ConvFormer: Closing the Gap Between CNN and Vision Transformers
提出一个新颖的注意力机制:MCA,并且在此基础上提出一个神经网络:ConvFormer
Motivation
Generally, both CNN and ViT have their pros and cons.
CNN 和 ViT 各有优缺点
To this end, there is a trend to take the merits of both CNNs and ViTs by migrating desired properties of ViTs to CNNs, including the general architecture design, long-range dependency, and data specificity provided by the attention mechanism.
为此,有一个同时考虑CNN 和 ViT 的所需要特征的趋势,包括架构设计,长距离以来,数据特异性(?)
因此作者他们提出MCA,MCA combines small and large kernel sizes for difffferent resolution patterns, which is proved to improve accuracy and effiffifficiency in (Tan and Le, 2019b).
Method
- MCA的框架
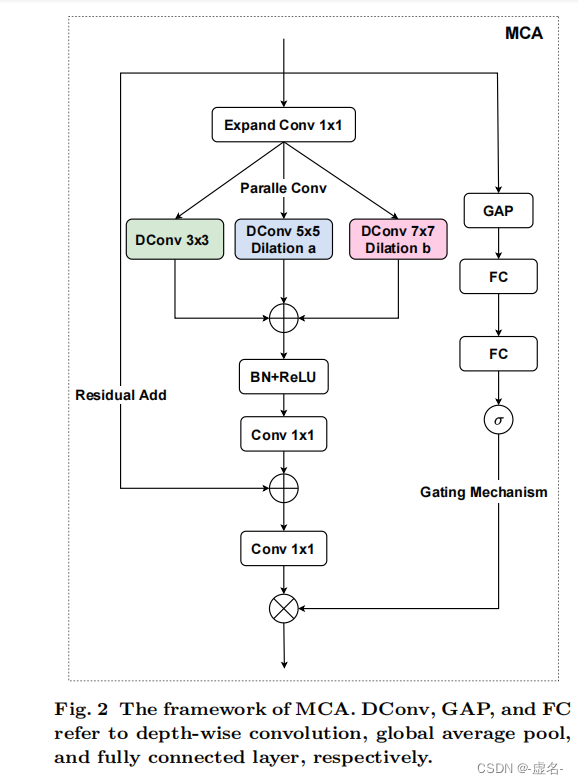
Expand Conv: 将输入的通道增加
DConv: depth-wise convolution
中间的1*1 conv:为了残差相加,将通道减少到与原输入一样