本文介绍清华大学语音与音频技术实验室(SATLab)Interspeech 2022录用论文The THUEE System Description for the IARPA OpenASR21 Challenge. 在去年的IARPA OpenASR21低资源语音识别挑战赛中,来自SATLab实验室参赛队伍THUEE在两个赛道的13个项目中取得了第一名的优秀成绩。THUEE队伍在受限赛道中使用了基于Kaldi的CNN-TDNN-F和CNN-TDNN-F-A系统,在半受限赛道中则使用了wav2vec 2.0 XLSR-53预训练模型。
01?OpenASR21挑战赛
OpenASR21低资源语音识别挑战赛是美国情报高级研究计划局IARPA的MATERIAL研究计划的一部分,致力于实现任意低资源语种的语音识别。
比赛中涉及了波斯语、格鲁吉亚语、爪哇语等15种低资源语言,每种语言提供了10小时的有标注训练语音,语音内容为日常电话对话。数据设置上又分为受限赛道、半受限赛道(又称为受限PLUS赛道)和非受限赛道,其中受限赛道只允许使用主办方提供的10小时数据,半受限赛道可以额外使用一部分无标注数据和公开的无监督预训练模型,而非受限赛道则不对训练数据做限制。
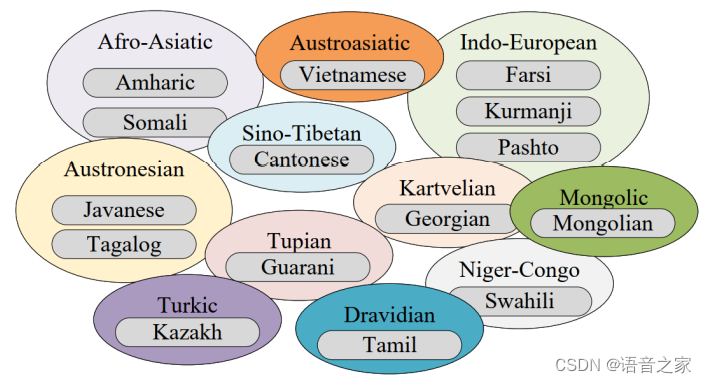
?比赛涉及到的15种语言
THUEE队伍参加了受限赛道和半受限赛道,并在两个赛道中取得了13项冠军。
02?受限赛道
系统中采用了CNN-TDNN-F和CNN-TDNN-F-A两种模型结构。CNN部分包括6层conv-relu block,而TDNN部分则包括11层TDNN-F block。Attention层使用了0.5的key-value rate。GMM-HMM模型的训练使用了13维的PLP特征, 而CNN-TDNN模型则使用了MFCC+ivector特征,一些语言里还额外加入了3维的pitch特征。
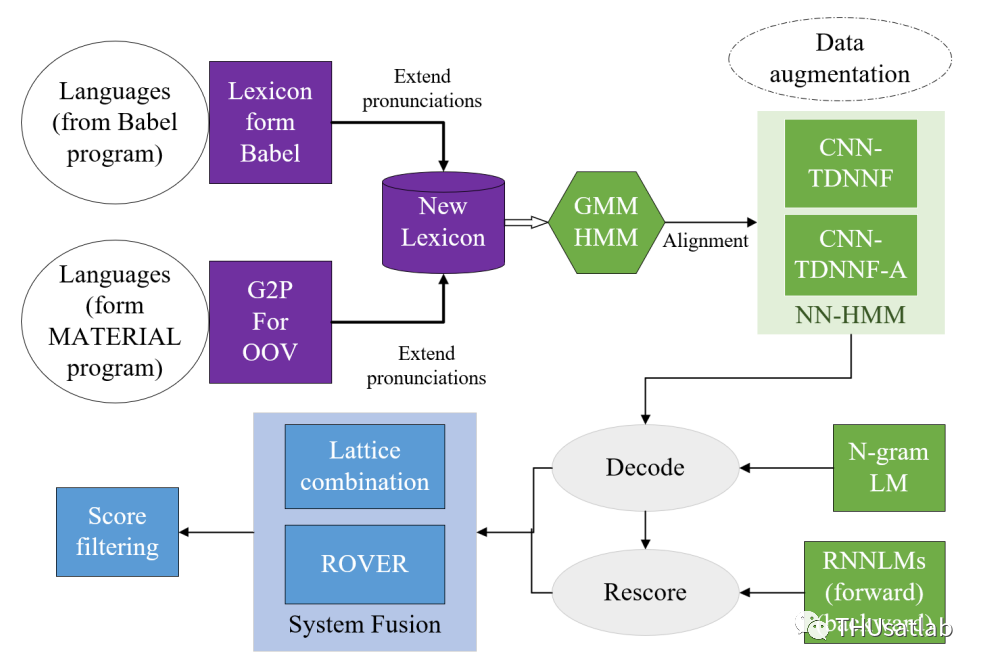
受限赛道的系统概况
除了使用主办方提供的BABLE词典外,我们还使用LanguageNet提供的多语种G2P模型对训练集和开发集中的集外词做了G2P操作,以进一步扩充词典。另外,我们还进行了速度扰动、音量扰动、频谱增强和加噪等数据增强操作。
由于测试数据并未进行逐句切分,所以需要事先对数据进行VAD。我们使用了基于RNN、CRNN和OSFs的三个不同的VAD系统对音频进行切分,并将三个系统的结果进行了融合。解码完成后,我们对结果进行了LSTM/反向LSTM重打分。最后,我们将各个系统识别得到的lattice进行融合,根据最小贝叶斯风险准则获得最终的lattice和解码结果。
03?半受限赛道
在半受限赛道中,我们使用了开源的XLSR-53多语种预训练模型作为基础,首先利用提供的无标注数据对XLSR-53模型进行无监督微调,之后再利用有标注数据做有监督微调。
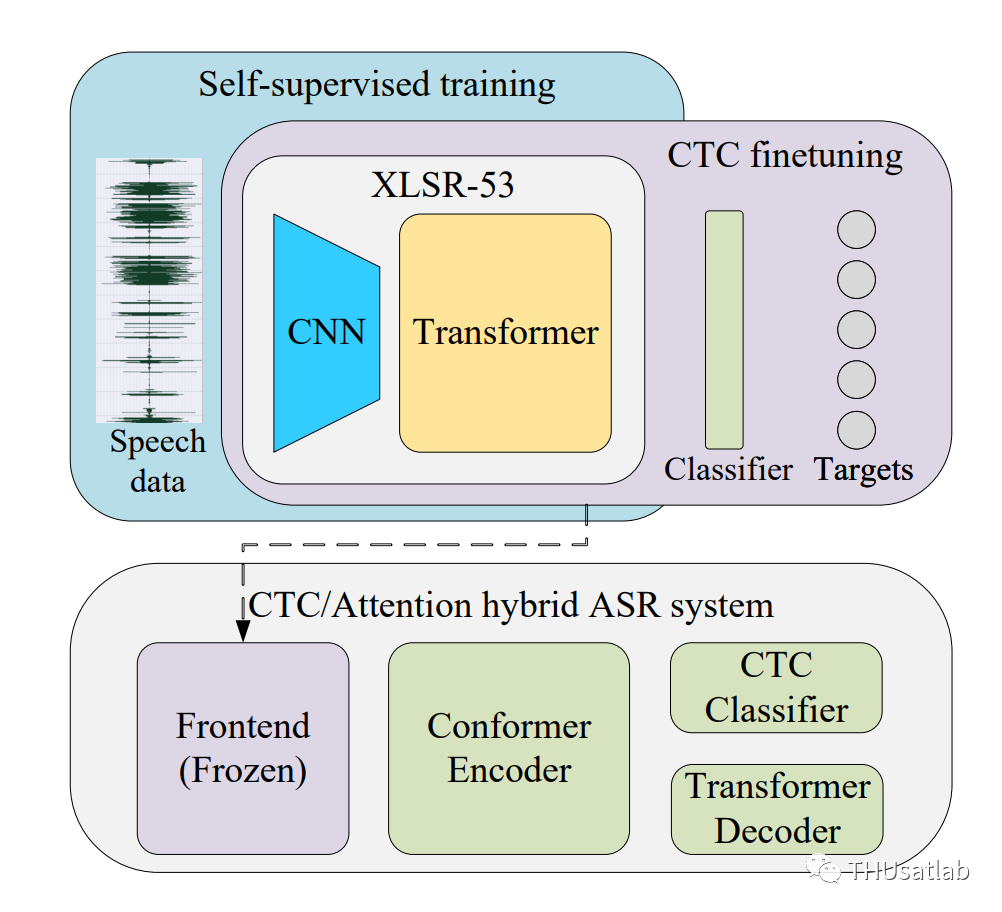
半受限赛道的系统概况
一部分OpenASR21语种有罗马化标注,这些语种使用罗马字符作为建模单元;另一些语种没有罗马化标注。这时我们使用字素作为建模单元。微调学习率为10E-3,共微调100K步。微调模型和受限赛道对应语种的模型使用ROVER工具进行融合。
THUEE队伍在OpenASR21赛事中取得了优异的成绩,其中限制赛道的关键在于多种系统的融合;而半限制赛道的关键提升来自于无监督+有监督的两步微调策略。