论文链接:https://arxiv.org/abs/2108.02982 ICCV 2021
Abstract
对比学习在无监督特征学习中得到了广泛的应用,其中正负样本对的设计是其关键之一。
改论文尝试设计一种不同于数据增强的特征级数据操作来增强自监督对比学习。
首先设计了一个正负样本对的相似度值分布可视化方案,这便于分析和理解学习过程,利用这个工具可以得到一些结果,根据这些结果启发了特征转换这个方法,包括Positive Extrapolation/Negative Interpolation
实验结果表明,论文提出的特征变换在ImageNet-100上比MoCo基线至少提高6.0%的精度,在ImageNet-1K上比MoCo V2基线至少提高2.0%的精度。
Introduction
对比学习的关键问题之一是设计正负样本对来学习嵌入空间,使正样本在空间中更靠近,而负样本被推开。
现有大多数方法都是通过数据增强来获取正负样本对,即利用同一图像的不同增强图来形成正样本对。例如CMC使用图像的亮度和色度颜色通道作为两个增强视图。InfoMin演示了增量的数据增强确实会减少视图之间的相互信息,从而提高传输性能。
经过一系列的改进,基于数据增强的对比学习方法在ImageNet上实现了接近完全监督的性能。但是以往的数据增强(如裁剪、颜色失真)大多直接来源于人类的直觉,缺乏太多的可解释性,无法保证其有效性。
论文认为特征级数据操作(例如特征转换)可以提供更多可解释的或有效的正负样本对来增强特征嵌入。
为此,论文首先设计了一个方案来可视化正负样本对在训练过程中的相似度值分布。从这些得分布可以解释模型参数值如何影响其性能。此外,它使我们能够观察到正负样本对的特征,从而发明更有效的特征转换(FT)
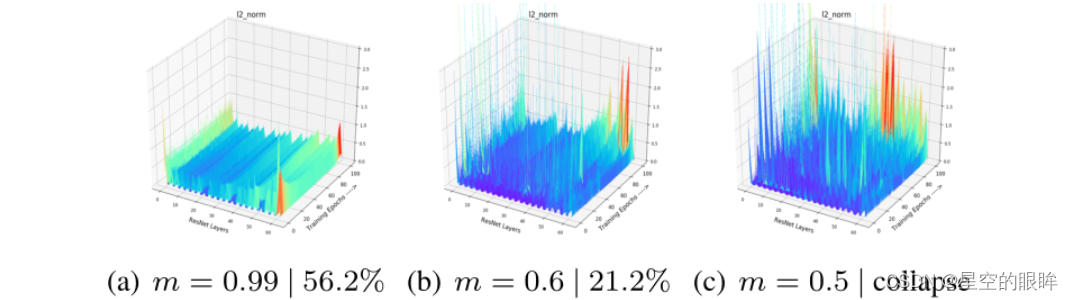
下图演示了得分可视化。通过绘制MoCo在不同动量值下的得分分布,我们可以清楚地观察到m = 0.99的情况下,正样本对相似度值更小,但取得了更好的性能。
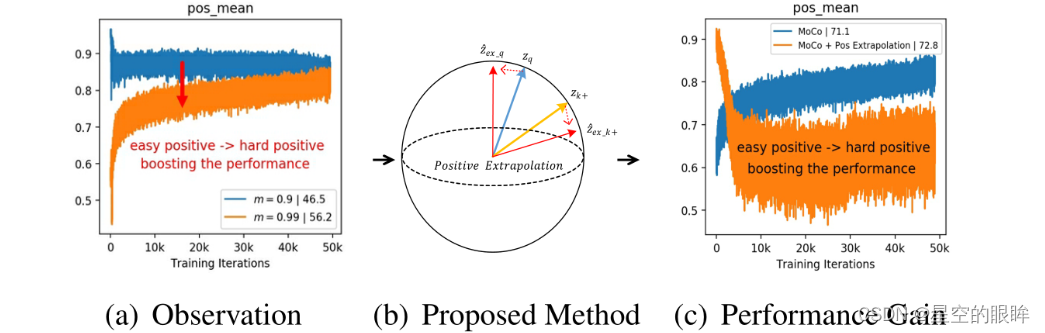
- (a)画出MoCo中的动量为0.99以及0.9时正样本对相似度值分布,表明得分越小的正样本对一般需要更长的时间收敛,但可以获得更好的精度。
- (b)受(a)的启发,对正样本对进行外推,以轻微降低得分,但生成了hard positives。
- ?利用正样本外推,将性能从71.1%(蓝色)提高到72.8%(橙色)。性能的提高与分布的变化是一致的。
- 从上图可以看出,正样本外推算法可以将模型的性能从“蓝色”提升到“橙色”。
正样本对的相似度值越小表示其相似性越小,这意味着该正样本对有较大的视图变化。实际上这与特征学习的目标是一致的,特征学习的目标是一种更具有视图不变性的视觉表示。因此我们推测hard positives可以传递大的视图变化性。受此启发,引入正样本对的外推运算(extrapolation),以增加视图变化性,从而获得hard positives。
此外,为了充分利用负样本特征,提出了负样本之间的随机插值,直观地为每一个训练步骤提供多样化的负样本,使模型具有更强的识别力。
与传统的数据增强不同,特征转换(FT)无需额外的训练样本,相反,它通过操纵正负样本对来重塑特征分布。特征转换将创建hard positives来学习更强的视图不变性,创建diversified negatives来学习更强的辨别性。
特征转换是根据学习到的表示,通过模型性能进行驱动,而数据增强对性能是盲目的。并且特征变化可以为各种下游任务实现性能改进。
可视化工具和特征转换可应用于各种自监督对比学习,包括MoCo,SimCLR,InfoMin,SwAv,SimSiam。后续将使用经典模型MoCo来演示框架。
Related Work
1.Contrastive Learning
对比损失在自监督学习中得到了广泛的应用。例如InfoMin使用NCE的下界来证明增量数据增强会减少视图之间的相互信息,从而提高传输性能。换句话说,对比学习中使用相对困难的数据增强可以提高迁移性能。
2.MixUp for contrastive learning
Mixup及其众多变体在与交叉熵损失配对时,为监督学习和半监督学习提供了高效的数据增强策略。
- Manifold mixup是用于监督学习的特征级正则化
- Un-mix提出在图像/像素空间使用mixup进行自监督学习
- MoChi提出将负样本混合在嵌入空间中进行hard negatives增强,但降低了分类精度
- i-Mix提出了在输入和伪标签空间中混合实例的策略,以便正则化对比训练。
论文提出用特征变换代替数据增强。正样本特征进行外推以增加hardness of positives,对memory bank中的负样本特征进行随机插值以增加多样性。相比数据增强,特征变换方法更加有效。
Visualization of Contrastive Learning
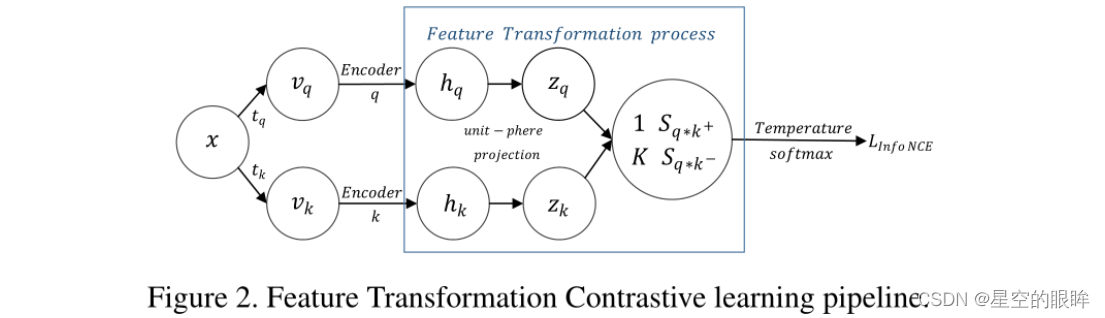
1.Preliminaries
从对比学习的基本步骤开始:每个数据样本x经过两个独立的数据增强管道tq和tk,获得两个视图vq和vk,构建正样本对,编码器q和k分别将两个视图映射到特征嵌入空间中得到 hq和hk,再对特征向量 hq和hk进行L2归一化处理,即将hq和hk投影到单位球上,得到zq和zk
根据这些样本对进行对比学习,得到对比损失函数:
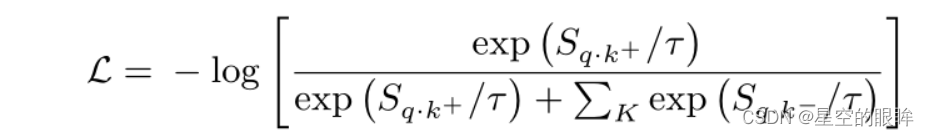
在这里,我们粗略地将Feature Transformation过程定义为对编码器嵌入hq和hk的某些操作,以重塑输出正负样本对的评分分布,以便在后续的InfoNCE损失中更好地进行对比学习。
2.Score Distribution Visualization
选择将正负样本对的相似度值可视化,而不是可视化损失曲线和转移精度,这是因为内部训练可以挖掘模型的学习能力。具体来说,有两个实际原因:
- InfoNCE损失的基本思想是用log-softmax的方式比较正负样本对相似度值,将其可视化能够帮助我们研究对比学习过程。
- 归一化后的特征向量zq和zk是高维向量,存储和可视化难度较大。
注意:该可视化工具是离线的,它不会影响训练速度,计算量可以忽略不计。
3.Visualization Examples with MoCo
选择计算效率高的模型MoCo为例来演示可视化设计。具体MoCo原理与细节略。
在ImageNet-100上尝试MoCo的各种m进行评估。如表所示,随着m的减小(增加编码器fk的更新速度),精度呈反u型,位于m = 0.99处获得最大准确度56.24%,当m≤0.5时,模型崩溃。

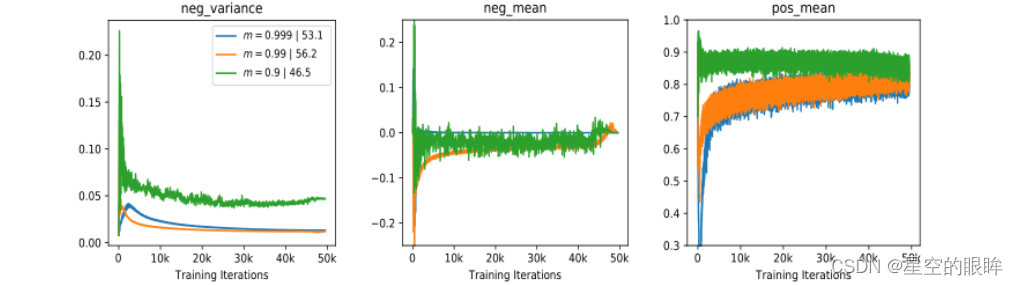
选择三个非平凡统计量来可视化分数分布:
-
the mean of positive scores(表示正样本对的距离的近似平均值)
-
the mean of negative scores(表示负样本对的距离的近似平均值)
-
the variance of negative scores(表示memory bank中负样本的波动程度)
如下图所示,当m越小,编码器k的更新速度越快,导致训练步骤之间的特征差异逐渐增大,表现为队列中负样本相似度值的变化越来越大。
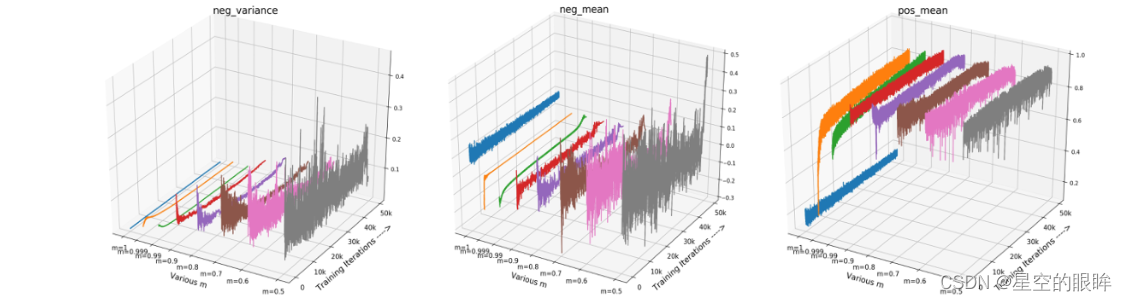
模型崩溃的内部分析:模型崩溃的原因是多方面的。小m(fk更新速度快)带来的不仅是不一致性,还有负样本相似度值的混乱。负样本相似度值的平均值反映了memory bank中所有负样本对的近似得分。如果随着训练过程剧烈波动,相应的损失值和梯度会剧烈波动,导致收敛效果不佳。
Hard Positive提高性能:m越小,更新速度越快,编码器fk与fq越相似,即在极端情况下,当m = 0时,各训练步骤的参数θk与θq完全相同。然而编码器fq和fk相似度的增加会导致zq和zk+的不相似度减少,只保留数据增强带来的视图差异,导致较高的正样本对相似度值。
在下图中将m从0.9(绿色)增加到0.99(橙色)时,简单的正样本对变成了困难的正样本对(从非常相似的0.9到不太相似的0.7),获得了更高的传输精度(从46.5%到56.2%),这个观察结果可以用InfoMin原理来解释:提高zq和zk+之间的视图变化性对应于增加对比学习的互信息,这迫使编码器学习更鲁棒的嵌入,从而提高传输精度。
Proposed Feature Transformation Method
InfoNCE的学习目标是将嵌入空间中的正样对(zq和zk+)拉得更近,同时推开负样本对(zq和存放在memory bank中的所有zk?),因此可以直接对正负样本特征进行特征变换,以提供适当的正则化]或增加学习难度。
具体而言,采用正样本外推法对原始的正样本对进行变换,进一步增加硬度,采用负样本随机插值法对memory bank进行插值,以增加负样本的多样性,如下图所示。值得注意的是,这些方法没有改变损失项,因为它只是用特征转换后的pos/neg计算的相似度值来替换原始的样本对计算的相似度值,并没有改变公式结构。
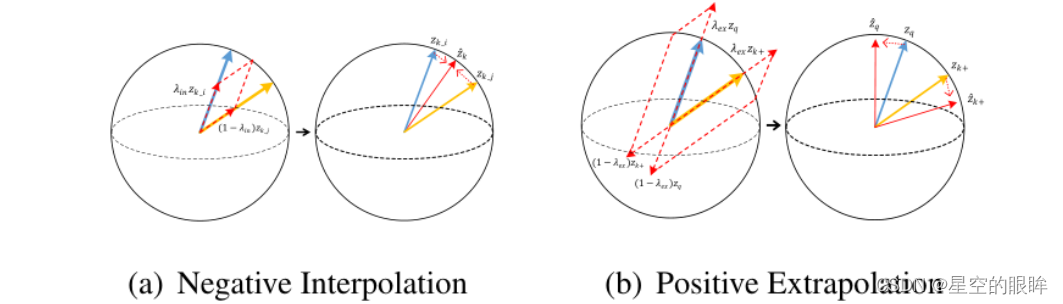
对于正样本外推法,指通过外推将两个正样本特征相互推开,将 easy positive转化 hard positive,这有利于对比学习。 对于负样本插值,指对memory bank中的两个负样本特征进行随机插值,生成一个新的插值负样本,目的是为了充分利用大量负样本。
注:两种FT方法都探索一种有效的方法来执行特征转换,而不是简单地将hard negatives扩展到memory bank中
Positive Extrapolation
已知将easy positive转化hard positive,即使得训练更加困难,这可以提升性能。所以探索一种方法,即在训练过程中,操纵正样本特征zq和zk+来增加它们之间的视图变化性。
首先,我们简单地对两个正特征进行加权相加,生成新的特征:
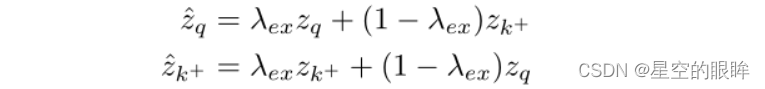
同时考虑mixup的设计原则,保证权值之和为1,并且保证zq^ zk+^ <= zq zk+
转换后的正样本对计算相似度公式如下:
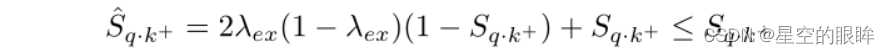
因为Sqk+∈[-1,1],所以(1-Sqk+) >= 0,为了使得Sqk+^ <= Sqk+,我们需要设置λex >= 1以及2λex(1-λex) <= 0
最终转换特征后的正样本对计算相似度值范围:
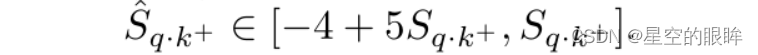
能否使用插值法产生hard postitive?实验证明不可以,原因是正样本特征之间的插值将正对拉到一起,从而降低了训练过程中的硬度。

Negative Interpolation
以往的对比模型没有充分利用负样本。例如在MoCo中,有许多重复的负样本特征存储在迭代的memorybank中。因此可以设计一种新的策略来充分利用负特征,增加队列中负样本的多样性。在具有足够随机性的条件下,我们在memory bank中提出负插值法,直观地为每个训练步骤提供多样化的负样本。
具体来说,将MoCo的存放负样本的memory bank表示为Zneg = {z1, z2…,zK},其中K为队列大小,同时设定Zperm为Zneg的随机排列。然后在这两个队列之间使用一个简单的插值来创建一个新的队列:
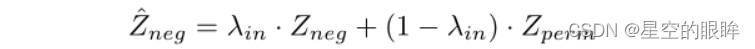
转换后的队列Zneg^为对比损失提供了新的插值负样本,其中随机排列和λin保证了每一个训练步骤的多样性。假设原队列Zneg提供了负样本的离散分布,使用负插值法可以通过随机插补填充分布的不完全样本点,从而得到一个更具识别力的模型。
Discussions: When to add feature transformation?
通过分析在不同训练阶段开始FT的效果,如下表所示:

注:论文中还要关于其它方面的讨论,如Dimension-level mixing等等
Experiments
注意:baseline指的是模型使用数据增强,而不是特征转换(FT)
在IN-100上使用Res-50对模型进行200 epoch的预训练:
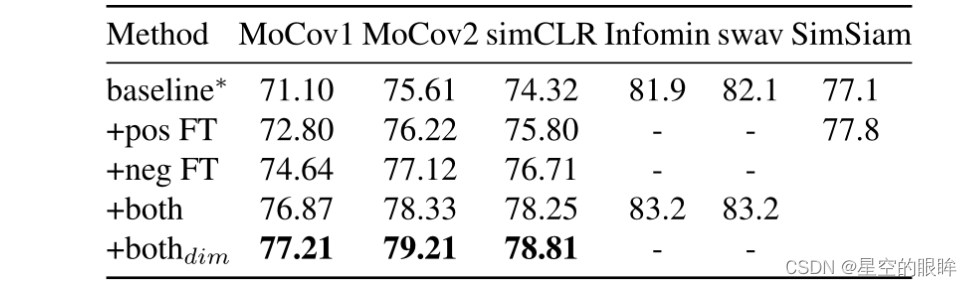
其它实验内容以及消融实验详情见原论文。