PaddleNLP最近发布了Paddle-Pipelines,Paddle-Pipelines是一个端到端智能文本产线框架,面向 NLP 全场景为用户提供低门槛构建强大产品级系统的能力。本项目将通过一种简单高效的方式搭建一套语义检索系统,使用自然语言文本通过语义进行智能文档查询,而不是关键字匹配,用户可以通过简单的配置,并上传数据,就可以完成自己想要定制化的搜索系统。
搜索技术的应用范围很广,比如建筑的规范搜索,公司内部规范条文的搜索,对话文本匹配,工单信息匹配,检索式智能问答,大规模不固定标签场景的文本分类,基于内容的搜索推荐等等场景。我们看一段视频,感受一下语义搜索的效果。
语义搜索
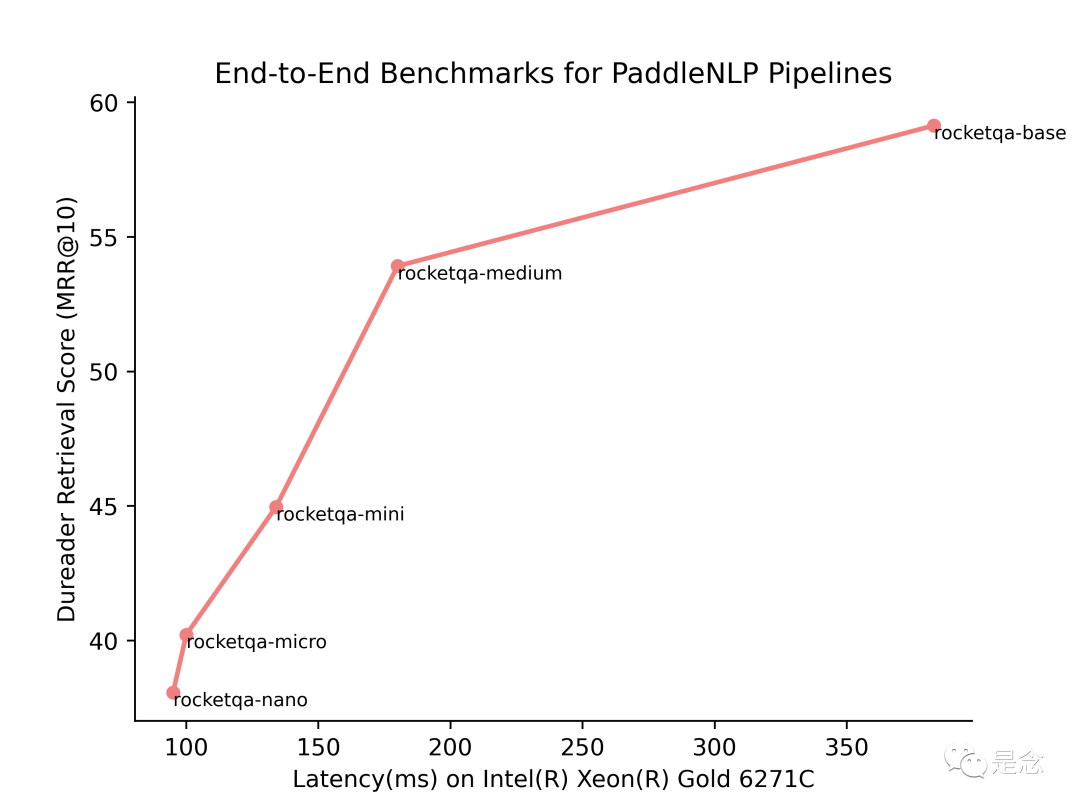
Pipelines预置了基于ERNIE 3.0系列模型训练的RocketQA的模型,效果图如下图所示,使用的数据集是Dureader Retrieval百万量级的人工标注的搜索数据集,对于速度和精度都进行了优化,其中nano模型在CPU上使用Pipelines能够达到100ms的速度,大大节省了用户的搭建成本。
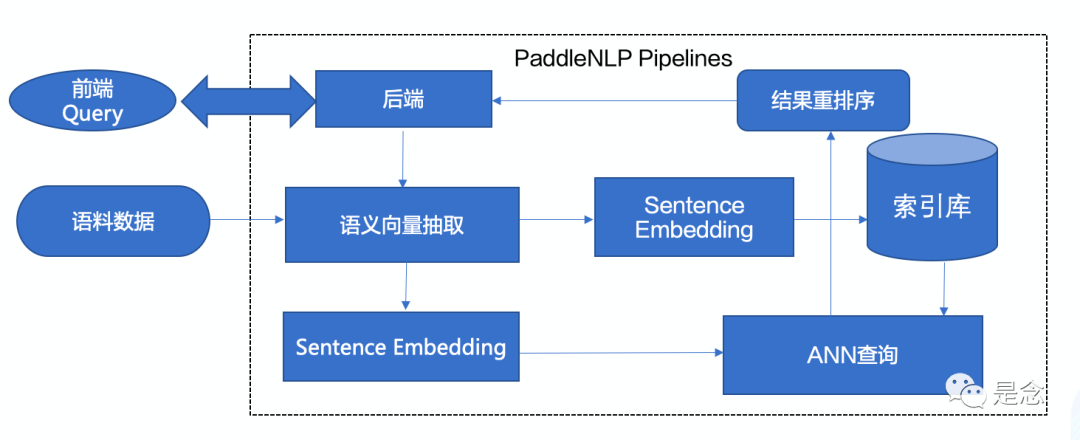
Pipelines的原理流程图如下,用户通过前端输入Query以后,后端收到数据,然后进行语义向量抽取,抽取出Sentence/Query Embdding,然后在索引库中进行ANN检索,然后对检索的结果进行重新排序,最后通过后端把结果返回给前端,用户就可以看到搜索的结果。
构建索引库的流程:用户把预先准备好的数据放入Pipelines系统,抽取向量得到Sentence Embedding,然后放入索引工具(比如Milvus,Elastic Search,FAISS)来构建索引库。
Pipelines的代码构建也很简单,下面是代码一段语义检索的代码示例:
from pipelines.document_stores import FAISSDocumentStore
from pipelines.nodes import DensePassageRetriever, ErnieRanker
# Step1: Preparing the data
documents = [
{'content': '金钱龟不分品种,只有生长地之分,在我国主要分布于广东、广西、福建、海南、香港、澳门等地,在国外主要分布于越南等亚热带国家和地区。',
'meta': {'name': 'test1.txt'}},
{'content': '衡量酒水的价格的因素很多的,酒水的血统(也就是那里产的,采用什么工艺等);存储的时间等等,酒水是一件很难标准化得商品,只要你敢要价,有买的那就值那个钱。',
'meta': {'name': 'test2.txt'}}
]
# Step2: Initialize a FaissDocumentStore to store texts of documents
document_store = FAISSDocumentStore(embedding_dim=768)
document_store.write_documents(documents)
# Step3: Initialize a DenseRetriever and build ANN index
retriever = DensePassageRetriever(document_store=document_store, query_embedding_model="rocketqa-zh-base-query-encoder",embed_title=False)
document_store.update_embeddings(retriever)
# Step4: Initialize a Ranker
ranker = ErnieRanker(model_name_or_path="rocketqa-base-cross-encoder")
# Step5: Initialize a SemanticSearchPipeline and ask questions
from pipelines import SemanticSearchPipeline
pipeline = SemanticSearchPipeline(retriever, ranker)
prediction = pipeline.run(query="衡量酒水的价格的因素有哪些?")
通过SemanticSearchPipeline就可以把定义的流水线节点串联起来,并且流水线的节点可以进行定制化,用户可以根据情况选择需要的节点。
搭建流程
为了帮助大家快速的搭建起来,Pipelines提供了Windows,Linux,Mac等主流系统的搭建流程,Windows上的搭建流程还特地录制了安装视频。下面特地介绍一下安装搭建流程,有需要的用户可以参考链接。
Windows的搭建流程请参考链接:https://github.com/PaddlePaddle/PaddleNLP/blob/develop/pipelines/examples/semantic-search/Install_windows.md
Windows的配套安装视频B站链接如下:https://www.bilibili.com/video/BV1DY4y1M7HE/?vd_source=f5bc16e5093165f01588d5a24417419d
Liunx和Mac的搭建流程请参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines/examples/semantic-search
Docker一键安装体验
如果用户想要快速体验带有后台和前端的Pipelines,可以使用Docker的方式来安装,这样就避免了各种平台的环境搭建,搭建环境难免会碰到各种各样的问题。
第一步启动elastic search容器
docker network create elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.3.3
docker run \
-d \
--name es02 \
--net elastic \
-p 9200:9200 \
-e discovery.type=single-node \
-e ES_JAVA_OPTS="-Xms256m -Xmx256m"\
-e xpack.security.enabled=false \
-e cluster.routing.allocation.disk.threshold_enabled=false \
-it \
docker.elastic.co/elasticsearch/elasticsearch:8.3.3
第二步是启动pipelines容器
对于Linux使用Docker的用户,使用下面的命令:
docker pull registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0
docker run -d --name paddlenlp_pipelines --net host -ti registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0
对于Windows&Macos上使用Docker的用户,用下面的命令:
docker pull registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin
docker run -d --name paddlenlp_pipelines -p 8891:8891 -p 8502:8502 -ti registry.baidubce.com/paddlepaddle/paddlenlp:2.4.0.windows.darwin
如果用户有gpu,可以启动对应版本的cuda镜像。详情请参考:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/pipelines
cpu容器启动大概需要等待3分钟,然后输入网址http://127.0.0.1:8502 就可以启动了,Enjoy it!如果有任何问题,可以去Github上提issue哈。