0、所需了解的知识
数据集
- 数据集的类别已有不需要另外指定,这是因为在读取之前已有数据集的时候,数据集中就会包含了许多数据,其中结构如下:
- 包括类别序号以及类别名字

预训练模型或者模型
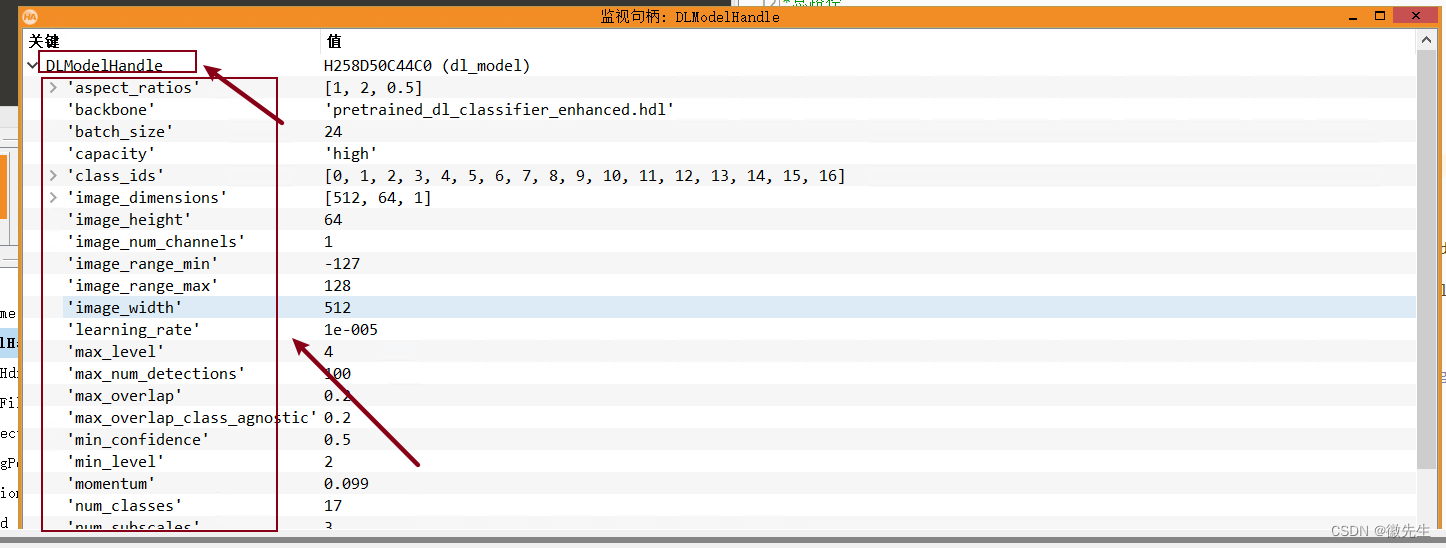
预训练模型也有了基本的参数,如下所示:
训练集、验证集以及测试集的区别:
一般会认为训练集、验证集以及测试集没有很大区别,但是在halcon由于比较固定和标准,所以三者的作用是区分开来的,比如:
- 训练集:用来对模型的数据进行训练以及模型调优;
- 验证集:对模型的超参数进行调优;
- 测试集:检查模型的泛化能力;
数据集的新建生成,在自动标注的时候
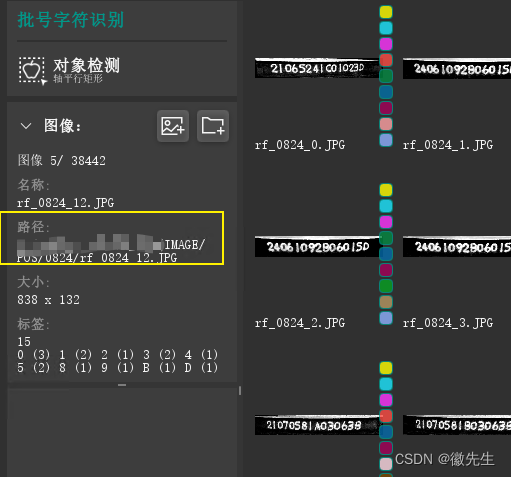
halcon数据集中文件路径可以链接不同的文件夹和文件信息,这些路径形成了一个数组,并且还有一个属性是包含了每一个图片的标注信息以及路径,所以建立新的数据集最好是重新指定一个文件夹,不然在软件中不好查看,需要一一指定
- 如下所示的路径
一、整体流程
创建模型或者加载模型――>加载数据集并进行预处理――>训练参数等的设置――>评估训练好的模型――>测试模型数据
1.创建模型或者加载模型
可以完全重新创建模型也可以通过加载预训练模型
create_dl_model_detection或者read_dl_model
1.创建模型
dev_update_off ()
*** 创建检测模型 ***
**设置参数
*必须的参数
Backbone := 'pretrained_dl_classifier_compact.hdl'
*class_ids的数量,标签的总类别数量
NumClasses := 6
*模型所需图片的规格参数
ImageWidth := 512
ImageHeight := 320
ImageNumChannels := 3
*
MinLevel := 2
MaxLevel := 4
NumSubscales := 3
AspectRatios := [1.0,0.5,2.0]
*容量参数
Capacity := 'medium'
*创建模型参数字典
create_dict (DLModelDetectionParam)
set_dict_tuple (DLModelDetectionParam, 'image_width', ImageWidth)
set_dict_tuple (DLModelDetectionParam, 'image_height', ImageHeight)
set_dict_tuple (DLModelDetectionParam, 'image_num_channels', ImageNumChannels)
set_dict_tuple (DLModelDetectionParam, 'min_level', MinLevel)
set_dict_tuple (DLModelDetectionParam, 'max_level', MaxLevel)
set_dict_tuple (DLModelDetectionParam, 'num_subscales', NumSubscales)
set_dict_tuple (DLModelDetectionParam, 'aspect_ratios', AspectRatios)
set_dict_tuple (DLModelDetectionParam, 'capacity', Capacity)
* 创建模型
create_dl_model_detection (Backbone, NumClasses, DLModelDetectionParam, DLModelHandle)
这里可能会怀着疑问为什么创建模型参数字典的那些属性,应该从哪里去看,其实官方都有相应的案例,在帮助文档中就可以找到,比如在目标检测案例中就有参数设置:
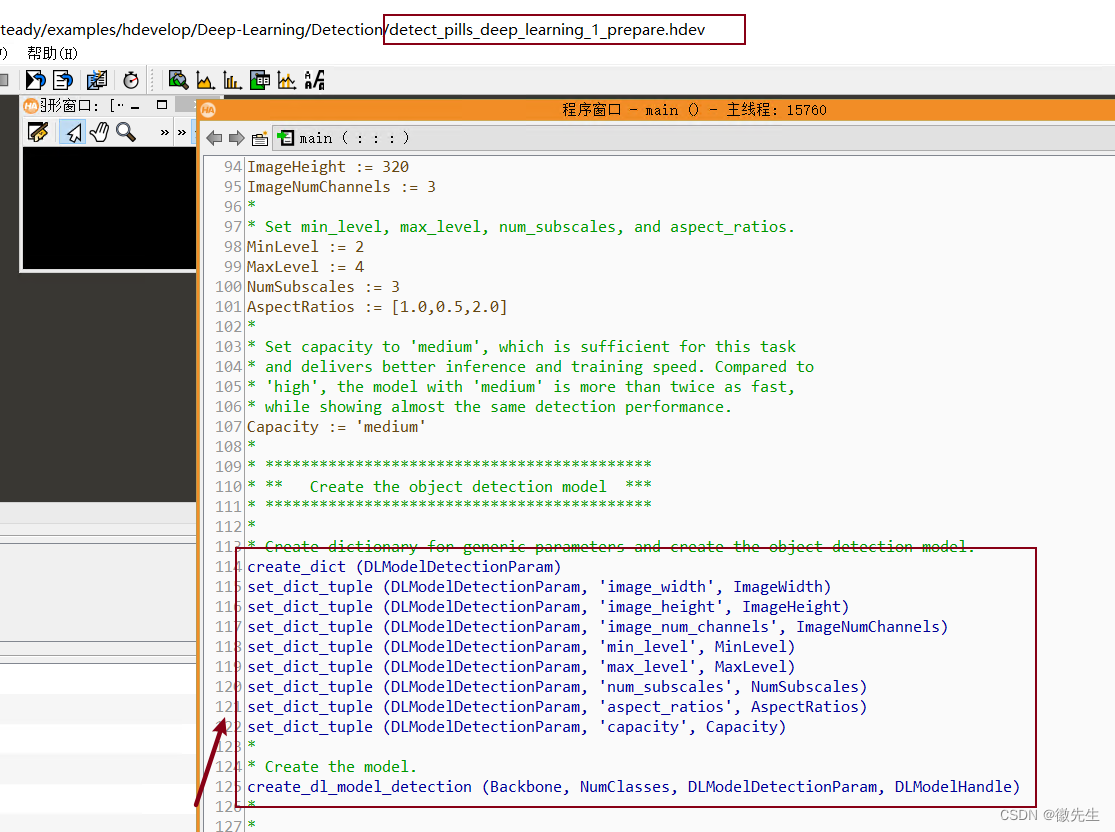
在操作手册中对应深度学习章节中会有文件名:

然后到安装路径中找到即可:C:\Users\Public\Documents\MVTec\HALCON-18.11-Steady\examples\hdevelop\Deep-Learning\Detection
核心代码就是create_dl_model_detection (Backbone, NumClasses, DLModelDetectionParam, DLModelHandle)
2.如何通过加载预训练模型加载模型
预加载模型可以直接从之前已有的模型获取相关参数,然后创建模型并设置参数即可
read_dl_model (ModelName, DLModelHandle)
从已有模型获取参数
#读取
ModelName := DataDir+'/Train/CFY/model/RF_best_dl_model_CFY_1.hdl'
read_dl_model (ModelName, DLModelHandle)
#根据自己的需要设置相关的参数,其实已经有预训练模型,大部分是不需要进行设置的
set_dl_model_param (DLModelHandle, 'runtime', 'gpu')
set_dl_model_param (DLModelHandle, 'gpu', 0)
set_dl_model_param (DLModelHandle, 'batch_size',24)
set_dl_model_param (DLModelHandle, 'max_overlap', 0.2)
set_dl_model_param (DLModelHandle, 'max_overlap_class_agnostic', 0.2)
set_dl_model_param (DLModelHandle, 'learning_rate', 0.001)
# 创建在模型中使用的训练参数字典
#参数:模型、将训练模型的时期数(越大训练效果越好)、定义将多少时间传递给下一个模型评估
#是否显示训练进度、设置随机种子、输出参数的名称、输出参数的字典、输出句柄
create_dl_train_param (DLModelHandle, 20, 1, 'true', 42, [], [], TrainParam)
2.加载数据集并进行预处理
读取数据集、切分数据集比例以及预处理相关参数
read_dict、split_dl_dataset、预处理(get_dl_model_param、create_dl_preprocess_param_from_model、preprocess_dl_dataset、dev_display_dl_data)
设置比例分割并进行预处理
#读取数据集
read_dict (PillBagHdictFile, [], [], DLDataset)
#从模型中获取预处理参数
create_dict (GenParam)
set_dict_tuple (GenParam, 'overwrite_files', true)
create_dl_preprocess_param_from_model (DLModelHandle, 'false', 'full_domain', [], [], [], DLPreprocessParam)
#预处理
preprocess_dl_dataset (DLDataset, DataDirectory, DLPreprocessParam, GenParam, DLDatasetFilename)
3.进行训练
分为两步,1、设置参数:比如超参以及数据增强参数;2、进行训练
train_dl_model。
训练
#在数据集上训练一个基于深度学习的模型
train_dl_model (DLDataset, DLModelHandle, TrainParam, 0, TrainResults, TrainInfos, EvaluationInfos)
4.进行模型评估
evaluate_dl_model评估以及dev_display_detection_detailed_evaluation可视化结果
*** 评估 ***
create_dict (WindowDict)
create_dict (GenParamEval)
set_dict_tuple (GenParamEval, 'detailed_evaluation', true)
set_dict_tuple (GenParamEval, 'show_progress', true)
*对选定的DLDataset样本评估DLModelHandle给出的模型。
evaluate_dl_model (DLDataset, DLModelHandle, 'split', 'test', GenParamEval, EvaluationResult, EvalParams)
*
create_dict (DisplayMode)
set_dict_tuple (DisplayMode, 'display_mode', ['pie_charts_precision','pie_charts_recall'])
*可视化类型检测模型的详细评估结果
dev_display_detection_detailed_evaluation (EvaluationResult, EvalParams, DisplayMode, WindowDict)
stop ()
*关闭字典中包含句柄的所有窗口。
dev_display_dl_data_close_windows (WindowDict)