Chat
������Ī��ʲ ���������,(�Ѿ��ڽ������ڴ�Ī��ʲǰ����ʿ��),ARGA����,��������ͼ�Ա�ѧϰ������ͦ��,���ǿ�Դ���½���
����rank:
��������������,motivationҲ����Ȼ,������Ϊ���Դ�2019DGI����֮��,��DGI�����濼�Dz��ĵĹ���,��ʾ��DGI�ɹ���ԭ�����Dz��ò�ͬ��ǿ�ķ���,���߽��cv����Ա�ѧϰ�ķ��������ġ�
����: O1���Ӷ�,1epoch�Ϳ���ѵ��,ȡ���б���Dѵ����ʧ��߿���չ,��������֤��s(ͼ������)�����½�
���²���: OGB-arxiv����full-batch,products,papers100M ��Ȼ������graphsage���в���,ֻ��һ���̶�����ǿ�˿���չ��,�����aaai22 ��ƪsugrl���ⷽ�滹�Dz���
֪ʶä��
���ڸ��Ӷȵ�֪ʶ,�������ἰ: InfoNce��ʧ O(ND) JSD ��ʧ�� O(D) BGRL(BYOL��graph�ϵ���չ)��GBT(barlow twins��graph�ϵ���չ) ȡ���� ������,���������Լ��� ��Ȼ���ø��Ӷȱ�� O(D)
���ķ��� GGD (graph group discrimination)
1. ������
���Ĵ� ��ǡ���ļ���� sigmoid����,̽��DGI�� DGIͨ����ڵ��ͼ������s֮��Ļ���Ϣ,�Ӷ���Ϊ�Ա�ѧϰ��graph�ϵ�paradigm��

DGI���ڵ�����:DGI����������������������������Ϣ,DGI���s�ķ����� ��ƽ��,�������sigmoid�������DGI��GNN(GCN)Ȩ�س�ʼ������ Xavier��ʼ��,������ʹ�� s ���ͼ������ ����ӽ�����ͬ����ֵ ��I,����һ������,I��һ��ȫ1����
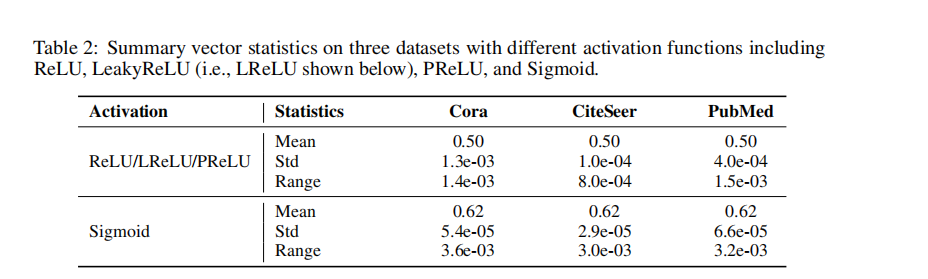
���������ʵ��ó���,�����������1����һ����֤:

ͨ���Ħ�,���ߴ�0��Ϊ1,��������ʵ��,��Щʵ��,�������s��ʵ��û�ж������ trivial����ôDGI�ļ���:ͨ���Ա�h��s�ƺ������������ɹ���ԭ��
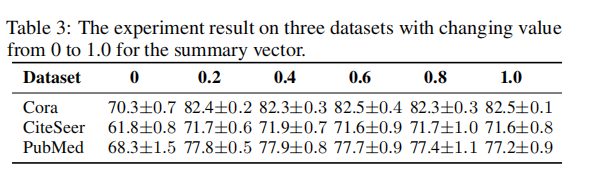
�ص���:
���������� ���s��С����,�������ճ���������epsilonI,������߲���I(ȫ1,epsilon=1)��ֱ�Ӵ������s���������ĺô�: ����Ҫ��������!!! ������D��һ������bilinear�Ĵ��,��Ҫ����ÿ���ڵ��s���д��,�����������֮��ij˷� ͨ������ǰ��ͷ��� ���ĺܶ�,

��� DGI����ʧ��Ϊ:

����,sum(zi)����Ϊzi (1D) ��s���,��s=1(D1),���,����ĺ������ zi��Ԫ��֮�͡� ���߶�������ۺ�Ҳ�����˱��,����mean max linear��ѧϰ���zi��s�Ľ�Ϸ�ʽ linear��˵���1D��� 11

sum��linear�ȽϺ�
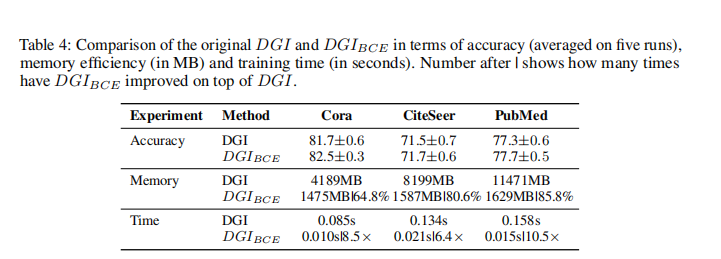
��DGI�ĶԱ�,������С�ڴ�,Pubmed��Ȼ����Ҫ 1629MB!!! ʱ����Ҳ����
���������sum��ʽ1,���������� BCE��DGI
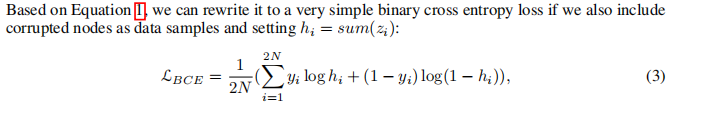
��һ�ֶ�Ԫ�����ص���ʽ,���ڵ�����ԭ����ͼ,yi=1,�ڵ����ڱ� �ƻ���ͼ,yi=0, ��������ʽ ���� ������ͼ�����нڵ���� �Ա�,�ж�h��ԭͼ���DZ��ƻ���ͼ,�ڵ�ڵ�֮��ĶԱ�:��Ϊ group discrimination
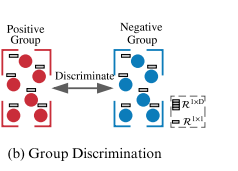
MVGRL��ʵ��,��һ��˵�� group discrimination
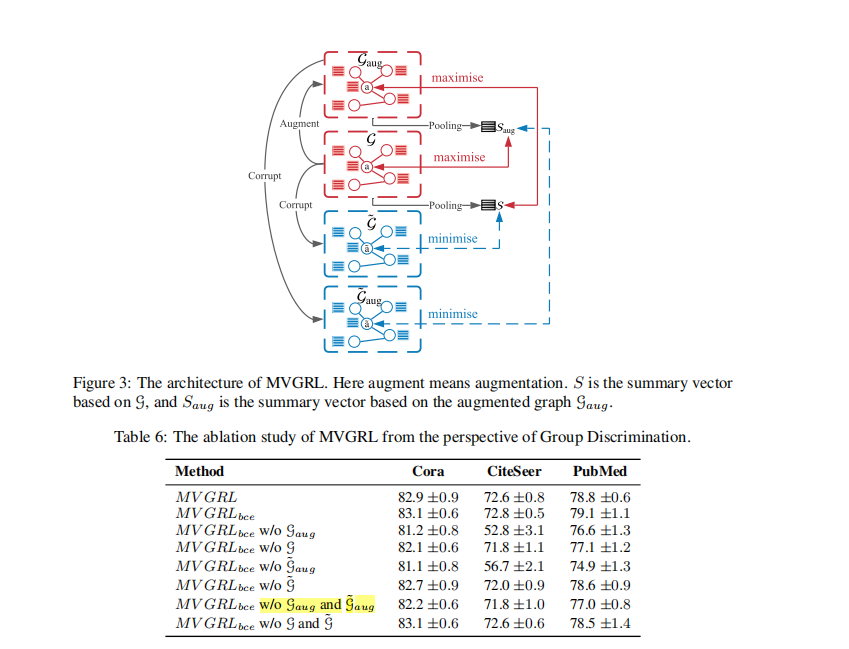
MVGRLͨ��diffusion ��augmented graph,�Ӷ������ͼ֮����жԱ�,�����������ǵ���ʧ,�γ�bce MVGRL,Ҳ��ok��, ,,, ��Ϊ ���� DGI�ı��,Ҳ�Dz�����h��s֮ǰ�����Ϣ
���ĵ�model
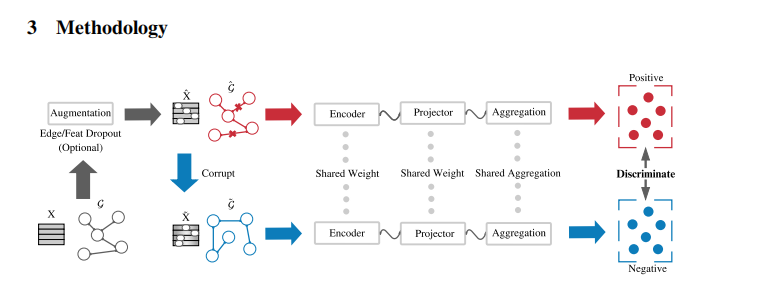
1. ͨ���ߺͽڵ�drop����ǿ
ע�� ���ﲻ������ö����ǿ����ͼ���жԱ�,���� ÿһ�� ��ͬ����ǿ��ͼ ������³����
2. Corrupt
�� DGIһ��,����shuffle X
3.Siamese GNN = GNN encoder+projector
���IJ���GCN��Ϊencoder, projector���Զ���Ķ��linear layers�� ������GNN����� ԭͼ�� corrupt֮��ͼ�Ľڵ������ �ڽ��е��IJ�֮ǰ,����������Ҫ������ͬ�� �ۺϷ�ʽ(sum mean max linear) hi=sum(zi)
4.group discrimination
BCE��ʧ,yi=1,ԭͼ�� yi�������� ����hi��yi����bce��ʧ
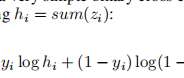
tricks

GNNencoder �����H,ͨ������ ���ڽӾ������ �����ǿ��H,��ԭ����H����֮��,�Ӷ�������������
discussion
NCE��JSD��ʧ
nce�ķ��� ���ڽڵ�i��Ҫzi��ci���1��,��ĸ��Ҫzi��������� ����һ��N��,��������zi 1d�� ci 1d��� ��Ҫ�ķ� O(D)�Ρ���� InfoNCE������ O(ND) ��
JSD����ÿ���ڵ㲻��Ҫ N�����������жԱ�,���� �б���������Ҫ zi��ci��� O(D)��

BRGL��GBT
BRGL ͨ�� ���zi��hi����������(����),ֻ�ù�ע����(�Լ����Լ���Ӧ����)
GBT ���������,GBT����ʧ��������һ�� Э������� iiԽ��Խ��,ijԽСԽ�á�
����������ʧ���ǰ��� �� ����������ˡ���JSDһ����O(D)��
������ h��һ���������,���൱���� �� �˷���� ���ӷ���

�����dz˷�����,������ͨ���ӷ�,�Ƿ��������� ������,�ܹ���������?--------- ������ ����margin loss�ĶԱ���ʧ aaai22 �ͽ����� Ҫд��һƪ����subCon�Cicdm
ʵ��
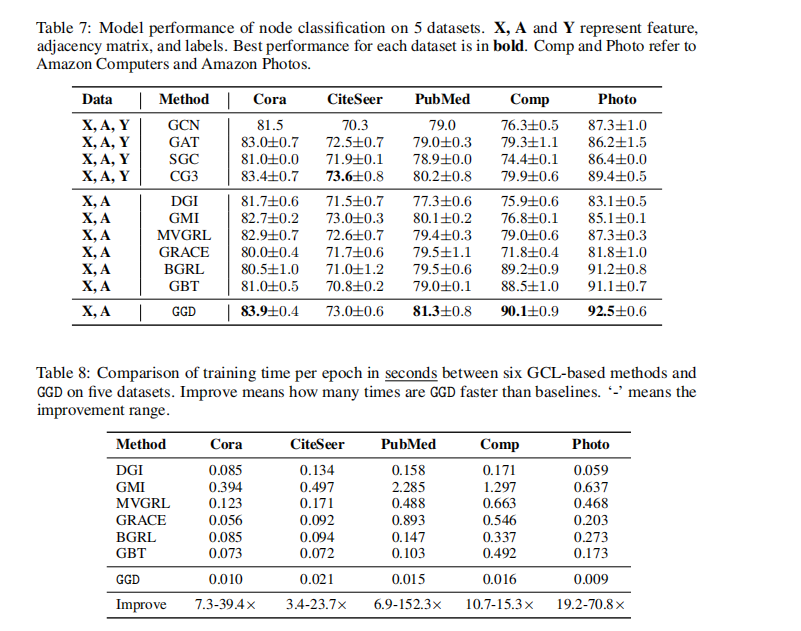
full-batch��,�ر� ��Լ�ڴ�
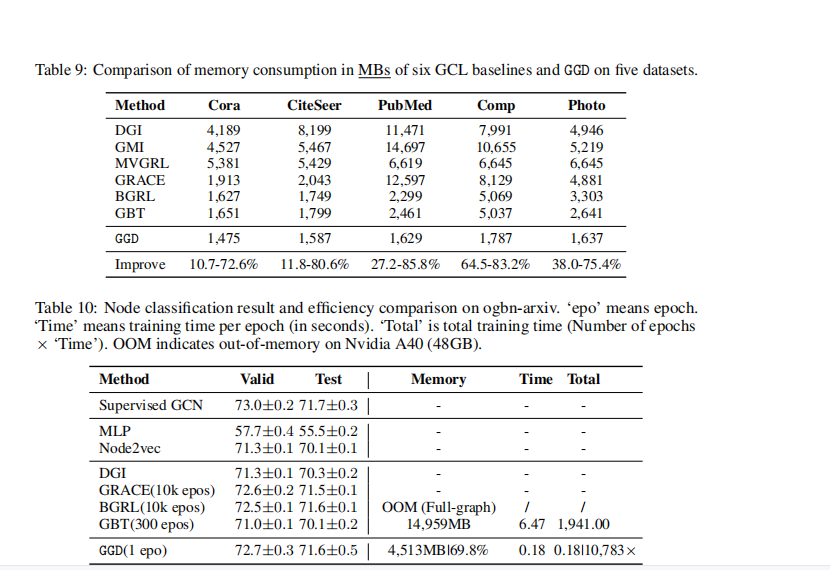
���ڲ���:graphsage
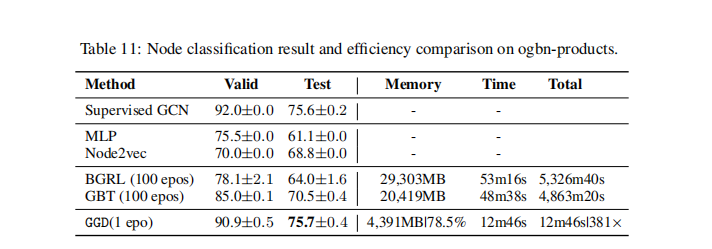
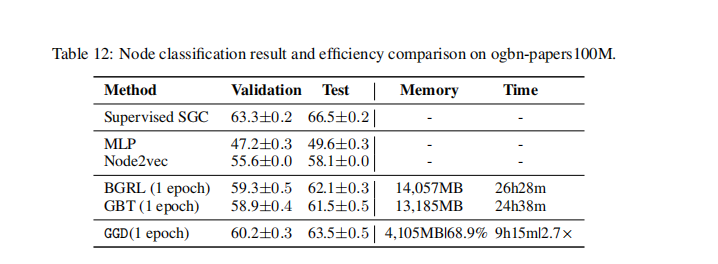
�����ij���������

����D,��������нڵ��֮����������ж�,��ǰ��,�Ա�ѧϰ�����ж���ѧϰ��Ӱ��,����жϱ���֮������������� (�ڻ��C����,����bilinear�Cdgi,����margin��������,����ƴ�ӨCcontact linear���)
Proof of Theorem1



