X-Gear: Multilingual Generative Language Models for Zero-Shot Cross-Lingual Event Argument Extraction
论文:https://arxiv.org/pdf/2203.08308.pdf
0 摘要
提出了一项利用多语言预训练生成语言模型进行零样本跨语言事件论元提取(EAE)的研究。通过将EAE定义为一个语言生成任务,有效地编码了事件结构,并捕获了论元之间的依赖关系。设计了与语言无关的模板来表示事件论元结构,它与任何语言都兼容,从而促进了跨语言传输。
提出的模型利用多语言预训练生成语言模型来生成句子,用从输入段落中提取的论元填充语言不可知模板的句子。该模型在源语言上进行训练,然后直接应用于目标语言进行事件论元提取。
实验表明,该模型在零样本跨语言EAE上的性能优于目前最先进的模型。为了更好地理解使用生成语言模型进行零样本跨语言迁移EAE的优势和当前的局限性,本文提出了全面的研究和错误分析。
1 引言
事件参数提取(EAE)旨在识别作为事件论元的实体,并识别它们对应的角色。
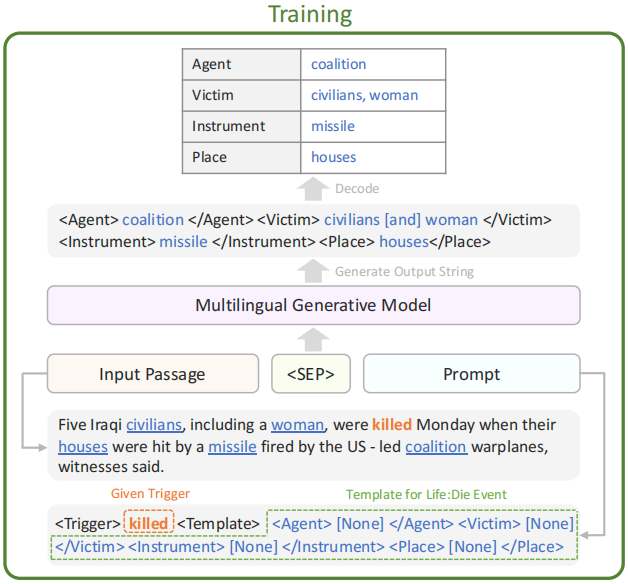
如下图所示,给冲突“destroyed” 的触发词:攻击事件(Attack),事件论元提取器需要将“commando”, “Iraq”, and “post”作为事件论元,并预测它们的角色分别为“Attacker”, “Place”, and “Target”。

如下图所示。一个跨语言事件论元提取的说明。给定任意语言的句子及其事件触发词(destroyed and 起义),该模型需要识别论元(commando, Iraq and post v.s. 军队, and 反对派)及其相应的角色(Attacker, Target, and Place)。

零样本跨语言EAE已经引起了相当多的关注,因为它消除了在少样本语言中构建EAE模型的标记数据的需求。在此设置中,模型将根据源语言中的示例进行训练,并直接在目标语言中的实例上进行测试。
最近,基于生成的模型在单语结构化预测任务上显示出了强大的性能?(Yan et al., 2021; Huang et al., 2021b; Paolini et al., 2021),包括EAE?(Li et al., 2021; Hsu et al., 2021)。这些工作原理是对预训练过的生成语言模型进行微调,以按照设计的模板生成输出,这样最终的预测就可以很容易地从输出中解码出来。与传统的基于分类的模型相比(Wang et al., 2019; Wadden et al., 2019; Lin et al., 2020),它们可以更好地捕获实体之间的结构和依赖性,因为模板提供了额外的声明性信息。
尽管基于生成的模型取得了成功,但先前作品中的模板设计是依赖于语言的,这使得它很难扩展到零样本跨语言迁移设置(Subburathinam et al., 2019; Ahmad et al., 2021)。 只是将这种在源语言上训练的模型应用于目标语言通常会产生代码转换输出,导致零样本跨语言迁移的性能很差,正如我们将在 5.4 节中经验性地展示的那样。 如何为零样本跨语言结构化预测问题设计基于语言无关生成的模型仍然是一个悬而未决的问题。
本文提出了一项研究:利用多语言预训练的生成模型进行零样本跨语言事件论元提取,并提出了X-GEAR(Cross-lingual Generative Event Argument extractoR)。给定一个输入段落(input passage)和一个精心设计的提示符(prompt),其中包含一个事件触发词和相应的语言无关模板,X-GEAR被训练生成一个句子,用论元填充语言无关模板的句子。
2 相关工作
| 不足之处 | |
| 零样本的跨语言结构化预测 | 以前大多数方法是基于分类的,与基于生成的模型相比,基于分类的模型对实体之间的依赖关系的能力更弱。 |
| 基于生成的结构化预测 | 虽然生成的模型在单语言结构化预测任务上的巨大成功,零样本跨语言有较差的性能 |
| 提示方法 | 对多语言任务的关注却很有限 |
跨语言解决方法:用了与语言无关模板
零样本的跨语言结构化预测
零样本跨语言学习消除了在低资源语言中训练模型对标记数据的需求。
研究了各种结构化预测任务,包括命名实体识别、依赖性解析、关系提取和事件论元提取。其中大多数是基于分类的模型,在多语言预训练的掩码语言模型上构建类字符。为了进一步处理语言之间的差异,其中一些需要额外的信息,如双语词典,翻译对和依赖解析树。
然而,与基于生成的模型相比,基于分类的模型对实体之间的依赖关系的能力更弱。
基于生成的结构化预测
一些工作已经证明了基于生成的模型在单语言结构化预测任务上的巨大成功,包括命名实体识别、关系提取和事件提取。然而,正如在第1节中提到的,它们设计的生成目标是依赖于语言的。
因此,直接将他们的方法应用于零样本跨语言设置将导致较差的首选性能。
提示方法
最近,人们越来越有兴趣在预先训练好的语言模型上加入提示,以指导模型的行为或引出知识。根据(Liu et al.,2021)中的分类法,可以根据语言模型的论元是否被调优以及是否引入了可训练的提示来对这些方法进行分类。
我们的方法属于修复提示和调优语言模型参数的类别。尽管在提示方法方面的研究蓬勃发展,但人们对多语言任务的关注却很有限。
3?零样本跨语言事件论元提取
本文专注于零样本跨语言 EAE。 给定一个输入段落和一个事件触发器,EAE 模型识别论元及其相应的角色。 更具体地说,如图 2 中的所示,给定input passage x 和属于事件类型 e (Life:Die) 的事件触发词 t?(killed),EAE 模型预测论元列表a = [a1, a2, ..., al] (coalition, civilians, woman, missile, houses) 和他们的相应角色r = [r1, r2, .., rl] (Agent, Victim, Victim, Instrument, Place)。
在零样本跨语言设置中,训练集 ![]() ?属于源语言,而测试集
?属于源语言,而测试集 ![]()
![]() 属于目标语言。
属于目标语言。
与单语言EAE类似,零样本跨语言EAE模型有望捕获论元之间的依赖关系,并做出结构化预测。然而,与单语言EAE不同的是,零样本跨语言EAE模型需要处理语言之间的差异(例如,语法、词序),并学习将知识从源语言转移到目标语言。
?4 模型:X-GEAR
两个挑战:(1)输入语言在训练和测试期间可能会有所不同; (2) 生成的输出字符串需要很容易地解析成最终的预测。
我们将零样本跨语言 EAE 制定为语言生成任务,并提出X-GEAR,一种跨语言生成事件论元提取器,如图下图所示。有两个挑战:(1)输入语言在训练和测试期间可能会有所不同; (2) 生成的输出字符串需要很容易地解析成最终的预测。 因此,输出字符串必须相应地反映输入语言的变化,同时保持良好的结构。
通过设计与语言无关的模板来解决这些挑战。具体来说,给定一个input passage?x和一个设计的提示符,其中包含给定的触发词t、它的事件类型e和一个与语言无关的模板,X-GEAR学习生成一个输出字符串,用从输入通道中提取的信息填充与语言无关的模板。与语言无关的模板以一种结构化的方式设计,因此从生成的输出中解析最终的论元预测a和角色预测r是容易的。此外,由于模板是语言不可知论的,它促进了跨语言迁移。
X-GEAR对多语言预训练的生成模型进行微调,如mBART-50(Tang等人,2020)或mT5(Xue等人,2021),并通过复制机制增强它们,以更好地适应输入语言的变化。
我们将介绍以下细节,包括与语言无关的模板、目标输出字符串、输入格式和训练细节。
4.1 语言不可知模板
我们为每个事件类型e创建了一个与语言无关的模板Te,其中我们列出了所有可能的关联角色,并为该事件类型e形成了一个唯一的html标记样式的模板。例如,在上图中,Life:die事件与四个角色相关联:Agent, Victim, Instrument, and Place。因此,Life:die事件的模板设计为:
<Agent>[None]</Agent><Victim>[None]</Victim><Instrument>[None]</Instrument><Place>[None]</Place>.

为了便于理解,我们使用英语单词来表示模板。然而,这些token([None],<Agent>,</Agent>,<Viictim>等)。被编码为特殊的标记,预训练模型从未见过,因此它们的表示需要从头开始学习。由于这些特殊的标记与任何语言都没有关联,也没有预先训练过,因此它们被认为是language-agnostic。
4.2 目标输出字符串
X-GEAR学习生成遵循与语言不可知的模板形式的目标输出字符串。为了组合用于训练的目标输出字符串,给定一个实例(x、t、e、a、r),我们首先为事件类型e选择与语言无关的模板Te,然后根据其角色r将Te中的所有“[None]”替换为a中相应的论元。如果一个角色有多个论元,我们将它们与一个特殊的标记“[和]”连接起来。例如,图2中的训练示例为受害者角色有两个论元(civilians 和woman),而输出字符串的相应部分将是<Victim> civilians [and] woman </Victim>.
如果对于一个角色没有相应的参数,我们在Te中保留“[None]”。通过应用此规则,图2中的训练示例的完整输出字符串将变成
<Agent> coalition </Agent><Victim> civilians[and] woman </Victim><Instrument> missile </Instrument> <Place> houses </Place>.

由于输出字符串是HTML-tag风格的,所以我们可以通过一个简单的基于规则的算法轻松地解码生成的输出字符串中的论元和角色预测。
4.3 输入格式
正如我们之前提到的,零样本跨语言 EAE 生成公式的关键是引导模型生成所需格式的输出字符串。 为了促进这种行为,我们向 X-GEAR 提供input passage x 和提示(没有在提示中显式包含事件类型 e,因为模板 Te 隐式包含此信息),如图 2 所示。提示包含模型进行预测的所有有价值的信息,包括触发器 t 和语言无关的模板。在 6.1 节中,我们将展示在提示中显式添加事件类型 e 的实验,并讨论其对跨语言的影响转移。
4.4 训练
为了使X-GEAR能够生成不同语言的句子,采用多语言预训练的生成模型作为基础模型,该模型建模给定之前生成的token和编码器c生成新token的条件概率和输入上下文,即,

?其中,xi是步骤i中解码器的输出。
Copy mechanism(复制机制)。尽管多语言预训练的生成模型可以在许多语言中生成序列,但仅仅依赖它们可能会产生hallucinating的论点(Li et al.,2021)。
因为目标输出字符串中的大多数token都出现在输入序列中,我们使用复制机制增强多语言预先训练的生成模型,以帮助X-GEAR更好地适应跨语言场景。
具体来说,我们遵循See等人(2017)来决定生成token t的条件概率,由多语言预训练的生成模型P和复制分布P
计算的词汇表分布的加权和
![]()
![]()
其中,w∈[0,1]是通过将时间步i中的解码器隐藏状态传递到一个线性层而计算出的复制概率。对于P
,它指的是由最后一个解码器层计算的(在时间步i)的交叉注意加权的输入标记的概率。然后对我们的模型进行端到端训练,但损失如下:
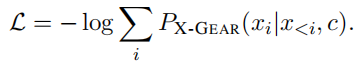
5 实验
ACE2005(F1值)
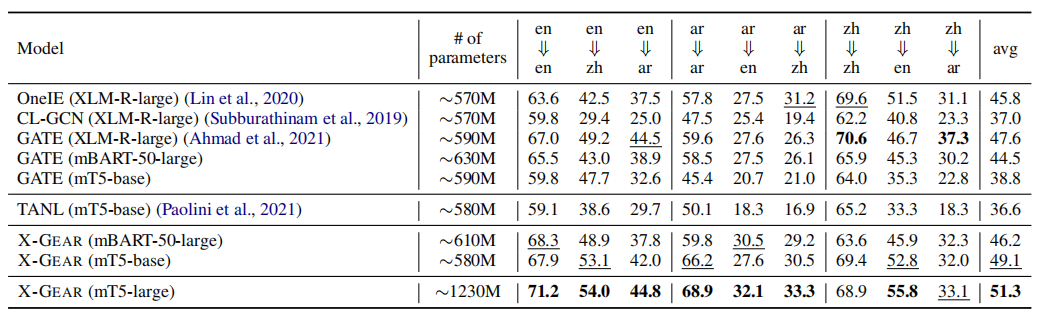
?ERE(F1值)

6 分析
6.1 消融实验
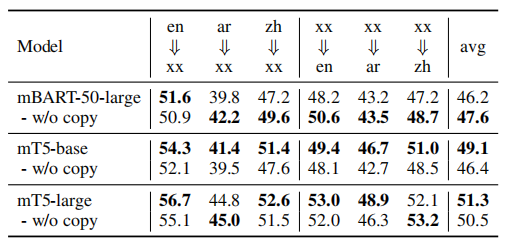
复制机制的影响。下表列出了具有和不使用复制机制的X-GEAR的性能。显示在使用mT5-large和mT5-base时添加复制机制,效果有所改进。但是,添加一个复制机制对mBART-50并不有效。我们推测,是因为mBART-50的预训练目标是去噪自编码,而且它已经学会了从输入中复制token。因此,添加复制机制就不那么有用。相比之下,mT5的预训练目标是只生成token被掩盖,导致缺乏复制输入的能力。因此,复制机制对mT5有益。
在ACE2005上的copy mechanism消融实验的F1值:
在提示符中包含事件类型。在第4节中,我们提到了为XGEAR设计的提示符只包含输入句子和与语言无关的模板。在本节中,我们将讨论在提示符中显式地包含事件类型信息是否有帮助。我们考虑了三种方式来包括事件类型的信息:
? English tokens.。 即使我们在非英语语言上进行训练或测试,我们也会将事件类型的英文版本放在提示中,例如,对事件类型 Attack 使用 Attack。
? Translated tokens。 对于每种事件类型,我们准备该事件类型令牌的翻译版本。 例如,攻击和攻击都代表攻击事件类型。 在训练或测试期间,我们根据输入段落的语言来决定使用的标记。 由于 ACE-2005 和 ERE 中的所有事件类型都是用英文编写的,因此我们使用了一个现成的机器翻译工具来执行翻译。
? Special tokens。 我们为每种事件类型创建一个特殊标记,并让模型从头开始学习特殊标记的表示。 例如,我们使用 <-attack-> 来表示攻击事件类型。
在ACE-2005的提示中包含事件类型信息的消融实验:
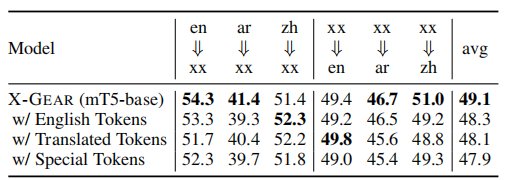
上表显示了结果。 在大多数情况下,在提示中包含事件类型信息会降低性能。 一个原因是一种语言中的一个词可以映射到另一种语言中的几个词。 例如,Life 事件类型与 Marry、Divorce、Born 和 Die 四种子事件类型相关。 在英语中,我们可以只用一个词 Life 来涵盖所有四种子事件类型。 但是,在中文里,说到结婚和离婚,Life应该翻译成“生活”; 说到Born and Die,Life应该翻译成“生命”。 在考虑提示中的事件类型时,这种不匹配可能会导致性能下降。 我们将如何在跨语言环境中有效使用事件类型信息留作未来的工作。
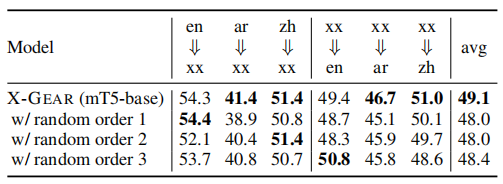
模板中角色顺序的影响。所设计的与语言无关的模板中的角色的顺序可能会影响性能。在设计模板时,我们有意地使角色的顺序接近于自然句子中的顺序。为了研究不同阶数的影响,我们用不同随机阶数的模板训练X-GEAR,结果如下表所示。随机顺序的X-GEAR仍然取得良好的性能,但比原始顺序的效果稍差。这表明X-GEAR对不同的模板不是非常敏感,而提供适当的角色顺序可以导致一个小的改进。
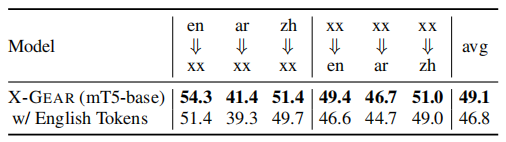
对模板中的角色使用英语标记,而不是特殊标记。在第 4 节中,我们提到我们使用与语言无关的模板来促进跨语言迁移。 进一步验证与语言无关的模板的有效性。 我们使用英语标记作为模板进行实验。 具体来说,我们将 format 设置为 Life:Die 事件的模板。
因此,对于非英语实例,目标输出字符串是一个代码转换序列。 表 6 列出了结果。 我们可以观察到,应用与语言无关的模板会带来 X-GEAR 2.3 F1 的平均分数提升。?
?6.2 误差分析
我们对X-GEAR(mT5-base)在从阿拉伯语到英语和从汉语转换到英语时进行了错误分析。对于每种情况,我们抽样了30个失败的示例,并在图3中展示了各种错误类型的分布。

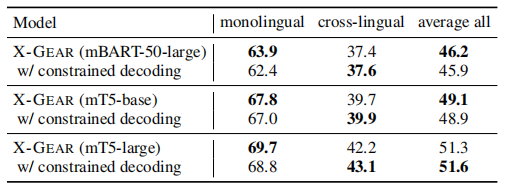
?6.3 约束解码
在所有的错误中,我们强调了两个具体的类别――“生成没有出现在文章中的单词”和“生成正确的中文预测”。这些错误可以通过应用约束解码(Cao et al.,2021)来强制所有生成的标记出现输入来解决。
下表给出了带有约束解码的X-GEAR的结果。我们观察到,适应这些限制确实有助于跨语言的可转移性,但它也损害了在某些单语情况下的表现。我们对这些预测进行了定性的检查。观察到,约束解码算法虽然保证了所有生成的令牌出现在输入中,但强制方法打破了学习到的整体序列分布。因此,在许多单语例子中,一旦其中一个标记被约束解码纠正,其后续生成的序列会发生很大变化,而使用beam解码的原始预测后缀序列实际上是正确的。这会导致性能下降。
而beam search是对贪心策略一个改进。思路也很简单,就是稍微放宽一些考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。