前言
之前本来想要做基于ZCU106的Vitis-AI开发,但是官方对106缺少相关文档说明,而我需要移植的yolov5模型需要使用Vitis-AI的2.0往后的版本来支持更新的pytorch版本,相对应的也需要更新Vitis等工具的版本,所以在缺少参考资料的情况下我选择找实验室换成了ZCU102开发板先把基本流程走一遍,这篇博客就记录了我移植yolov5模型的整个过程。
开发环境
硬件环境:Zcu102开发板
PC机操作系统:Ubuntu18.04.4(错误的Ubuntu版本会让Xilinx相关软件报各种奇怪的错误,Xilinx相关工具支持的Ubuntu版本在各个技术文档里面都有说明,经典反例:Ubuntu18.04.6就不是Xilinx支持的系统,但是是在官网自动下载的Ubuntu18系统)
PC机目标检测模型运行环境:Pytorch1.8.0+Cuda11.1
PC机Xilinx相关开发环境:Vitis2022.1+Petalinux2022.1+Xilinx Runtime2022.1+Vitis-AI2.5.0
目标检测模型:Yolov5(6.0版本)
整体流程
模型移植的整体流程如下图:
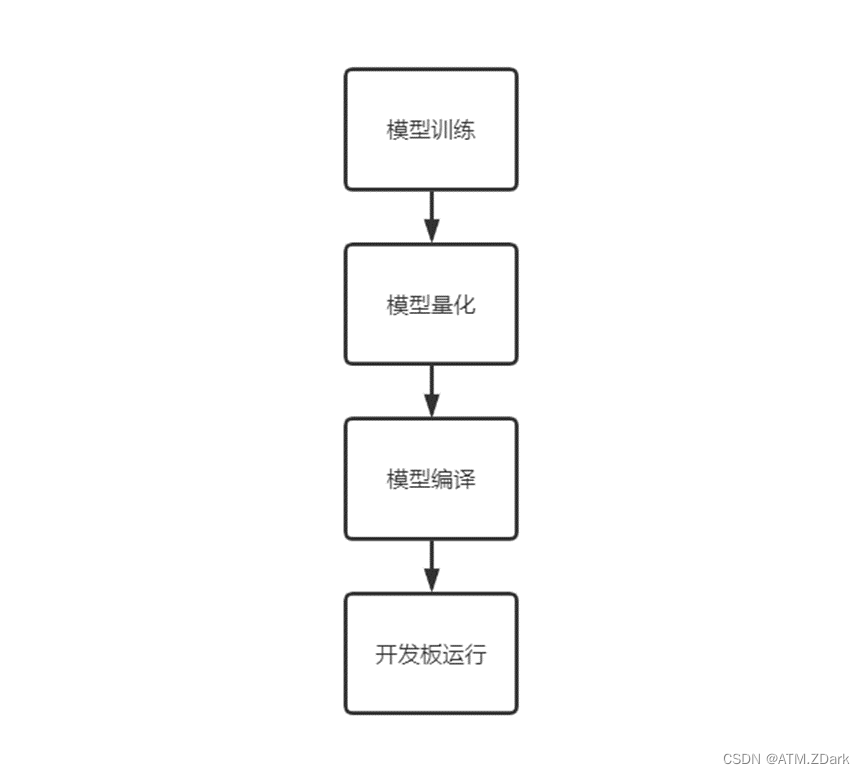
1.模型训练
训练前,先查阅Zcu102对应的DPUCZDX8G产品指南,了解到该DPU支持的神经网络算子如下图所示(文档中还有对各个算子的输入输出大小的限制,这里没有列出来,如果有自己改动yolov5模型的算子的话,请对照其中内容做详细比对):

由于yolov5的6.0版本激活函数已经被是SiLU函数了,而该DPU是不支持该激活函数的,在Vitis-AI的定制OP功能中应该可以实现SiLU函数,但是我还没有摸索清楚,所以这里将模型中的SiLU激活函数替换回了老版本yolov5模型的LeakyReLU函数。具体需要修改的文件为common.py和experimental.py文件,作如下修改。我一共修改了3处激活函数,解决了在量化时因为SiLU激活函数报错的问题。
# 修改前
self.act = nn.SiLU
# 修改后
self.act = nn.LeakyReLU(0.1, inplace=True)
修改完激活函数后,只需要按照yolov5模型正常方法进行训练即可。得到一个针对自己的数据集有目标检测能力的yolov5模型。
2.模型量化
UG1414文档中提到了模型量化的全过程,流程图如下:
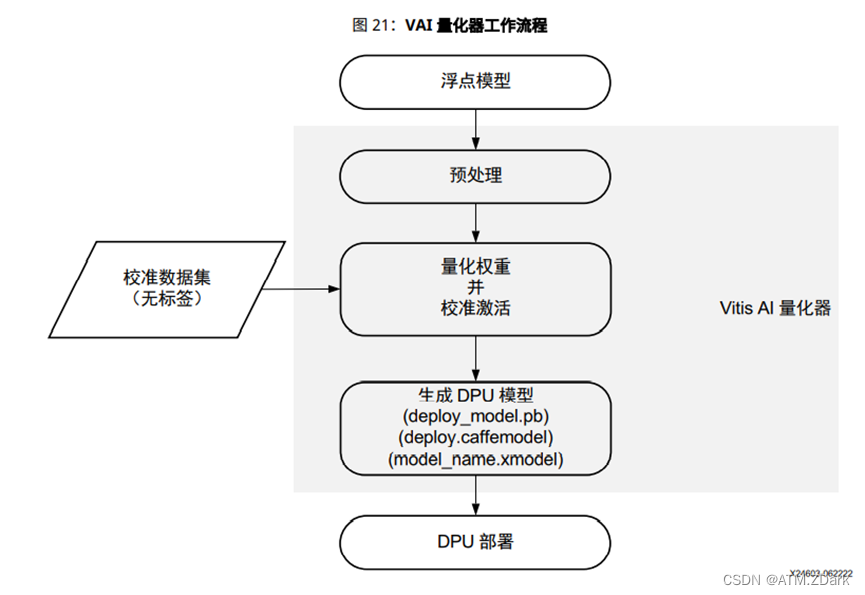
同时,文档中提到了在对用户自定义模型进行量化时需要做到:

这里就需要从代码层面来分析yolov5模型的特征提取过程,整个特征提取过程都是直接使用pytorch的torch张量的相关算子对数据进行处理的,但是在检测层,有一段对最终的三层特征进行处理的代码没有使用torch张量的相关算子,所以在对模型做量化时,需要注释掉这一段代码,并将其添加在检测函数中。该代码位于yolo.py文件的Detect类中,如下所示:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x[i](bs,self.no * self.na,20,20) to x[i](bs,self.na,20,20,self.no)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid() # (tensor): (b, self.na, h, w, self.no)
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
z.append(y.view(bs, -1, self.no)) # z (list[P3_pred]): Torch.Size(b, n_anchors, self.no)
return x if self.training else (torch.cat(z, 1), x)
修改后如下所示:
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x[i](bs,self.no * self.na,20,20) to x[i](bs,self.na,20,20,self.no)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
return x
在量化时,需要将这段代码写到补充到量化后的模型输出之后,才能继续使用yolov5后续的特征分析,得到目标检测结果,这段代码中还用到Detect类中的_make_grid函数,也需要写进量化程序中,如下图所示。这里主要是要把Detect类中的用到的相关参数都搬出来,如果你自定义的yolov5模型改动了这些参数,那就也需要跟着改。
# 模型推理
x=model(im) # 这里的model已经是量化后的模型了,x代表量化后模型的输出
nc = 11 # 1
no = nc + 5 + 180
anchors = [[1.25, 1.625, 2, 3.75, 4.125, 2.875], [1.875, 3.8125, 3.875, 2.8125, 3.6875, 7.4375], [3.625, 2.8125, 4.875, 6.1875, 11.65625, 10.1875]]
nl = 3 # number of detection layers
na = 3 # number of anchors
grid = [torch.zeros(1).to(device)] * nl # init grid
anchors = torch.tensor(anchors).float().to(device).view(nl, -1, 2)
anchor_grid=[torch.zeros(1).to(device)] * nl
stride = [8, 16, 32]
z = []
for i in range(nl):
bs, _, ny, nx, _no = x[i].shape
if grid[i].shape[2:4] != x[i].shape[2:4]:
grid[i], anchor_grid[i] = _make_grid(anchors, stride, nx, ny, i)
y = x[i].sigmoid() # (tensor): (b, self.na, h, w, self.no)
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + grid[i]) * stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor_grid[i] # wh
z.append(y.view(bs, -1, no)) # z (list[P3_pred]): Torch.Size(b, n_anchors, self.no)
out, train_out = torch.cat(z, 1), x
def _make_grid(anchors,stride,nx=20, ny=20, i=0):
d = anchors[i].device
shape = 1, 3, ny, nx, 2
y, x = torch.arange(ny, device=d), torch.arange(nx, device=d)
yv, xv = torch.meshgrid([y, x])
grid = torch.stack((xv, yv), 2).expand(shape).float() # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (anchors[i].clone() * stride[i]).view((1, 3, 1, 1, 2)).expand(shape).float()
return grid, anchor_grid
按照官方文档要求对yolov5模型进行调整后,接着参考一下官方提供的pytorch模型量化代码(minst数据集手写体识别)来写一个量化脚本。量化分为两步,第一步生成量化设置文件:
from pytorch_nndct.apis import torch_quantizer
# 加载yolov5模型
model = DetectMultiBackend(file_path)
input = torch.randn([1, 3, 1024, 1024],device=device)
quantizer = torch_quantizer(
quant_mode, model, (input), device=device,bitwidth=8)
quant_model = quantizer.quant_model
quant_model = quant_model.to(device)
# 运行量化后模型,evaluate函数参考yolov5的val.py和之前提到的特征处理部分做修改即可
print(evaluate(model=quant_model))
# 生成量化设置文件
quantizer.export_quant_config()
第二步生成量化后的xmodel模型:
from pytorch_nndct.apis import torch_quantizer
# 加载yolov5模型
model = DetectPrunedMultiBackend(file_path)
input = torch.randn([1, 3, 1024, 1024],device=device)
quantizer = torch_quantizer(
quant_mode, model, (input), device=device,bitwidth=8)
quant_model = quantizer.quant_model
quant_model = quant_model.to(device)
print(evaluate(model=quant_model))
# 生成xmodel模型
if deploy:
quantizer.export_xmodel(deploy_check=False)
这两段代码其实很接近,主要是由于官方提供的pytorch模型量化代码还有有一部分内容用于对量化后的模型进行快速微调,放到这两步中,第一步用于训练量化后的模型并快速微调量化后参数,第二步直接读取第一步保存的参数生成xmodel文件。但是由于缺少对该API函数的说明,所以我还没有摸清楚这里的模型训练损失应该怎么整,再加上我给我自己的yolov5模型添加的改动里面对损失函数的改动较大,所以暂时搁置了快速微调功能,如果有大佬会用的话,欢迎在评论区中赐教。
写好相关python脚本后,需要在vitis-AI的docker环境下来运行,我使用的是目前最新的vitis-AI2.5,docker镜像为cpu版本。在docker中的pytorch环境下运行模型量化脚本,得到一个编译前的xmodel文件,在后续过程中需要将该模型编译为ZCU102板子对应的DPUCZDX8G版本。只不过我为了能够能更好地调试量化过程,选择了将Vitis-AI的量化器的python源码安装到了我的Ubuntu电脑的conda环境中,pytorch版本的Vitis-AI量化器源码位于该目录下,在conda环境下安装这个部分,就可以在docker外使用Vitis-AI量化器了,便于调试。
3.模型编译
这一步其实挺轻松的,在docker中的pytorch环境下使用pytorch模型的编译器工具vai_c_xir对上一步生成的xmodel文件做编译即可。我使用的指令如下所示。其中-x参数指定了上一步得到的xmodel文件,-a参数指定了DPU和开发板的架构文件,-o参数指定了输出结果的目录,-n参数指定了输出模型的名称。这一步不报错的话,会得到一个拥有1个dpu字图(subgraph)的模型,正确的编译情况下输出如下图所示:
vai_c_xir -x ./DetectMultiBackend_int.xmodel -a /opt/vitis_ai/compiler/arch/DPUCZDX8G/ZCU102/arch.json -o ./ -n model
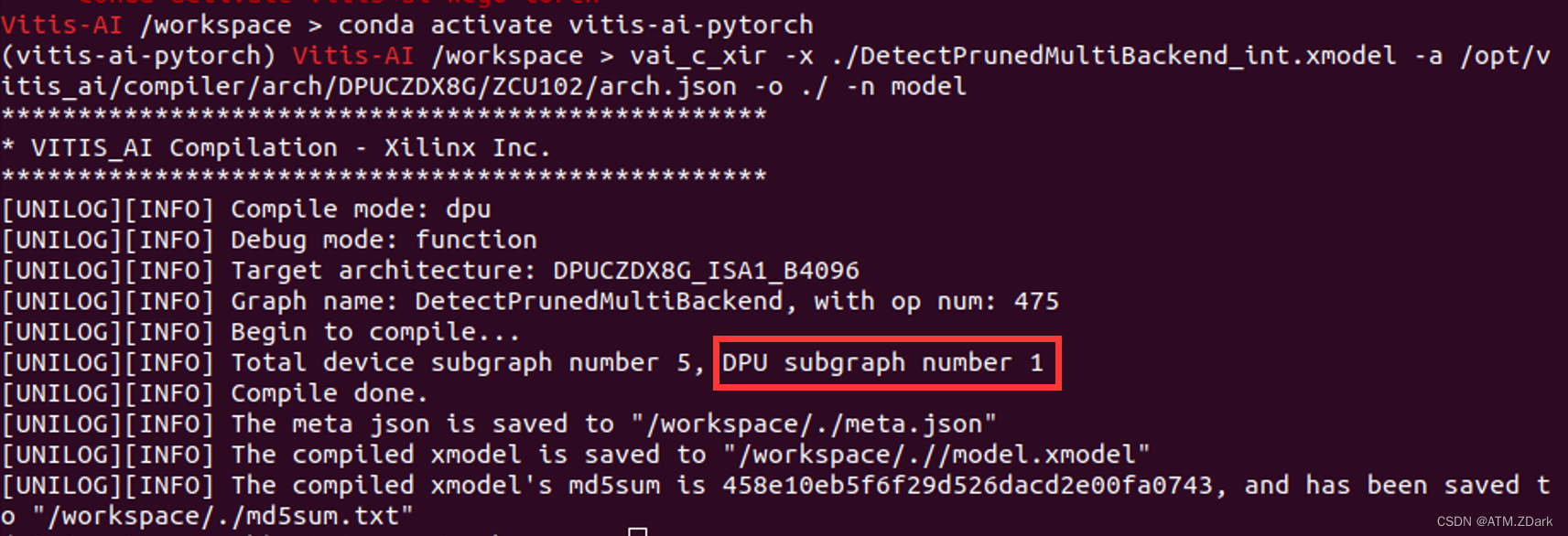
如果你在编译时得到了一个有多个DPU子图的模型,说明你的模型并没有被完整的量化编译过来,原因有两点。第一点是没有按要求将前传方法以外的函数全部移出去,第二点是模型中有DPU不能识别的算子,这两点都会导致在量化编译中将模型拆开成多个子图,运行这样的模型需要自己在代码中按顺序读取多个子图的输出并补充没有被量化编译的函数/算子,这样会极大地加大工作量,非常麻烦。
我编译后的模型是编译前模型的1/3左右大小,仅供参考。
4.开发板运行
得到编译模型之后,就需要准备开发板运行的环境了。
第一步是给开发板布置嵌入式系统。ZCU102的官方指导很多,在UG1414文档中直接下载ZCU102的嵌入式系统镜像即可,该镜像为2022.1版本,在PL端添加了DPU设备,在PS端也设置了驱动,属于是下载即用的DPU开发嵌入式环境。下载完后使用SD卡烧写工具把镜像烧写到SD卡上,就制作好ZCU102的嵌入式系统启动盘了。
开发板选择SD卡启动模式,PC机使用minicom对开发板进行uart调试,配置好网络接口后让开发板可以连通外网,这些就不细讲了,网上的相关资料也挺多的。
第二步是把torch编译到开发板上的python环境中。虽然编译后的模型不使用torch.nn算子进行运行,但是yolov5代码的预处理和后处理部分用到了很多使用tensor张量的相关函数来对数据做处理,由于没有时间一点点改成numpy,所以我还是选择了把pytorch编译到开发板上。我这里直接选择把源码copy到板子上,在板子上做编译。按照github上的流程先下载源码并git到全部组件后,在编译时使用如下指令(因为板子上缺这缺那,所以不能完全按照github上那些简单的指令来编译安装torch),编译时间大概是6个小时左右:
git submodule update --remote third_party/protobuf
USE_CUDA=0 USE_MKLDNN=0 USE_QNNPACK=0 USE_NNPACK=0 USE_DISTRIBUTED=0 BUILD_CAFFE2=0 BUILD_CAFFE2_OPS=0 python3 setup.py build
python3 setup.py develop && python3 -c "import torch"
第三步是安装其他的yolov5 python依赖。这些依赖中只有pytorch是用到了C++,其他的都是纯py,所以只有torch需要用开发板自带的编译器做编译,其他的直接用pip安装whl文件即可。(PS:有一点要吐槽的是这个镜像里面不带pip,所以还需要先自己安装pip,在这个过程中需要用date指令提前给板子设置好时间,最好是保持和日期同步,不然下载东西的时候会报奇怪的错误)。
第四步,在环境全部准备好之后,就只需要一个板子上的测试脚本了,官方有一个针对pytorch模型的测试脚本,用来将模型放入DPU并运行的相关API都可以参考该脚本来使用,相关代码如下:
def get_child_subgraph_dpu(graph: "Graph") -> List["Subgraph"]:
assert graph is not None, "'graph' should not be None."
root_subgraph = graph.get_root_subgraph()
assert (root_subgraph is not None), "Failed to get root subgraph of input Graph object."
if root_subgraph.is_leaf:
return []
child_subgraphs = root_subgraph.toposort_child_subgraph()
assert child_subgraphs is not None and len(child_subgraphs) > 0
return [
cs
for cs in child_subgraphs
if cs.has_attr("device") and cs.get_attr("device").upper() == "DPU"
]
# 读取模型的全部子图(这里量化后只有一个子图),将模型加载到DPU中
g = xir.Graph.deserialize(model)
subgraphs = get_child_subgraph_dpu(g)
all_dpu_runners = []
for i in range(threads):
all_dpu_runners.append(vart.Runner.create_runner(subgraphs[0], "run"))
在这里我们需要根据DPU模型的输入输出格式来改动yolov5的测试程序val.py。在量化过程中,模型的输入和输出都由量化前的浮点数变为了量化后的定点数,其小数点位置都保存在模型中。为了方便观察,这里使用netron工具打开xmodel文件查看模型结构。
输入模块如下图。这里有两点非常重要,第一点是输入数据为8位定点数,小数点在第7位,针对这一点,yolov5模型输入的本来是归一化的浮点数图像数据,这里就需要乘2的7次幂128后将数据格式改变为8位整形,这样就实现了浮点数转定点数的过程,具体代码如下所示,第一段代码读取模型输入的小数点位置,第二段对输入图像做处理。(我这里直接把第一步得到的input_scale加入到了dataloader类中,在下一步对图像做维度变换时一并做了乘算和格式转换,具体请看下一点的相关代码)
# 读取量化后模型对输入的定点数数据的小数点位置,得出在浮点数转定点数时需要乘的系数input_scale
input_fixpos = all_dpu_runners[0].get_input_tensors()[0].get_attr("fix_point")
input_scale = 2 ** input_fixpos
第二点是输入图像的维度为batchsize×w×h×3(1×1024×1024×3),而我们使用dataloader读取的图像数据维度为1×3×1024×1024。所以需要修改dataloader类,让输入符合DPU模型的输入,在datasets.py的LoadImagesAndLabels类中修改__getitem__方法,在末尾添加这样一段代码,就将维度和数据存储格式都修改好了。
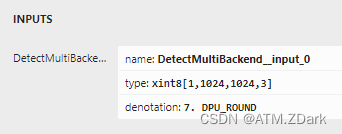
# 将图像维度调整到DPU要求的定点输入
img = torch.from_numpy(img)
img = img.permute(1, 2, 0).float().numpy() / 255 * self.inputscale + 0.5
img = img.astype(np.int8)
输出一共有三层特征层,这里以最小的一层举例:
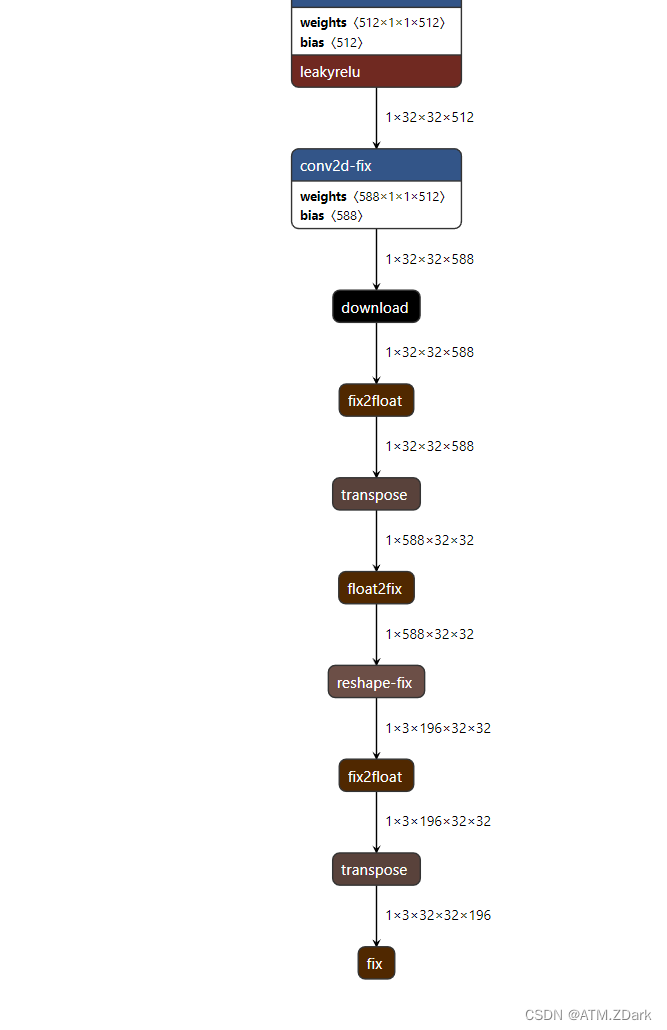
重点:1.DPU的输出为download处的输出1×32×32×588,而并非fix节点处的1×3×32×32×196
所以在后续处理中,需要我们将1×32×32×588转变为1×3×32×32×196,这里需要参考原始yolov5模型的流程,先将1×32×32×588转为1×588×32×32,再转为1×3×196×32×32,最后转为1×3×32×32×196。
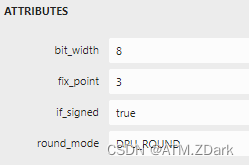
2.在fix节点可以看到该输出为8位有符号定点数,小数点为第3位,实际上存储格式为整形。所以在后续处理中,需要将该整形数据转化为浮点数据,并且除以2的3次幂8,才能用于后续的NMS等后处理。
3.三个不同的特征层的定点数据小数点可能不一样!!!!我这里就是其中两层小数点位为3,一层为4,这一点千万要注意。
具体代码如下所示:
output[0] = (output[0].float() / 8).permute(0, 3, 1, 2).view(1, 3, 196, 128, 128).permute(0, 1, 3, 4, 2)
output[1] = (output[1].float() / 8).permute(0, 3, 1, 2).view(1, 3, 196, 64, 64).permute(0, 1, 3, 4, 2)
output[2] = (output[2].float() / 16).permute(0, 3, 1, 2).view(1, 3, 196, 32, 32).permute(0, 1, 3, 4, 2)
结语
完成这几步之后,就已经可以在ZCU102开发板上解析出目标检测的目标框了,目前特征提取的速率能够在输入为1024×1024图像的前提下达到30fps,检测性能也没有很大的影响,算是达成了一个阶段性目标。而在博客中分享的这些差不多就是我在这个过程中踩过的主要坑点,踩坑的关键原因还是因为相关手册对这些输入输出的维度以及格式的说明太少了,每一步都需要我去自己用各种工具翻来覆去地看,然后来揣度官方给的那几个基本没注释的代码的含义,这个过程虽然很麻烦,但是也帮我加深了对yolov5模型的数据处理的理解,也算是学到了点东西吧。完整的代码因为一些原因不能在这里公开,所以如果各位看官有没有看懂的地方,希望能直接在评论区提问,我也会尽我所能,和大家一起交流学习。后续我还会继续在这一个部分上做一些工作,也希望有相同目标的小伙伴能够多多发言讨论,相互指教。