一、阅读:关于视觉识别领域发展的个人观点
1、CV和NLP的三大差异和挑战
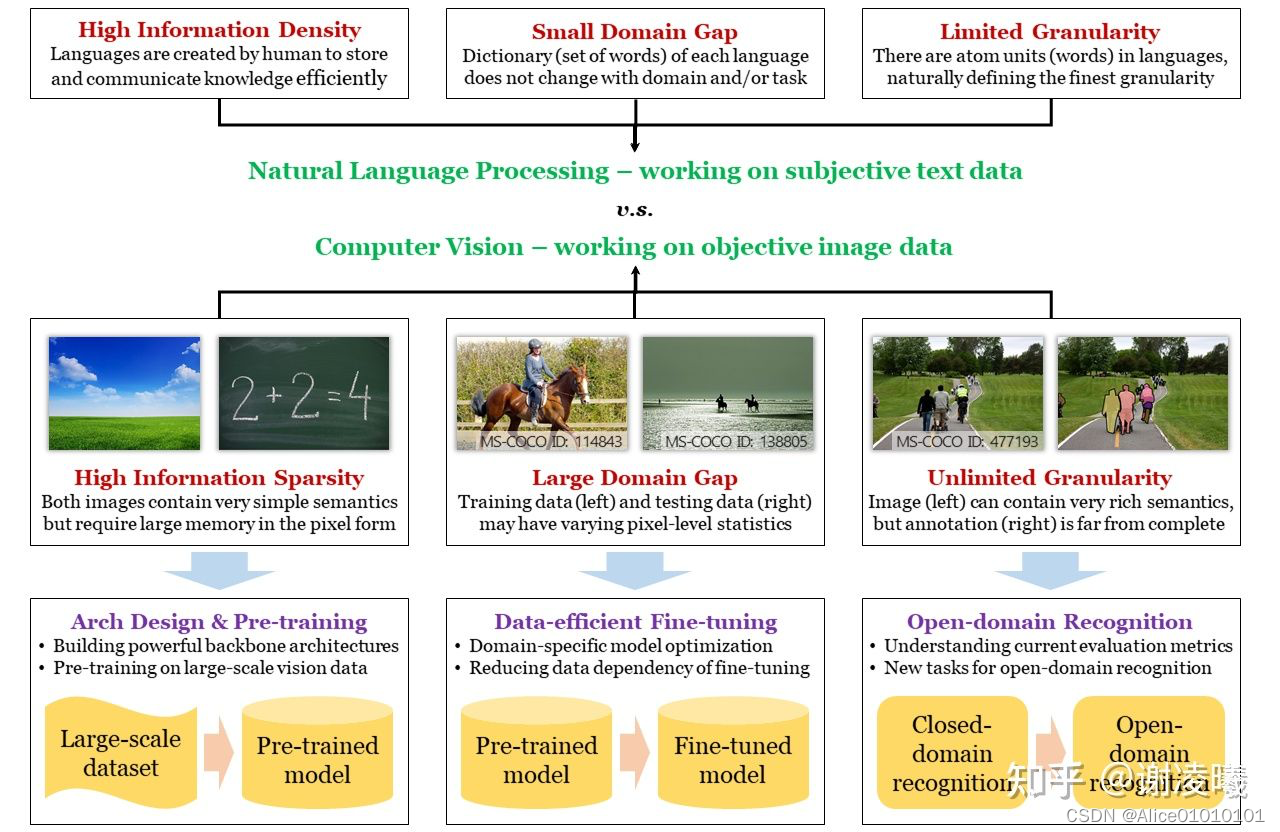
??????????????CV和NLP的差异、CV三大挑战及应对方法
- 语义稀疏性:解决方案为构建高效计算模型(神经网络)和视觉预训练。此处的主要逻辑在于,想要提升数据的信息密度,就必须假设数据的非均匀分布(信息论)并对其建模(即学习数据的先验分布)。目前,最为高效的建模方式有两类,一类是通过神经网络架构设计,来捕捉数据无关的先验分布(例如卷积模块对应于图像数据的局部性先验、transformer模块对应于图像数据的注意力先验);一类是通过在大规模数据上的预训练,来捕捉数据相关的先验分布。这两个研究方向,也是视觉识别领域最为基础、受到关注最多的研究方向。
- 域间差异性:解决方案为数据高效的微调算法。根据以上分析,网络体量越大、预训练数据集体量越大,计算模型中存储的先验就越强。然而,当预训练域和目标域的数据分布具有较大差异时,这种强先验反而会带来坏处,因为信息论告诉我们:提升某些部分(预训练域)的信息密度,就一定会降低其他部分(预训练域没有包含的部分,即预训练过程中认为不重要的部分)的信息密度。现实中,目标域很可能部分或者全部落在没有包含的部分,导致直接迁移预训练模型的效果很差(即过拟合)。此时,就需要通过在目标域进行微调来适应新的数据分布。考虑到目标域的数据体量往往远小于预训练域,因而数据高效是必不可少的假设。此外,从实用的角度看,模型必须能够适应随时变化的域,因而终身学习是必须实现的目标。
- 无限粒度性:解决方案为开放域识别算法。无限粒度性包含开放域特性,是更高的追求目标。这个方向的研究还很初步,特别是业界还没有能被普遍接受的开放域识别数据集和评价指标。这里最本质的问题之一,是如何向视觉识别中引入开放域能力。可喜的是,随着跨模态预训练方法的涌现(特别是2021年的CLIP),自然语言越来越接近成为开放域识别的牵引器,我相信这会是未来2-3年的主流方向。然而,我并不赞成在追求开放域识别的过程中,涌现出的各种zero-shot识别任务。我认为zero-shot本身是一个伪命题,世界上并不存在也不需要zero-shot识别方法。现有的zero-shot任务,都是使用不同方法,将信息泄露给算法,而泄露方式的千差万别,导致不同方法之间难以进行公平对比。在这个方向上,我提出了一种被称为按需视觉识别的方法,以进一步揭示、探索视觉识别的无限粒度性。
2、各个研究方向
- 如果一定要在卷积和transformer之间做取舍,那么transformer的潜力更大,主要因为它能够统一不同的数据模态,尤其是文本和图像这两个最常见也最重要的模态。
- 可解释性是一个很重要的研究方向,但是我个人对于深度神经网络的可解释性持悲观态度。NLP的成功,也不是建立在可解释性上,而是建立在过拟合大规模语料库上。对于真正的AI来说,这可能不是太好的信号。
- 从实际应用上看,应该将不同的预训练任务结合起来。也就是说,应当收集混合数据集,其中包含少量有标签数据(甚至是检测、分割等更强的标签)、中量图文配对数据、大量无任何标签的图像数据,并且在这样的混合数据集上设计预训练方法。
- 从CV领域看,无监督预训练是最能体现视觉本质的研究方向。即使跨模态预训练给整个方向带来了很大的冲击,我依然认为无监督预训练非常重要,必须坚持下去。需要指出,视觉预训练的思路很大程度上受到了自然语言预训练的影响,但是两者性质不同,因而不能一概而论。尤其是,自然语言本身是人类创造出来的数据,其中每个单词、每个字符都是人类写下来的,天然带有语义,因此从严格意义上说,NLP的预训练任务不能被视为真正的无监督预训练,至多算是弱监督的预训练。但是视觉不同,图像信号是客观存在、未经人类处理的原始数据,在其中的无监督预训练任务一定更难。总之,即使跨模态预训练能够在工程上推进视觉算法,使其达到更好的识别效果,视觉的本质问题还是要靠视觉本身来解决。
- 当前,纯视觉无监督预训练的本质在于从退化中学习。这里的退化,指的是从图像信号中去除某些已经存在的信息,要求算法复原这些信息:几何类方法去除的是几何分布信息(如patch的相对位置关系);对比类方法去除的是图像的整体信息(通过抽取不同的view);生成类方法如MIM去除的是图像的局部信息。这种基于退化的方法,都具有一个无法逾越的瓶颈,即退化强度和语义一致性的冲突。由于没有监督信号,视觉表征学习完全依赖于退化,因此退化必须足够强;而退化足够强时,就无法保证退化前后的图像具有语义一致性,从而导致病态的预训练目标。举例说,对比学习从一张图像中抽取的两个view如果毫无关系,拉近它们的特征就不合理;MIM任务如果去除了图像中的关键信息(如人脸),重建这些信息也不合理。强行完成这些任务,就会引入一定的bias,弱化模型的泛化能力。未来,应该会出现一种无需退化的学习任务,而我个人相信,通过压缩来学习是一条可行的路线。
- 在域间差异明显的情况下,解决大数据和小样本的冲突。这又是CV和NLP的不同点:NLP已经基本不用考虑预训练和下游任务的域间差异性,因为语法结构和常见单词完全一样;而CV则必须假设上下游数据分布显著不同,以致于上游模型未经微调时,在下游数据中无法抽取底层特征(被ReLU等单元直接滤除)。因此,用小数据微调大模型,在NLP领域不是大问题(现在的主流是只微调prompt),但是在CV领域是个大问题。在这里,设计视觉友好的prompt也许是个好方向,但是目前的研究还没有切入核心问题。
- 按需视觉识别,提供了在形式上统一各种视觉任务的可能性。例如,分类、检测、分割等任务,在这一框架下得到了统一。这一点可能对视觉预训练带来启发。目前,视觉预训练和下游微调的边界并不清楚,预训练模型究竟应该适用于不同任务,还是专注于提升特定任务,尚无定论。然而,如果出现了形式上统一的识别任务,那么这个争论也许就不再重要。顺便说,下游任务在形式上的统一,也是NLP领域享有的一大优势。
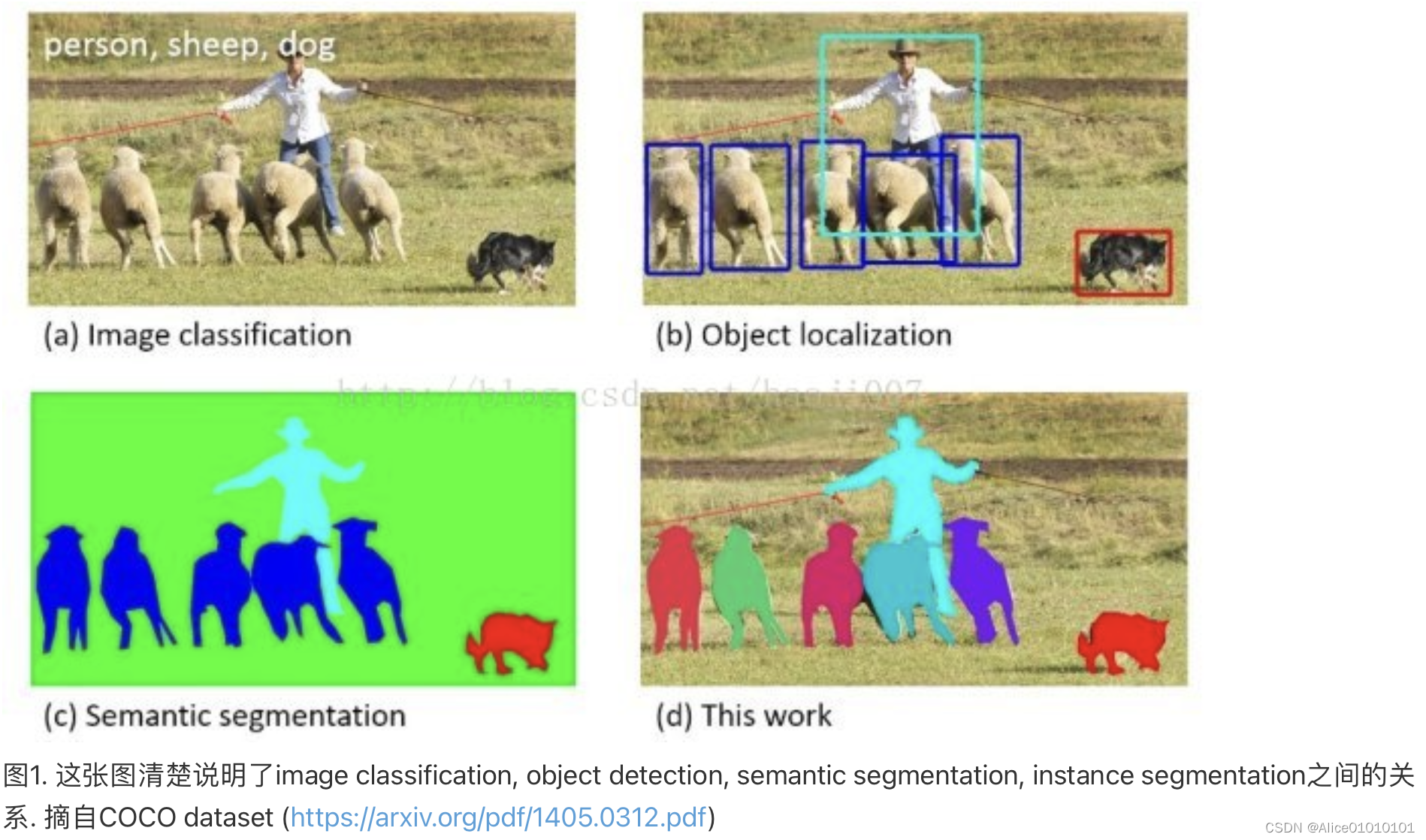
二、(d)是instance segmentation
三、阅读论文
3.1 OCEAN-SOT(Object-aware Anchor-Free Tracking)
??在过去的几年中,基于anchor的Siamese算法成为了单目标跟踪的主流。但是其本身在训练时设置了较为严苛的正负样本阈值(IoU>0.6)。这种设置固有的问题是:算法在训练时无法“看见”重合度较小的anchor,如果在测试时候分类分支将这样的anchor选为目标区域,那回归网络预测结果将非常差。
??Different from anchor-based methods which estimate the offsets of anchor boxes, anchor-free mechanisms predict the location of objects in a direct way, estimating the key points of objects, e.g., the object center and corners. Another branch of anchor-free detectors predicts the object bounding box at each pixel level without using any references, e.g., anchors or key points.
??The core idea is to estimate the distances from each pixel within the target object to the four sides of the ground truth bounding box.
3.2
机器学习4种自动调参方法:网格搜索、随机搜索、贝叶斯优化和Hyperband
FOCUS:将整个目标区域内的所有点作为正样本
Anchor-based最重要的提供先验,分类的正样本是在物体的中心;Anchor-free方法,物体边缘的点也需要做regression回归,这时候也要回归到物体上面
Challenges:
Siamese can’t go deeper
Trackers are too slow
No essential novelty/improvement
a new framework is required
Future Study:
Tracking and segmentation
Merging MOT and SOT
Involve other learning method(e.g. Self-training)
Tracking 使用TPE调后处理参数
3.3 Backbone is all your need: A simplified architecture for VOT
??Siamese networks is a widely-used two-branch architecture in a surge of tracking algorithms. Previous works based on Siamese Networks formulate VOT as a similarity matching problem and conduct the interaction through cross-correlation.
??It is a general paradigm to seamlessly transfer networks pre-trained from the classification task to provide a stronger initialization for VOT. In our method, we also initialize our transformer backbone with pre-trained parameters.
??For the search image, the inputsize (224 * 224) is the same with that in general vision transformers [15,41], so the pre-trained position embedding p0 can be directly used for the search image (ps = p0). However, the exemplar image is smaller than the search image, so the pre-trained position embedding can not fit well for the exemplar image.
??The input of transformer backbone includes the search sequence s0, the exemplar sequence e0 and the foveal sequence e0*. The exemplar image is small in VOT, so the token number in e0 and e0* are modest as well.
3.4 STARK
In summary, this work has three contributions.
- We propose a new transformer architecture dedicated to visual tracking. It is capable of capturing global feature dependencies of both spatial and temporal information in video sequences.
- The whole method is end-to-end, does not need any postprocessing steps such as cosine window and bounding box smoothing, thus largely simplifying existing tracking pipelines.
- The proposed trackers achieve state-of-the-art performance on fifive challenging short-term and long-term benchmarks, while running at real-time speed.
Usually, the tracking pipelines of previous trackers use various post-processing to choose the best bounding box as the tracking result. Though it brings better results, post-processing causes the performance being sensitive to hyper-parameters.
The transformer architecture is similar to that in DETR with 6 encoder layers and 6 decoder layers, which consists of multi-head attention layers(MHA) and feed-forward networks(FFN).
The whole training process of STARK-ST consists of two stages, which take 500 epochs for localization and 50 epochs for classifification, respectively.
We also try to replace the corner head with a three-layer perceptron as in DETR.The experiment shows that the performance of STARK with an MLP as the box head is 2.7% lower than that of the proposed corner head.
When removing the score head, the performance drops to 64.5%, which is lower than that of STARK-S50 without using temporal information. This demonstrates that improper uses of temporal information may hurt the performance and it is important to fifilter out unreliable templates.
In the encoder-decoder attention module, the target query can attend to all positions on the template and the search region features, thus learning robust representations for the final bounding box prediction




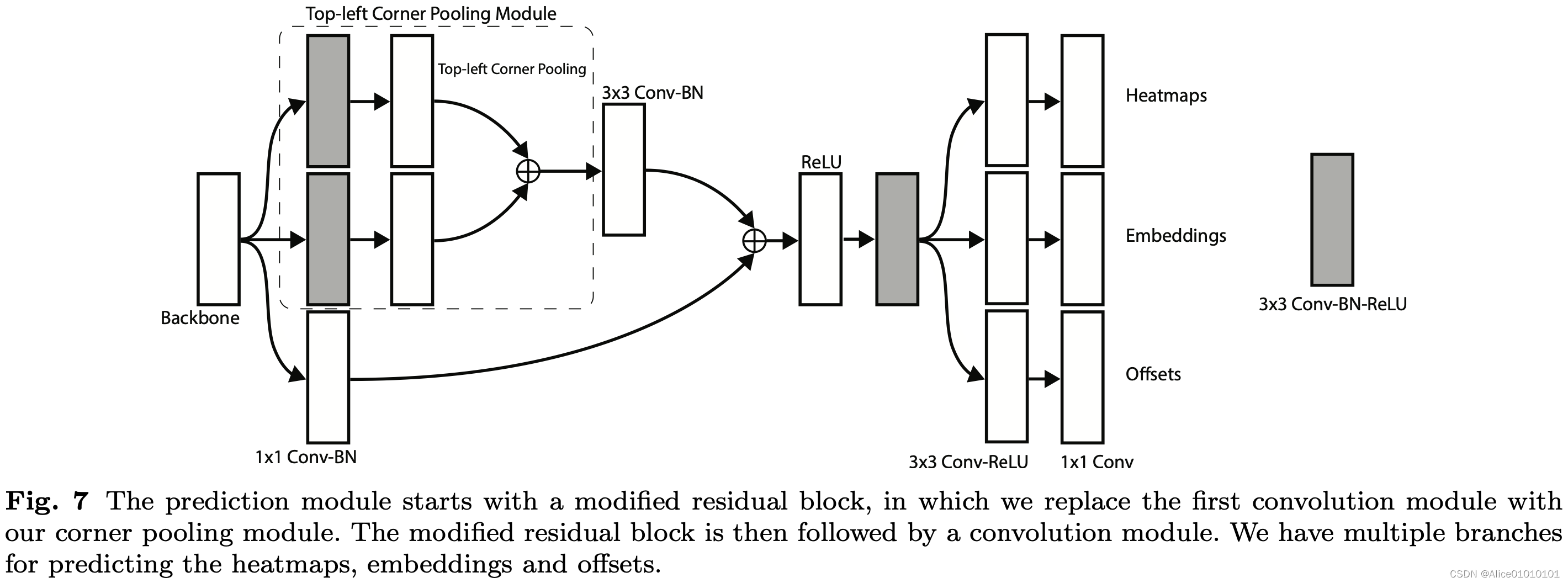
已知heatmap预测corner角点坐标(top-left和bottom-right)的代码:
class Corner_Predictor(nn.Module):
""" Corner Predictor module"""
def __init__(self, inplanes=64, channel=256, feat_sz=20, stride=16, freeze_bn=False):
super(Corner_Predictor, self).__init__()
self.feat_sz = feat_sz
self.stride = stride
self.img_sz = self.feat_sz * self.stride
'''top-left corner'''
self.conv1_tl = conv(inplanes, channel, freeze_bn=freeze_bn)
self.conv2_tl = conv(channel, channel // 2, freeze_bn=freeze_bn)
self.conv3_tl = conv(channel // 2, channel // 4, freeze_bn=freeze_bn)
self.conv4_tl = conv(channel // 4, channel // 8, freeze_bn=freeze_bn)
self.conv5_tl = nn.Conv2d(channel // 8, 1, kernel_size=1)
'''bottom-right corner'''
self.conv1_br = conv(inplanes, channel, freeze_bn=freeze_bn)
self.conv2_br = conv(channel, channel // 2, freeze_bn=freeze_bn)
self.conv3_br = conv(channel // 2, channel // 4, freeze_bn=freeze_bn)
self.conv4_br = conv(channel // 4, channel // 8, freeze_bn=freeze_bn)
self.conv5_br = nn.Conv2d(channel // 8, 1, kernel_size=1)
'''about coordinates and indexs'''
with torch.no_grad():
self.indice = torch.arange(0, self.feat_sz).view(-1, 1) * self.stride
# generate mesh-grid
self.coord_x = self.indice.repeat((self.feat_sz, 1)) \
.view((self.feat_sz * self.feat_sz,)).float().cuda()
self.coord_y = self.indice.repeat((1, self.feat_sz)) \
.view((self.feat_sz * self.feat_sz,)).float().cuda()
def forward(self, x, return_dist=False, softmax=True):
""" Forward pass with input x. """
score_map_tl, score_map_br = self.get_score_map(x)
if return_dist:
coorx_tl, coory_tl, prob_vec_tl = self.soft_argmax(score_map_tl, return_dist=True, softmax=softmax)
coorx_br, coory_br, prob_vec_br = self.soft_argmax(score_map_br, return_dist=True, softmax=softmax)
return torch.stack((coorx_tl, coory_tl, coorx_br, coory_br), dim=1) / self.img_sz, prob_vec_tl, prob_vec_br
else:
coorx_tl, coory_tl = self.soft_argmax(score_map_tl)
coorx_br, coory_br = self.soft_argmax(score_map_br)
return torch.stack((coorx_tl, coory_tl, coorx_br, coory_br), dim=1) / self.img_sz
def get_score_map(self, x):
# top-left branch
x_tl1 = self.conv1_tl(x)
x_tl2 = self.conv2_tl(x_tl1)
x_tl3 = self.conv3_tl(x_tl2)
x_tl4 = self.conv4_tl(x_tl3)
score_map_tl = self.conv5_tl(x_tl4)
# bottom-right branch
x_br1 = self.conv1_br(x)
x_br2 = self.conv2_br(x_br1)
x_br3 = self.conv3_br(x_br2)
x_br4 = self.conv4_br(x_br3)
score_map_br = self.conv5_br(x_br4)
return score_map_tl, score_map_br
def soft_argmax(self, score_map, return_dist=False, softmax=True):
""" get soft-argmax coordinate for a given heatmap """
score_vec = score_map.view((-1, self.feat_sz * self.feat_sz)) # (batch, feat_sz * feat_sz)
prob_vec = nn.functional.softmax(score_vec, dim=1)
exp_x = torch.sum((self.coord_x * prob_vec), dim=1)
exp_y = torch.sum((self.coord_y * prob_vec), dim=1)
if return_dist:
if softmax:
return exp_x, exp_y, prob_vec
else:
return exp_x, exp_y, score_vec
else:
return exp_x, exp_y
CornetNet
ByteTrack
