深度学习模型被广泛应用于各种视觉任务的同时,似乎传统的图像处理方式已经被人们渐渐遗忘,然而很多时候传统图像处理方式的稳定性和可解释性依然是深度学习模型所不能达到的。本文是CVPR2022的一篇将传统与深度相结合进行inpainting的文章。
在图像inpainting任务中,目前的深度学习模型主要面临两个问题:
1、由于是数据驱动模型,因此深度学习模型在进行inpainting时几乎都是依赖先前的训练数据。这使得其往往忽略了图像相邻像素的之间的平滑性这一基本但是极其重要的先验信息。
2、依然由于数据驱动,因此深度学习模型会对训练的图像和mask有记忆性,这导致其对不同图像以及mask会有泛化性问题。
在传统图像inpainting模型中,预测核模型是一类非常经典且有效的模型(其基本思想是一个像素点通过一个像素点周围的像素进行加权更新得到新的像素点),并且其不会受到上面两个问题的困扰。为此作者企图将预测核的方式引入到深度学习模型中,此外,相比较于传统模型,深度学习模型有着更深层次的图像特征的概念,因此作者将其进一步从图像等级的预测核推广到特征等级的预测核。
对于一个缺失图像
I
I
I,经典的预测核模型可以表示为
I
^
=
I
⊙
K
\hat{I} = I \odot K
I^=I⊙K,其中
K
∈
R
H
×
W
×
N
2
K \in R^{H \times W \times N^2 }
K∈RH×W×N2是一个预测核矩阵,具体的,对于位置为
p
p
p的像素点,其工作原理为:
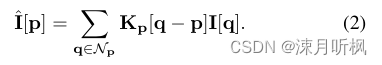
可以看到,预测核就是对目标像素点周围一定范围内的像素点进行线性加权。传统的
K
K
K通常都是人为设定的,这显然不好,因此作者在这里提出通过一个预测网络
φ
(
.
)
\varphi(.)
φ(.)来预测
K
K
K:
K
=
φ
(
I
,
M
)
K = \varphi(I,M)
K=φ(I,M)。于是就有了第一个流程图:
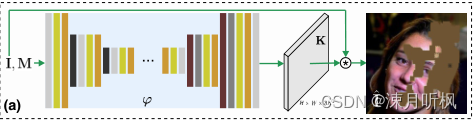
尽管这种方式在缺失率低时有一定效果,但是缺失率稍微大一点,这种方式就没法用了,这是因为预测核的组合范围(对标深度学习中的感受野)非常有限,信息无法传递到远离缺失边界的内部。为此,作者考虑了感受范围更广的特征层面,进行特征层面的预测核估计。首先为了得到图像特征,作者预设了一个自编码网络,其编码-解码表示如下:
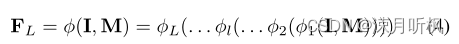

紧接着作者仿照图像层面的预测核获得方式,用网络来获得预测核:

对第
F
l
F_l
Fl?层中间特征,作者通过专属的网络来获得预测核
K
l
K_l
Kl?作用到其上
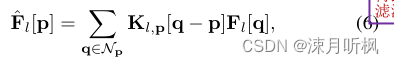
于是就有了第二个流程图:
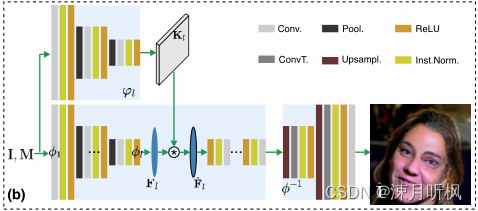
通过这种方式解决了第一种流程难以应对大缺失率的问题,但是其依然存在一些问题:
1、理论上对多层特征都进行滤波显然效果会更明显,然而每一个核的获得都要通过一个专属的网络,计算量大。
2、每个核之间的特征不能共享,使得先前的优势(已经预测的特征)无法传递下去。
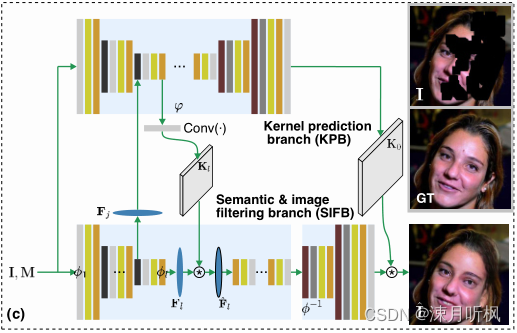
为此作者提出了一种交互的渐进式预测方法,通过一个网络的不同尺度的输出来预测不同尺度的核,并且在这个过程中更新后的图像特征会传递到核预测流程,帮助接下来的核预测:
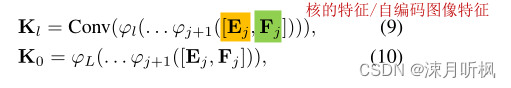
其中
E
j
E_j
Ej?是第j个尺度的预测核的特征,
F
j
F_j
Fj?是第j个尺度的图像特征,第j+1个尺度的预测核通过融合两个特征后,经过一层单独的卷积获得,于是就有了第三个流程:
这么做除了可以大大降低计算量,个人认为还有几种显而易见的好处:
1、降低了核预测流程的难度,使其可以预测的更加准确以及预测的更加和当前图像相关
2、稳定了整个训练过程
实验部分的话主要有两点:
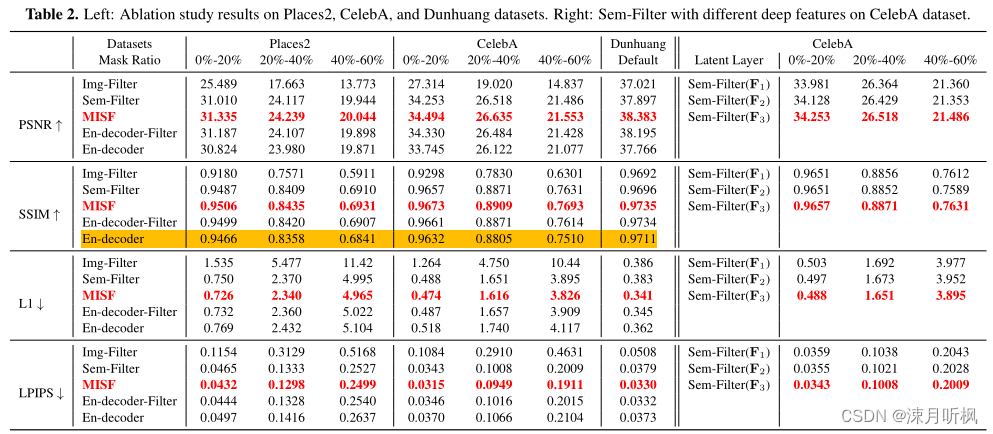
第一点是消融部分的表2对上面三种流程进行了性能比较,并且右半部分说明了滤波核添加的位置越深效果越好。

第二点是消融部分的图7。其主要表达了在自编码的过程中修复的特征在经过滤波前(绿色)和经过滤波后(红色)与真实图像的特征的相关性。可以看出仅仅是经过了一层滤波,其效果就非常明显。
‘
本人目前 烟台大学 数学与信息科学学院 研二在读,主要感兴趣的方向为:底层视觉处理,对比学习,因果推断,多模态等。感兴趣的小伙伴可以+V:w13375533677 共同进步!!!