NNDL ʵ���� ���Է���
3.1 ����Logistic�ع�Ķ���������
3.1.1 ���ݼ�����
�������ȹ���һ���ķ�������,������ѵ��������֤���Ͳ��Լ���
��������������Դ�����������������״����,ÿ�����¶�һ��������Dzɼ�1000������,ÿ����������2��������
���ݼ��Ĺ�������make_moons�Ĵ���ʵ������:
import math
import copy
import torch
def make_moons(n_samples=1000, shuffle=True, noise=None):
"""
���ɴ�������������״����
����:
- n_samples:��������С,��������Ϊint
- shuffle:�Ƿ��������,��������Ϊbool
- noise:�Զ��ij̶���������,��������ΪNone��float,noiseΪNoneʱ��ʾ����������
���:
- X:��������,shape=[n_samples,2]
- y:��ǩ����, shape=[n_samples]
"""
n_samples_out = n_samples // 2
n_samples_in = n_samples - n_samples_out
# �ɼ���1������,����Ϊ(x,y)
# ʹ��'torch.linspace'��0��pi�Ͼ���ȡn_samples_out��ֵ
# ʹ��'torch.cos'��������ȡֵ������ֵ��Ϊ����1,ʹ��'torch.sin'��������ȡֵ������ֵ��Ϊ����2
outer_circ_x = torch.cos(torch.linspace(0, math.pi, n_samples_out))
outer_circ_y = torch.sin(torch.linspace(0, math.pi, n_samples_out))
inner_circ_x = 1 - torch.cos(torch.linspace(0, math.pi, n_samples_in))
inner_circ_y = 0.5 - torch.sin(torch.linspace(0, math.pi, n_samples_in))
print('outer_circ_x.shape:', outer_circ_x.shape, 'outer_circ_y.shape:', outer_circ_y.shape)
print('inner_circ_x.shape:', inner_circ_x.shape, 'inner_circ_y.shape:', inner_circ_y.shape)
# ʹ��'torch.cat'���������ݵ�����1������2�ֱ���ά��0ƴ����һ��,�õ�ȫ������1������2
# ʹ��'torch.stack'������������ά��1�ѵ���һ��
X = torch.stack(
[torch.cat([outer_circ_x, inner_circ_x]),
torch.cat([outer_circ_y, inner_circ_y])],
axis=1
)
print('after concat shape:', torch.cat([outer_circ_x, inner_circ_x]).shape)
print('X shape:', X.shape)
# ʹ��'torch. zeros'����һ�����ݵı�ǩȫ������Ϊ0
# ʹ��'torch. ones'����һ�����ݵı�ǩȫ������Ϊ1
y = torch.cat(
[torch.zeros([n_samples_out]), torch.ones([n_samples_in])]
)
print('y shape:', y.shape)
# ���shuffleΪTrue,���������ݴ���
if shuffle:
# ʹ��'torch.randperm'����һ����ֵ��0��X.shape[0],������е�һάTensor������ֵ,���ڴ�������
idx = torch.randperm(X.shape[0])
X = X[idx]
y = y[idx]
# ���noise��ΪNone,�������ֵ��������
if noise is not None:
# ʹ��'torch.normal'���ɷ�����̬�ֲ������Tensor��Ϊ����,���ӵ�ԭʼ������
X += torch.normal(0, noise, X.shape)
return X, y
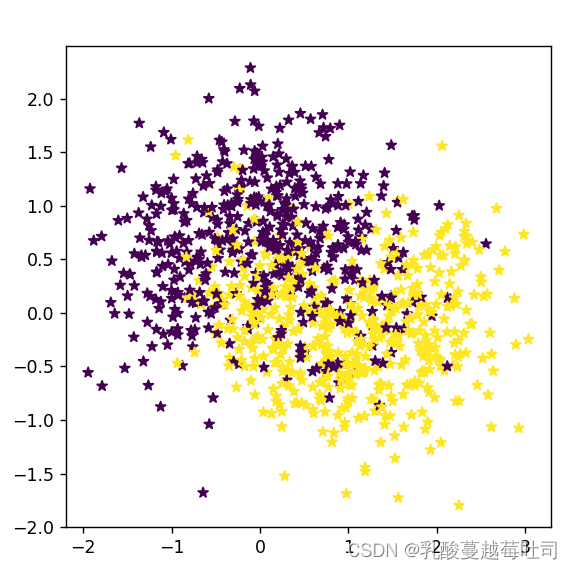
����ɼ�1000������,�����п��ӻ���
# ����1000������
n_samples = 1000
X, y = make_moons(n_samples=n_samples, shuffle=True, noise=0.5)
# ���ӻ����������ݼ�,��ͬ��ɫ������ͬ���
import matplotlib.pyplot as plt
plt.figure(figsize=(5,5))
plt.scatter(x=X[:, 0].tolist(), y=X[:, 1].tolist(), marker='*', c=y.tolist())
plt.xlim(-3,4)
plt.ylim(-3,4)
plt.savefig('linear-dataset-vis.pdf'
plt.show()
���:
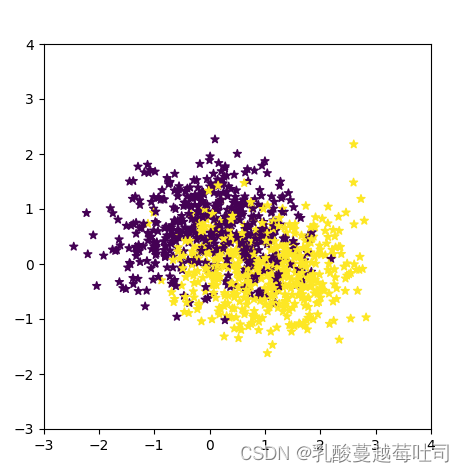
��1000���������ݲ�ֳ�ѵ��������֤���Ͳ��Լ�,����ѵ����640������֤��160�������Լ�200��������ʵ������:
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
y_train = y_train.reshape([-1,1])
y_dev = y_dev.reshape([-1,1])
y_test = y_test.reshape([-1,1])
����,���Ǿ������Moon1000���ݼ��Ĺ�����
# ��ӡX_train��y_train��ά��
print("X_train shape: ", X_train.shape, "y_train shape: ", y_train.shape)
# ��ӡһ��ǰ5�����ݵı�ǩ
print (y_train[:5])
���:
3.1.2 ģ����
Logistic�ع���һ�ֳ��õĴ������������������ģ�͡������Իع�һ��,Logistic�ع�Ҳ�Ὣ����������Ȩ�������Ե��ӡ���֮ͬ������,Logistic�ع������˷����Ժ���g:RD��(0,1),Ԥ������ǩ�ĺ������ p(y=1|x) ,�Ӷ�������������Ժ������ʺϽ��з�������⡣
p
(
y
=
1
�O
x
)
=
��
(
w
T
x
+
b
)
p(y=1|x)=\sigma (w^{T}x+b)
p(y=1�Ox)=��(wTx+b)
���м����ΪLogistic����,�����ǽ����Ժ���f(x;w,b)�������ʵ�����䡰��ѹ����(0,1)֮��,������ʾ���ʡ�Logistic��������Ϊ:
��
(
x
)
=
1
1
+
e
x
p
(
?
x
)
\sigma(x)=\frac{1}{1+exp(-x)}
��(x)=1+exp(?x)1?
Logistic�����Ĵ���ʵ������:
# ����Logistic����
def logistic(x):
return 1 / (1 + torch.exp(-x))
# ��[-10,10]�ķ�Χ������һϵ�е�����ֵ,���ڻ��ƺ�������
x = torch.linspace(-10, 10, 10000)
plt.figure()
plt.plot(x.tolist(), logistic(x).tolist(), color="#e4007f", label="Logistic Function")
# ����������
ax = plt.gca()
# ȡ���Ҳ���ϲ�������
ax.spines['top'].set_color('none')
ax.spines['right'].set_color('none')
# ����Ĭ�ϵ�x���y�᷽��
ax.xaxis.set_ticks_position('bottom')
ax.yaxis.set_ticks_position('left')
# ��������ԭ��Ϊ(0,0)
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
# ����ͼ��
plt.legend()
plt.savefig('linear-logistic.pdf')
plt.show()
���: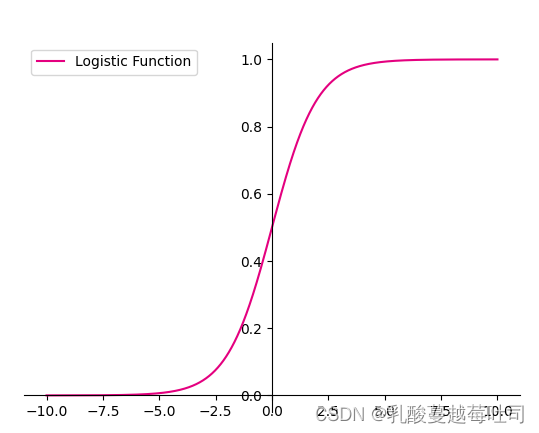
�������,��������0����ʱ,Logistic��������Ϊ���Ժ���;��������ֵ�dz����dz�Сʱ,�����������������ơ�����ԽС,��Խ�ӽ�0;����Խ��,��Խ�ӽ�1������ΪLogistic������������������,ʹ�����������ֱ�ӿ���Ϊ���ʷֲ���
Logistic�ع�����
Logistic�ع�ģ����ʵ�������Բ���Logistic���������,ͨ���Ὣ Logistic�ع�ģ���е�Ȩ�غ�ƫ�ó�ʼ��Ϊ0,ͬʱ,Ϊ�����Ԥ��������Ч��,���ǽ�N��������Ϊһ����г�����Ԥ�⡣
y
^
=
p
(
y
�O
x
)
=
��
(
X
w
+
b
)
\hat{y}=p(y|x)=\sigma (Xw+b)
y^?=p(y�Ox)=��(Xw+b)
����
X
��
R
N
��
D
Ϊ
N
����������������
,
y
^
Ϊ
N
��������Ԥ��ֵ���ɵ�
N
������
X��R^{N\times D}ΪN����������������,\hat{y}ΪN��������Ԥ��ֵ���ɵ�Nά������
X��RN��DΪN����������������,y^?ΪN��������Ԥ��ֵ���ɵ�Nά������
����,���ǹ���һ��Logistic�ع�����,����ʵ������:
# ��������
class Op(object):
def __init__(self):
pass
def __call__(self, inputs):
return self.forward(inputs)
def forward(self, inputs):
raise NotImplementedError
def backward(self, inputs):
raise NotImplementedError
op=Op
class model_LR(op):
def __init__(self, input_dim):
super(model_LR, self).__init__()
self.params = {}
# �����Բ��Ȩ�ز���ȫ����ʼ��Ϊ0
self.params['w'] = torch.zeros([input_dim, 1])
# self.params['w'] = torch.normal(mean=0, std=0.01, shape=[input_dim, 1])
# �����Բ��ƫ�ò�����ʼ��Ϊ0
self.params['b'] = torch.zeros([1])
def __call__(self, inputs):
return self.forward(inputs)
def forward(self, inputs):
"""
����:
- inputs: shape=[N,D], N����������,D������
���:
- outputs:Ԥ���ǩΪ1�ĸ���,shape=[N,1]
"""
# ���Լ���
score = torch.matmul(inputs, self.params['w']) + self.params['b']
# Logistic ����
outputs = logistic(score)
return outputs
����һ��
�������3������Ϊ4����������Logistic�ع�ģ��,�۲���������
# �̶��������,����ÿ�����н��һ��
torch.seed()
# �������3������Ϊ4������
inputs = torch.randn([3,4])
print('Input is:', inputs)
# ʵ����ģ��
model = model_LR(4)
outputs = model(inputs)
print('Output is:', outputs)
���:
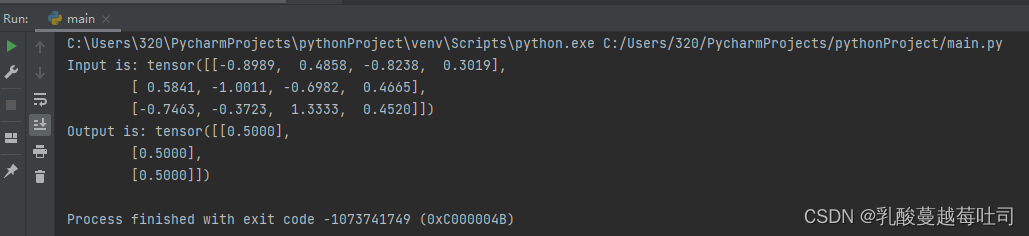
����������,ģ�����յ����g(?)��Ϊ0.5���������ڲ���ȫ0��ʼ����,��������ֵ�Ĵ�СΪ����,Logistic����������ֵ��Ϊ0,��������Ϊ0.5��
����1:Logistic�ع��ڲ�ͬ���鼮��,�����������ijƺ�,��������Щ?����Ϊ�ĸ��ƺ����?
���ж������ʻع�,��˹�ٻع顣
�������ʻع���á����ڶ���������,��������ǵ�λ��Ծ����,���ǵ�λ��Ծ����������,������,�����ö������ʺ������档�������ʺ���(logistic function),��ƶ��ʺ������Ӷ������ʻع�������־��ܵ�֪�������˶������ʺ���,ͦ�������˵ġ�
����2:ʲô�Ǽ����?
�������һ�����ӵ��˹��������еĺ���,ּ�ڰ�������ѧϰ�����еĸ���ģʽ������Ԫ��,�����input����һϵ�м�Ȩ��ͺ���������һ������,���������������ļ������
ΪʲôҪ�ü����?
��Ϊ��������ÿһ��������������һ��������͵Ĺ���,��һ������ֻ�dzн�����һ�����뺯�������Ա任,�������û�м����,��ô�����㹹����������ô����,�ж��ٲ�,�����������������������,�����������ϲ����ܹ������Ϊ���ӵ����⡣�����뼤���֮��,���ǻᷢ�ֳ����ļ�������Ƿ����Ե�,���Ҳ�����Ԫ���������Ԫ��,ʹ����������Աƽ��������κη����Ժ���,��������ʹ��������Ӧ�õ����������ģ���С�
�������������Щ?
(1)sigmoid
�ٶ���:sigmoid��������Ӱ�ز���Ԫ���,�ܽ���ֵӳ�䵽(0,1)����,��������������,����ʽΪ:
f
(
x
)
=
1
1
+
e
?
x
f ( x ) = \frac{1}{1+e^{-x}}
f(x)=1+e?x1?
���ص�:
�ŵ�:ƽ����������
ȱ��:�������������,����ʱ,�����׳����ݶ���ʧ
(2)tanh
�ٶ���:˫�����к���,����ʽΪ:
f
(
x
)
=
1
?
e
?
2
x
1
+
e
?
2
x
f(x) = \frac{1-e^{-2x}}{1+e^{-2x}}
f(x)=1+e?2x1?e?2x?
���ص�:
�ŵ�:ƽ��,������,�����ֵΪ0,�����ٶȱ�sigmoid��,���ٵ�������
ȱ��:�����׳����ݶ���ʧ
(3)relu
�ٶ���:�������Ե�Ԫ,�����ʽΪ:
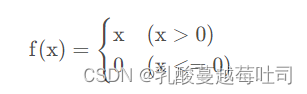
���ص�:
�ŵ�:������̼�,�������ݶ���ʧ���ݶȱ�ը����
ȱ��:С�ڵ���0ʱ�����
3.1.3 ��ʧ����
��ģ��ѵ��������,��Ҫʹ����ʧ����������Ԥ��ֵ����ʵֵ֮��IJ��졣
����һ����������,y��ʾ����x�ı�ǩ����ʵ���ʷֲ�,����y^=p(y|x)��ʾԤ��ı�ǩ���ʷֲ���
ѵ��Ŀ����ʹ��y^�����ܵؽӽ�y,ͨ������ʹ�ý�������ʧ������
�ڸ���y�������,���Ԥ��ĸ��ʷֲ�y^���ǩ��ʵ�ķֲ�yԽ�ӽ�,����ԽС;���p(x)��yԽԶ,�����ؾ�Խ��
���ڶ���������,����ֻ��Ҫ����y=p(y=1|x),��1?y����ʾp(y=0|x)��
������N��ѵ��������ѵ����{(x(n),y(n))}Nn=1,ʹ�ý�������ʧ����,Logistic�ع�ķ��պ������㷽ʽΪ:
R
(
w
,
b
)
=
?
1
N
��
n
=
1
N
(
y
(
n
)
l
o
g
y
^
(
n
)
+
(
1
?
y
(
n
)
l
o
g
(
1
?
y
^
(
n
)
)
R(w,b)=-\frac{1}{N}\sum_{n=1}^{N}(y^{(n)}log\hat{y}^{(n)}+(1-y^{(n)}log(1-\hat{y}^{(n)})
R(w,b)=?N1?n=1��N?(y(n)logy^?(n)+(1?y(n)log(1?y^?(n))
����������Ľ�������ʧ�����Ĵ���ʵ������:
# ʵ�ֽ�������ʧ����
class BinaryCrossEntropyLoss(op):
def __init__(self):
self.predicts = None
self.labels = None
self.num = None
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
"""
����:
- predicts:Ԥ��ֵ,shape=[N, 1],NΪ��������
- labels:��ʵ��ǩ,shape=[N, 1]
���:
- ��ʧֵ:shape=[1]
"""
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = -1. / self.num * (torch.matmul(self.labels.t(), torch.log(self.predicts)) + torch.matmul((1-self.labels.t()), torch.log(1-self.predicts)))
loss = torch.squeeze(loss, 1)
return loss
# ����һ��
# ����һ�鳤��Ϊ3,ֵΪ1�ı�ǩ����
labels = torch.ones([3,1])
# ������պ���
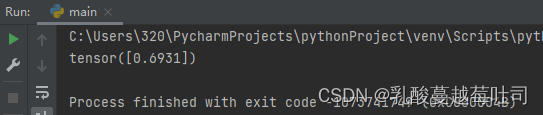
bce_loss = BinaryCrossEntropyLoss()
print(bce_loss(outputs, labels))
���:
3.1.4 ģ���Ż�
��ͬ�����Իع���ֱ��ʹ����С���˷����ɽ���ģ�Ͳ��������,Logistic�ع���Ҫʹ���Ż��㷨��ģ�Ͳ����������εص�������ȡ���ŵ�ģ��,�Ӷ������ܵؽ��ͷ��պ�����ֵ��
�ڻ���ѧϰ������,������õ��Ż��㷨���ݶ��½�����
ʹ���ݶ��½�������ģ���Ż�,������Ҫ��ʼ������W�� b,Ȼ�ϵؼ������ǵ��ݶ�,�����ݶȵķ�������²�����
3.1.4.1 �ݶȼ���
��Logistic�ع���,���պ���R(w,b) ���ڲ���w��b��ƫ����Ϊ:
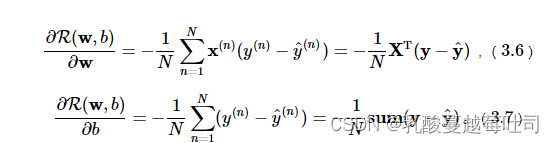
ͨ����ƫ�����ļ�����̶�����Logistic�ع����ӵ�backward������,����ʵ������:
class model_LR(op):
def __init__(self, input_dim):
super(model_LR, self).__init__()
# ������Բ����
self.params = {}
# �����Բ��Ȩ�ز���ȫ����ʼ��Ϊ0
self.params['w'] = torch.zeros([input_dim, 1])
# self.params['w'] = paddle.normal(mean=0, std=0.01, shape=[input_dim, 1])
# �����Բ��ƫ�ò�����ʼ��Ϊ0
self.params['b'] = torch.zeros([1])
# ��Ų������ݶ�
self.grads = {}
self.X = None
self.outputs = None
def __call__(self, inputs):
return self.forward(inputs)
def forward(self, inputs):
self.X = inputs
# ���Լ���
score = torch.matmul(inputs, self.params['w']) + self.params['b']
# Logistic ����
self.outputs = logistic(score)
return self.outputs
def backward(self, labels):
"""
����:
- labels:��ʵ��ǩ,shape=[N, 1]
"""
N = labels.shape[0]
# ����ƫ����
self.grads['w'] = -1 / N * torch.matmul(self.X.t(), (labels - self.outputs))
self.grads['b'] = -1 / N * torch.sum(labels - self.outputs)
3.1.4.2 ��������
�ڼ���������ݶ�֮��,���ǰ������湫ʽ���²���:
���Ц� Ϊѧϰ�ʡ�
������IJ������¹��̰�װΪ�Ż���,���ȶ���һ���Ż�������Optimizer,����������е��Ż������á������������,��Ҫ��ʼ���Ż����ij�ʼѧϰ��init_lr,�Լ�ָ���Ż�����Ҫ�Ż��IJ���������ʵ������:
from abc import abstractmethod
# �Ż�������
class Optimizer(object):
def __init__(self, init_lr, model):
"""
�Ż������ʼ��
"""
# ��ʼ��ѧϰ��,���ڲ������µļ���
self.init_lr = init_lr
# ָ���Ż�����Ҫ�Ż���ģ��
self.model = model
@abstractmethod
def step(self):
"""
����ÿ�ε�����θ��²���
"""
pass
Ȼ��ʵ��һ���ݶ��½������Ż�������SimpleBatchGD��ִ�в������¹��̡�����step������ģ�͵�grads����ȡ���������ݶȲ����¡�����ʵ������:
class SimpleBatchGD(Optimizer):
def __init__(self, init_lr, model):
super(SimpleBatchGD, self).__init__(init_lr=init_lr, model=model)
def step(self):
# ��������
# �������в���,���չ�ʽ(3.8)��(3.9)���²���
if isinstance(self.model.params, dict):
for key in self.model.params.keys():
self.model.params[key] = self.model.params[key] - self.init_lr * self.model.grads[key]
3.1.5 ����ָ��
�ڷ���������,ͨ��ʹ��ȷ��(Accuracy)��Ϊ����ָ�ꡣ���ģ��Ԥ����������ʵ���һ��,��˵��ģ��Ԥ����ȷ��ȷ�ʼ���ȷԤ����������ܵ�Ԥ�������ı�ֵ:
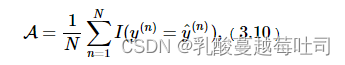
����I(?)��ָʾ����������ʵ������:
def accuracy(preds, labels):
"""
����:
- preds:Ԥ��ֵ,������ʱ,shape=[N, 1],NΪ��������,�����ʱ,shape=[N, C],CΪ�������
- labels:��ʵ��ǩ,shape=[N, 1]
���:
- ȷ��:shape=[1]
"""
# �ж��Ƕ����������Ƕ��������,preds.shape[1]=1ʱΪ����������,preds.shape[1]>1ʱΪ���������
if preds.shape[1] == 1:
# ������ʱ,�ж�ÿ������ֵ�Ƿ����0.5,������0.5ʱ,���Ϊ1,�������Ϊ0
# ʹ��'paddle.cast'��preds����������ת��Ϊfloat32����
preds = torch.tensor(preds>=0.5, dtype=torch.float32)
else:
# �����ʱ,ʹ��'paddle.argmax'�������Ԫ��������Ϊ���
preds = torch.argmax(preds,1, int32)
return torch.mean(torch.tensor(torch.eq(preds, labels), dtype=torch.float32))
# ����ģ�͵�Ԥ��ֵΪ[[0.],[1.],[1.],[0.]],��ʵ���Ϊ[[1.],[1.],[0.],[0.]],����ȷ��
preds = torch.tensor([[0.],[1.],[1.],[0.]])
labels = torch.tensor([[1.],[1.],[0.],[0.]])
print("accuracy is:", accuracy(preds, labels))
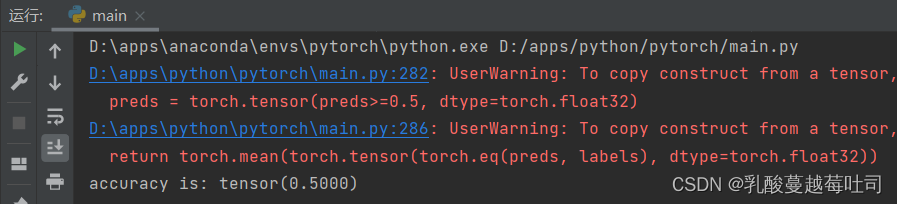
3.1.6 ����Runner��
����RunnerV1,���µ�RunnerV2����ѵ��������ʹ���ݶ��½������������Ż�,ģ��ѵ�������м�����ѵ��������֤���ϵ���ʧ������ָ�겢��ӡ,ѵ�������б�������ģ�͡�����ʵ������:
# ��RunnerV2���װ����ѵ������
class RunnerV2(object):
def __init__(self, model, optimizer, metric, loss_fn):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn
self.metric = metric
# ��¼ѵ�������е�����ָ��仯���
self.train_scores = []
self.dev_scores = []
# ��¼ѵ�������е���ʧ�����仯���
self.train_loss = []
self.dev_loss = []
def train(self, train_set, dev_set, **kwargs):
# ����ѵ������,���û�д���ֵ��Ĭ��Ϊ0
num_epochs = kwargs.get("num_epochs", 0)
# ����log��ӡƵ��,���û�д���ֵ��Ĭ��Ϊ100
log_epochs = kwargs.get("log_epochs", 100)
# ����ģ�ͱ���·��,���û�д���ֵ��Ĭ��Ϊ"best_model.pdparams"
save_path = kwargs.get("save_path", "best_model.pdparams")
# �ݶȴ�ӡ����,���û�д�����Ĭ��Ϊ"None"
print_grads = kwargs.get("print_grads", None)
# ��¼ȫ������ָ��
best_score = 0
# ����num_epochs��ѵ��
for epoch in range(num_epochs):
X, y = train_set
# ��ȡģ��Ԥ��
logits = self.model(X)
# ���㽻������ʧ
trn_loss = self.loss_fn(logits, y).item()
self.train_loss.append(trn_loss)
# ��������ָ��
trn_score = self.metric(logits, y).item()
self.train_scores.append(trn_score)
# ��������ݶ�
self.model.backward(y)
if print_grads is not None:
# ��ӡÿһ����ݶ�
print_grads(self.model)
# ����ģ�Ͳ���
self.optimizer.step()
dev_score, dev_loss = self.evaluate(dev_set)
# �����ǰָ��Ϊ����ָ��,�����ģ��
if dev_score > best_score:
self.save_model(save_path)
print(f"best accuracy performence has been updated: {best_score:.5f} --> {dev_score:.5f}")
best_score = dev_score
if epoch % log_epochs == 0:
print(f"[Train] epoch: {epoch}, loss: {trn_loss}, score: {trn_score}")
print(f"[Dev] epoch: {epoch}, loss: {dev_loss}, score: {dev_score}")
def evaluate(self, data_set):
X, y = data_set
# ����ģ�����
logits = self.model(X)
# ������ʧ����
loss = self.loss_fn(logits, y).item()
self.dev_loss.append(loss)
# ��������ָ��
score = self.metric(logits, y).item()
self.dev_scores.append(score)
return score, loss
def predict(self, X):
return self.model(X)
def save_model(self, save_path):
torch.save(self.model.params, save_path)
def load_model(self, model_path):
self.model.params = torch.load(model_path)
3.1.7 ģ��ѵ��
�������Logistic�ع�ģ�͵�ѵ��,ʹ�ý�������ʧ�������ݶ��½��������Ż���
ʹ��ѵ��������֤������ģ��ѵ��,��ѵ�� 500��epoch,ÿ��50��epoch��ӡ��ѵ�����ϵ�ָ�ꡣ
����ʵ������:
# �̶��������,����ÿ�����н��һ��
torch.seed()
# ������
input_dim = 2
# ѧϰ��
lr = 0.1
# ʵ����ģ��
model = model_LR(input_dim=input_dim)
# ָ���Ż���
optimizer = SimpleBatchGD(init_lr=lr, model=model)
# ָ����ʧ����
loss_fn = BinaryCrossEntropyLoss()
# ָ�����۷�ʽ
metric = accuracy
# ʵ����RunnerV2��,������ѵ������
runner = RunnerV2(model, optimizer, metric, loss_fn)
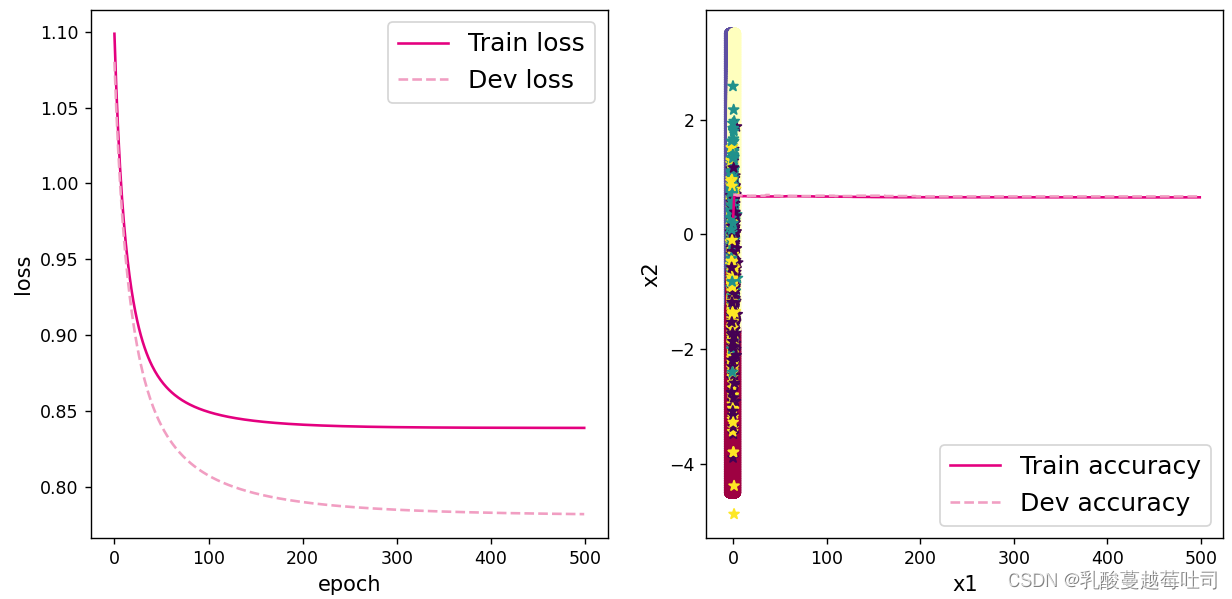
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=500, log_epochs=50, save_path="best_model.pdparams")
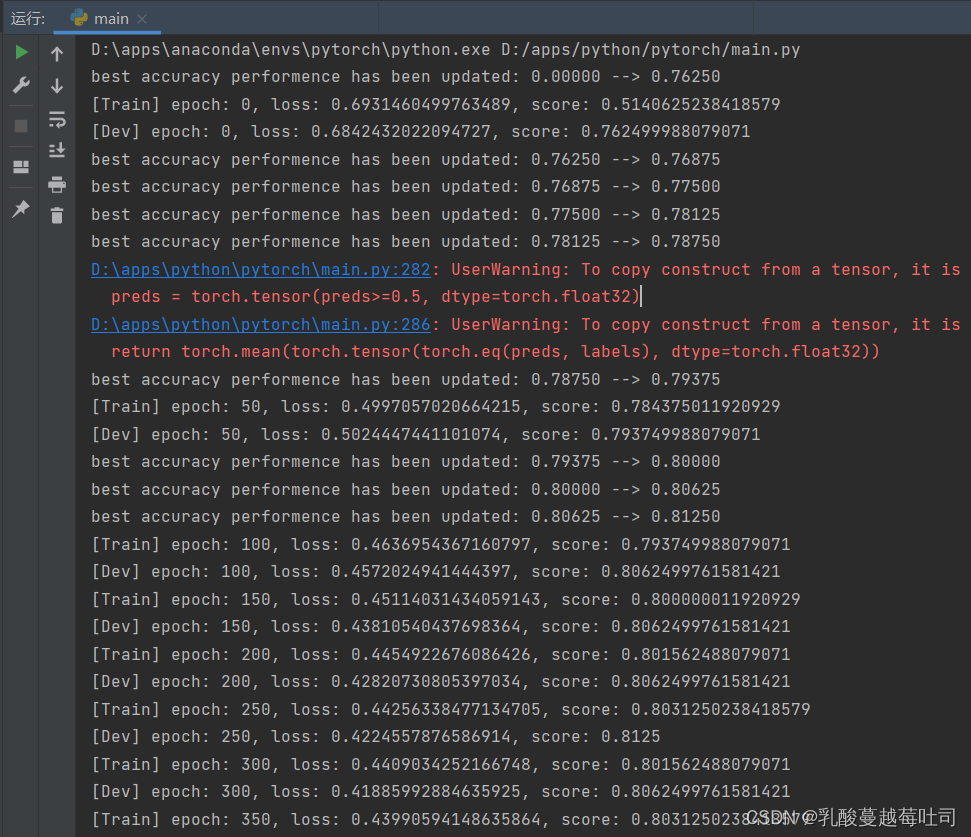
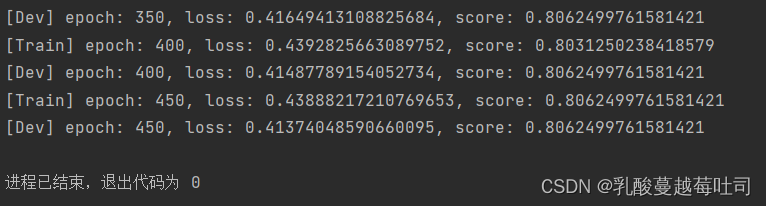
���ӻ��۲�ѵ��������֤����ȷ�ʺ���ʧ�ı仯�����
# ���ӻ��۲�ѵ��������֤����ָ��仯���
def plot(runner,fig_name):
plt.figure(figsize=(10,5))
plt.subplot(1,2,1)
epochs = [i for i in range(len(runner.train_scores))]
# ����ѵ����ʧ�仯����
plt.plot(epochs, runner.train_loss, color='#e4007f', label="Train loss")
# ����������ʧ�仯����
plt.plot(epochs, runner.dev_loss, color='#f19ec2', linestyle='--', label="Dev loss")
# �����������ͼ��
plt.ylabel("loss", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='upper right', fontsize='x-large')
plt.subplot(1,2,2)
# ����ѵ��ȷ�ʱ仯����
plt.plot(epochs, runner.train_scores, color='#e4007f', label="Train accuracy")
# ��������ȷ�ʱ仯����
plt.plot(epochs, runner.dev_scores, color='#f19ec2', linestyle='--', label="Dev accuracy")
# �����������ͼ��
plt.ylabel("score", fontsize='large')
plt.xlabel("epoch", fontsize='large')
plt.legend(loc='lower right', fontsize='x-large')
plt.tight_layout()
plt.savefig(fig_name)
plt.show()
plot(runner,fig_name='linear-acc.pdf')
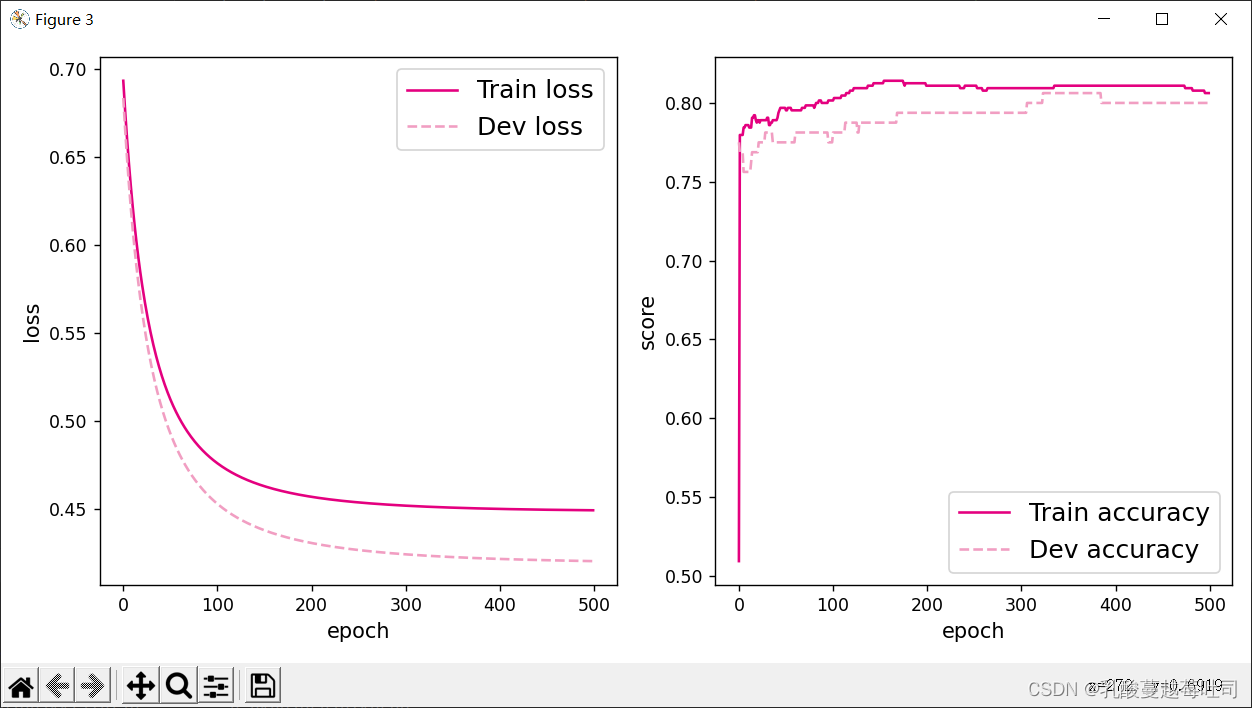
�����������Կ���,��ѵ��������֤����,loss�õ�������,ͬʱȷ��ָ�궼�ﵽ�˽ϸߵ�ˮƽ,ѵ���Ƚϳ�֡�
3.1.8 ģ������
ʹ�ò��Լ���ѵ����ɺ������ģ�ͽ�������,�۲�ģ���ڲ��Լ��ϵ�ȷ�ʺ�loss���ݡ�����ʵ������:
score, loss = runner.evaluate([X_test, y_test])
print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))

���ӻ��۲���ϵľ��߽߱� Xw+b=0��
def decision_boundary(w, b, x1):
w1, w2 = w
x2 = (- w1 * x1 - b) / w2
return x2
plt.figure(figsize=(5,5))
# ����ԭʼ����
plt.scatter(X[:, 0].tolist(), X[:, 1].tolist(), marker='*', c=y.tolist())
w = model.params['w']
b = model.params['b']
x1 = torch.linspace(-2, 3, 1000)
x2 = decision_boundary(w, b, x1)
# ���ƾ��߽߱�
plt.plot(x1.tolist(), x2.tolist(), color="red")
plt.show()
3.2 ����Softmax�ع�Ķ��������
Logistic�ع������Ч�ؽ������������,���ڷ���������,����һ����������,�������C����2 �ķ������⡣Softmax�ع����Logistic�ع��ڶ���������ϵ��ƹ㡣
ʹ��Softmax�ع�ģ�Ͷ�һ�������ݼ����ж����ʵ�顣
3.2.1 ���ݼ�����
�������ȹ���һ���Ķ��������,������ѵ��������֤���Ͳ��Լ���
���������������3����ͬ�Ĵ�,ÿ���ض�һ��������Dzɼ�1000������,ÿ����������2��������
���ݼ��Ĺ�������make_multi�Ĵ���ʵ������:
import numpy as np
import torch
def make_multiclass_classification(n_samples=100, n_features=2, n_classes=3, shuffle=True, noise=0.1):
"""
���ɴ������Ķ��������
����:
- n_samples:��������С,��������Ϊint
- n_features:��������,��������Ϊint
- shuffle:�Ƿ��������,��������Ϊbool
- noise:�Զ��ij̶���������,��������ΪNone��float,noiseΪNoneʱ��ʾ����������
���:
- X:��������,shape=[n_samples,2]
- y:��ǩ����, shape=[n_samples,1]
"""
# ����ÿ��������������
n_samples_per_class = [int(n_samples / n_classes) for k in range(n_classes)]
for i in range(n_samples - sum(n_samples_per_class)):
n_samples_per_class[i % n_classes] += 1
# �������ͱ�ǩ��ʼ��Ϊ0
X = torch.zeros([n_samples, n_features])
y = torch.zeros([n_samples], dtype='int32')
# �������3�����������������
centroids = torch.randperm(2 ** n_features)[:n_classes]
centroids_bin = np.unpackbits(centroids.numpy().astype('uint8')).reshape((-1, 8))[:, -n_features:]
centroids = torch.to_tensor(centroids_bin, dtype='float32')
# ���ƴ����ĵķ���̶�
centroids = 1.5 * centroids - 1
# �����������ֵ
X[:, :n_features] = torch.randn(shape=[n_samples, n_features])
stop = 0
# ��ÿ���������ֵ�����ڴ����ĸ���
for k, centroid in enumerate(centroids):
start, stop = stop, stop + n_samples_per_class[k]
# ָ����ǩֵ
y[start:stop] = k % n_classes
X_k = X[start:stop, :n_features]
# ����ÿ���������ֵ�ķ�ɢ�̶�
A = 2 * torch.rand(shape=[n_features, n_features]) - 1
X_k[...] = torch.matmul(X_k, A)
X_k += centroid
X[start:stop, :n_features] = X_k
# ���noise��ΪNone,���������������
if noise > 0.0:
# ����noise��Ĥ,����ָ������Щ������������
noise_mask = torch.rand([n_samples]) < noise
for i in range(len(noise_mask)):
if noise_mask[i]:
# ���������������������ǩֵ
y[i] = torch.randint(n_classes, shape=[1]).astype('int32')
# ���shuffleΪTrue,���������ݴ���
if shuffle:
idx = torch.randperm(X.shape[0])
X = X[idx]
y = y[idx]
return X, y
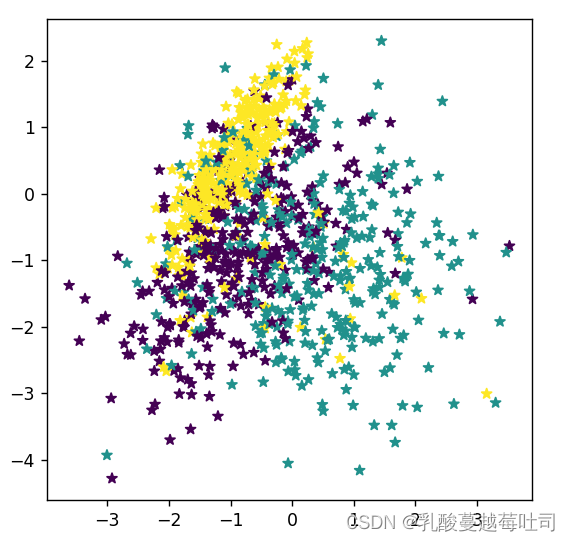
����ɼ�1000������,�����п��ӻ���
import matplotlib.pyplot as plt
# �̶��������,����ÿ�����н��һ��
torch.seed()
# ����1000������
n_samples = 1000
X, y = make_multiclass_classification(n_samples, n_features=2, n_classes=3, noise=0.2)
# ���ӻ����������ݼ�,��ͬ��ɫ������ͬ���
plt.figure(figsize=(5,5))
plt.scatter(x=X[:, 0].tolist(), y=X[:, 1].tolist(), marker='*', c=y.tolist())
plt.savefig('linear-dataset-vis2.pdf')
plt.show()
��ʵ�����ݲ�ֳ�ѵ��������֤���Ͳ��Լ�������ѵ����640������֤��160�������Լ�200����
num_train = 640
num_dev = 160
num_test = 200
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
# ��ӡX_train��y_train��ά��
print("X_train shape: ", X_train.shape, "y_train shape: ", y_train.shape)

����,���Ǿ������Multi1000���ݼ��Ĺ�����
# ��ӡǰ5�����ݵı�ǩ
print(y_train[:5])
3.2.2 ģ����
��Softmax�ع���,��������Ԥ��ķ�ʽ��Ԥ����������ÿ�������������ʡ���Logistic �ع鲻ͬ����,Softmax�ع�����ֵ�������������C,��ÿ�����ĸ���ֵ��ͨ��Softmax����������⡣
3.2.2.1 Softmax����
Softmax�������Խ��������ӳ��Ϊһ�����ʷֲ�������һ��Kά����,x=[x1,?,xK],Softmax�ļ��㹫ʽΪ
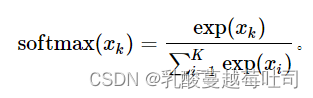
��Softmax�����ļ��������,Ҫע�������������������⡣����Softmax ���������е�xk������ͬ��С����ֵa,������,���е������Ӧ��Ϊ1k������Ҫ�������������������:
aΪһ���dz���ĸ���,��ʱexp(a) �ᷢ���������������ڽ�����ֵ����ʱ,����ֵ��С,�ᱻ��������Ϊ0����ʱ,Softmax�����ķ�ĸ���Ϊ0,���¼����������;
aΪһ���dz��������,��ʱ�ᵼ��exp(a)�������������,���¼���������⡣
Ϊ�˽��������������������,�ڼ���Softmax����ʱ,����ʹ��xk?max(x)����xk�� ��ʱ,ͨ����ȥ���ֵ,xk���Ϊ0,�����������������;ͬʱ,��ĸ�����ٻ����һ��ֵΪ1����,�Ӷ�Ҳ����������������⡣
Softmax�����Ĵ���ʵ������:
def softmax(X):
"""
����:
- X:shape=[N, C],N��������,C������
"""
x_max = torch.max(X, dim=1, keepdim=True)[0] #N, 1
x_exp = torch.exp(X - x_max)
partition = torch.sum(x_exp, 1, keepdim=True) #N, 1
return x_exp / partition
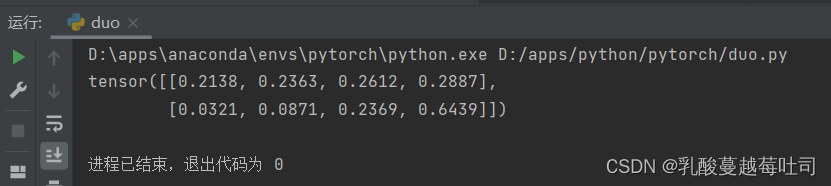
# �۲�softmax�ļ��㷽ʽ
X = torch.tensor([[0.1, 0.2, 0.3, 0.4],[1,2,3,4]])
predict = softmax(X)
print(predict)
3.2.2.2 Softmax�ع�����
��Softmax�ع���,����ǩy��{1,2,��,C}������һ������x,ʹ��Softmax�ع�Ԥ����������c����������Ϊ
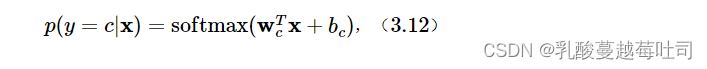
����wc�ǵ� c ���Ȩ������,bc�ǵ� c ���ƫ�á�
Softmax�ع�ģ����ʵ�������Ժ�����Softmax��������ϡ�
��N��������Ϊһ����г�����Ԥ�⡣
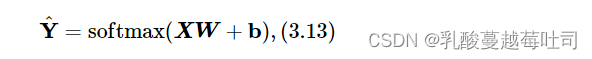
����X��RN��DΪN����������������,W=[w1,����,wC]ΪC�����Ȩ��������ɵľ���,Y^��RCΪ��������Ԥ������������ɵľ���
���Ǹ��ݹ�ʽ(3.13)ʵ��Softmax�ع�����,����ʵ������:
class model_SR(op):
def __init__(self, input_dim, output_dim):
super(model_SR, self).__init__()
self.params = {}
# �����Բ��Ȩ�ز���ȫ����ʼ��Ϊ0
self.params['W'] = torch.zeros([input_dim, output_dim])
# self.params['W'] = paddle.normal(mean=0, std=0.01, shape=[input_dim, output_dim])
# �����Բ��ƫ�ò�����ʼ��Ϊ0
self.params['b'] = torch.zeros([output_dim])
self.outputs = None
def __call__(self, inputs):
return self.forward(inputs)
def forward(self, inputs):
"""
����:
- inputs: shape=[N,D], N����������,D��������
���:
- outputs:Ԥ��ֵ,shape=[N,C],C�������
"""
# ���Լ���
score = torch.matmul(inputs, self.params['W']) + self.params['b']
# Softmax ����
self.outputs = softmax(score)
return self.outputs
# �������1������Ϊ4������
inputs = torch.randn([1,4])
print('Input is:', inputs)
# ʵ����ģ��,���������볤��Ϊ4,��������Ϊ3
model = model_SR(input_dim=4, output_dim=3)
outputs = model(inputs)
print('Output is:', outputs)

�����������Կ���,����ȫ0��ʼ����,����ÿ�������������ʾ�Ϊ1C��������Ϊ,��������ֵ�Ĵ�СΪ����,���Ժ���f(x;W,b)�����ֵ��Ϊ0����ʱ,�پ���Softmax�����Ĵ���,ÿ�������������ʺ�ȡ�
Logistic�����Ǽ������Softmax�����Ǽ����ô?̸̸��Ŀ�����
Softmax�����ڶ����������ļ����,�ڶ������������,�����������ǩ����Ҫ���Ա��ϵ�����ڳ���Ϊ K ������ʵ����,Softmax ���Խ���ѹ��Ϊ����Ϊ K,ֵ��(0,1)��Χ��,����������Ԫ�ص��ܺ�Ϊ 1 ��ʵ������
Softmax �������� max ������ͬ:max ������������ֵ,�� Softmax ȷ����С��ֵ���н�С�ĸ���,���Ҳ���ֱ�Ӷ��������ǿ�����Ϊ���� argmax �����ĸ��ʰ汾��soft���汾��
Softmax �����ķ�ĸ�����ԭʼ���ֵ����������,����ζ�� Softmax ������õĸ��ָ��ʱ˴���ء�
3.2.3 ��ʧ����
Softmax�ع�ͬ��ʹ�ý�������ʧ��Ϊ��ʧ����,��ʹ���ݶ��½����Բ��������Ż���ͨ��ʹ��Cά��one-hot��������y��{0,1}C����ʾ����������е�����ǩ���������c,��������ʾΪ:
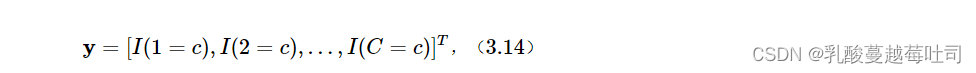
����I(?)��ָʾ����,�������ڵ�����Ϊ���桱,I(?)=1;����,I(?)=0��
������N��ѵ��������ѵ����{(x(n),y(n))}Nn=1,��y^(n)=softmax(WTx(n)+b)Ϊ����x(n)��ÿ�����ĺ�����ʡ����������Ľ�������ʧ��������Ϊ:

�۲���ʽ,y(n)c��cΪ��ʵ���ʱΪ1,���Ϊ0��Ҳ����˵,��������ʧֻ������ȷ����Ԥ�����,���,��ʽ�ֿ����Ż�Ϊ:

����y(n)�ǵ�n�������ı�ǩ��
���,���ཻ������ʧ�����Ĵ���ʵ������:
class MultiCrossEntropyLoss(op):
def __init__(self):
self.predicts = None
self.labels = None
self.num = None
def __call__(self, predicts, labels):
return self.forward(predicts, labels)
def forward(self, predicts, labels):
"""
����:
- predicts:Ԥ��ֵ,shape=[N, 1],NΪ��������
- labels:��ʵ��ǩ,shape=[N, 1]
���:
- ��ʧֵ:shape=[1]
"""
self.predicts = predicts
self.labels = labels
self.num = self.predicts.shape[0]
loss = 0
for i in range(0, self.num):
index = self.labels[i]
loss -= torch.log(self.predicts[i][index])
return loss / self.num
# ����һ��
# ������ʵ��ǩΪ��1��
labels = torch.tensor([0])
# ������պ���
mce_loss = MultiCrossEntropyLoss()
print(mce_loss(outputs, labels))

3.2.4 ģ���Ż�
ʹ���ݶ��½������в���ѧϰ��
3.2.4.1 �ݶȼ���
������պ���R(W,b)���ڲ���W��b��ƫ��������Softmax�ع���,���㷽��Ϊ:
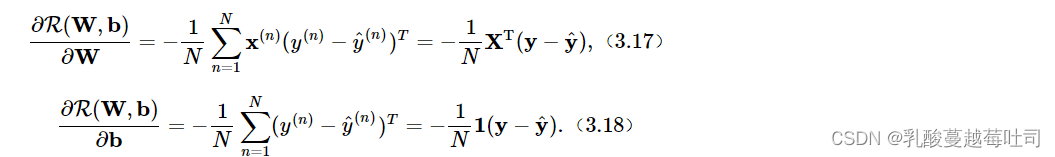
����X��RN��DΪN��������ɵľ���,y��RNΪN��������ǩ��ɵ�����,y^��RNΪN��������Ԥ���ǩ��ɵ�����,1ΪNά��ȫ1������
���������㷽��������ģ�͵�backward������,����ʵ������:
class model_SR(op):
def __init__(self, input_dim, output_dim):
super(model_SR, self).__init__()
self.params = {}
# �����Բ��Ȩ�ز���ȫ����ʼ��Ϊ0
self.params['W'] = torch.zeros([input_dim, output_dim])
# self.params['W'] = paddle.normal(mean=0, std=0.01, shape=[input_dim, output_dim])
# �����Բ��ƫ�ò�����ʼ��Ϊ0
self.params['b'] = torch.zeros(output_dim)
# ��Ų������ݶ�
self.grads = {}
self.X = None
self.outputs = None
self.output_dim = output_dim
def __call__(self, inputs):
return self.forward(inputs)
def forward(self, inputs):
self.X = inputs
# ���Լ���
score = torch.matmul(self.X, self.params['W']) + self.params['b']
# Softmax ����
self.outputs = softmax(score)
return self.outputs
def backward(self, labels):
"""
����:
- labels:��ʵ��ǩ,shape=[N, 1],����NΪ��������
"""
# ����ƫ����
N =labels.shape[0]
labels = torch.nn.functional.one_hot(labels, self.output_dim)
self.grads['W'] = -1 / N * torch.matmul(self.X.t(), (labels-self.outputs))
self.grads['b'] = -1 / N * torch.matmul(torch.ones(shape=[N]), (labels-self.outputs))
3.2.4.2 ��������
�ڼ���������ݶ�֮��,����ʹ��3.1.4.2��ʵ�ֵ��ݶ��½������в������¡�
3.2.5 ģ��ѵ��
ʵ����RunnerV2��,������ѵ�����á�ʹ��ѵ��������֤������ģ��ѵ��,��ѵ��500��epoch��ÿ��50��epoch��ӡѵ�����ϵ�ָ�ꡣ����ʵ������:
# �̶��������,����ÿ�����н��һ��
torch.seed()
# ������
input_dim = 2
# �����
output_dim = 3
# ѧϰ��
lr = 0.1
# ʵ����ģ��
model = model_SR(input_dim=input_dim, output_dim=output_dim)
# ָ���Ż���
optimizer = SimpleBatchGD(init_lr=lr, model=model)
# ָ����ʧ����
loss_fn = MultiCrossEntropyLoss()
# ָ�����۷�ʽ
metric = accuracy
# ʵ����RunnerV2��
runner = RunnerV2(model, optimizer, metric, loss_fn)
# ģ��ѵ��
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=500, log_eopchs=50, eval_epochs=1,
save_path="best_model.pdparams")
# ���ӻ��۲�ѵ��������֤����ȷ�ʱ仯���
plot(runner, fig_name='linear-acc2.pdf')
plt.show()
һ��ʼ���в���������������ͼ,����һ�¼���һ��plt.show()�ͽ���ˡ�
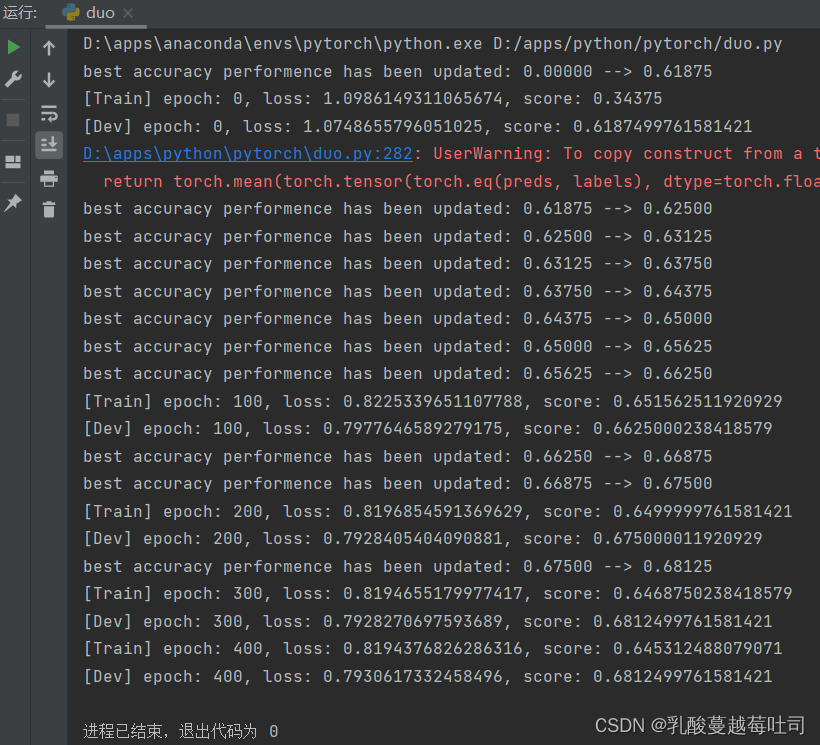
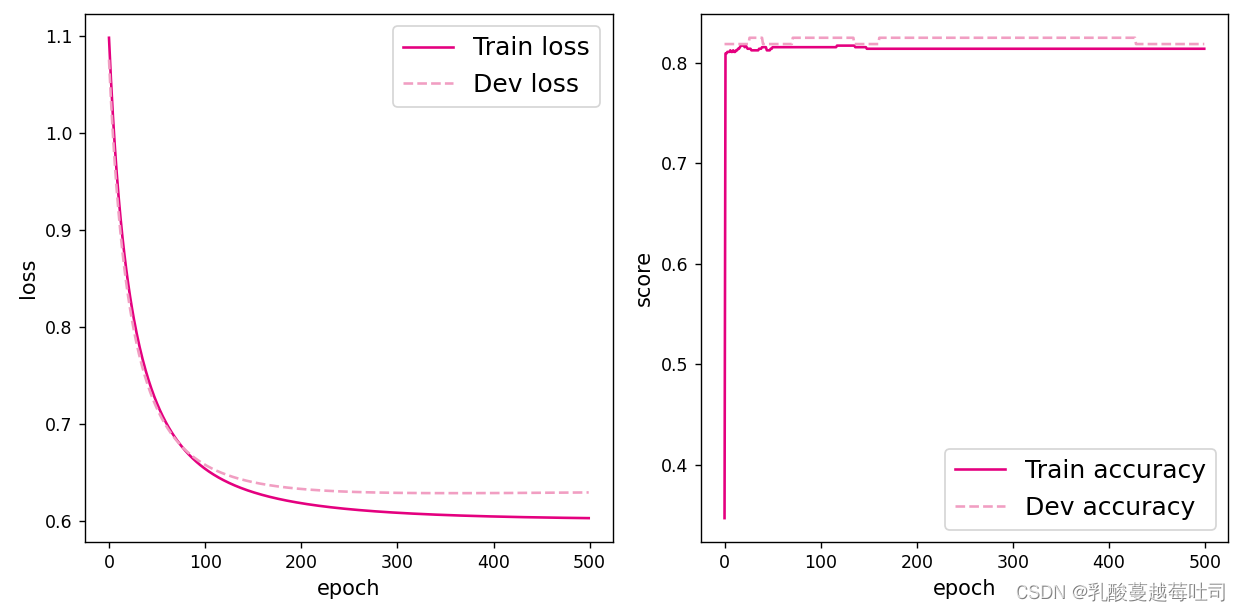
3.2.6 ģ������
ʹ�ò��Լ���ѵ����ɺ������ģ�ͽ�������,�۲�ģ���ڲ��Լ��ϵ�ȷ�ʡ�����ʵ������:
score, loss = runner.evaluate([X_test, y_test])
print("[Test] score/loss: {:.4f}/{:.4f}".format(score, loss))
lr=0.1,epochs=500
 lr=0.2,epochs=1000
lr=0.2,epochs=1000
 lr����Ϊ0.2�Ժ�,score��loss���½�,˵��ģ�ʹﵽ��Ƿ��ϡ�
lr����Ϊ0.2�Ժ�,score��loss���½�,˵��ģ�ʹﵽ��Ƿ��ϡ�
lr=0.001,epochs=1000
 lr����Ϊ0.001�Ժ�,score����,lossȴ�������,˵��ģ�ʹﵽ�˹����״̬��
lr����Ϊ0.001�Ժ�,score����,lossȴ�������,˵��ģ�ʹﵽ�˹����״̬��
���ӻ��۲���ֽ����
# ��������40000�����ݵ�
x1, x2 = torch.meshgrid(torch.linspace(-3.5, 2, 200), torch.linspace(-4.5, 3.5, 200))
x = torch.stack([torch.flatten(x1), torch.flatten(x2)], axis=1)
# Ԥ���Ӧ���
y = runner.predict(x)
y = torch.argmax(y, axis=1)
# �����������
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(x[:,0].tolist(), x[:,1].tolist(), c=y.tolist(), cmap=plt.cm.Spectral)
torch.seed()
n_samples = 1000
X, y = make_multiclass_classification(n_samples=n_samples, n_features=2, n_classes=3, noise=0.2)
plt.scatter(X[:, 0].tolist(), X[:, 1].tolist(), marker='*', c=y.tolist())
plt.show()
3.3 ʵ��:����Softmax�ع�����β����������
3.3.1 ���ݴ���
3.3.1.1 ���ݼ�����
Iris���ݼ�,Ҳ��Ϊ�β�����ݼ�,������3���β�����(Setosa��Versicolour��Virginica),ÿ�������50������,����150������������ÿ�������а�����4������:����ȡ�������ȡ����곤���Լ��������,��ʵ��ͨ���β����4���������жϸ����������
3.3.1.2 ������ϴ
ȱʧֵ����
�����ݼ��е�ȱʧֵ���쳣ֵ��������з����ʹ���,��֤���ݿ��Ա�ģ��������ȡ������ʵ������:
from sklearn.datasets import load_iris
import pandas
import numpy as np
iris_features = np.array(load_iris().data, dtype=np.float32)
iris_labels = np.array(load_iris().target, dtype=np.int32)
print(pandas.isna(iris_features).sum())
print(pandas.isna(iris_labels).sum())
����������,�β�����ݼ��в�����ȱʧֵ�������
�쳣ֵ����
ͨ������ͼֱ�۵���ʾ���ݷֲ�,���۲������е��쳣ֵ��
import matplotlib.pyplot as plt #���ӻ�����
# ����ͼ�鿴�쳣ֵ�ֲ�
def boxplot(features):
feature_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
# ����������ͼƬ
plt.figure(figsize=(5, 5), dpi=200)
# ��ͼ����
plt.subplots_adjust(wspace=0.6)
# ÿ��������һ������ͼ
for i in range(4):
plt.subplot(2, 2, i+1)
# ������ͼ
plt.boxplot(features[:, i],
showmeans=True,
whiskerprops={"color":"#E20079", "linewidth":0.4, 'linestyle':"--"},
flierprops={"markersize":0.4},
meanprops={"markersize":1})
# ͼ��
plt.title(feature_names[i], fontdict={"size":5}, pad=2)
# y����̶�
plt.yticks(fontsize=4, rotation=90)
plt.tick_params(pad=0.5)
# x����̶�
plt.xticks([])
plt.savefig('ml-vis.pdf')
plt.show()
boxplot(iris_features)
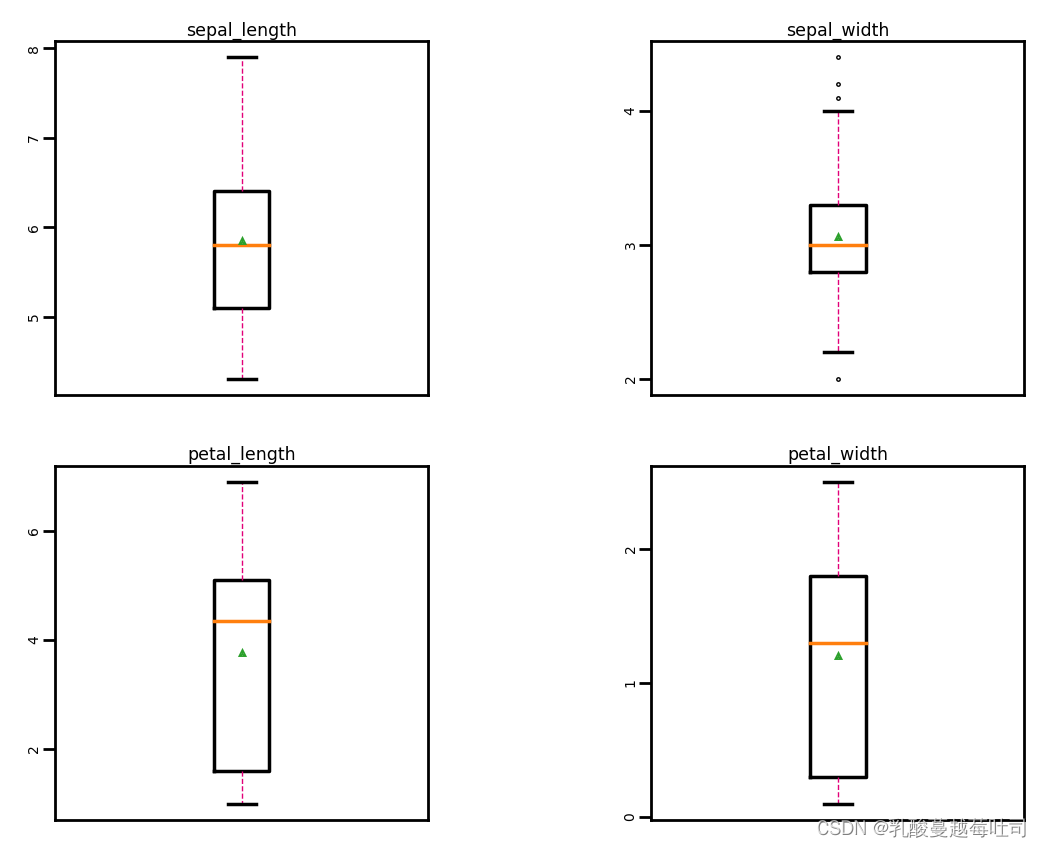
����������,�����л����������쳣ֵ,���Բ���Ҫ�����쳣ֵ������
3.3.1.3 ���ݶ�ȡ
��ʵ���н����ݼ�����Ϊ����������:
ѵ����:����ȷ��ģ�Ͳ���;
��֤��:��ѵ������������������,����ʹ����ǰֹͣ����ѡ������ģ��;
���Լ�:���ڹ���Ӧ��Ч��(û����ģ����Ӧ�ù�������,������ģ������ʵ����Ӧ�õ�Ч��)��
�ڱ�ʵ����,��80%����������ģ��ѵ��,10%����������ģ����֤,10%����������ģ�Ͳ��ԡ�����ʵ������:
# �������ݼ�
def load_data(shuffle=True):
"""
����������
����:
- shuffle:�Ƿ��������,��������Ϊbool
���:
- X:��������,shape=[150,4]
- y:��ǩ����, shape=[150]
"""
# ����ԭʼ����
X = np.array(load_iris().data, dtype=np.float32)
y = np.array(load_iris().target, dtype=np.int32)
X = torch.tensor(X)
y = torch.tensor(y)
# ���ݹ�һ��
X_min = torch.min(X, 0)[0]
X_max = torch.max(X, 0)[0]
X = (X-X_min) / (X_max-X_min)
# ���shuffleΪTrue,�����������
if shuffle:
idx = torch.randperm(X.shape[0])
X = X[idx]
y = y[idx]
return X, y
# �̶��������
torch.seed()
num_train = 120
num_dev = 15
num_test = 15
X, y = load_data(shuffle=True)
print("X shape: ", X.shape, "y shape: ", y.shape)
X_train, y_train = X[:num_train], y[:num_train]
X_dev, y_dev = X[num_train:num_train + num_dev], y[num_train:num_train + num_dev]
X_test, y_test = X[num_train + num_dev:], y[num_train + num_dev:]
# ��ӡX_train��y_train��ά��
print("X_train shape: ", X_train.shape, "y_train shape: ", y_train.shape)

# ��ӡǰ5�����ݵı�ǩ
print(y_train[:5])

3.3.2 ģ����
ʹ��Softmax�ع�ģ�ͽ����β������ʵ��,��ģ�͵�����ά�ȶ���Ϊ4,���ά�ȶ���Ϊ3������ʵ������:
# ������
input_dim = 4
# �����
output_dim = 3
# ʵ����ģ��
model = model_SR(input_dim=input_dim, output_dim=output_dim)
3.3.3 ģ��ѵ��
ʵ����RunnerV2��,ʹ��ѵ��������֤������ģ��ѵ��,��ѵ��80��epoch,����ÿ��10��epoch��ӡѵ�����ϵ�ָ��,���ұ���ȷ����ߵ�ģ����Ϊ���ģ�͡�����ʵ������:
# ѧϰ��
lr = 0.2
# �ݶ��½���
optimizer = SimpleBatchGD(init_lr=lr, model=model)
# ��������ʧ
loss_fn = MultiCrossEntropyLoss()
# ȷ��
metric = accuracy
# ʵ����RunnerV2
runner = RunnerV2(model, optimizer, metric, loss_fn)
# ����ѵ��
runner.train([X_train, y_train], [X_dev, y_dev], num_epochs=200, log_epochs=10, save_path="best_model.pdparams")
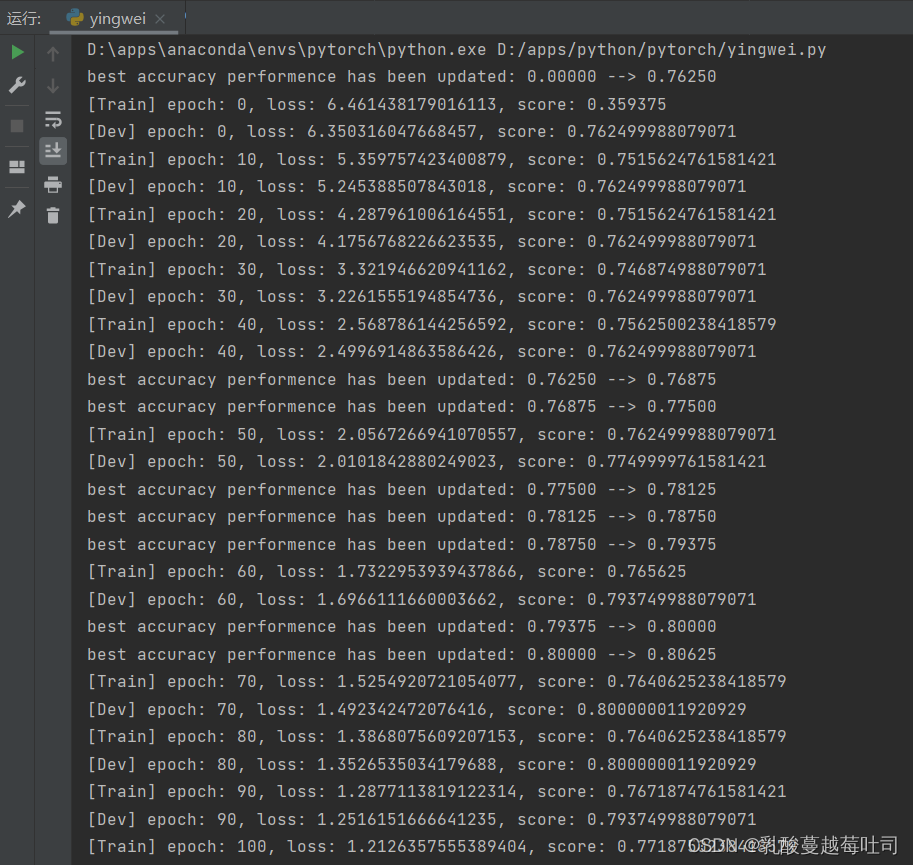
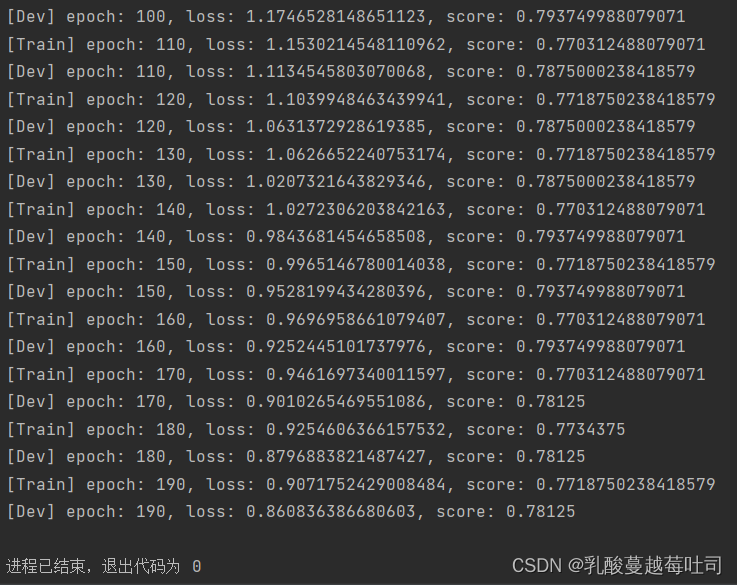
���ӻ��۲�ѵ��������֤����ȷ�ʱ仯�����
plot(runner,fig_name='linear-acc3.pdf')
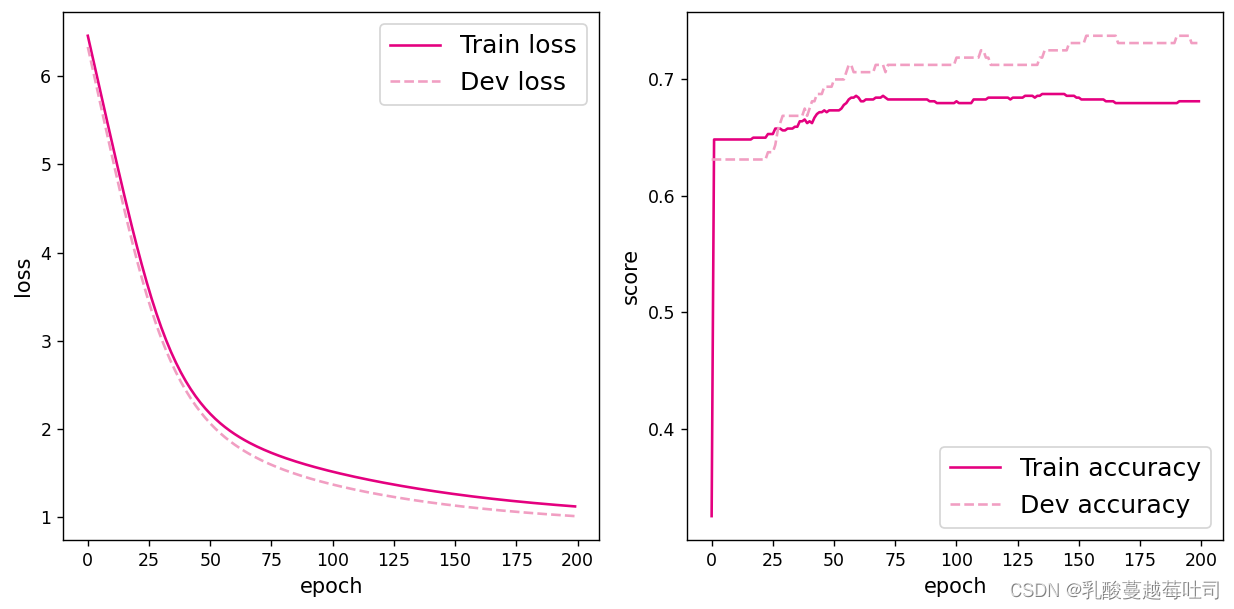
3.3.4 ģ������
ʹ�ò������ݶ���ѵ�������б�������ģ�ͽ�������,�۲�ģ���ڲ��Լ��ϵ�ȷ�����������ʵ������:
# ��������ģ��
runner.load_model('best_model.pdparams')
# ģ������
score, loss = runner.evaluate([X_test, y_test])

3.3.5 ģ��Ԥ��
ʹ�ñ���õ�ģ��,�Բ��Լ��е����ݽ���ģ��Ԥ��,��ȡ��1�����ݹ۲�ģ��Ч��������ʵ������:
# Ԥ����Լ�����
logits = runner.predict(X_test)
# �۲�����һ��������Ԥ����
pred = torch.argmax(logits[0]).numpy()
# ��ȡ�����������������
label = y_test[0].numpy()
# �����ʵ�����Ԥ�����
print("The true category is {} and the predicted category is {}".format(label, pred))

3.5 ʵ����չ
Ϊ�˼���Ի���ѧϰģ�͵�����,���Լ������������ʵ��:
���Ե���ѧϰ�ʺ�ѵ�������ȳ�����,�۲��Ƿ��ܹ��õ����ߵľ���;
��һ��,�Ȱ�ѧϰ�ʵ���Ϊ0.0001,ѵ����������Ϊ200

�ڶ���ѧϰ��0.18,ѵ������300

������ѧϰ��0.22,ѵ������250
 ע:������ģ��Ԥ�������,��ѧϰ�ʵ�С��������,���Է���score����,����loss��������,˵����ʱģ�ʹﵽ�˹����״̬������ѧϰ�����õĹ���С,��ʹ��ģ�����,����ѵ��������������,�ڲ��Լ��������½���
ע:������ģ��Ԥ�������,��ѧϰ�ʵ�С��������,���Է���score����,����loss��������,˵����ʱģ�ʹﵽ�˹����״̬������ѧϰ�����õĹ���С,��ʹ��ģ�����,����ѵ��������������,�ڲ��Լ��������½���
�ܽ�:�������˽��˼�������ڵı�Ҫ�ԡ�Logistic�ع������Ч�ؽ������������,Softmax�ع����Logistic�ع��ڶ���������ϵ��ƹ㡣����һЩ��ʽ���Ű�,��ǰ��һЩ��ʽ�����˸�ϰѵ������������һ�µ���ѧϰ�ʡ�ѵ��������Щ������ȷ�ʺ���ʧ��Ӱ��,