1. баОПБГОА
ШЫРрдкздШЛГЁОАжаПЩвдПьЫйЖЈЮЛВЂЪЖБ№ПДЕНЕФЮФзжаХЯЂ,ЕЋЪЧЯывЊМЦЫуЛњзіЕНКЭШЫРрвЛбљЪЧБШНЯРЇФбЕФЁЃПЊЗЂШЫдБвЛжБЯывЊШУЛњЦївВФмЪЖБ№ЭМЯёжаЕФЮФзжаХЯЂЁЃЕБШЛ,ЖдгкздШЛГЁОАРДЫЕ,ЭМЯёжаЕФаХЯЂИДдгЩѕжСЪЧЕЭаЇЕФ,ЮФзжХдЕФЮяЬхЉpЙтгА,вдМАзжЬхбеЩЋЁЂДѓаЁЁЂЪщаДЗчИё,ЖМЛсИјЛњЦїЪЖБ№ДјРДВЛЭЌГЬЖШЕФгАЯьЁЃЭМЯёЮФБОЪЖБ№ЭЈГЃБЛЛЎЗжЮЊСНИіВПЗж:ЮФБОМьВтгыЮФБОЪЖБ№ЁЃ
ЮФБОМьВтЪЧЮФБОЪЖБ№ЪзЯШвЊзіЕФвЛВН,ЪЧБиВЛПЩШБЕФвЛВНЁЃвЊШУЛњЦїЪЖБ№здШЛГЁОАжаЛёШЁЕФЮФБОаХЯЂ,вЊЯШШУЛњЦїжЊЕРЮФБОаХЯЂЕФЮЛжУЁЃЯждквВгаКмЖрЮФБОМьВтЕФНтОіЗНАИ,ЕЋЪЧдкУцЖдИДдгЕФЭМЯёЪБ,ЭљЭљПЙИЩШХФмСІВЛОЁШчШЫвтЁЃЖјЧветаЉЭМЯёЭЈГЃЛсгаВЛЭЌзжЬх(Р§ШчвеЪѕЮФзж),ВЛЭЌаЮзД,бЯжигАЯьСЫЮФБОЕФМьВтгыЪЖБ№ЁЃ
2.ЖргябдбЁдёФЃПщ
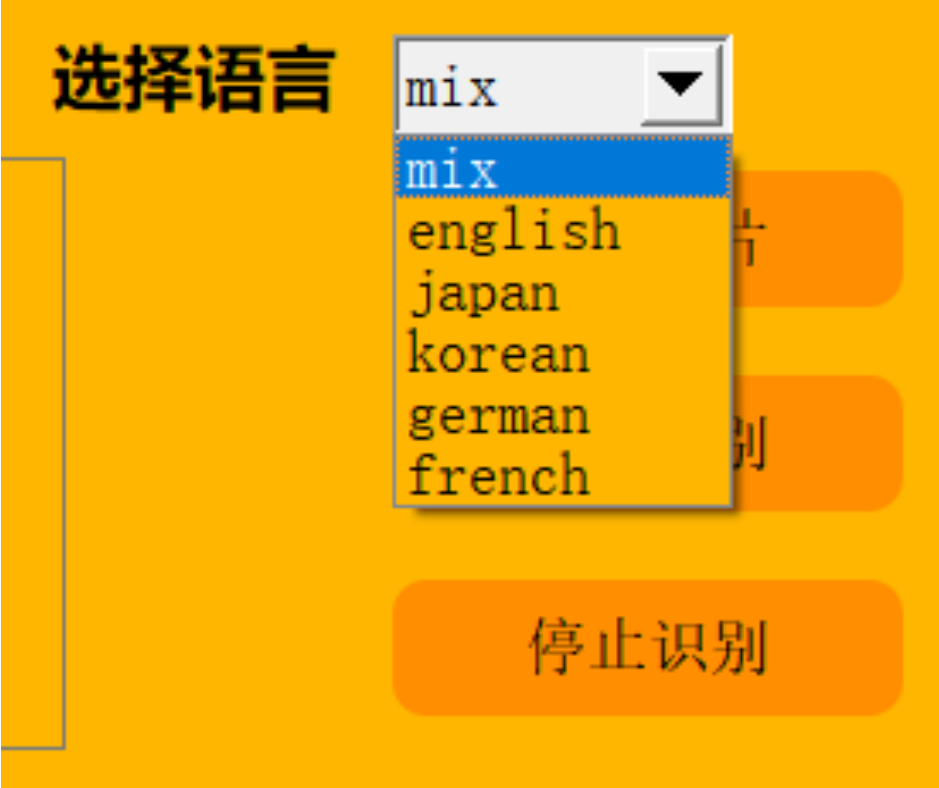
3.ЪЖБ№аЇЙћеЙЪО


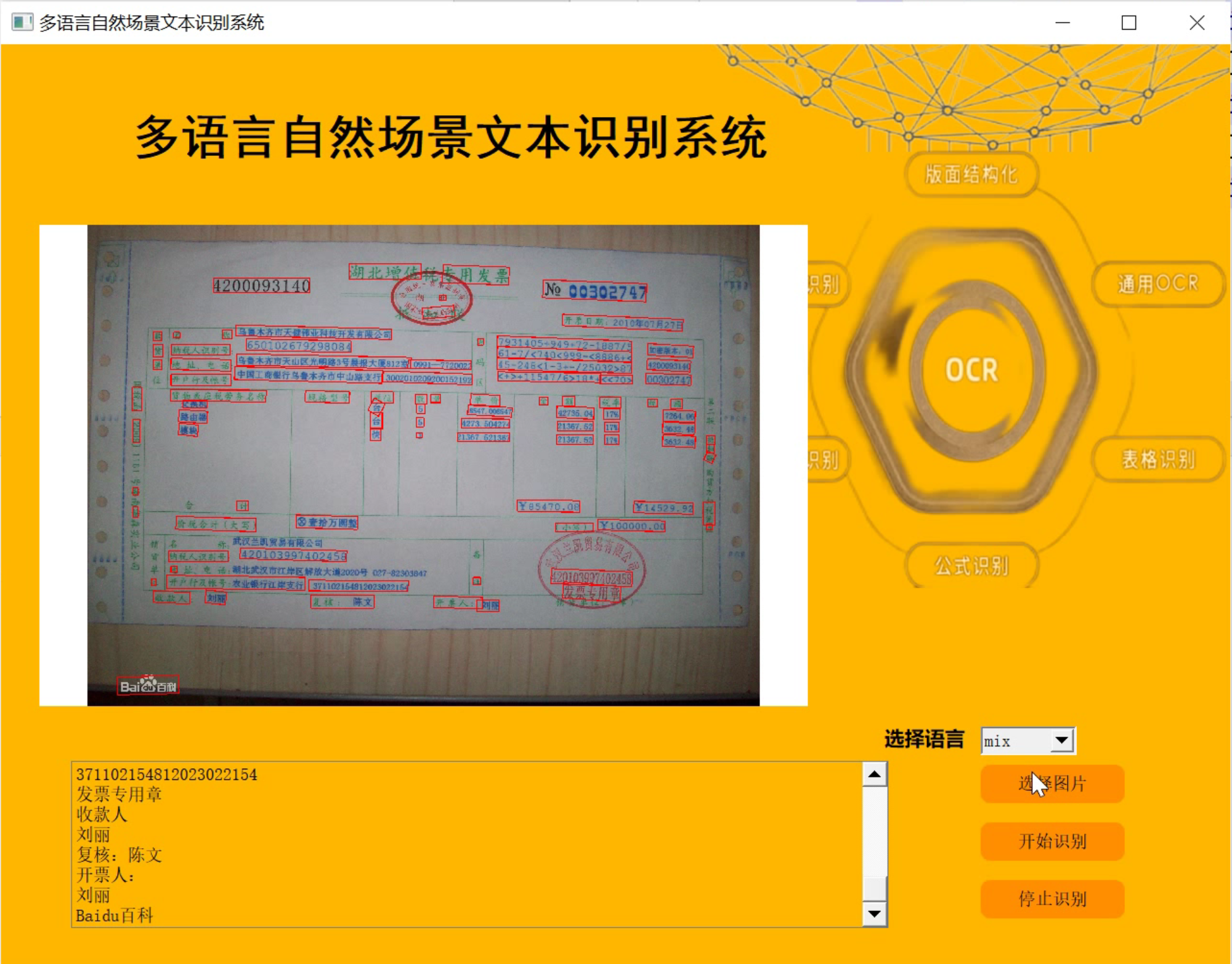
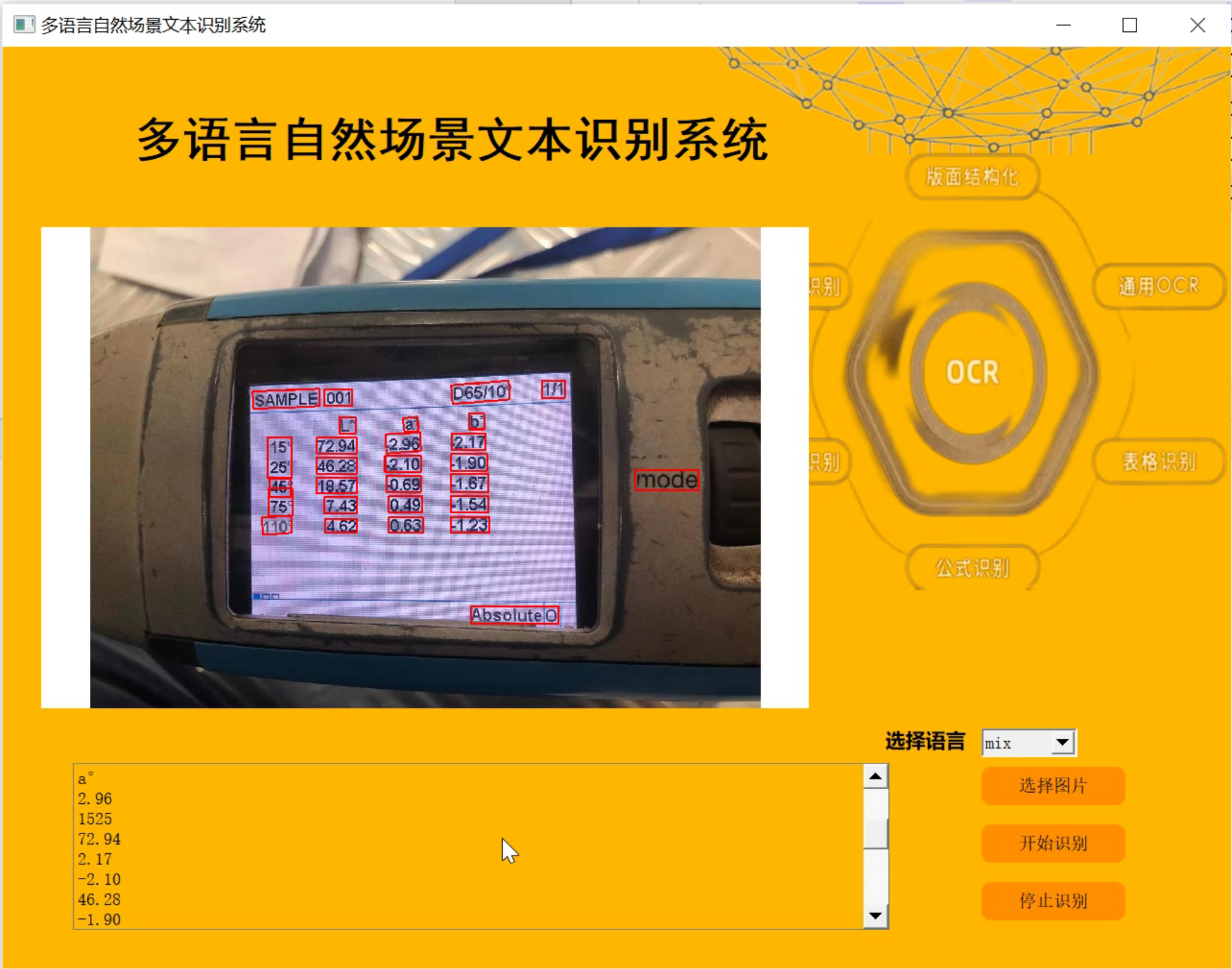

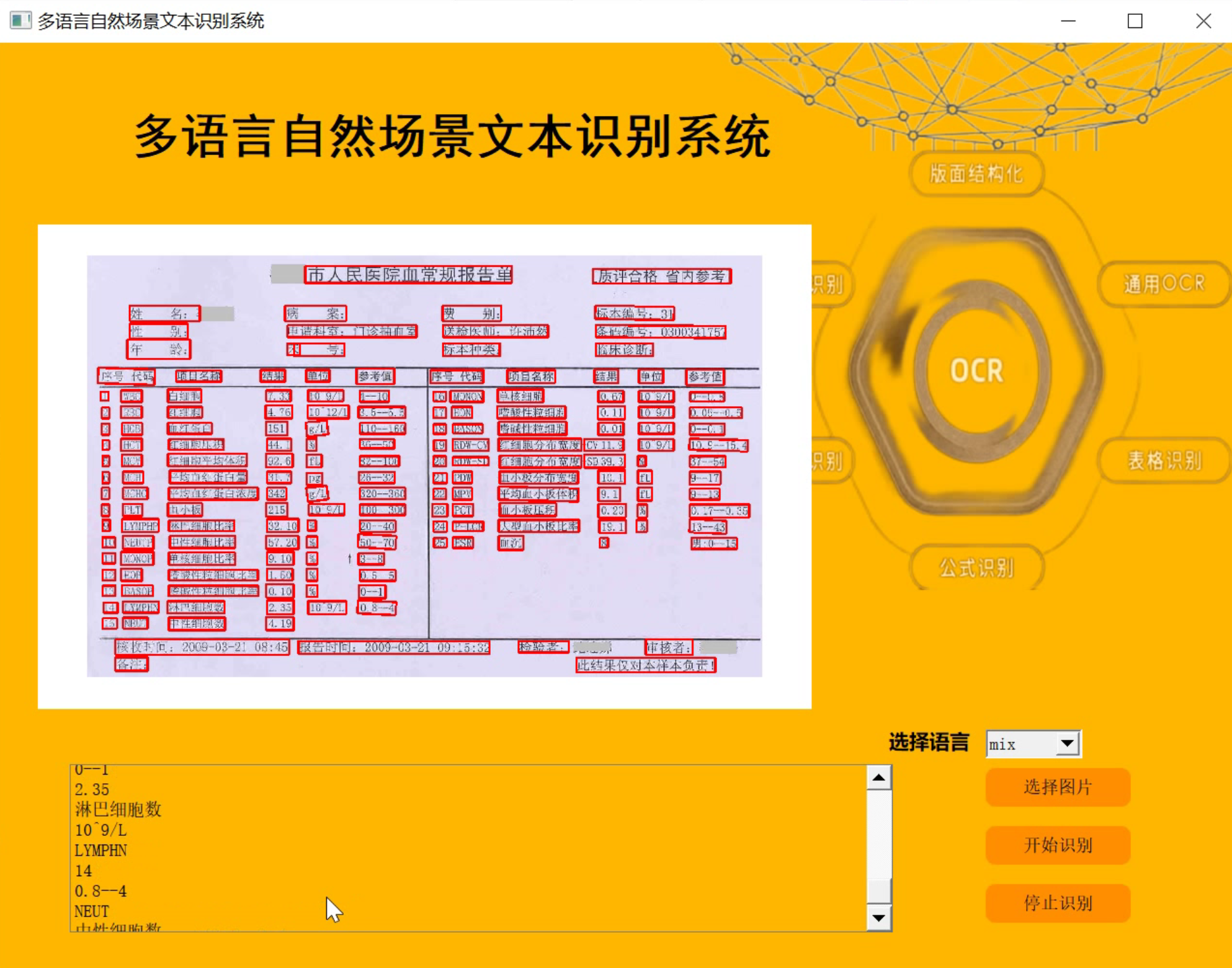
4.аЇЙћЪгЦЕбнЪО
OpencvЖргябдздШЛГЁОАЮФБОЪЖБ№ЯЕЭГ(дДТы&НЬГЬ)_пйСЈпйСЈ_bilibili
5.ЮФБОЪЖБ№ЫуЗЈCRNN
ЮФБОЪЖБ№ЪЧАбЮФзжЭМЦЌзЊЛЛГЩМЦЫуЛњПЩЖСЮФБОЕФЙ§ГЬ,ЪфШыЪЧДгдЭМжаВУМєГіРДЕФКђбЁЧјгђЕФЭМЦЌ,ЪфГіЪЧЭМЦЌжаАќКЌЕФЮФзжађСаЁЃФПЧАЕФЮФБОЪЖБ№ЗНЗЈАбЪЖБ№ШЮЮёПДзївЛжжађСаЪЖБ№ШЮЮё,ПЩвдЪЁТдзжЗћЕФЗжИюЁЃКЭвЛАуЭМЯёЗжРрШЮЮёВЛвЛбљ,ЮФБОЪЖБ№ЪфГіЕФЪЧЮФзжађСа,ГЄЖШВЛЙЬЖЈЁЃШчЭМЫљЪО,ИљОнађСаНЈФЃЗНЪНЕФВЛЭЌ НЋ ФП ЧА ЮФ БО ЪЖ Б№ ЗН ЗЈ Зж ЮЊ СН Дѓ Рр :
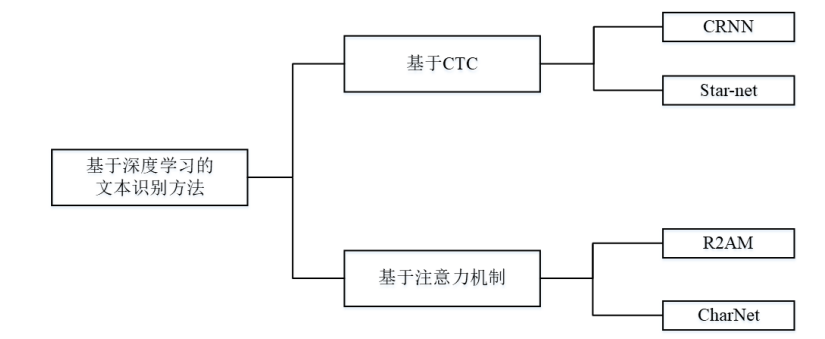
1.Лљ гк CTC(Connectionist Temporal Classification)ЕФЮФБОЪЖБ№ЫуЗЈ
2.ЛљгкзЂвтСІЛњжЦЕФЮФБОЪЖБ№ЫуЗЈ
ЮФБОЪЖБ№ЕФФПЕФЪЧНЋКђбЁЧјгђжаЕФЮФБОЭМАИЪЖБ№ЮЊБъзМЕФЮФзж,гЩгкЮФБОЪЖБ№ЫуЗЈВЂВЛЪЧТлЮФЕФбаОПжиЕу,ЫљвдБОНкжЛНщЩмЮФжаЪЙгУЕНЕФCRNNЮФБОЪЖБ№ЫуЗЈЁЃ
CRNNЕФжївЊЫМЯыОЭЪЧНЋЮФБОЪЖБ№ПДзїЪЧЖдађСаЕФдЄВт,ЖјВЛЪЧНЋЮФБОПДзїЖРСЂЕФФПБъ,ЫљвдВЩгУСЫRNNЭјТчРДдЄВтађСа,ЫуЗЈЕФжївЊСїГЬПЩвдЗжЮЊШ§ИіВПЗж:ЭЈЙ§CNNЭјТчЬсШЁЭМЯёЬиеї,ШЛКѓВЩгУBiSTLM(ЫЋЯђГЄЖЬЪБМЧвф)ЭјТчРДЖдађСаНјаадЄВт,зюКѓЭЈЙ§CTCзЊТМВуРДЕУЕНзюжеЕФНсЙћЁЃ
ДњТыЪЕЯж
class CRNN(nn.Module):
def __init__(self, characters_classes, hidden=256, pretrain=True):
super(CRNN, self).__init__()
self.characters_class = characters_classes
self.body = VGG()
self.stage5 = nn.Conv2d(512, 512, kernel_size=(3, 2), padding=(1, 0))
self.hidden = hidden
self.rnn = nn.Sequential(BidirectionalLSTM(512, self.hidden, self.hidden),
BidirectionalLSTM(self.hidden, self.hidden, self.characters_class))
self.pretrain = pretrain
if self.pretrain:
import torchvision.models.vgg as vgg
pre_net = vgg.vgg16(pretrained=True)
pretrained_dict = pre_net.state_dict()
model_dict = self.body.state_dict()
pretrained_dict = {k: v for k, v in pretrained_dict.items() if k in model_dict}
model_dict.update(pretrained_dict)
self.body.load_state_dict(model_dict)
for param in self.body.parameters():
param.requires_grad = False
def forward(self, x):
x = self.body(x)
x = self.stage5(x)
x = x.squeeze(3)
x = x.permute(2, 0, 1).contiguous()
x = self.rnn(x)
x = F.log_softmax(x, dim=2)
return x
6.ЛљгкCTCЕФЗНЗЈЁЃ
етжжЗНЗЈжБНгНЋзжЗћЬиеїађСазЊЛЏЮЊзжЗћИХТЪ,ЭЈЙ§CTCЫ№ЪЇРДЕУЕНЪЖБ№LossЁЃЪмЕНгявєЪЖБ№ЕФЦєЗЂ,CRNNНЋCTCв§ШыЕНЛљгкЭМЯёЕФађСаЪЖБ№жа,CRNNЪЧвЛжжЖЫЕНЖЫЕФЮФБОађСаЪЖБ№ЯЕЭГ,АќРЈОэЛ§ФЃПщЁЂЕнЙщФЃПщКЭзЊТМФЃПщЁЃЮЊСЫЬсШЁРДздЯрЙиЩЯЯТЮФЕФаХЯЂ,гУЕНСЫвЛжжбЛЗОэЛ§ЩёОЭјТчЁЊЁЊLSTM,дкLSTMжаЭЈЙ§ЁАУХЁБРДПижЦРњЪЗаХЯЂЕФвХЭќКЭЕБЯШзДЬЌЕФИќаТЁЃStar-netНЋПеМфБфЛЛКЭCRNNЯрНсКЯ,в§ШыПеМфзЂвтСІЛњжЦЖдОпгаМИКЮЛћБфЕФЮФБОЭМЯёНјаааЃе§,ДгЖјЪЕЯжЖдОпгаМИКЮЛћБфЕФГЁОАЮФБОЕФЪЖБ№ЁЃЮЊСЫБмУтRNNбЕСЗЙ§ГЬжаЕФЬнЖШЭЫЛЏКЭЬнЖШБЌеЈЁЃ
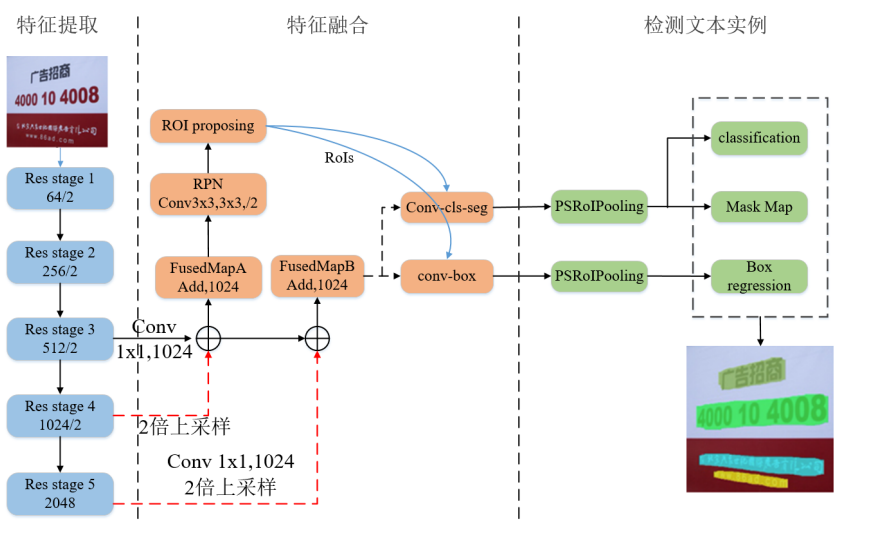
GaoЬсГіСЫвЛжжЖЫЕНЖЫЕФШЋОэЛ§ЮФБОЪЖБ№ЭјТч,ИУЭјТчВЩгУCNNВЖзНГЄЦквРРЕЙиЯЕ,ВЂДњЬцRNNЩњГЩађСаЬиеї,ИУФЃаЭДѓДѓЬсИпСЫЪЖБ№ЦїЕФЪЖБ№ЫйЖШЁЃЮФЯз[1]-[2]ЭЌбљдЫгУЩёОЭјТчНсКЯCTCЪЕЯжСЫзМШЗТГАєЕФЪЖБ№здШЛГЁОАжаЧуаБЕФЮФБО,ШчЯТЭМЫљЪОЁЃ

ДњТыЪЕЯж
def ctc(img, text_recs, adjust=False):
"""
МгдиCTCФЃаЭ,НјаазжЗћЪЖБ№
"""
results = {}
xDim, yDim = img.shape[1], img.shape[0]
for index, rec in enumerate(text_recs):
xlength = int((rec[6] - rec[0]) * 0.1)
ylength = int((rec[7] - rec[1]) * 0.2)
if adjust:
pt1 = (max(1, rec[0] - xlength), max(1, rec[1] - ylength))
pt2 = (rec[2], rec[3])
pt3 = (min(rec[6] + xlength, xDim - 2), min(yDim - 2, rec[7] + ylength))
pt4 = (rec[4], rec[5])
else:
pt1 = (max(1, rec[0]), max(1, rec[1]))
pt2 = (rec[2], rec[3])
pt3 = (min(rec[6], xDim - 2), min(yDim - 2, rec[7]))
pt4 = (rec[4], rec[5])
degree = degrees(atan2(pt2[1] - pt1[1], pt2[0] - pt1[0])) # ЭМЯёЧуаБНЧЖШ
partImg = dumpRotateImage(img, degree, pt1, pt2, pt3, pt4)
# dis(partImg)
if partImg.shape[0] < 1 or partImg.shape[1] < 1 or partImg.shape[0] > partImg.shape[1]: # Й§ТЫвьГЃЭМЦЌ
continue
text = recognizer.recognize(partImg)
if len(text) > 0:
results[index] = [rec]
results[index].append(text) # ЪЖБ№ЮФзж
return results
7.ЯЕЭГећКЯ
8.ЭъећдДТы&ЛЗОГВПЪ№ЪгЦЕНЬГЬ&здЖЈвхUIНчУц
OpencvЖргябдздШЛГЁОАЮФБОЪЖБ№ЯЕЭГ(дДТы&НЬГЬ) (mianbaoduo.com)
9. ВЮПМЮФЯз
[1]КЋгю.ЛљгкCNNМАRPNММЪѕЕФЮФзжЪЖБ№гІгУ[J].ЛњЕчаХЯЂ.2019,(21).90-91,93.DOI:10.3969/j.issn.1671-0797.2019.21.046.
[2]РюгБ,СѕОеЛЊ,взвЂЛЊ.здШЛГЁОАЭМЯёЕФзжЗћЪЖБ№ЗНЗЈ[J].АќзАЙЄГЬ.2018,(5).168-172.
[3]РюЮФаљ,ЫяМОЗс.ЛљгкИДКЯгХЛЏЕФЩюЖШВЃЖћзШТќЛњЕФТЗХЦЮФзжЭМЯёЪЖБ№ЫуЗЈ[J].МЦЫуЛњЙЄГЬгыПЦбЇ.2018,(1).79-85.DOI:10.3969/j.issn.1007-130X.2018.01.012.
[4]ЭђУШ.ЛљгкЩюЖШбЇЯАЕФздШЛГЁОАЮФзжМьВтгыЪЖБ№ЗНЗЈбаОП[D].2019
[5]ГТЙ№АВ.ЖЫЕНЖЫЕФздШЛГЁОАЮФзжМьВтгыЪЖБ№ЩёОЭјТчЕФбаОПгыЪЕЯж[D].2019
[6]Baoguang Shi,Xiang Bai,Cong Yao.An End-to-End Trainable Neural Network for Image-Based Sequence Recognition and Its Application to Scene Text Recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence.2017,39(11).2298-2304.