ǰ��
ż�������ʼ�,����������ǰд�Ĵ���opencvʵ�ַ�ƱͼƬ�еı�����ıʼǡ���Ȼ�����Ѿ������ѧϰ���������,���ǻ�ͷ������ȥ��̽��,�о������е���˼��,��Ҫ���������Լ������ʼDZ���,ͬʱ������̤��ͼ��ij�ѧ����ѽ~
0 ���
ocr��ʶ�����ʵ����ͨ��ʶ����֮��,����Ҫʵ�ַ�Ʊ�����ڱ��ȵ�ʶ��,������Ҫʵ�ַ�Ʊ���б�����ļ���ʶ��,����Ҫ����Ĵ�������Ϊ��ͳ�����ֿ����yolo�Ὣһ������һ��ʶ�𡣶���Ʊ�����������,��ʹ��ͬһ����,Ҳ��Ϊ���ߵĻ���,���Բ�������Ϊ��һ����һ��ġ�

������������,�ҵ�˼·�������Ƚ�ͼƬ���ձ����ֳ���ͼ,Ȼ��ÿ����ͼ�������������ʶ���ܵ���ʶ��,������еĽ������֮�ظ��û�������ǰǰ���Ĵ�������,���¿��Է�Ϊ���¼���:
- �ж�ͼƬ�Ƿ���Ҫ��Ƕ���ת(90,180,270)
- �ж��Ƿ���ҪС�Ƕȵ���ת,��֤���ߵ�ˮƽ
- ʹ��opencv�Ա����С���ο������ȡ
- �Ա��������������л���(����ͼ��ʾ)
- �����е���ͼ����ocrģ�ͽ��м��
- ƴ�ӽ��
������Ҫ����һ���ڽ���2,3,4ͼ����������ʹ�õĺ��������Լ�������չ�Ķ������г����Ұ����dz��������
- Ҫ�����:Python+OpenCVУ������ȡ�����еĸ�����
- OpenCV��python ͼ�����(���ڸ���Ҷ�任�������ӱ任)
- python ͼƬ�еı���ʶ��
- OpenCV��Python ������ȡ
- OpenCV��python ��̬ѧ����(��ʴ�����͡��������㡢��Ե���)
1 �ж��Ƿ���ҪС�Ƕȵ���ת
��Ʊ���кܶ�ĺ���,ʹ��Canny������ȡ����+��������ȡֱ��(���������һ�����ȭ),Ȼ����Ը�����Щ���ߵ�б�ʵľ�ֵ��ȷ��ͼ���Ƿ�����б,�Լ���б֮����Ҫ��ת�ĽǶȡ�Ȼ����ͼ������½�Ϊ��������,�����ת������
import cv2
import numpy as np
import pytesseract
import cv2 as cv
import math
image = cv2.imread('C:\\Users\\14192\\Desktop\\7.jpg', 1)
# �Ҷ�ͼƬ
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
edges = cv.Canny(gray, 50, 150, apertureSize=3) # 50,150,3
cv.imwrite('test_3\\edges_whole.jpg', edges)
lines = cv.HoughLinesP(edges, 1, np.pi / 180, 500, 0, minLineLength=50, maxLineGap=50) # 650,50,20
print("һ����{}��ֱ��".format(len(lines)))
pi = 3.1415
theta_total = 0
theta_count = 0
for line in lines:
x1, y1, x2, y2 = line[0]
rho = np.sqrt((x1 - x2) ** 2 + (y1 - y2) ** 2)
theta = math.atan(float(y2 - y1) / float(x2 - x1 + 0.001))
print(rho, theta, x1, y1, x2, y2)
if theta < pi / 4 and theta > -pi / 4:
theta_total = theta_total + theta
theta_count += 1
cv.line(image_copy, (x1, y1), (x2, y2), (0, 0, 255), 2)
# cv.line(edges, (x1, y1), (x2, y2), (0, 0, 0), 2)
theta_average = theta_total / theta_count
print(theta_average, theta_average * 180 / pi)
cv.imwrite('test_3\\line_detect4rotation.jpg', image_copy)
affineShrinkTranslationRotation = cv.getRotationMatrix2D((0, rows), theta_average * 180 / pi, 1)
gray = cv.warpAffine(gray, affineShrinkTranslationRotation, (cols, rows))
cv.imwrite('test_3\\image_Rotation.jpg', gray)
����ʹ��Canny�����õ�������״,����ͼһ��ʾ��Ȼ��ʹ�û�������ȡ����ֱ����Ϣ(����ͼ��),Ȼ��ͨ��б�ʶ�ֱ�߽���ɸѡ,�õ����ߵ���Ϣ(����ͼ����ʾ)��



�漰����ͼ��������
1. Canny������ȡ
Canny��ȡ������Ϣ��ԭ�������Ƚ��и�˹ȥ��,���ƽ��ͼƬ;
Ȼ���ȡͼ����ˮƽ�ʹ�ֱ�����һ����,Ҳ�����ݶ���Ϣ;
���ű�����ͼ,ֻ������Щ�ڸ����ݶ��о�������ݶȵ����ص��ԭʼ��Ϣ,��Ϊ�����Ե�,ֻ�б߽��ϵ����ص��ݶȲ������ġ�
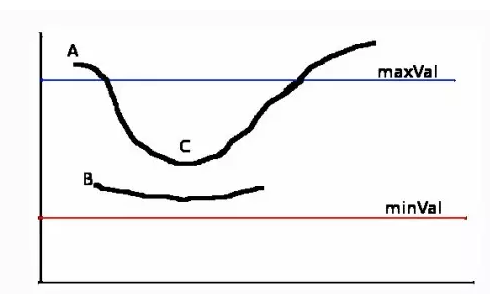
������ôѡ���ݶȴ�С��Ϊ��ֵҲ��Ҫ��Ϊ����,��Canny��������������ֵҪ�趨,minVal��maxVal.����maxVal������Ϊ�DZ߽�,С��minVal��ֱ������,����Ϊӵ�������ݶȵĵ��DZ߽硣��������֮������ص�,�������Ƿ��ij���߽�����,�������,����Ϊ�DZ߽���Ϣ,����������
������һ����ʾ��ͼ,�ο�opencv��Ե���CCanny������ѧϰ����-��Ե���-Canny��Ե�������������,��������ֵ���õıȽ�С��ʱ��,��ôCanny����֮���ͼ��ᱣ�������������Ϣ����ʵ��ʹ����,һ����Ҫ��������,��һ��������ԭͼimg,�ڶ��͵����������ֱ���minVal��maxVal,�ؼ��ֲ���apertureSize�Ǽ���ͼ���ݶ�ʱʹ�õľ����˵ijߴ���Ϣ,Ĭ��Ϊ3,��һ�ؼ��ֲ���L2gradient,�����������趨���ݶȴ�С�ķ���,��ʹ�õ�ʱ��,�����Ȳ������ᡣ
2. ����仯��ȡֱ��
����任(Hough Transform)��ͼ�����е�һ��������ȡ����,�ù�����һ�������ռ���ͨ�������ۼƽ���ľֲ����ֵ�õ�һ�����ϸ��ض���״�ļ�����Ϊ����任�����
����任��1962����PaulHough�״����,�����Hough�任������������ֱ�ߺ�����,����ķ���Ҫ��֪������߽��ߵĽ�������,������Ҫ�й�����λ�õ�����֪ʶ�����ַ�����һ��ͻ���ŵ��Ƿָ�����Robustness,�������ݵIJ���ȫ���������Ƿdz����С�Ȼ��,Ҫ��������߽�Ľ������ﳣ���Dz����ܵġ�������1972����Richard Duda & Peter Hart�ƹ�ʹ��,�������任�������ͼ���е�ֱ��,��������任��չ��������״�����ʶ��,��ΪԲ����Բ������任������������ռ�֮��ı任����һ���ռ��о�����ͬ��״������ֱ��ӳ�䵽��һ������ռ��һ�������γɷ�ֵ,�Ӷ��Ѽ��������״������ת��Ϊͳ�Ʒ�ֵ���⡣
�����߱任��һ������Ѱ��ֱ�ߵķ���. ��ʹ�û����߱任֮ǰ, ����Ҫ��ͼ����б�Ե���Ĵ���,Ҳ�������߱任��ֱ������ֻ���DZ�Ե��ֵͼ��.
��OpenCV��,���ǿ�����HoughLines���������ñ�����任SHT�Ͷ�߶Ȼ���任MSHT����HoughLinesP�������ڵ����ۼƸ��ʻ���任PPHT���ۼƸ��ʻ���任ִ��Ч�ʺܸ�,���������HoughLines����,���Ǹ�������ʹ��HoughLinesP������
lines =cv.HoughLinesP(image, rho, theta, threshold[, lines[, minLineLength[, maxLineGap]]] )
- image:����ͼ��(����Ϊ��ֵͼ��),�Ƽ�ʹ��canny��Ե���Ľ��ͼ��
- rho:�ۼ����ľ���ֱ���,������Ϊ��λ
- theta:�ۼ����ĽǶȷֱ���,�Ի��ȱ�ʾ
- threshold:�ۼ�����ֵ����,int����,�����趨��ֵ�ű������߶�,ֵԽ��,��������ζ�ż�����߶�Խ��,������߶θ���Խ�١�
- lines:�������������δ֪,���ֲ�ͬ��lines�Խ��ûӰ��,���Dz�Ҫ���������Ĵ���
- minLineLength:����߶ε���С����
- maxLineGap:ͬһ�����������߶��ж�Ϊһ���߶ε�����������(����),�������趨ֵ,��������߶ε���һ���߶�,ֵԽ��,�����߶��ϵĶ���Խ��,Խ�п��ܼ��DZ�ڵ�ֱ�߶�
3. ����任
����任��ָ�������ռ��н���һ�����Ա任(����һ������)������һ��ƽ��(����һ������),�任Ϊ��һ�������ռ�Ĺ��̡�������ά�������,ÿ������任������һ������A��һ������b����,������д��A��һ�����ӵ���b��һ������任��Ӧ��һ�������һ�������ij˷�,������任�ĸ��϶�Ӧ����ͨ�ľ���˷�,ֻҪ����һ��������е�����ĵ���,��һ��ȫ����0�������ұ���һ��1,���������ĵ���Ҫ����һ��1.
Affine Transform������һ�ֶ�ά����任�Ĺ���,����һ�ֶ�ά����֮������Ա任,���ֶ�άͼ�εġ�ƽֱ�ԡ�(���任��ֱ����ֱ��,Բ������Բ��)�͡�ƽ���ԡ�(��ʵ�DZ��ֶ�άͼ�μ�����λ�ù�ϵ����,ƽ������ƽ����,��ֱ���ϵĵ�λ��˳��,���ر�ע��������нǿ��ܻᷢ���仯)������任����ͨ��һϵ�е�ԭ�ӱ任�ĸ�����ʵ�ְ���:ƽ��(Translation)������(Scale)����ת(Flip)����ת(Rotation)�ʹ���(Shear). �ο�����:opencvѧϰ(��ʮ��)֮����任warpAffine
����opencvʵ�ַ���任һ����漰��warpAffine��getRotationMatrix2D��������,����warpAffine����ʵ��һЩ����ӳ��,��getRotationMatrix2D���Ի����ת����
2. ʹ��opencv�Ա����С���ο������ȡ
2.1 ͼ��Ԥ����
# ��ֵ��
binary = cv2.adaptiveThreshold(~gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 35, -5)
cv2.imwrite("test4\\gray.jpg", binary)

���Ƚ�ͼƬ�Ҷȴ���,Ȼ��ʹ��cv2.adaptiveThresholdʵ�ֶ�ֵ���������ڻҶ�ͼ�ǽ�ԭ������ͨ��תΪ��ͨ��,ÿ�����ص��ֵ��Χ��(0,255)֮��,0��ʾ��ɫ,255��ʾ��ɫ����ֵ���������ǽ�ͼ����ȫ�ı�ɺڰ�������ɫ(ʵ�ʻ���Ӹ���)�����õĶ�ֵ��������cv2.threshold�̶���ֵ��ֵ��������adaptiveThreshold����Ӧ��ֵ��ֵ�����̶���ֵ�ķ������ǶԸ�����ֵ����ͳһ��Ϊij��ָ����ɫ,������ֵ��������һ����ɫ������Ӧ��ֵ��ֵ����������ͼƬһС�������ֵ�������Ӧ�������ֵ,�Ӷ��õ�Ҳ����Ϊ���ʵ�ͼƬ���ο�����python-opencv�����ܽ�֮(һ)threshold��adaptiveThreshold��Otsu ��ֵ��
dst = cv2.adaptiveThreshold(src, maxval, thresh_type, type, Block Size, C)
- src: ����ͼ,ֻ�����뵥ͨ��ͼ��,ͨ����˵Ϊ�Ҷ�ͼ
- dst: ���ͼ
- maxval: ������ֵ��������ֵ(����С����ֵ,����type������),�������ֵ
- thresh_type: ��ֵ�ļ��㷽��,��������2������:cv2.ADAPTIVE_THRESH_MEAN_C; cv2.ADAPTIVE_THRESH_GAUSSIAN_C.
- type:��ֵ������������,��̶���ֵ������ͬ,��������5������: cv2.THRESH_BINARY; cv2.THRESH_BINARY_INV; cv2.THRESH_TRUNC; cv2.THRESH_TOZERO;cv2.THRESH_TOZERO_INV.
- Block Size: ͼƬ�зֿ�Ĵ�С
- C :��ֵ���㷽���еij�����
�����������ͼƬ��~grap���ʾ��λȡ��,���Կ���ע�ԭ����ɫ�ı�Ϊ��ɫ,ԭ������ɫ�����Ϊ��ɫ��
2.2 ������ʶ��
���ݵõ��Ķ�ֵͼ,�ֱ�ʶ����ߡ�����,���������߽��.
rows, cols = binary.shape
print("rows: ", rows, ", cols: ", cols)
scale = 60
# ʶ�����
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (cols // scale, 1))
eroded = cv2.erode(binary, kernel, iterations=1)
cv2.imwrite("test4\\Eroded_Image.jpg", eroded)
dilatedcol = cv2.dilate(eroded, kernel, iterations=1)
cv2.imwrite("test4\\transverse.jpg", dilatedcol)
# ʶ������
scale = 20
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 40))
eroded = cv2.erode(binary, kernel, iterations=1)
dilatedrow = cv2.dilate(eroded, kernel, iterations=1)
cv2.imwrite("test4\\verticalline.jpg", dilatedrow)
# ��ʶ����
bitwiseAnd = cv2.bitwise_and(dilatedcol, dilatedrow)
# cv2.imshow("����չʾ:", bitwiseAnd)
cv2.imwrite("test4\\point.jpg", bitwiseAnd) # ����ֵ���ص�����ͼƬ����
print(bitwiseAnd.shape)
merge = cv2.add(dilatedcol, dilatedrow)
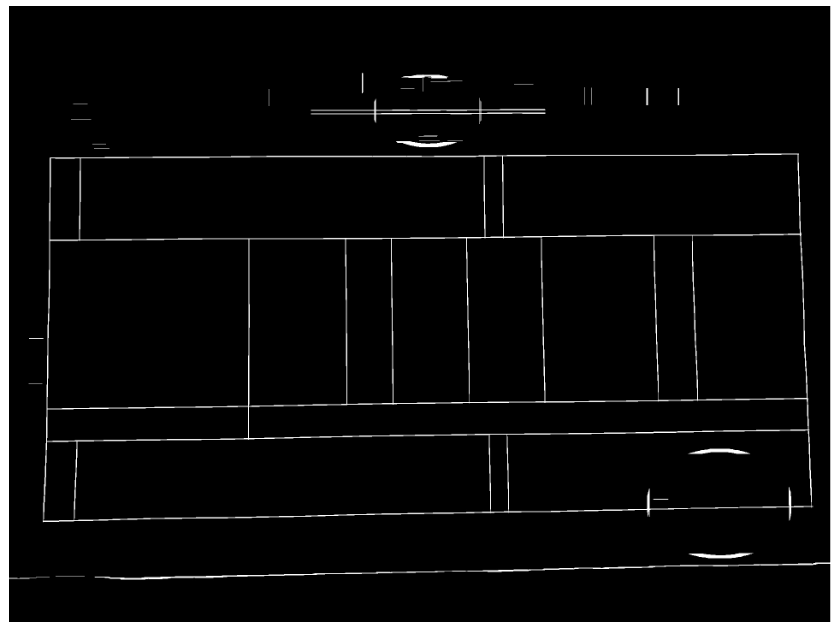
������������������ɻ�,��Ȼ�����ᵽ�Ļ���������������ȡֱ��,��ôΪʲô���ﲻʹ�á��ҵĸо���,����ҪѰ�Ҵ�߶�ֱ�ߵ�ʱ��,����ʹ�û����������Ƕ�������ȫ�ֵĺ��и���С�߶ε�ͼ��,�Ͳ�������,���Ȼ�������Ҫ�ֶ���������ֵ,ֻ�г�����ֵ�IJŻᱻ��Ϊ��ֱ�ߡ����ǿ�����һ����ʵ��,��������ֵΪcol/20,col/10,col/7,col/5�IJ�ͬ��������Կ����������õ�������Ҫ�ı߿��ߡ�


�����Ҫʹ�ø�ʴ�����͡�ʶ����ߺ����ߵ�ԭ������һ��,ͨ��������Ӧ�ĺ˾���kernel,Ȼ����и�ʴeroded�����Ͳ���dilate�������Ϳ��Եõ������ߡ������ߵĽ������ͨ��bitwise_and�������,�����ߵĽ���ͼ�����ͨ��add����ʵ�֡�


�漰����ͼ��������
������ҪҪ����һ�º˾����Լ���ʴ�����͡������㡢������,��������̬ѡ�������Բο���̬ѧ����(��ʴ�����͡��������㡢��Ե���)
�˾�������һ��np.array������,����һ��ʮ�ֺ˾���
element = cv2.getStructuringElement(cv2.MORPH_CROSS,(5,5))
�䱾����һ�������ľ���
array([[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0],
[1, 1, 1, 1, 1],
[0, 0, 1, 0, 0],
[0, 0, 1, 0, 0]], dtype=uint8)
ͬ������֪��
cv2.getStructuringElement(cv2.MORPH_RECT,(5,5))
�䱾����ȫ1����
���Ƕ�����һ�������ĺ˾���֮��,��ʹ���������и�ʴ�����Ͳ�����
- ��ʴ:��ʴ�������ı߽縯ʴ��,����������ͼ��,��������˶�Ӧ��ԭͼ����������ֵΪ1,��ô����Ԫ�ؾͱ���ԭ����ֵ,�����Ϊ�㡣��ҪӦ����ȥ��������,Ҳ���ԶϿ�����һ������塣
- ����:����������Ӧ��ԭͼ�������ֵֻҪ��һ����1,��������ֵ����1��һ���ڳ�����,�ȸ�ʴ������,��Ϊ��ʴ��ȥ����������ʱ��Ҳ��ʹͼ����С,��������֮��Ҫ�������͡���ȻҲ������������������ֿ���
��������ʹ�õĺ˾�����״Ϊ(cols // scale, 1),������ͼ�ķ�Ʊ,��colΪ1920,scale��Ϊ���ó�40,Ҳ����(48,1),����һ�������ε�ȫ1����,��ô������������ڸ�ʴ��ʱ��, �Ὣ��ֱ�߱���,���������48���ص��������ᱻ����Ϊ��ɫ�������Ͳ��õ��������еĺ��ᱻ�������������͵�ԭ��Ҳ����,�������ˡ���ʴ�����͵ķ��ؽ��������ԭͼ��С��image,����ͼ��ʾ��
������ͱ������ǽ���ʴ�����Ͱ���һ���Ĵ�����д������������߲����ǿ����,���ȿ���ղ����ܵõ�ԭ�ȵ�ͼ��
Ϊ�˻�ȡͼ���е���Ҫ����:��һ����ֵͼ����ʹ�ñ�����Ϳ�����,��������ͼ���е�����,Ҳ���Զ�ͼ�����ÿ�������ñ�����,��������Ҳ������һЩ����Ķ���
- ������:�ȸ�ʴ������,�����Ƴ���ͼ�������γɵİߵ㡣
- ������:�����ͺ�ʴ,�������ӱ����Ϊ����С��Ķ���;
2.3 ����
�ڻ���˺��ߺ����ߵĽ���ͼ��bitwiseAnd�Լ���ú��ߺ����ߵĽ���ͼ��merge֮��,������λ��ֱ���,��Ҫ�����ֲ�ͬ��˼·
- ʹ��opencv��findContours()���ܻ�þ�������
- ���ݽ���,ɾ������Ľ���֮��,һ�α����佻������з�
��ʹ�õ��ǵ�һ��˼·,�ȰѴ��븽��,�����˵�ڶ���˼·�����ó�����
def get_contours(image):
image_copy = image
rows,cols =image.shape
contours, hierarchy = cv.findContours(image, cv.RETR_LIST, cv.CHAIN_APPROX_SIMPLE)
length = len(contours)
print("�ҵ�{}������".format(length))
rects = []
for i in range(length):
cnt = contours[i]
area = cv.contourArea(cnt)
if area < int(rows*cols*0.001):
continue
approx = cv.approxPolyDP(cnt, 3, True) # 3
x, y, w, h = cv.boundingRect(approx)
rect = (x, y, w, h)
small_rects.append(rect)
# cv.rectangle(image_copy, (x, y), (x+w, y+h), (0, 0, 255), 3)
# cv.imwrite('test1\\table_out.jpg', image_copy)
roi = image[y:y + h, x:x + w]
joints_contours, joints_hierarchy = cv.findContours(roi, cv.RETR_LIST, cv.CHAIN_APPROX_SIMPLE)
# print len(joints_contours)
# if h < 80 and h > 20 and w > 10 and len(joints_contours)<=4:
if h < 80 and h > 20 and w > 10 and len(joints_contours) <= 6: # important
cv.rectangle(image_copy, (x, y), (x + w, y + h), (255 - h * 3, h * 3, 0), 3)
# small_rects.append(rect)
cv.imwrite('test4\\table_out.jpg', image_copy)
print("����ɸѡ֮��,����{}������".format(len(small_rects)))
return small_rects
small_rects = get_contours(merge1)
ͨ������Ĵ���,���Ի��ÿ���������,����з�һ��,�õ��Ľ������:
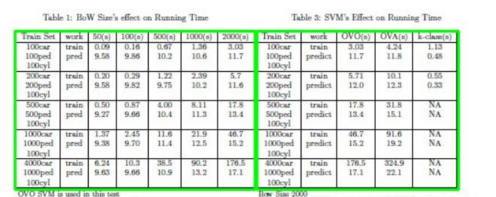
�ڶ���˼·,���ڽ����ʹ�÷�ʽ,Ҳ������˼·�����Ȳο� Ҫ�����:Python+OpenCVУ������ȡ�����еĸ������еĴ���,ʹ���˵�һ�ַ�ʽ,���ַ�ʽ��˼·��ͨ����õĽ���ͼ��,�����а�ɫ������������ȡ����;ɾ������λ�úܽ�����������;��������������֮��,�ֱ𱣴��������б���,Ȼ�����α��������ꡢ������,����ѭ���ķ�ʽ�����и
for i in range(len(mylisty) - 1):
for j in range(len(mylistx) - 1):
# �ڷָ�ʱ,��һ������Ϊy����,�ڶ�������Ϊx����
ROI = image[mylisty[i] + 3:mylisty[i + 1] - 3, mylistx[j]:mylistx[j + 1] - 3] # ��ȥ3��ԭ������������СROI��Χ
cv2.imwrite("test1//fengezituzhanshi{}{}.jpg".format(i,j), ROI)
���ַ�ʽ������excel���ֱȽϱ��ı�������ͼ��ʾ,�����ڷ�Ʊ������ᵼ�¶�����и
�ڶ���˼·����һ��ʵ�ֿ����������ͼ����ʾ,��û�г���ʵ��,����Ӧ���ǿ��еġ�
����
- ���߶����ʶ��Ϊϸ�߶�����