一个 5×5 的矩阵。
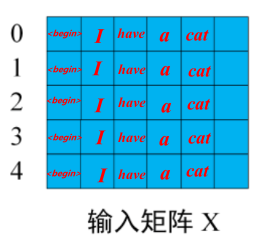
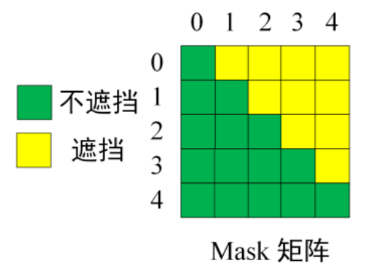
?掩码后:
?
用 0 1 2 3 4 5 分别表示 "<Begin> I have a cat <end>",在?Mask?可以发现输入部分单词 0 只能使用单词 0 的信息去预测单词I,而单词 1 的位置可以使用单词 0, 1 的信息去预测have,即只能使用之前的信息预测下一个。
?Step 2:
接下来的操作和之前的 Self-Attention 一样,通过输入矩阵X分别乘对应权重矩阵,计算得到Q,K,V矩阵。然后计算Q和??的乘积?
?。
?
Step 3: 计算掩码后的?矩阵
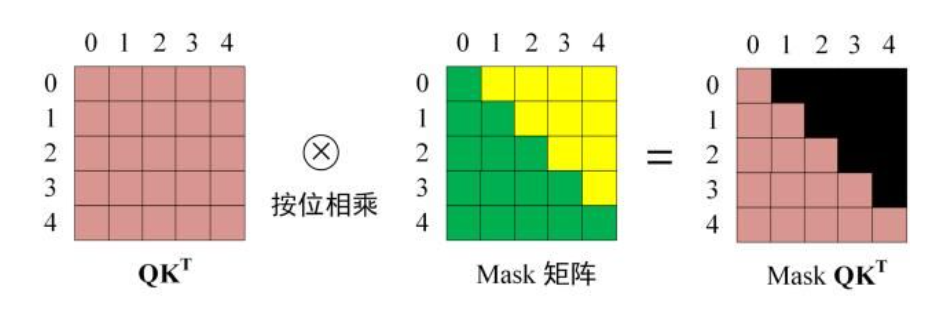
先对进行掩码操作,得到Mask
,接着用遮挡后的矩阵进行Softmax,计算attention score,每一行的和都为 1。但是单词 0 在单词 1, 2, 3, 4 上的 attention score 都为 0。
类似下图:

Step 4:?
用Softmax之后的Mask 矩阵与矩阵V相乘,得到输出Z
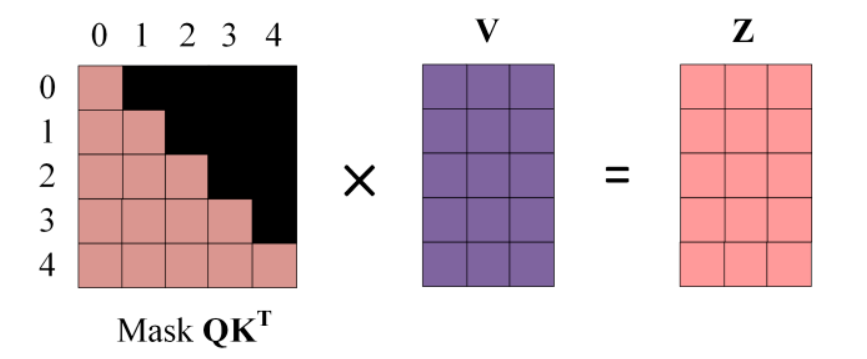
单词 1 的输出向量?Z1?是只包含单词 1 信息的。
Step 5:
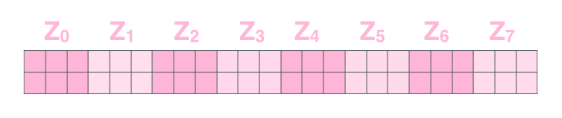
通过上述步骤就可以得到一个 Mask Self-Attention 的输出矩阵?Zi?,然后和 Encoder 类似,通过 Multi-Head Attention 拼接多个输出Zi?然后计算得到第一个 Multi-Head Attention 的输出Z,Z与输入X维度一样。
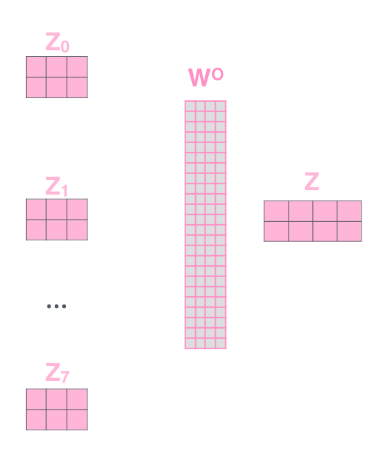
假如得到了8个特征矩阵,将得到的的8个特征矩阵[Z0,Z1,Z2,Z3,Z4,Z5,Z6,Z7]拼接起来,得到一个维度较高的特征矩阵
再通过一个全连接层乘以降维矩阵Wo,得到我们需要的特征矩阵Z。
4.2.2 Cross Attention
之所以称为交叉注意力,是因为 向量 q , k , v? 不是来自同一个模块。
Decoder中第二个Multi-head Attention和encoder中的区别不大,主要区别在输出不同,这个模块的输入K,V矩阵不是使用上一个Mask Multi-head Attetion的输出计算的,而是使用了Encoder的最终输出里的信息计算的。

详细步骤:

Step 1:
Mask Multi-head Attetion模块计算出来的最终输出作为Q,与Encoder中的K相乘求注意力分数矩阵A
Step 2:
注意力分数矩阵A与Encoder中的V矩阵相乘求和得到第二个Multi-head Attention的输出,这里设为Z'
Step 3:
这里并不是直接将第二个Multi-head Attention的输出Z'?投入到Feed Foward里面,而是和Masked Multi-Head Attention?的输出Z做一个residual connection(残差连接),即Add&Norm层还需要之前masked模块的输出,即做一个Z+Z'再layer normalization,和Encoder的Add&Norm一样,只是输入不同。
这里Add&Norm层的输出作为cross attention模块最终的输出。
4.3.3 Feed Foward

cross attention模块的输出经过下一个全连接层,得到输出Z''接着再做一步残差操作,这里是全连接层的输出Z''+cross attention模块的输出Z',再进行层归一化,得到一个decoder模块的输出Z'''
4.3.4 Decoders
上面三大步是一个decoder模块的过程,N个decoder组合在一起才是Transformer的decoders模块,原论文中是6个decoder叠加在一起。
还有Decoder中cross attention里用到的Encoder中的K,V并不是一个Encoder模块的输出,也是N个Encoder模块叠加后的最终K,V, 而且这里K和V会传给每一个decoder的cross attention模块。
4.3.5 最终输出
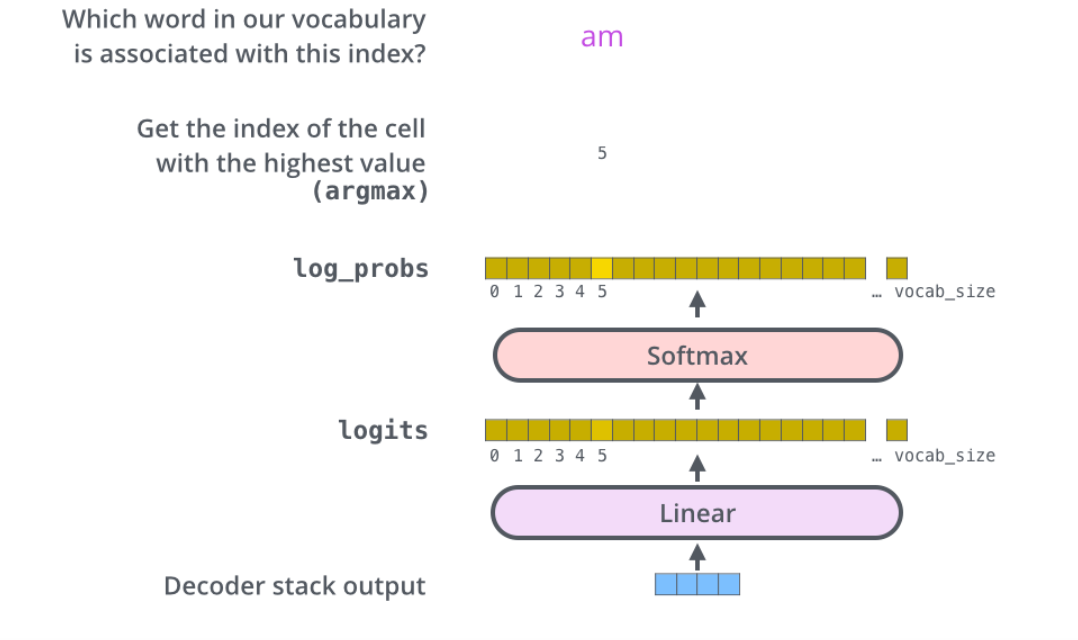
6个Decoder部分组成的Decoders执行完成以后输出特征词向量序列,还需通过Linear and Softmax Layer层将其转换成我们需要的词输出。

Step1:Linear layer
Linear layer是一个简单的全连接神经网络,它将Decoder中输出的特征向量序列映射成一个logits向量。假设我们的模型内置了10000个“输出词汇”,那么logits将有10000个单元格的大小,每个单元格都对应了唯一单词的分数。
Step 2:Softmax
接着将logits向量输入softmax层,将这些分数进行归一化处理转换成对应的概率,选择概率值最大的单元格对应的单词输出,这就是我们需要输出的词汇。
参考:
?Transformer模型详解(图解最完整版) - 知乎 (zhihu.com)
(8条消息) Transformer Decoder_weixin_42418688的博客-CSDN博客_transformer的decoder