MobileNets
MobileNetv1
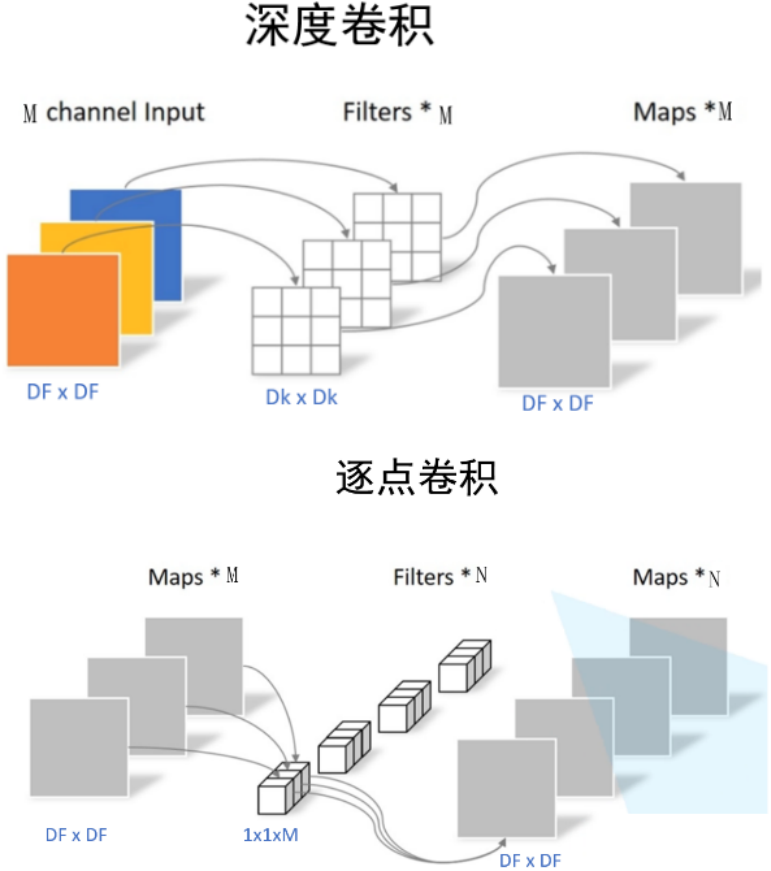
深度可分离卷积
深度学习的经典网络模型,如ResNet、VGG、GooogleNet等已经达到了不错的效果,但存在一个问题,即模型庞大,参数较多,计算量较大,在一些实际的场景如移动或嵌入式设备中很难被应用。此时就出现了针对这些移动场景的轻量级的网络―MobileNets。
MobileNet模型是基于深度可分离卷积,这是一种分解卷积的形式。这种形式将标准卷积分解为一个深度卷积和一个逐点卷积的1x1的卷积。
深度卷积只处理长宽方向的空间信息
逐点卷积只处理跨通道方向的信息

深度卷积(dw)
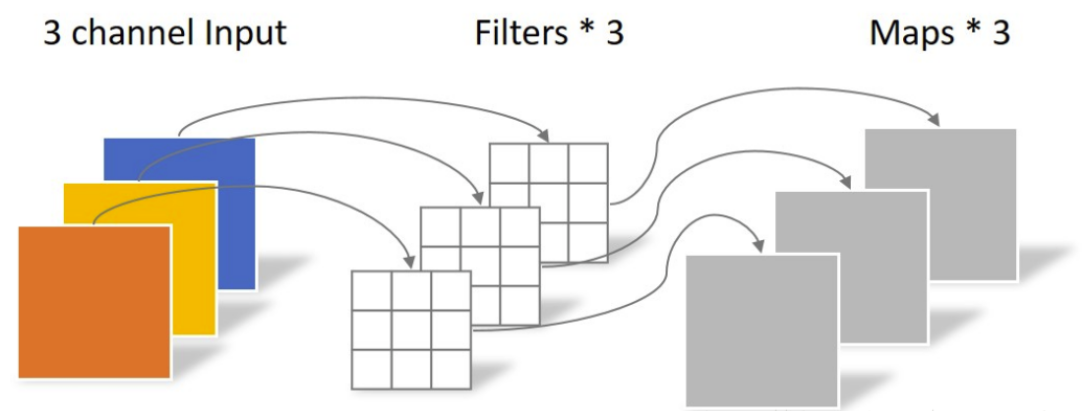
深度卷积与标准卷积的区别在于深度卷积的卷积核为单通道模式,需要对输入的每一个通道进行卷积,以此得到和输入特征图通道数一致的输出特征图。
深度卷积中一个卷积核只处理一个通道,即每个卷积核只处理自己对应的通道。输入特征图有多少个通道就有多少个卷积核。将每个卷积核处理后的特征图堆叠在一起。输入和输出特征图的通道数相同。
输入特征图的通道上为3,由于采用的卷积核是单通道模式,所以要三个单通道卷积核才可和输入图像完全一一对应的卷积,以此得到了输出的特征图,输出特征图的个数为3。
深度卷积的输入特征图通道数 = 卷积核个数 = 输出特征图个数
由于只处理长宽方向的信息会导致丢失跨通道信息,为了将跨通道的信息补充回来,需要进行逐点卷积。

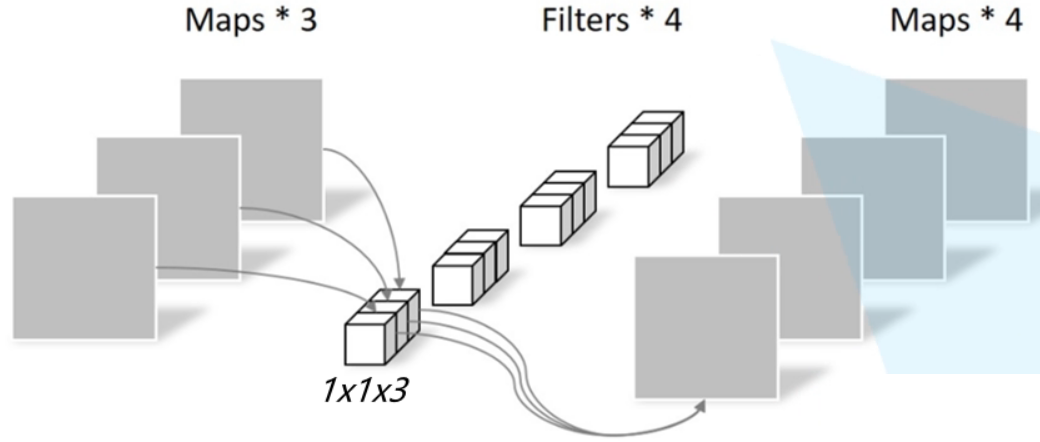
逐点卷积
通过深度卷积可得到特征图,但输入特征图通道数=卷积核个数=输出特征图个数,导致输出的特征图的个数太少了【或者可以说输出特征图的通道数太少了】,从而会影响信息的有效性。
此时就要进行逐点卷积,其实质就是用1x1的卷积核进行升维。【1x1的卷积核的主要作用就是对特征图进行升维和降维。】
从上一步得到了3个特征图【或者说成是一个有三个通道的特征图】,卷积核大小为1x1x3,卷积核个数为4,这样卷积后就可以得到4个特征图。
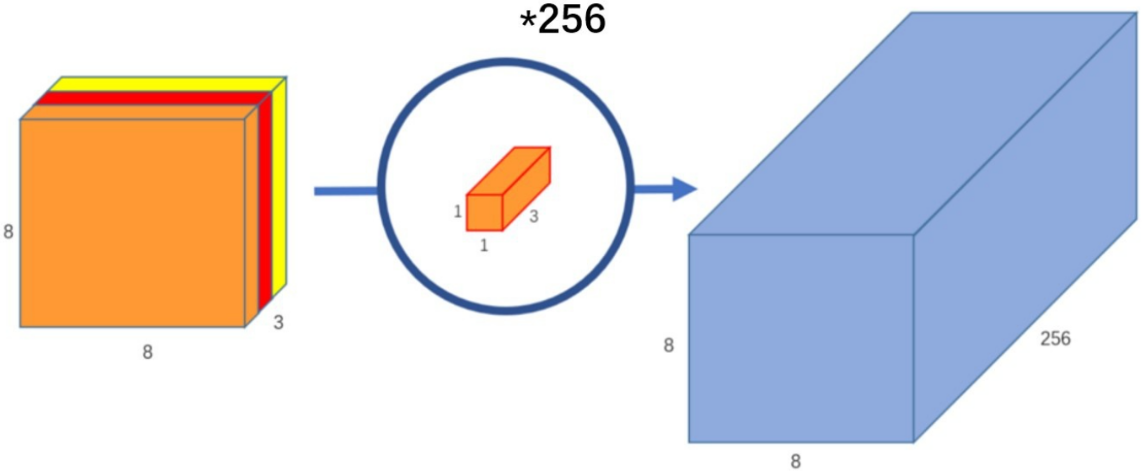
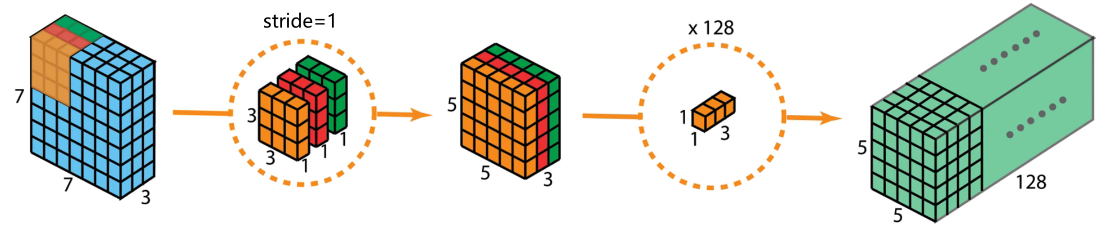
参数量和计算量
标准卷积

参数量:标准卷积的参数量是DK x DK × M x N
计算量:假设输出的特征图尺寸也是DF x DF,标准卷积的计算量是DK x DK × M x N x DF x DF。
参数量指网络中需要多少参数,对于卷积来说,就是卷积核里所有的值的个数,其往往和空间使用情况有关;计算量指网络中进行了多少次乘加运算,对于卷积来说,得到的特征图都是进行一系列的乘加运算得到的,计算公式就是卷积核的尺寸DK x DK × M、卷积核个数N、及输出特征图尺寸DF x DF的乘积,计算量往往和时间消耗有关。】
深度可分离卷积
参数量
深度卷积:参数量为DK x DK × M
逐点卷积:参数量为M x N
深度可分离卷积的参数量为DK x DK × M + M x N计算量
深度卷积:计算量为DK x DK × M x DF x DF
逐点卷积:计算量为M x N x DF x DF
深度可分离卷积的参数量为DK x DK × M x DF x DF+MxNxDF x DF
综上,得到了标准卷积和深度可分离卷积的参数量和计算量,用它们的比值进行比较:一般N较大,?可忽略不计,DK 表示卷积核的大小,若DK =3,
?。若使用常见的 3 × 3 卷积核,那么深度可分离卷积的参数量和计算量下降到原来的九分之一左右。
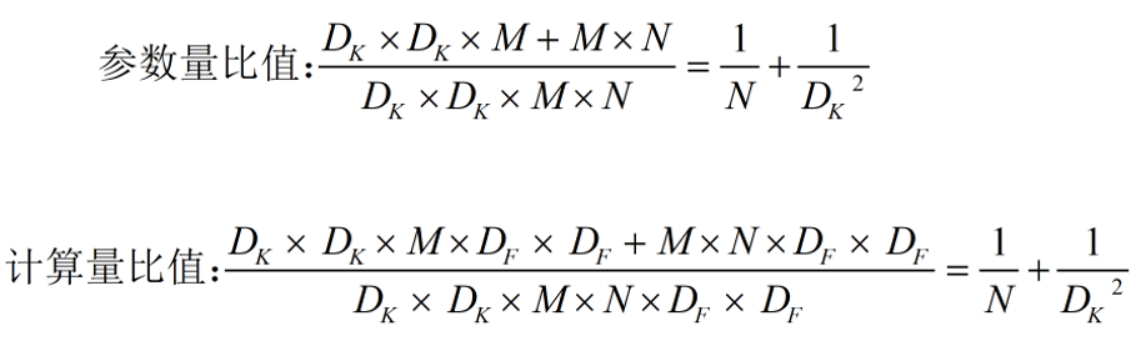
MobileNetv1网络结构

MobileNetv2
在MobileNetv1的训练中,深度卷积时卷积核容易废掉,即训练完后很多卷积核是空的。
MobileNetv2认为造成的原因是由于Relu函数造成的,在输入维度是2,3时,输出和输入相比丢失了较多信息;但在输入维度是15到30时,输出则保留了输入的较多信息。
这说明在使用Relu函数时,当输入的维度较低时,会丢失较多信息,因此可以想到两种思路,一是把Relu激活函数替换成别的,二是通过升维将输入的维度变高。MobileNetv2就是这么做的:Linear Bottlenecks 和 Inverted Residuals。
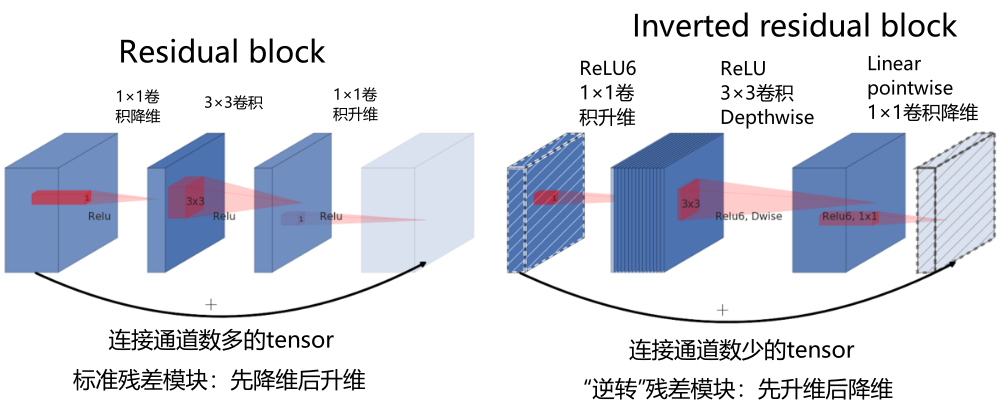
MobileNetV2 使用了逆转残差模块。
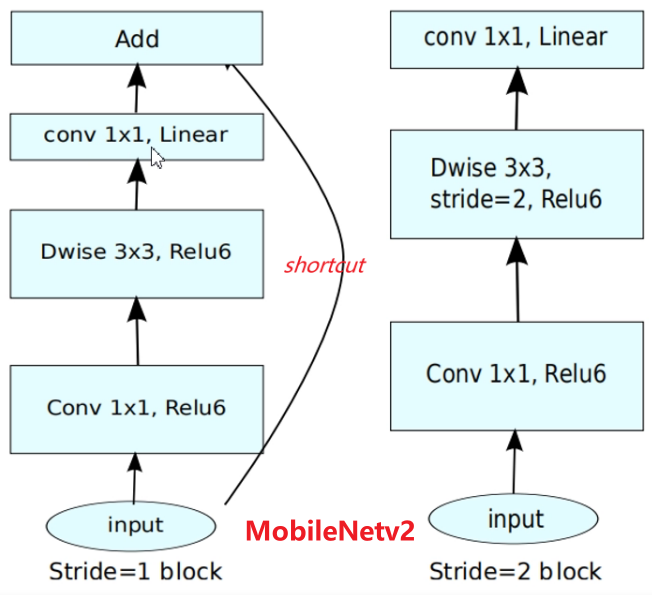
输入图像,使用1x1卷积提升通道数 -> 在高维空间下使用深度卷积 -> 使用1x1卷积下降通道数,降维时采用线性激活函数(y=x)。
????????当步长等于1且输入和输出特征图的shape相同时,使用残差连接输入和输出;
????????当步长=2(下采样阶段)直接输出降维后的特征图。
对比 ResNet 的残差结构。
输入图像,使用1x1卷积下降通道数 -> 在低维空间下使用标准卷积 -> 使用1x1卷积上升通道数,激活函数都是ReLU函数。
????????当步长等于1且输入和输出特征图的shape相同时,使用残差连接输入和输出;
????????当步长=2(下采样阶段)直接输出降维后的特征图。
Linear Bottlenecks

深度可分离卷积的每个块构成:首先是一个3x3的深度卷积,其次是BN、Relu层,接下来是1x1的逐点卷积,最后又是BN和Relu层。
前文说要把Relu激活函数替换,MobileNetv2将Relu替换成线性激活函数。但不是将所有的Relu激活都换成了线性激活,而是将上图中标黄的Relu变成了线性激活函数。变换后的块在文章中称为Linear Bottlenecks,结构如下图所示:

Inverted Residuals
Inverted Residuals中文是倒残差结构
左侧为ResNet中的残差结构,其结构为1x1卷积降维 -> 3x3卷积 -> 1x1卷积升维;
右侧为MobileNetv2中的倒残差结构,其结构为1x1卷积升维 -> 3x3 DW卷积 -> 1x1卷积降维。MobileNetv2先使用1x1进行升维的原因是前面所说的高维信息通过ReLU激活函数后丢失的信息更少。
MobileNetv3
注:NAS(网络结构搜索),如VGG、ResNet、MobileNetv1、MobileNetv2等网络结构都是手动去设计的,像网络的层数、卷积核大小、步长等参数。而NAS是通过计算机来实现最优的参数设定,通过比较不同参数的网络模型效果,从而选择最优的参数设置。
新增SE模块
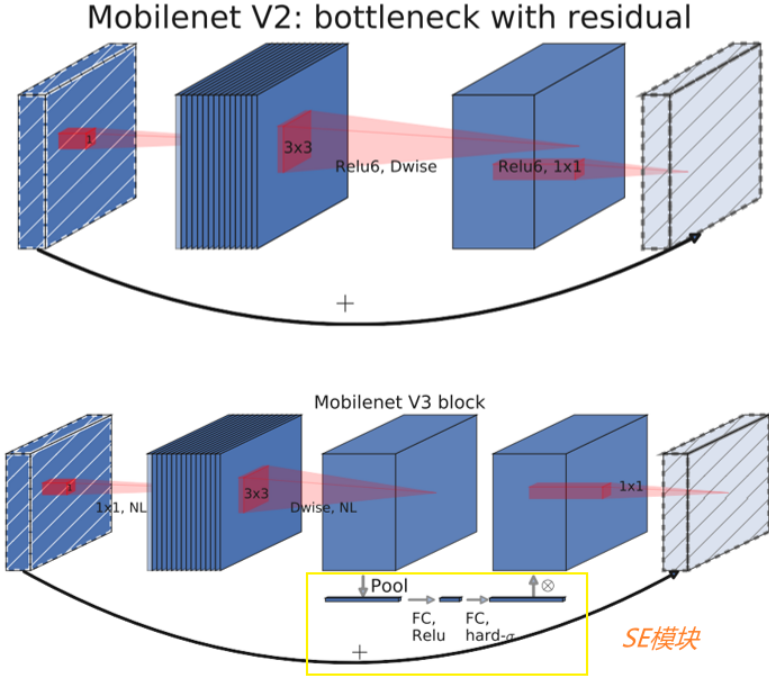
下图上半部分是MobileNetv2的block,下半部分是MobileNetv3的block。
MobileNetv3的block和MobileNetv2基本一致,主要是加入了SE模块(图中黄色框部分)。SE模块先将特征图的每个通道都进行平均池化,然后进行两个全连接层得到输出结果,这个结果会和原始的特征图进行相乘,得到新的特征图。
【注:第一个全连接层的输出设置为原来通道数的1/4,第二个全连接层输出设置为通道数】
SE注意力机制
- 将特征图进行全局平均池化,特征图有多少通道,那么池化结果(一维向量)就有多少元素,[h, w, c]==>[None, c]。
- 经过两个全连接层得到输出向量。第一个全连接层的输出通道数 = 原输入特征图通道数的1/4;第二个全连接层的输出通道数 = 原输入特征图的通道数:先降维后升维。
- 全连接层的输出向量可理解为,向量的每个元素是对每张特征图进行分析得出的权重关系。比较重要的特征图就会赋予更大的权重,即该特征图对应的向量元素值较大。反之,不太重要的特征图对应的权重值较小。
- 第一个全连接层使用ReLU激活函数,第二个全连接层使用 hard_sigmoid 激活函数
- 经过两个全连接层得到一个由channel个元素组成的向量,每个元素是针对每个通道的权重,将权重和原特征图的对应相乘,得到新的特征图数据
举例说明:下图左上角表示为两个通道的特质图,经平均池化后得到左下角的图;再次经过两次全连接层后,转化成了右下角的图,最后用右下角的0.5、0.6分别乘原始的特质图,则得到最终的右上角的图。

SE组件的作用:通过显示地建模通道之间的相互依存关系来增强通道级的特征响应(即学习一组权重,将权重赋予到每个通道来改善特征表示),使得重要特征得到加强,非重要特征得到弱化
具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征,并抑制对当前任务用处不大的特征?
重新设计耗时层结构
- 减少第一个卷积层卷积核个数(32 -> 16)
????????减少卷积核数量,使用ReLU或swish,准确率几乎相同。
-
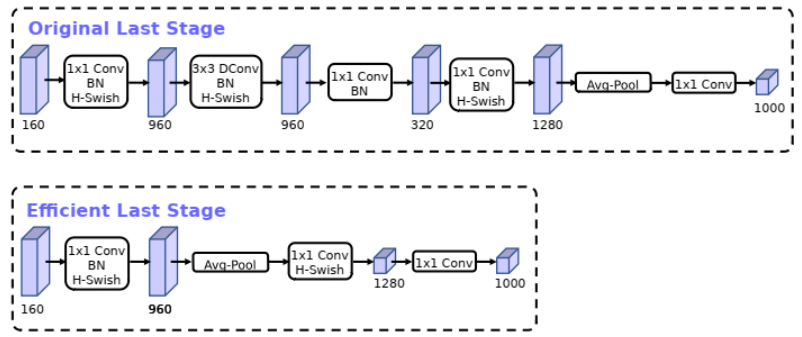
精简Last Stage
????????Original Last Stage是通过NAS算出来的,但实际测试发现Efficient Last Stage结构可在不损失精度情况下去除一些多余的层。
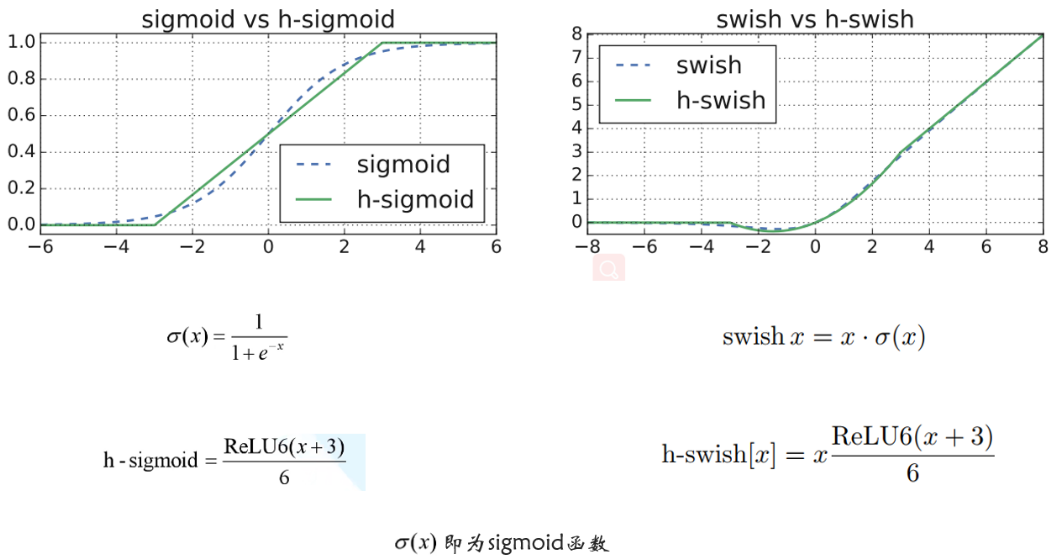
重新设计激活函数
在MobileNetv1和MobileNetv2版本中使用的Relu激活函数是Relu6激活函数。

MobileNetv3版本使用的激活函数为h-swish。
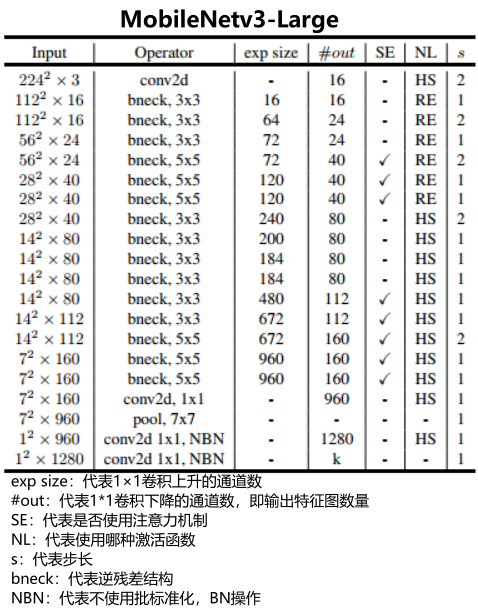
MobileNetv3的网络结构

更改YOLOv5
搭建核心模块
①激活函数
定义hard_sigmoid激活函数和hard_swish激活函数
"""
swish: x / e^-x
h_sigmoid: ReLU6(x+3) / 6 ReLU6: min(max(x,0),6)
h_swish: x * ReLU6(x+3) / 6
"""
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace) # inplace为True,将会改变输入的数据;否则不改变原输入,只产生新的输出
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)②SE注意力机制
SE注意力机制由 全局平均池化 + 全连接层降维 + 全连接层升维 + 对应权重相乘 组成。
class SELayer(nn.Module):
"""
对特征图进行全局平均池化,特征图有多少通道,那么池化结果(一维向量)就有多少元素,[h, w, c]==>[None, c]
经过两个全连接层得到输出向量
第一个全连接层的输出通道数 = 原输入特征图通道数的1/4; 第一个全连接层使用ReLU激活函数
第二个全连接层的输出通道数 = 原输入特征图的通道数; 第二个全连接层使用 hard_sigmoid 激活函数
经过两个全连接层得到一个由channel个元素组成的向量,每个元素是针对每个通道的权重,将权重和原特征图的对应相乘
"""
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
# Squeeze操作, 对tensor变量进行维度压缩, 获取全局信息
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化, [b,h,w,c]==>[b,c]==>[b,1,1,c]
# Excitation操作(FC + ReLU + FC + Sigmoid), 经过一系列激活操作, 但不改变操作前后的大小和通道数
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction), # 第一个全连接层的输出通道数=原输入特征图通道数的1/4
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel), # 第二个全连接层的输出通道数=原输入特征图通道数
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1) # 学习到的每一channel的权重
return x * y # 将权重和原特征图的对应相乘③标准卷积块
标准卷积块是由 普通卷积 + 批标准化 + 激活函数 组成
class conv_bn_hswish(nn.Module):
"""
This equals to
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
"""
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
# Conv2d(in_channels,out_channels,kernel_size,stride,padding,dilation,groups,bias)
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = h_swish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))④逆残差模块
class MobileNet_Block(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
"""
MobileNet_Block: [int_ch, out_ch, hidden_ch, kernel_size, stride, use_se, use_hs]
:param hidden_dim: 表示在 Inverted residuals 中的扩张通道数
Inverted residuals block: ①1×1卷积升维 ②3×3卷积 ③1×1卷积降维
:param use_se: 表示是否使用 SELayer
:param use_hs: 表示使用 h_swish 还是 ReLU
"""
super(MobileNet_Block, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
# 输入通道数 = 扩张通道数, 不进行通道扩张
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw, 深度卷积
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride,
(kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite, SE模块
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear, 逐点卷积
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
# 输入通道数 ≠ 扩张通道数, 进行通道扩张
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride,
(kernel_size - 1) // 2, groups=hidden_dim,bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y加入YOLOv5
- common.py文件修改,加入如下代码
# ---------------------------- MobileBlock start -------------------------------
from torch import nn
"""
swish: x / e^-x
h_sigmoid: ReLU6(x+3) / 6 ReLU6: min(max(x,0),6)
h_swish: x * ReLU6(x+3) / 6
"""
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class SELayer(nn.Module):
"""
对特征图进行全局平均池化,特征图有多少通道,那么池化结果(一维向量)就有多少元素,[h, w, c]==>[None, c]
经过两个全连接层得到输出向量
第一个全连接层的输出通道数 = 原输入特征图通道数的1/4; 第一个全连接层使用ReLU激活函数
第二个全连接层的输出通道数 = 原输入特征图的通道数; 第二个全连接层使用 hard_sigmoid 激活函数
经过两个全连接层得到一个由channel个元素组成的向量,每个元素是针对每个通道的权重,将权重和原特征图的对应相乘
"""
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
# Squeeze操作, 对tensor变量进行维度压缩, 获取全局信息
self.avg_pool = nn.AdaptiveAvgPool2d(1) # 全局平均池化, [b,h,w,c]==>[b,c]==>[b,1,1,c]
# Excitation操作(FC + ReLU + FC + Sigmoid), 经过一系列激活操作, 但不改变操作前后的大小和通道数
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction), # 第一个全连接层的输出通道数=原输入特征图通道数的1/4
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel), # 第二个全连接层的输出通道数=原输入特征图通道数
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1) # 学习到的每一channel的权重
return x * y # 将权重和原特征图的对应相乘
class conv_bn_hswish(nn.Module):
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
# Conv2d(in_channels,out_channels,kernel_size,stride,padding,dilation,groups,bias)
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = h_swish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MobileNet_Block(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
"""
:param hidden_dim: 表示在 Inverted residuals 中的扩张通道数
Inverted residuals block: ①1×1卷积升维 ②3×3卷积 ③1×1卷积降维
:param use_se: 表示是否使用 SELayer
:param use_hs: 表示使用 h_swish 还是 ReLU
"""
super(MobileNet_Block, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
# 输入通道数 = 扩张通道数, 不进行通道扩张
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw, 深度卷积
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride,
(kernel_size - 1) // 2, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite, SE模块
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear, 逐点卷积
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
# 输入通道数 ≠ 扩张通道数, 进行通道扩张
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride,
(kernel_size - 1) // 2, groups=hidden_dim,bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y
# ---------------------------- MobileBlock end ----------------------------------
yolo.py文件修改:在yolo.py的parse_model函数中,加入h_sigmoid, h_swish, SELayer, conv_bn_hswish, MobileNet_Block五个模块
-
新建yaml文件:在model文件下新建yolov5-mobilenetv3-small.yaml文件,添加以下代码,自行更换small与large
-
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license # Parameters nc: 6 # number of classes depth_multiple: 0.33 # model depth multiple width_multiple: 0.50 # layer channel multiple anchors: - [10,13, 16,30, 33,23] # P3/8 - [30,61, 62,45, 59,119] # P4/16 - [116,90, 156,198, 373,326] # P5/32 # YOLOv5 v6.0 backbone backbone_small: # MobileNetV3-small 11层 # [from, number, module, args] # MobileNet_Block: [out_ch, hidden_ch, kernel_size, stride, use_se, use_hs] # hidden_ch表示在Inverted residuals中的扩张通道数 # use_se 表示是否使用 SELayer, use_hs 表示使用 h_swish 还是 ReLU [[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2 [-1, 1, MobileNet_Block, [16, 16, 3, 2, 1, 0]], # 1-p2/4 [-1, 1, MobileNet_Block, [24, 72, 3, 2, 0, 0]], # 2-p3/8 [-1, 1, MobileNet_Block, [24, 88, 3, 1, 0, 0]], # 3-p3/8 [-1, 1, MobileNet_Block, [40, 96, 5, 2, 1, 1]], # 4-p4/16 [-1, 1, MobileNet_Block, [40, 240, 5, 1, 1, 1]], # 5-p4/16 [-1, 1, MobileNet_Block, [40, 240, 5, 1, 1, 1]], # 6-p4/16 [-1, 1, MobileNet_Block, [48, 120, 5, 1, 1, 1]], # 7-p4/16 [-1, 1, MobileNet_Block, [48, 144, 5, 1, 1, 1]], # 8-p4/16 [-1, 1, MobileNet_Block, [96, 288, 5, 2, 1, 1]], # 9-p5/32 [-1, 1, MobileNet_Block, [96, 576, 5, 1, 1, 1]], # 10-p5/32 [-1, 1, MobileNet_Block, [96, 576, 5, 1, 1, 1]], # 11-p5/32 ] backbone_large: # MobileNetV3-large 15层 # [from, number, module, args] # MobileNet_Block: [out_ch, hidden_ch, kernel_size, stride, use_se, use_hs] # hidden_ch表示在Inverted residuals中的扩张通道数 # use_se 表示是否使用 SELayer, use_hs 表示使用 h_swish 还是 ReLU [[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2 [-1, 1, MobileNet_Block, [ 16, 16, 3, 1, 0, 0]], # 1-p1/2 [-1, 1, MobileNet_Block, [ 24, 64, 3, 2, 0, 0]], # 2-p2/4 [-1, 1, MobileNet_Block, [ 24, 72, 3, 1, 0, 0]], # 3-p2/4 [-1, 1, MobileNet_Block, [ 40, 72, 5, 2, 1, 0]], # 4-p3/8 [-1, 1, MobileNet_Block, [ 40, 120, 5, 1, 1, 0]], # 5-p3/8 [-1, 1, MobileNet_Block, [ 40, 120, 5, 1, 1, 0]], # 6-p3/8 [-1, 1, MobileNet_Block, [ 80, 240, 3, 2, 0, 1]], # 7-p4/16 [-1, 1, MobileNet_Block, [ 80, 200, 3, 1, 0, 1]], # 8-p4/16 [-1, 1, MobileNet_Block, [ 80, 184, 3, 1, 0, 1]], # 9-p4/16 [-1, 1, MobileNet_Block, [ 80, 184, 3, 1, 0, 1]], # 10-p4/16 [-1, 1, MobileNet_Block, [112, 480, 3, 1, 1, 1]], # 11-p4/16 [-1, 1, MobileNet_Block, [112, 672, 3, 1, 1, 1]], # 12-p4/16 [-1, 1, MobileNet_Block, [160, 672, 5, 2, 1, 1]], # 13-p4/16 [-1, 1, MobileNet_Block, [160, 960, 5, 1, 1, 1]], # 14-p5/32 [-1, 1, MobileNet_Block, [160, 960, 5, 1, 1, 1]], # 15-p5/32 ] # YOLOv5 v6.0 head head: [[-1, 1, Conv, [512, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 6], 1, Concat, [1]], # cat backbone P4 [-1, 3, C3, [512, False]], # 13 [-1, 1, Conv, [256, 1, 1]], [-1, 1, nn.Upsample, [None, 2, 'nearest']], [[-1, 4], 1, Concat, [1]], # cat backbone P3 [-1, 3, C3, [256, False]], # 17 (P3/8-small) [-1, 1, Conv, [256, 3, 2]], [[-1, 14], 1, Concat, [1]], # cat head P4 [-1, 3, C3, [512, False]], # 20 (P4/16-medium) [-1, 1, Conv, [512, 3, 2]], [[-1, 10], 1, Concat, [1]], # cat head P5 [-1, 3, C3, [1024, False]], # 23 (P5/32-large) [[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
参考?
详细且通俗讲解轻量级神经网络――MobileNets【V1、V2、V3】
神经网络参数量、计算量(FLOPS)、内存访问量(AMC)计算详解