ЪЙгУHugging FaceЕФPytorchАцБОBERTФЃаЭНјааFine-tuneЪЕЯжЮФБОЗжРр
Hugging FaceШЗЪЕПЩвдШУBERTБфЕУКмШнвзЪЙгУ,етРяНщЩмвЛЯТШчКЮЪЙгУHugging FaceЕФPytorchАцБОBERTФЃаЭНјааFine-tuneЪЕЯжЮФБОЗжРрЁЃ
ЮФеТФПТМ
Tokenize
ЪзЯШ,ЮвУЧашвЊПДПДШчКЮЖджаЮФдЄСЯНјааTokenizeЕФВйзїЁЃЗЯЛАВЛЫЕ,етРяжБНгЩЯДњТыЁЃ
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
batch_sentences = [
"ЮвдкЙужн",
"НёЬьЬьЦјКмКУ",
"НёЬьЪЧ2022Фъ9дТ23Ше",
]
encoded_input = tokenizer(batch_sentences,
padding="max_length",
truncation=True,
max_length=20)
print(encoded_input)
етРяжБНгЪЙгУСЫ,transformersЯТУцЕФAutoTokenizer,ЪЙгУbert-base-chineseРДБрТы,ЪфГіЕФНсЙћШчЯТЁЃ
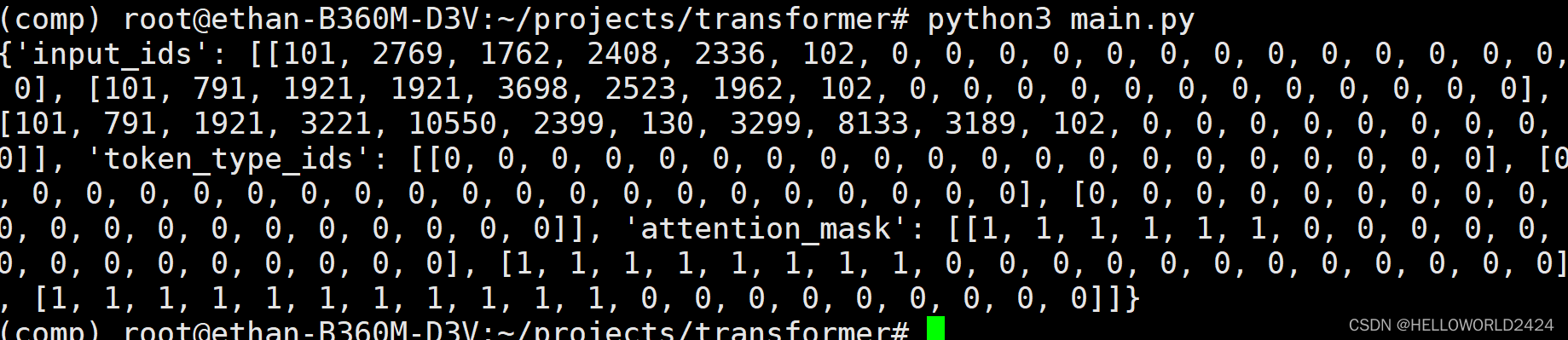
ПЩвдПДЕН,етРяЖЈвхСЫmax_seq_length=20,ВЛзуМгpadding,ГЌЙ§здЖЏНиЖЯ,ЭЗЮВМгШы101,102ДњБэНиЖЯЁЃ
Decode
decodeЪЧTokenizeЕФЗДВйзї,етРяЖдЕквЛОфБрТыНјааdecodeВйзїЁЃ
data = tokenizer.decode(encoded_input["input_ids"][0])
print(data)
ЕУГіРДдкЧАКѓЬэМгСЫПЊЪМКЭНсЪјЗћКХ,КЭPAD

ЙЙНЈВЂбЕСЗФЃаЭ
ЮвУЧетРяЪЧгУСЫTHUCNewsЪ§ОнМЏ,ДђПЊЭјвГЯТдиTHUCNews.zipЮФМўМДПЩ,РяУцвЛЙВга10ИіРрБ№,етРяжЛЪЙгУСЫ2Рр,ЮЊСЫМгПьбЕСЗЫйЖШ,ЗжБ№гУСЫЬхг§КЭгщРжЁЃЫљвдЖЈвхmodelЪБКђ,ашвЊжИУїЮФБОРрБ№Ъ§ЁЃ
AutoModelForSequenceClassification.from_pretrained(ЁАbert-base-chineseЁБ, num_labels=2)
ЙЙНЈКЭбЕСЗФЃаЭЕФДњТыШчЯТУцЫљЪО:
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
from transformers import AutoModelForSequenceClassification, AdamW, AutoTokenizer, get_scheduler
from dataset import MyDataset
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
train_dataset = MyDataset(file_path="./THUCNews", tokenizer=tokenizer)
train_dataloader = DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)
model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2)
optimizer = AdamW(model.parameters(), lr=5e-5)
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
name="linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for segment_ids, labels in train_dataloader:
outputs = model(segment_ids.to(device), labels=labels.to(device))
loss = outputs.loss
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
#БЃДцФЃаЭВЮЪ§
torch.save(model.state_dict(), "new_classify.pth")
#МгдиФЃаЭВЮЪ§
model.load_state_dict(torch.load("new_classify.pth"))
бЕСЗЙ§ГЬШчЯТЫљЪО,бЕСЗЭъГЩЛсБЃДцФЃаЭЁЃ
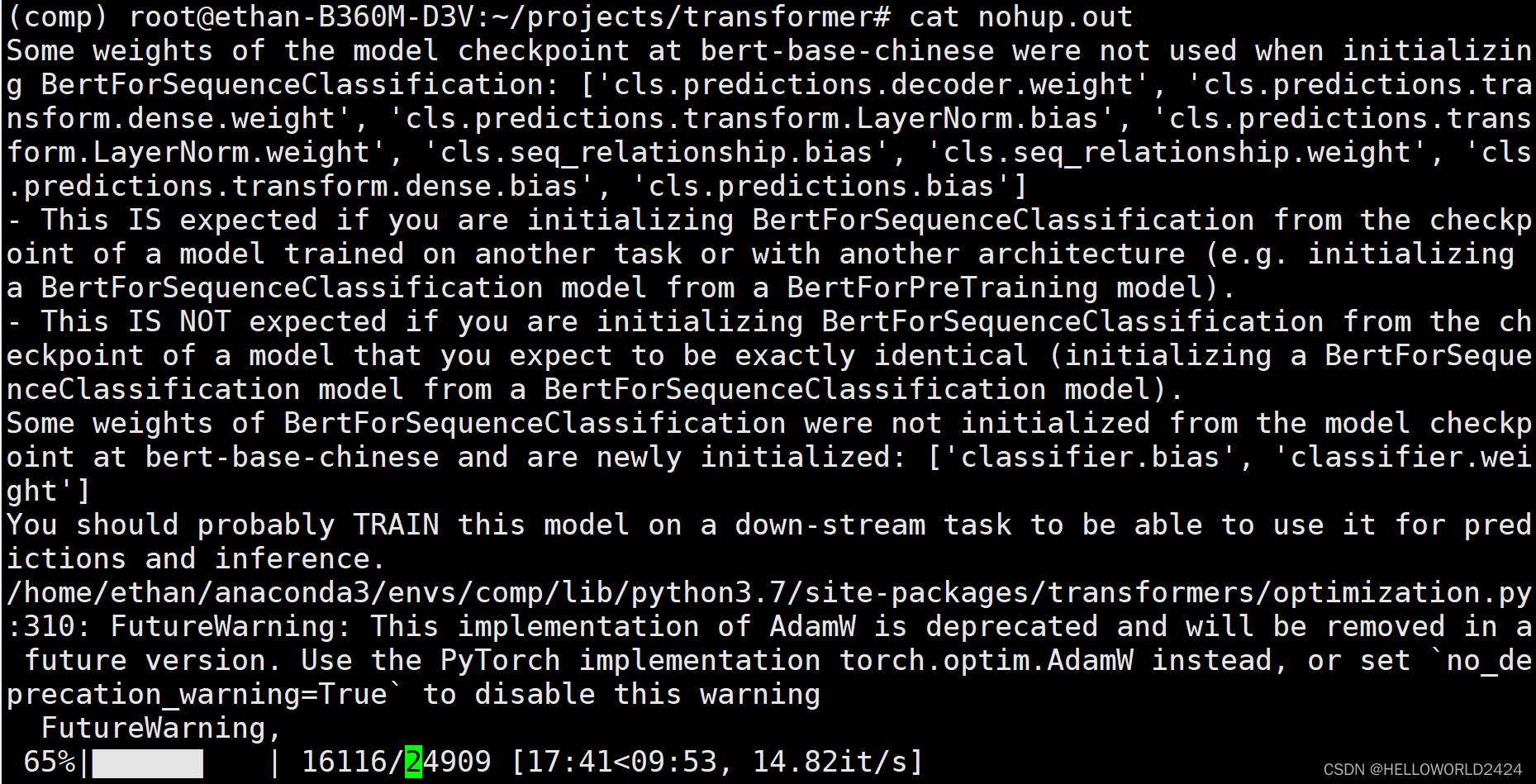
ФЃаЭЦРЙР
import torch
import evaluate
from torch.utils.data import DataLoader
from transformers import AutoModelForSequenceClassification, AutoTokenizer
from dataset import MyDataset
# диШыФЃаЭ
model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=2)
model.load_state_dict(torch.load("new_classify.pth"))
# зМБИВтЪдМЏ
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
eval_dataset = MyDataset(file_path="./THUCNews_test", tokenizer=tokenizer)
eval_dataloader = DataLoader(dataset=eval_dataset, batch_size=8, shuffle=True, drop_last=True)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
metric = evaluate.load("accuracy")
model.to(device)
model.eval()
for segment_ids, labels in eval_dataloader:
with torch.no_grad():
outputs = model(segment_ids.to(device), labels=labels.to(device))
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
metric.add_batch(predictions=predictions.cpu().numpy(), references=labels.cpu().numpy())
result = metric.compute()
print(result)
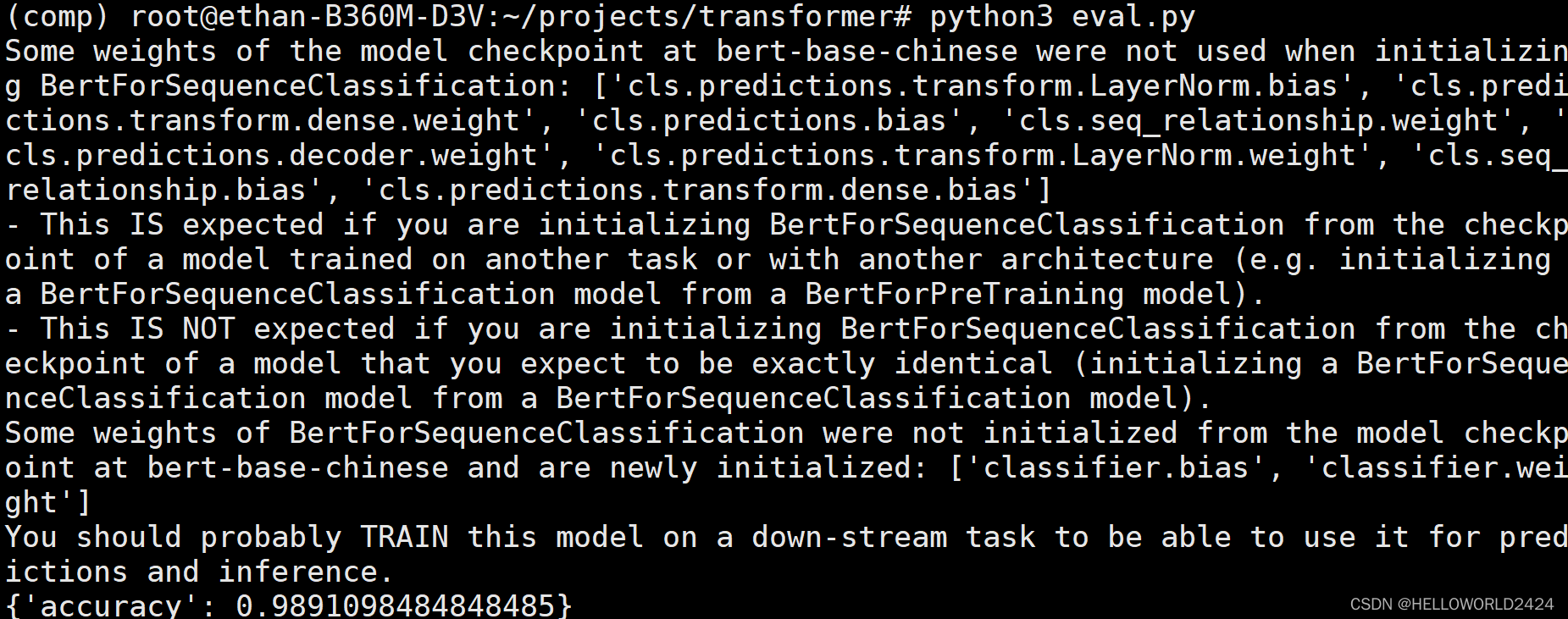
етРяЕФдЄВтзМШЗТЪЮЊ98.9%зѓгв,BERTФЃаЭЛЙЪЧYYDSЕФЁЃ